

티스토리 뷰
반응형
E1-TTS: Simple and Fast Non-Autoregressive TTS
- Efficient non-autoregressive zero-shot text-to-speech model이 필요함
- E1-TTS
- Denoising diffusion pre-training과 distribution matching distillation을 활용
- Text, audio pair 간의 explicit monotonic alignment를 제거
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- Non-Autoregressive (NAR) Text-to-Speech (TTS) model은 text로부터 speech를 parallel 하게 생성하므로, 하나의 unit 씩 합성하는 Autoregressive (AR) model 보다 빠른 추론이 가능함
- FastSpeech, FastPitch와 같은 기존의 NAR TTS은 duration predictor와 alignment supervision에 의존함
- Input text와 해당 speech 간의 monotonic alignment는 각 text unit과 associate 된 speech unit 수에 대한 information을 제공하고, learned duration predictor는 각 text unit에 대한 speech timing을 estimate 함 - 한편으로 Flow-TTS와 같이 alignment supervision, explicit duration prediction에 대한 의존성을 제거한 Implicit-Duration Non-Autoregressive (ID-NAR) TTS model을 활용할 수도 있음
- 특히 DiTTo-TTS와 같은 diffusion-based ID-NAR TTS는 zero-shot TTS에서 우수한 성능을 보임
- BUT, 해당 diffusion-based model은 high-synthesis quality를 위해 상당한 iterative sampling procedure가 필요함
- 이를 해결하기 위해 ProDiff, CoMoSpeech, FlashSpeech, VoiceFlow, ReFlow-TTS와 같이 teacher model의 sampling trajectory를 approximate 하는 distillation technique을 고려할 수 있음
- 이때 generator의 sample distribution과 data distribution 간의 divergence를 directly approximate 하면 더 나은 성능을 달성할 수 있음
- FastSpeech, FastPitch와 같은 기존의 NAR TTS은 duration predictor와 alignment supervision에 의존함
-> 그래서 distribution matching distillation을 활용한 diffusion-based ID-NAR TTS model인 E1-TTS를 제안
- E1-TTS
- Efficient inference를 위해 Distribution Matching Distillation을 적용
- Diffusion-based ID-NAR TTS model을 one-step generator로 distill
< Overall of E1-TTS >
- Distribution Matching Distillation을 활용한 one-step diffusion-based ID-NAR TTS model
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Background
- Distribution Matching Distillation
- $\mathbb{R}^{d}$의 data distribution $p(x)$를 고려해 보자
- 그러면 density $p(x)$를 Gaussian perturbation kernel $q_{t}(x_{t}|x)=\mathcal{N}(x_{t};\alpha_{t}x,\sigma_{t}^{2}I_{d})$와 convolve 하여 perturbed density $p_{t}(x_{t}):=\int p(x)q_{t}(x_{t}|x)\text{d}x$를 얻을 수 있음
- $\alpha_{t},\sigma_{t}>0$ : 각 time $t\in[0,1]$에서 signal-to-noise ratio - 일반적으로 diffuion model은 각 time $t$에서 score function $s_{p}(x_{t},t):=\nabla_{x_{t}}\log p_{t}(x_{t})$를 approximate 하는 neural network를 학습함
- 여기서 random noise $Z\sim \mathcal{N}(0,I_{d})$를 사용하여 distribution $q_{\theta}(x)$의 fake sample $\hat{X}:=g_{\theta}(Z)$를 output 하는 generator function $g_{\theta}(z):\mathbb{R}^{d}\rightarrow\mathbb{R}^{d}$를 고려하자
- 2개의 score function $s_{p}(x):=\nabla_{x}\log p(x)$와 $s_{q}(x):=\nabla_{x}\log q_{\theta}(x)$를 얻을 수 있다면, 다음과 같이 KL divergence의 gradient를 compute할 수 있음:
(Eq. 1) $ \nabla_{\theta}D_{KL}(q_{\theta}(x)||p(x))=\mathbb{E}\left[ \left(s_{q}(\hat{X})-s_{p}(\hat{X})\right)\frac{\partial g_{\theta}(Z)}{\partial \theta}\right]$ - BUT, $s_{p}(x), s_{q}(x)$를 directly obtaining하는 것은 어려우므로, diffusion model을 training 하여 perturbed distribution $p_{t}(x_{t})$와 $q_{\theta,t}(x_{t}):=\int q_{\theta}(x)q_{t}(x_{t}|x)\text{d}x$의 score function $s_{p}(x_{t},t), s_{q}(x_{t},t)$를 estimate 할 수 있음
- 그러면 모든 noise scale에서 weighted average KL divergence는:
(Eq. 2) $D_{\theta}:=\mathbb{E}_{t\sim p(t)}\left[w_{t}D_{KL}(q_{\theta,t}(x_{t})||p_{t}(x_{t} ))\right]$
- $w_{t}\geq 0$ : time-dependent weighting factor, $p(t)$ : time distribution - $W\sim\mathcal{N}(0,I_{d})$를 independent Gaussian noise라 하고, $\hat{X}_{t}:=\alpha_{t}\hat{X}+\sigma_{t}W$라고 할 때, weighted KL divergence의 gradient는:
(Eq. 3) $\nabla_{\theta}D_{\theta}=\mathbb{E}_{t\sim p(t)}\left[w_{t}\alpha_{t}\left(s_{q}(\hat{X}_{t},t)-s_{p}(\hat{X},t) \right)\frac{\partial g_{\theta}(Z)}{\partial \theta}\right]$
- [Algorithm 1]은 pre-trained score estimator $s_{\phi}(x_{t},t)\approx s_{p}(x_{t},t)$가 주어졌을 때, single-step generator $g_{\theta}$로 distill 하기 위해 사용됨
- Generator $g_{\theta}$는 randomly initialize되어야 하지만, $s_{\phi}$로 $g_{\theta}$를 initialize 하면 더 나은 성능을 얻을 수 있음
- 추가적으로 normalization layer와 같은 일부 paramter만 tuning하여 one-step generator로 convert 할 수 있음
- Distribution Matching Distillation (DMD)는 Generative Adversarial Network (GAN)과 유사하지만, 더 나은 stability와 minimal tuning을 제공하고 mode collapse 문제를 방지할 수 있음
- 그러면 density $p(x)$를 Gaussian perturbation kernel $q_{t}(x_{t}|x)=\mathcal{N}(x_{t};\alpha_{t}x,\sigma_{t}^{2}I_{d})$와 convolve 하여 perturbed density $p_{t}(x_{t}):=\int p(x)q_{t}(x_{t}|x)\text{d}x$를 얻을 수 있음

- Rectified Flow
- Rectified Flow는 neural Ordinary Differential Equation (ODE)를 구성하는데 사용됨
- 이때 ODE formulation은:
(Eq. 4) $\text{d}Y_{t}=v(Y_{t},t)\text{d}t,\,\,\,t\in[0,1]$ - 그러면 다음의 optimization problem을 solve 하여 2개의 random distribution $X_{0}\sim\pi_{0}, X_{1}\sim\pi_{1}$에 mapping 함:
(Eq. 5) $v(x_{t},t):=\arg\min_{v}\mathbb{E}\left|\left| v(\alpha_{t}X_{1}+\sigma_{t}X_{0},t)- (X_{0}-X_{1})\right|\right|_{2}^{2}$
- $\alpha_{t}=t$, $\sigma_{t}=(1-t)$ - $X_{0}\sim\mathcal{N}(0,I_{d})$, $X_{0}\perp X_{1}$인 special case에 대해, drift $v(x_{t},t)$는 score function $s(x_{t},t)=\nabla_{x_{t}}\log p_{t}(x_{t})$와 $x_{t}$의 linear combination과 같음:
(Eq. 6) $s(x_{t},t)=-\frac{1-t}{t}v(x_{t},t)-\frac{1}{t}x_{t}$
- $X_{t}:=\alpha_{t}X_{1}+\sigma_{t}X_{0}$ - 논문은 (Eq. 5)의 Rectified Flow loss를 사용하여 diffusion model을 training 함
- (Eq. 6)은 Rectified Flow model에 DMD를 적용할 수 있도록 함
- 이때 ODE formulation은:

3. Method
- E1-TTS는 full text와 partially masked speech를 input으로 하여 completed speech를 output 하는 cacaded conditional generative model에 해당함
- 특히 E1-TTS는 first stage에서 모든 speech token을 simultaneously generate 함
- 추가적으로 2개의 Diffusion Transformer (DiT)를 one-step generator로 변환하기 위해 DMD를 적용하여 inference pipeline에서 모든 iterative sampling을 제거함
- Mel Spectrogram AutoEncoder
- 논문은 log-mel-spectrogram을 24Hz에서 32-dimensional continuous token으로 compress 하는 AutoEncoder를 활용함
- 이후 해당 compressed representation을 기반으로 diffusion model을 training 하여 efficiency를 향상함
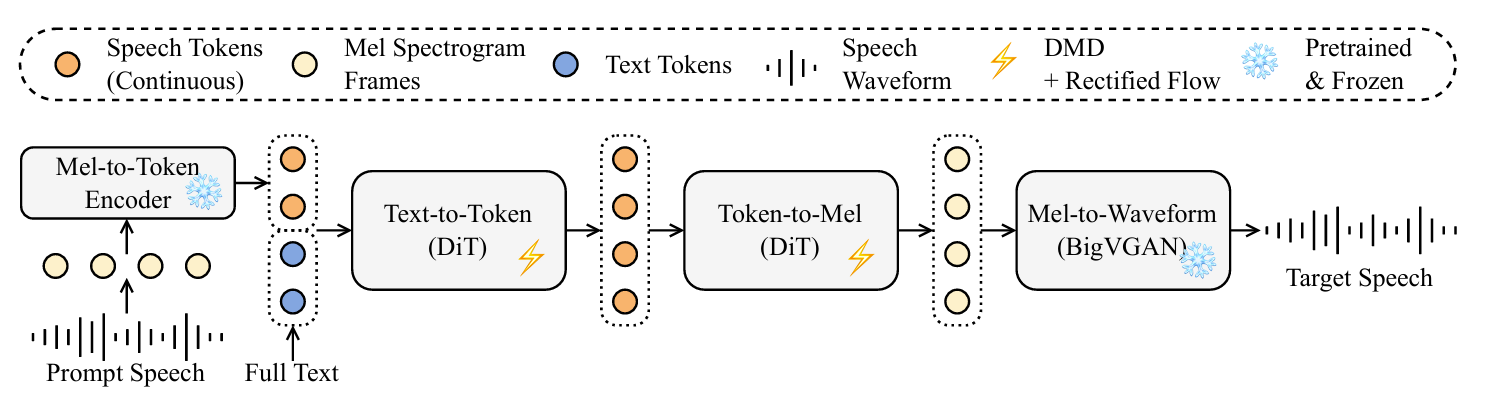
- Text-to-Token Diffusion Transformer
- Text-to-Token DiT는 full text가 주어졌을 때 input speech token의 masked part를 estimate 함
- Training 중에 speech token sequence는 prefix, masked middle, suffix의 3가지 part로 split 됨
- 이때 middle part의 length를 uniformly sample 한 다음, middle part의 beginning position을 uniformly sample 함
- 추가적으로 $10\%$의 probability로 entire speech token sequence를 masking 함
- E1-TTS의 모든 Transformer block에는 Rotary Positional Embedding (RoPE)가 적용되고, Text-to-Token model의 경우 text, speech token 간의 diagonal alignment를 위해 positional embedding을 적용함
- RoPE를 사용하면 각 token은 position index와 associate 되고 해당 token에 해당하는 embedding은 position index에 비례하는 angle로 rotate 됨
- Text token에 대해서는 increasing integer position index를 사용하고 speech token에 대해서는 fractional position index를 사용함
- 여기서 increment는 $n_{text}/n_{speech}$로 설정됨
- 해당 embedding design을 통해 text, speech 간의 diagonal initial attention pattern을 얻을 수 있음
- Training 중에 speech token sequence는 prefix, masked middle, suffix의 3가지 part로 split 됨
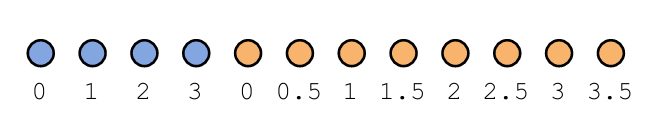
- Duration Modeling
- 기존의 ID-NAR TTS model과 마찬가지로 E1-TTS는 추론 시에 total duration이 필요함
- 이를 위해 논문은 VoiceBox와 유사한 duration predictor를 도입함
- Text, speech token 간의 rough alignment는 RAD-TTS aligner를 training 하여 얻어지고, 이후 partially masked duration을 estimate 하기 위해 regression-based duration model을 training 함 - 결과적으로 duration model은 full text (phoneme sequence)와 partially observed duration을 input으로 하여 context에 따라 unknown duration을 predict 함
- 이때 total duration에서 $L1$ difference를 minimize 하는 것이 phoneme-level duration을 directly minimize 하는 것보다 total duration error를 더욱 낮출 수 있음
- 이를 위해 논문은 VoiceBox와 유사한 duration predictor를 도입함
- Inference
- E1-TTS를 사용한 text-based speech editing은 다음과 같이 수행됨
- 먼저 original text와 speech를 forced-align 하여 original phoneme duration을 얻음
- 다음으로 duration predictor는 target phoneme sequence와 unedited phoneme의 original duration을 사용하여 target speech의 total duration을 predict 함
- 이때 original speech는 speech token으로 encode 되고 edited part에 해당하는 old token은 제거됨
- 한편으로 estimated target duration에 match 하기 위해 noise token을 추가적으로 insert 함
- 최종적으로 target text와 partially masked target speech를 Text-to-Token DiT에 전달하여 reconstructed speech token을 얻음
- 즉, unedited part의 original speech characteristic을 preserve 하면서 target text와 match 되는 edited speech output을 얻음

4. Experiments
- Settings
- Results
- 전체적으로 E1-TTS의 성능이 가장 우수함

- Text-based Speech Inpainting
- Speech inpainting 측면에서도 E1-TTS가 가장 선호됨

- Robustness to Different Speech Rate
- E1-TTS는 total duration prediction 측면에서 error tolerance를 보임

- Robustness to Hard Case
- Hard sentence에 대해서도 E1-TTS는 robust 한 합성이 가능함
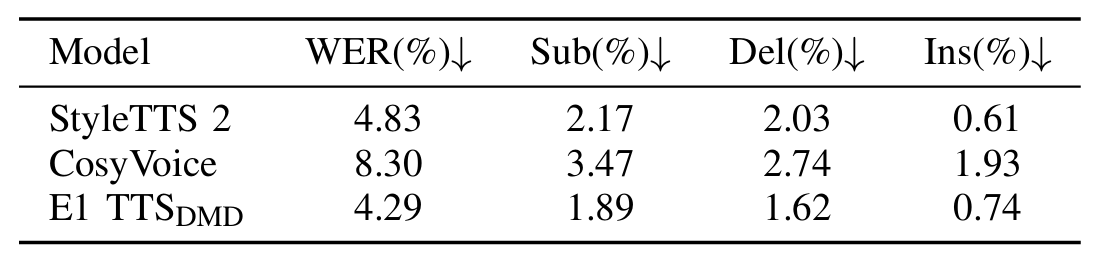
- Sample Variation
- E1-TTS는 기존보다 높은 sample diversity를 보임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글