

티스토리 뷰
Paper/TTS
[Paper 리뷰] FACTSpeech: Speaking a Foreign Language Pronunciation Using Only Your Native Characters
feVeRin 2025. 6. 10. 17:44반응형
FACTSpeech: Speaking a Foreign Language Pronunciation Using Only Your Native Characters
- 대부분의 text-to-speech model은 transliterated text를 고려하지 않음
- FACTSpeech
- Input text의 pronunciation을 native, literal pronunciation으로 변환하는 language shift embedding을 도입
- Speaker identity를 preserve 하면서 pronunciation을 향상하기 위해 conditional instance normalization을 적용
- 논문 (INTERSPEECH 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 input text로부터 natual speech를 생성하는 것을 목표로 함
- 최근의 CrossSpeech는 2개 이상의 language를 가지는 language-mixed sentence를 처리하기 위해 monolingual TTS를 multilingual TTS로 expand 함
- BUT, bilingual, parallel speech corpus를 확보하기 어려우므로 대부분의 language-mixed TTS model은 서로 다른 language의 monolingual training data를 기반으로 구축됨
- Monolingual dataset은 speaker identity가 linguistic information에 entangle 되어 있으므로 target language representation으로 replace 할 때 speaker identity preserving이 어려움
- 한편으로 SANE-TTS는 이를 해결하기 위해 Domain Adversarial Training을 채택함
- Language-mixed sentence는 code-mixed, transliterate의 2가지 형태를 가짐
- 이때 기존 TTS model은 대부분 code-mixed sentence를 기반으로 하지만, real-world scenario에서는 transliterate 방식을 일반적으로 사용함
- 최근의 CrossSpeech는 2개 이상의 language를 가지는 language-mixed sentence를 처리하기 위해 monolingual TTS를 multilingual TTS로 expand 함
-> 그래서 transliterate 기반의 TTS model인 FACTSpeech를 제안
- FACTSpeech
- Native, literal language 간의 pronunciation을 control 하면서 transliterated speech로부터 synthesis를 수행
- 즉, target language에 대한 prior knowledge 없이 native pronunciation을 얻을 수 있음 - Transliterated transcript를 학습하기 위해 Transliteration-based Data Augmentation (TDA)를 도입하고, Language Shift Embeddding (LSE)를 사용해 language 간의 relationship을 학습
- 추가적으로 speaker identity를 preserve 하면서 pronunciation accuracy를 향상하기 위해 Conditional Instance Normalization (CIN)을 채택
- Native, literal language 간의 pronunciation을 control 하면서 transliterated speech로부터 synthesis를 수행
< Overall of FACTSpeech >
- Transliterate 기반의 foreign-accent controllable TTS model
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
- FACTSpeech는 FastPitch를 기반으로 text encoder, variance predictor, decoder로 구성됨
- Variance predictor는 pitch, energy, duration predictor를 가짐
- 이때 multi-speaker conditioning을 위해 variance predictor에 speaker lookup table을 적용하여 speaker representation을 얻음 - 추가적으로 native pronunciation을 위해 decoder에 CIN을 추가함
- Variance predictor는 pitch, energy, duration predictor를 가짐

- Text Encoder
- FACTSpeech는 text embedding을 input으로 사용함
- 여기서 text embedding은 language-dependent grapheme sequence와 lookup table을 통해 얻어짐
- Text embedding은 positional encoding과 LSE에 add 되고 text encoder에 전달되고, text encoder는 hidden linguistic representation $h_{text}$를 생성함
- Pitch and Energy Predictor
- FACTSpeech는 FastPitch를 extend 하여 energy predictor와 pitch predictor를 도입함
- Pitch/energy predictor는 $h_{text}$에 각각 pitch/energy information을 제공함
- Pitch/energy embedding은 predicted value를 single 1D convolutional layer에 전달하여 얻어지고, predicted pitch/energy embedding은 $h_{text}$에 add 됨 - Pitch predictor는 pyin algorithm에 의해 추출된 predicted, ground-truth pitch value 간의 Mean Square Error (MSE)로 optimize 되고, energy predictor 역시 predicted, ground-truth energy value 간의 MSE로 optimize 됨
- Ground-truth energy value는 각 mel-spectrogram frame의 amplitude에서 $L2$ normalization을 통해 compute 됨
- 이때 각각의 loss function은:
(Eq. 1) $\mathcal{L}_{pitch}=\text{MSE}(x_{pitch},\hat{x}_{pitch})$
(Eq. 2) $\mathcal{L}_{energy}=\text{MSE}(x_{energy},\hat{x}_{energy})$
- $ \text{MSE}(x,\hat{x})=\frac{1}{T}\sum_{t=1}^{T}(x(t)-\hat{x}(t))^{2}$
- $x,\hat{x}$ : 각각 ground-truth, predicted value, $T$ : sequence length
- Pitch/energy predictor는 $h_{text}$에 각각 pitch/energy information을 제공함
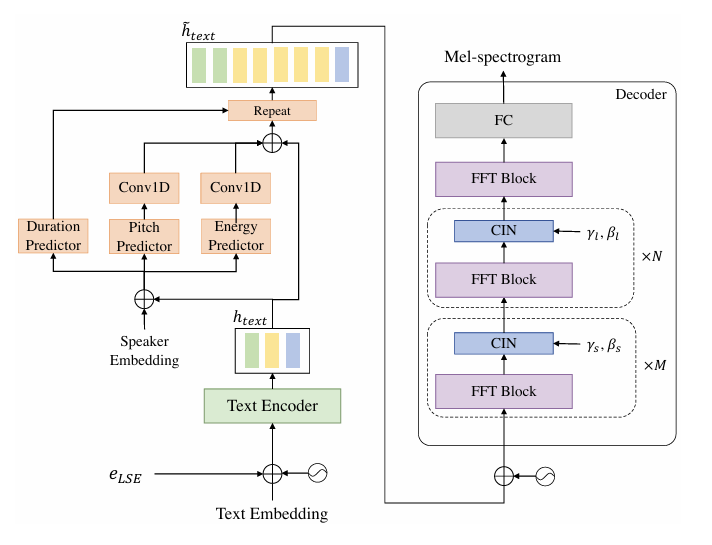
- Duration Predictor with Online Aligner
- Linguistic, acoustic representation 간의 length를 match 하기 위해 duration predictor를 도입함
- Duration predictor는 speaker embedding으로 condition 되어 $h_{text}$를 input으로 사용해 token duration을 predict 함
- Predicted duration은 pitch, energy embedding과 combine 된 $h_{text}$ upsampling에 사용됨
- Duration predictor는 predicted duration과 ground-truth duration 간의 MSE loss를 통해 optimize 됨:
(Eq. 3) $\mathcal{L}_{duration}=\text{MSE}(x_{duration},\hat{x}_{duration})$
- $x_{duration},\hat{x}_{duration}$ : target, predicted duration
- Target duration value는 online duration search algorithm을 통해 추출됨
- 이는 language-specific external aligner에 의존하지 않으므로 다른 language로 easily extend 될 수 있음 - 여기서 $\mathcal{L}_{ForwardSum}, \mathcal{L}_{bin}$은 online aligner를 optimize 하는 데 사용됨
- $\mathcal{L}_{ForwardSum}$은 주어진 mel-spectrogram $X$에 대한 input text $S$의 likelihood를 maximize 하는 connectionist temporal classification loss를 통해 얻어짐
- $\mathcal{L}_{bin}$은 soft alignment $A_{soft}$를 hard alignment $A_{hard}$에 close 하기 위해 사용되고, 두 alignment 간의 KL-divergence로 얻어짐
- 결과적으로 두 loss의 formulation은:
(Eq. 4) $\mathcal{L}_{ForwardSum}=-\log P(S|X)$
(Eq. 5) $\mathcal{L}_{bin}=D_{KL}(A_{soft}||A_{hard})$
- $A_{soft}$ : text, mel-spectrogram representation의 $L2$ distance에 대한 softmax를 취하여 얻어지고, 이때 각 representation은 text, mel-spectrogram을 1D convolutional layer에 전달하여 얻어짐
- Viterbi algorithm을 적용하면 $A_{soft}$는 target duration을 represent 하는 $A_{hard}$로 convert 됨
- 최종적으로 alginment loss는 $\mathcal{L}_{align}=\mathcal{L}_{ForwardSum}+\mathcal{L}_{bin}$과 같이 얻어짐
- Duration predictor는 speaker embedding으로 condition 되어 $h_{text}$를 input으로 사용해 token duration을 predict 함
- Decoder
- Decoder는 Feed-Forward Transformer (FFT) block을 기반으로 구성되고, upsampled hidden representation $\tilde{h}_{text}$를 input으로 하여 mel-spectrogram을 predict 함
- 이때 top layer의 hidden vector는 language information을 학습하고, bottom layer는 speaker information을 학습하는 경향이 있음
- 이를 기반으로 이후 논문은 CIN을 통해 decoder를 conditioning 함 - 한편으로 predicted mel-spectrogram에 대한 reconstruction loss는:
(Eq. 6) $\mathcal{L}_{mel}=\text{MSE}(y_{mel},\hat{y}_{mel})$
- $y_{mel}$ : ground-truth mel-spectrogram, $\hat{y}_{mel}$ : predicted mel-spectrogram - 그러면 overall training loss는:
(Eq. 7) $\mathcal{L}_{total}=\mathcal{L}_{mel}+\lambda_{p}\mathcal{L}_{pitch}+\lambda_{e}\mathcal{L}_{energy}+\mathcal{L}_{duration}+\mathcal{L}_{align}$
- $\lambda_{p},\lambda_{e}=0.1$
- 이때 top layer의 hidden vector는 language information을 학습하고, bottom layer는 speaker information을 학습하는 경향이 있음
3. Multilingual TTS Extension
- 논문은 transliteration-based data augmentation과 Language Shift Embedding (LSE)를 활용함
- 이를 통해 target foreign language에 대한 knowledge 없이도 natural pronunciation을 합성하도록 함
- 추가적으로 pronunciation accuracy를 향상하고 speaker identity를 preserve 하기 위해 Conditional Instance Normalization (CIN)을 도입함
- Transliteration-based Data Augmentation
- Transliteration은 source language script에서 target language와의 phonetic similarity에 기반하여 mapping을 수행함
- 이때 transliteration-based data augmentation은 transliterated text와 target language pronunciation 간의 relationship을 학습할 수 있도록 함
- BUT, synthesized speech pronunciation은 training data에 의해 결정되므로 pronunciation style control이 부족하고 input text에만 의존할 수 있음
- 따라서 이를 해결하기 위해 LSE를 도입함
- Language Shift Embedding (LSE)
- LSE는 transliterated data에서 native pronunciation을 학습하도록 하는 learned embedding으로써 entire model과 함께 training 되어 total loss를 minimize 하도록 training 됨
- Training 중에 FACTSpeech는 LSE와 해당 text embedding을 associate 하는 방법을 학습하고, 이를 통해 input text representation을 다른 language domain으로 shift 할 수 있음
- 추가적으로 language $A$에서 language $B$로 transliterate 된 script를 training 할 때 LSE $e_{LSE}^{A2B}$가 해당 text embedding에 add 됨
- 이를 통해 model은 LSE와 text embedding 간의 learned association을 활용하여 language $B$의 native pronunciation을 생성할 수 있음
- 마찬가지로 language $B$에서 language $A$로 transliterate 된 script를 training 할 때 LSE $e_{LSE}^{B2A}$는 $e_{LSE}^{A2B}$의 negative로 compute 됨
- Conditional Instance Normalization (CIN)
- Pronunciation accuracy를 향상하고 speaker identity를 preserve 하기 위해, 논문은 decoder training을 guide 하는 CIN을 도입함
- CIN은 desired information을 활용하여 hidden state를 regulate 할 수 있음
- 먼저 channel 수 $C$, sequence length $T$에 대해, $\mathbf{X}\in\mathbb{R}^{C\times T}$를 decoder hidden state라고 하자
- Language, speaker information에 대한 learnable affine parameter $\{\gamma_{l},\beta_{l}\}, \{\gamma_{s},\beta_{s}\}$는 $\mathbf{X}$를 regulate 하는 데 사용됨
- 이를 통해 hidden state가 specific language, speaker style에 의해 guide 되도록 함 - 그러면 CIN의 formulation은:
(Eq. 8) $\text{CIN}(x_{c})=\gamma_{c}\frac{x_{c}-\mu_{c}}{\sigma_{c}}+\beta_{c}$
- $\mu_{c}=\frac{1}{T}\sum_{t=1}^{T}x_{t}^{c}$, $\sigma_{c}=\sqrt{\frac{1}{T}\sum_{t=1}^{T}(x_{t}^{c}-\mu_{c})+\epsilon}$
- $\mathbf{x}_{c}^{t}\in\mathbf{X}$ : $\mathbf{X}$에서 $c$-th channel, $t$-th time step의 scalar value
- $T$ : hidden sequence length
- Language, speaker information에 대한 learnable affine parameter $\{\gamma_{l},\beta_{l}\}, \{\gamma_{s},\beta_{s}\}$는 $\mathbf{X}$를 regulate 하는 데 사용됨
- CIN은 desired information을 활용하여 hidden state를 regulate 할 수 있음
4. Experiments
- Settings
- Dataset : English, Korean Dataset (internal)
- Comparisons : SANE-TTS
- Results
- 전체적으로 FACTSpeech가 가장 우수한 성능을 달성함

- Spoken Language Identification
- FACTSpeech는 서로 다른 language를 효과적으로 classify 할 수 있음

- Speaker-Language Disentanglement
- TDA를 적용하는 경우 text representation으로부터 speaker information을 제거할 수 있음

- Pronunciation Control Between Languages
- LSE를 적용하면 pronunciation style을 control 할 수 있음

반응형
'Paper > TTS' 카테고리의 다른 글
댓글