

티스토리 뷰
Paper/TTS
[Paper 리뷰] ProsodyFM: Unsupervised Phrasing and Intonation Control for Intelligible Speech Synthesis
feVeRin 2025. 6. 15. 07:37반응형
ProsodyFM: Unsupervised Phrasing and Intonation Control for Intelligible Speech Synthesis
- 기존의 text-to-speech model은 phrasing, intonation 측면에서 한계가 있음
- ProsodyFM
- Prosody 측면에서 phrasing, intonation을 향상하기 위해 Flow Matching backbone을 활용하고 Phrase break encoder, Duration predictor, Terminal intonation encoder를 도입
- Explicit prosodic label 없이 training 되어 break duration, intonation pattern의 broad spectrum을 uncover
- 논문 (AAAI 2025) : Paper Link
1. Introduction
- Phrasing, intonation, prominence, rhythm 등의 property를 encompass 하는 prosody는 literal meaning 이상의 rich information을 convey 할 수 있음
- BUT, 대부분의 Text-to-Speech (TTS)는 phrasing, intonation의 prosody 측면에서 한계가 있음
- 먼저 phrasing은 word를 chunk로 grouping 하는 것에 해당함
- 특히 intonational phrase에는 고유한 intonation pattern을 가지는 word chunk가 포함되어 있음
- 이때 Phrase break는 intonational phrase end의 perceivable acoustic pause를 나타내고, speech intelligibility를 향상하는데 필수적임
- Phrase break는 sentence에서 phrasal organization을 imply 하므로, listener가 sentence의 syntatic structure를 accurately discern 하고 correct meaning을 deduce 할 수 있도록 함 - BUT, break label 확보의 어려움과 break duration의 variability로 인해 기존의 TTS model은 break를 miss 하거나 misplace 하는 경향이 있음
- Intonation 역시 intelligible speech를 합성하는데 필수적임
- 특히 Terminal intonation은 intonational phrase에서 last word의 intonation pattern을 나타내고, 상당한 linguistic, paralinguistic information을 포함함
- 대표적으로 sentence end의 rising terminal intonation은 uncertainty나 clarification request를 나타내고, falling intonation은 certainty나 assertion을 나타냄 - 해당 intonation change는 pitch contour를 통해 얻을 수 있지만, 대부분의 TTS model은 absolute pitch value를 directly modeling 하므로 natural intonation을 accurately capture 하기 어려움
- 아래 그림과 같이 pitch tracking에는 pitch value, unvoiced/voiced에 대한 prediction error가 존재하기 때문
- 특히 Terminal intonation은 intonational phrase에서 last word의 intonation pattern을 나타내고, 상당한 linguistic, paralinguistic information을 포함함
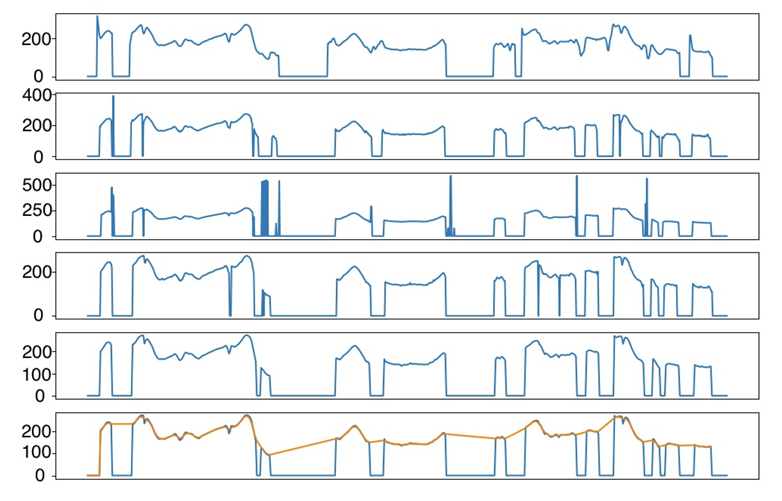
-> 그래서 phrasing, intonation modeling을 향상한 prosody-aware TTS model인 ProsodyFM을 제안
- ProsodyFM
- Flow Matching (FM) backbone을 채택하여 unsupervised manner로 prosody를 향상
- Phrase modeling 측면에서는, Phrase Break Encoder를 통해 initial break location을 capture하고 break duration을 adjust 하기 위해 Duration Predictor를 도입
- Intonation modeling 측면에서는, Pitch Processor를 통해 pitch tracking error를 완화하고 pitch shape에 대한 robust modeling을 지원
< Overall of ProsodyFM >
- Flow Matching framework를 기반으로 phrasing, intonation modeling을 향상한 prosody-aware TTS model
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
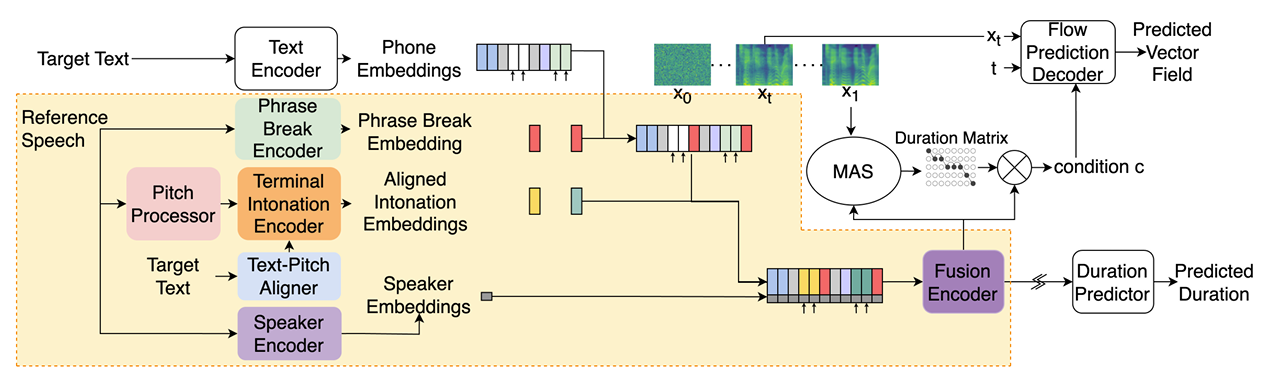
- ProsodyFM은 reference speech에서 phrasing, terminal intonation pattern을 추출하고 해당 pattern을 target text와 match 할 수 있도록 adjust 함
- 구조적으로는 MatchaTTS backbone을 채택하여 Optimal-Transport Conditional Flow Matching (OT-CFM)을 기반으로 training 됨
- 먼저 Pitch Predictor는 robust pitch shape segment를 추출함
- Phrase Break Encoder는 initial phrase break location을 predict 하고, speaker information과 combine 되어 Duration Predictor를 통해 duration으로 refine 됨
- Text-Pitch Aligner는 target text에서 intonation pattern을 estimate 하여 reference intonation pattern selection을 guide 함
- Terminal Intonation Encoder는 target text와 align 된 terminal intonation pattern을 modeling 함
- 이때 ProsodyFM은 raw text로부터 mel-spectrogram을 predict 하고 HiFi-GAN을 통해 waveform으로 변환함
- 한편으로 training 시 reference speech는 ground-truth로 사용되어 target text와 match 되지만, 추론 시에는 target text가 reference speech의 transcript와 match 되지 않음
- 구조적으로는 MatchaTTS backbone을 채택하여 Optimal-Transport Conditional Flow Matching (OT-CFM)을 기반으로 training 됨
- Pitch Processor
- Pitch Processor는 interpolation, smoothing, perturbation의 3가지 operation을 통해 last word의 robust pitch shape segment를 추출함
- 먼저 pitch tracking에서 discrete, unreliable raw pitch value를 continuous contour로 interpolate, smooth 함
- 이후 pitch shape를 emphasize 하기 위해 각 contour point에서 random offset을 substract 하여 specific value information을 perturbing 하고 shape pattern을 preserve 함
- Random offset은 $[f_{\min},f_{\max}]$로부터 uniformly sample 됨
- Phrase Break Encoder
- Phrase Break Encoder는 pharse break의 발생을 predict 하여 각 intonational phrase의 last word를 locate 함
- 해당 last word location은 Pitch Processor와 Text-Pitch Aligner가 해당하는 pitch shape segment, word embedding을 select 할 수 있도록 guide 함
- Training 중에 Phrase Break Encoder는 reference speech에서 phrase break를 identify 하기 위해 froze Phrase Break Detector를 사용함
- 추론 시 aligned reference speech가 inavailable 한 경우, T5에서 fine-tuning 된 Phrase Break Predictor를 사용하여 plain target text로부터 breaks를 directly infer 함
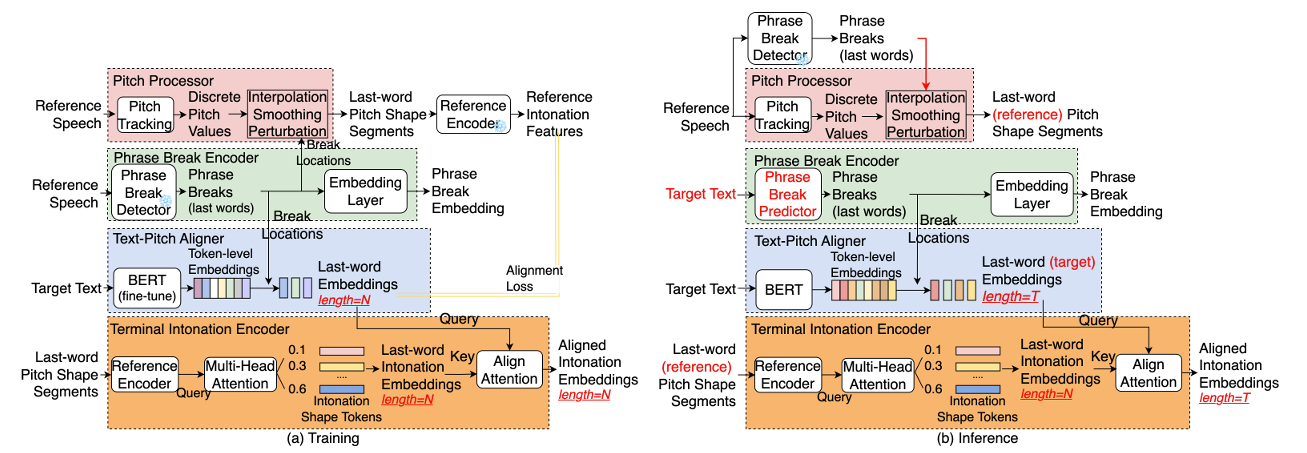
- Text-Pitch Aligner
- Text-Pitch Aligner는 추론 시 matched speech 없이도 target text의 intonation pattern을 predict 할 수 있음
- 이를 위해 논문은 BERT-derived word embedding과 Reference Encoder에서 추출된 reference intonation feature 간의 $L2$ loss를 minimize 하여 BERT를 fine-tuning 함
- Reference Encoder는 Terminal Intonation Encoder와 identical 하지만 gradient flow를 방지하기 위해 detach 됨 - 이후 predicted BERT embedding은 Terminal Intonation Encoder에서 suitable reference intonation pattern의 selection을 gudie 하는 데 사용됨
- 이를 위해 논문은 BERT-derived word embedding과 Reference Encoder에서 추출된 reference intonation feature 간의 $L2$ loss를 minimize 하여 BERT를 fine-tuning 함
- Terminal Intonation Encoder
- Terminal Intonation Encoder는 target text에 align 된 terminal intonation pattern을 추출함
- Reference Encoder는 reference speech에서 last word의 pitch shape segment를 fixed-length intonation feature로 compress 하여 multi-head attention module의 query로 사용함
- 이때 attention module은 reference intonation feature와 intonation shape token bank 간의 similarity를 학습함
- 해당 token은 다양한 intonation pattern을 capture하고 represent 하는 learnable codebook으로 사용됨
- 여기서 token은 OT-CFM loss로 training되므로 annotated intonation label이 필요하지 않음 - 결과적으로 multi-head attention module은 token에 대한 weight를 생성하고, wegithed sum은 reference speech의 last-word intonation embedding을 생성함
- 한편으로 추론 시에는 reference speech가 target text와 align 되지 않으므로, reference speech의 last word 수와 target text의 last word 수가 다를 수 있음
- 따라서 논문은 scaled dot-product attention (Align Attention module)을 사용하여 reference speech에서 target text에 best suit 한 terminal intonation pattern을 select 함
- 이를 위해 reference speech의 last word intonation을 key/value로, target text의 last word embedding을 query로 사용함 - 해당 alignment를 통해 ProsodyFM은 추론 시 reference speech와 target text를 기반으로 terminal intonation pattern을 autononmously choice 할 수 있음
- 따라서 논문은 scaled dot-product attention (Align Attention module)을 사용하여 reference speech에서 target text에 best suit 한 terminal intonation pattern을 select 함
- Reference Encoder는 reference speech에서 last word의 pitch shape segment를 fixed-length intonation feature로 compress 하여 multi-head attention module의 query로 사용함
- Mel-Spectrogram Generation
- 추론 시 Fusion Encoder는 phrase break, aligned intonation embedding, speaker phone embedding을 combine 하여 phone-level prior statistics를 생성함
- Duration Predictor는 각 phone과 phrase break의 optimal duration을 결정하여 frame-level condition $c$를 얻음
- 이후 $c$, sample time $t$, $x_{t}$가 주어지면, Flow Prediction Decoder는 target vector field를 predict 함
- 최종적으로 ODE Solver는 해당 predicted vector field를 사용하여 mel-spectrogram을 생성함
3. Experiments
- Settings
- Dataset : LibriTTS, VCTK
- Comparisons : StyleSpeech, GenerSpeech, StyleTTS2, MatchaTTS
- Results
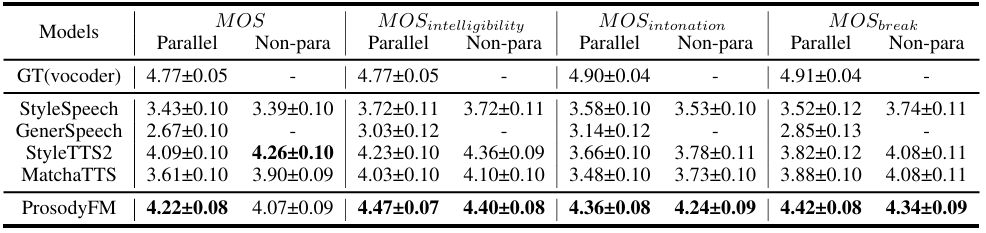
- 전체적으로 ProsodoyFM의 성능이 가장 우수함
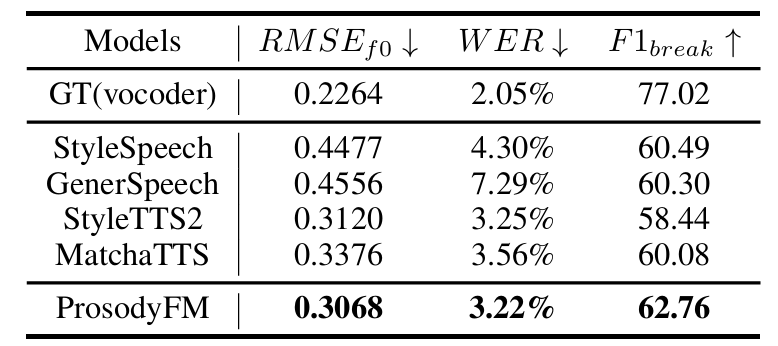
- MOS 측면에서도 ProsodyFM이 가장 뛰어남
- Model Generalizability
- ProsodyFM은 Out-of-Distribution dataset에 대해서도 우수한 성능을 달성함

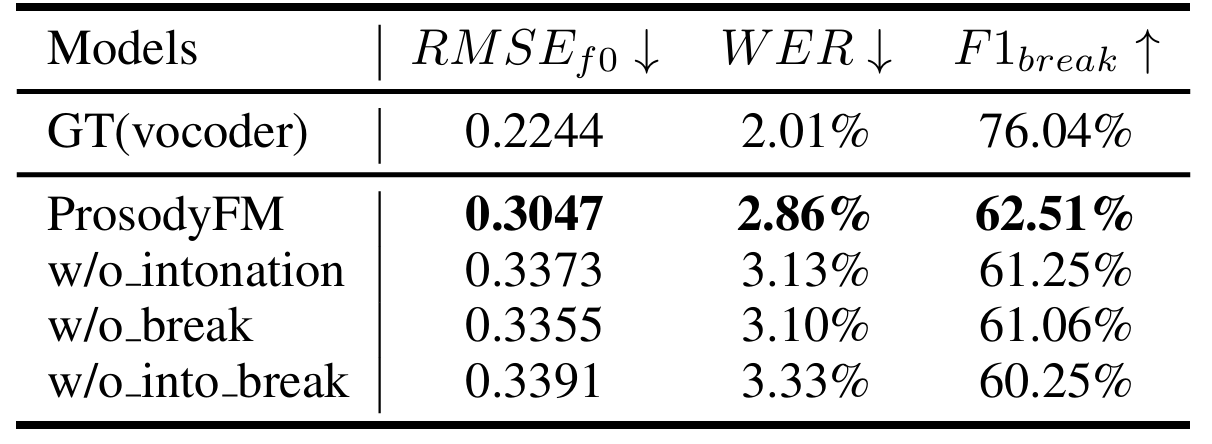
- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함
- Prosody Controllability
- Intonation control 측면에서 level tone이 reference로 제공되면 flat pitch contour가 나타남
- Rising/falling tone이 제공되면 마찬가지로 upward/downward movement가 나타남 - Phrasing control 측면에서 ProsodyFM은 noticeable blank를 반영할 수 있음
- Intonation control 측면에서 level tone이 reference로 제공되면 flat pitch contour가 나타남

반응형
'Paper > TTS' 카테고리의 다른 글
댓글