

티스토리 뷰
Paper/TTS
[Paper 리뷰] Flow-TTS: A Non-Autoregressive Network for Text to Speech Based on Flow
feVeRin 2024. 2. 6. 11:29반응형
Flow-TTS: A Non-Autoregressive Network for Text to Speech Based on Flow
- Non-autoregressive Text-to-Speech를 위해 generative flow를 활용할 수 있음
- Flow-TTS
- Single feed-forward network 만을 사용하여 고품질의 음성을 합성
- Spectrum 생성을 위해 flow를 활용하고 single network를 통해 alignment와 spectrogram 생성을 jointly learn
- 논문 (ICASSP 2020) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 input text sequence $\{ x_{1}, x_{2}, ..., x_{N}\}$로부터 output acoustic sequence $\{ y_{1}, y_{2}, ..., y_{T}\}$를 생성함
- Concatenative TTS와 statistical TTS는 pipeline이 복잡하고 부자연스러운 음성을 생성하는 단점이 있음
- End-to-End TTS는 이러한 한계를 극복할 수 있고, 두 부분으로 구성됨
- Normalized text symbol을 mel-spectrogram과 같은 time-aligned feature로 변환하는 spectrogram generation network
- Time-aligned feature를 audio로 변환하는 vocoder
- 논문에서는 spectrogram generation network 구성에 집중하고 vocoder로써는 WaveGlow를 채택
- 이때 spectrogram generation network는 아래와 같이 2가지 범주로 분류할 수 있음
- Autoregressive model
- 높은 음성 품질을 달성할 수 있지만, 느린 decoding 속도를 가짐
- Teacher forcing technique을 활용하여 학습 과정을 개선할 수 있지만, 예측 분포와 실제 data 분포 간의 mismatch가 발생할 수 있음 - Non-autoregressive model
- Autoregressive model에 비해서는 추론 속도를 크게 개선할 수 있지만, text sequence와 spectrogram sequence 사이의 alignment를 학습하는 것이 어려움
- 결과적으로 well-trained autoregressive teacher를 통한 guide가 필요하기 때문에 학습 과정이 복잡해짐
- Autoregressive model
-> 그래서 non-autoregressive TTS의 한계를 극복하기 위해 generative flow를 활용한 Flow-TTS를 제안
- Flow-TTS
- Generative flow (Glow)를 활용하여 효율적인 density 추정과 sampling을 지원
- Teacher model에 기반한 parameter distillation을 사용하지 않고 single feed-forward network만을 활용
- Single feed-forward network를 통해 alignment, spectrogram generation을 jointly learning
< Overall of Flow-TTS >
- Generative flow를 TTS에 활용하는 최초의 시도
- Single feed-forward network를 통해 alignment와 spectrogram generation을 jointly learn
- 결과적으로 기존 autoregressive model 보다 우수한 합성 품질을 달성

2. Flow-Baed Generative Model
- Flow-based generative model은 invertible transform의 sequence를 적용하여 Guassian 분포와 같은 단순한 probability density를 복잡한 density로 변환하는 것
- Random variable $\mathbf{z}$와 known probability density function $\mathbf{z} \sim \pi(\mathbf{z})$가 주어졌을 때,
- Flow-based generative model은 transformation function의 sequence $f=f_{1} \circ f_{2} \circ ... \circ f_{L}$을 사용하여 $\mathbf{z}$를 새로운 random variable $\mathbf{y}$에 mapping
- 이때 $\mathbf{y}$는 동일한 dimension을 가지고, 각 $f_{i}$는 invertible 함 - 여기서 $\mathbf{y}$의 probability density function은 variable transformation을 통해 계산됨:
(Eq. 1) $\log p_{Y}(\mathbf{y}) = \log \pi(\mathbf{z})+\sum_{i=1}^{L} \log \left| \det \frac{\partial f_{i}}{\partial f_{i-1}} \right|$
- $\det \frac{\partial f_{i}}{\partial f_{i-1}}$ : $f_{i}$의 Jacobian determinant - 이때 효율적인 계산을 위해 flow-based generative model은 triangular matrix를 Jacobian transformation으로 사용하고, $\pi(\mathbf{z})$로써 isotropic Gaussian을 사용
- 이를 통해 flow-based generative model은 (Eq. 1)을 최대화함으로써 high-dimensional data를 모델링함
- Random variable $\mathbf{z}$와 known probability density function $\mathbf{z} \sim \pi(\mathbf{z})$가 주어졌을 때,
3. Flow-TTS
- Flow-TTS는 generative flow (Glow)를 기반으로 함
- 전체 architecture는 Encoder, Decoder, Length predictor, Positional attention layer로 구성됨
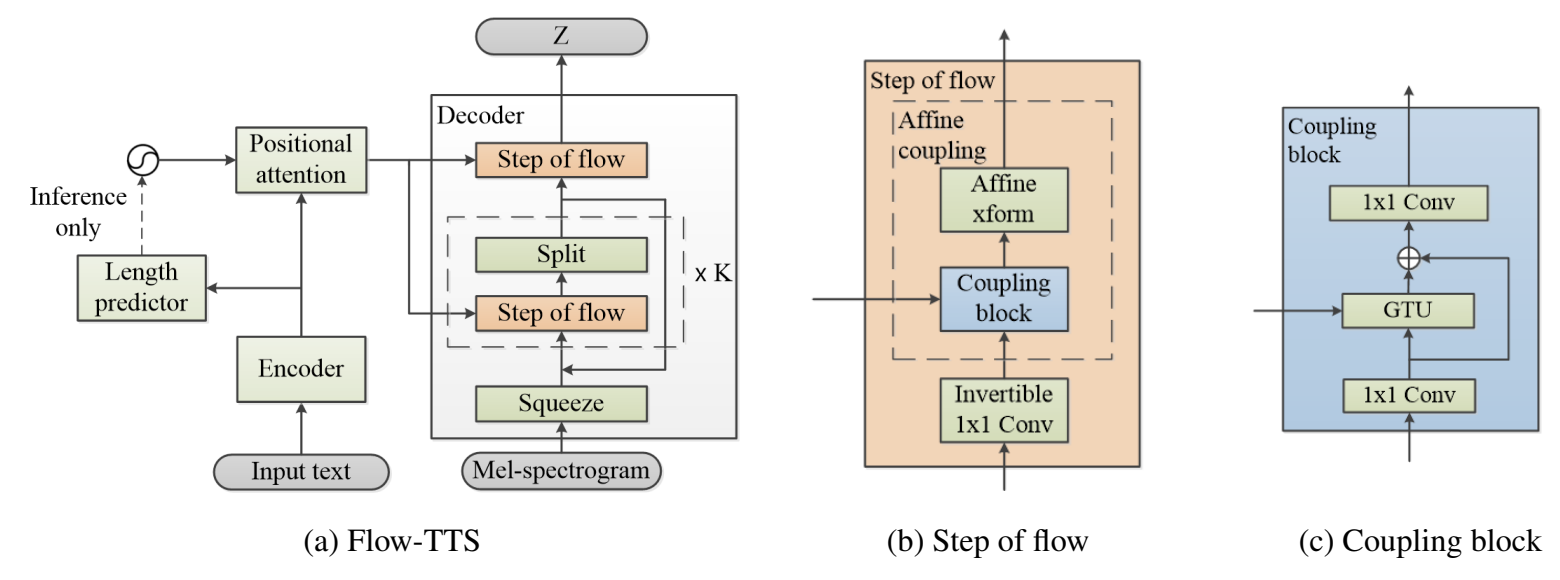
- Encoder
- Encoder는 text symbol을 trainable embedding으로 변환한 다음, convolution block을 적용함
- 각 convolution block은 1D convolution layer, ReLU activation, Batch Normalization, Dropout으로 구성됨
- 추가적으로 long-range textual inforamtion을 추출하기 위해 encoder 끝에 LSTM layer가 사용됨
- Text length는 output spectrogram length 보다 훨씬 짧으므로 LSTM은 추론 속도에는 영향을 미치지 않으면서 model의 수렴성을 크게 개선할 수 있음
- Length Predictor
- Length predictor는 output spectrogram sequence의 length를 예측하는 데 사용됨
- Autoregressive model은 special stop token을 사용하여 length를 예측할 수 있지만, Flow-TTS는 output frame을 병렬로 예측하기 때문에 sequence length를 미리 예측해야 함
- 구조적으로는 2-layer 1D convolution network로 구성되고 각 network는 Layer Normalization, Dropout을 포함
- 추가적으로 length predictor의 끝에는 accumulated layer가 사용되어 모든 symbol duration을 final length까지 accumulate 함
- Length predictor는 encoder 다음에 위치하여 안정적인 학습을 위해 logarithmic doamin에서 length를 예측
- Positional Attention
- Positional attention은 input text sequence와 output spectrogram sequence 간의 alignment를 학습
- 이를 위해 multi-head dot-product attention mechanism을 적용
- Encoder의 output hidden state를 key, value로, spectrogram length의 positional encoding을 query로 사용 - 학습 과정에서 spectrogram length는 ground-truth spectrogram으로부터 얻어지고 추론 시에는 length predictor에 의해 예측됨
- 이를 위해 multi-head dot-product attention mechanism을 적용
- Decoder
- Decoder는 multi-scale architecture와 일련의 flow step들로 구성된 Glow architecture를 활용
- 각 flow step은 2개의 invertible transformation layer, invertible $1 \times 1$ convolution, affine coupling layer로 구성
- Positional attention layer에서 생성된 condition을 flow에 공급하는 coupling block을 활용
- 이러한 squeeze operation을 위해 8의 group size를 사용하여 spectrogram을 grouping 함
- Affine Coupling Layer
- Affine coupling layer는 forward/reverse가 모두 계산 효율적이고 log-determinant를 가지는 invertible transformation으로:
(Eq. 2) $\mathbf{z}_{a}, \mathbf{z}_{b} = split(\mathbf{z})$
(Eq. 3) $(\log \mathbf{s},\mathbf{t}) = NN(\mathbf{z}_{b})$
(Eq. 4) $\mathbf{s}=\exp(\log \mathbf{s})$
(Eq. 5) $\mathbf{y}_{a} = \mathbf{s}\cdot \mathbf{z}_{a}+\mathbf{t}$
(Eq. 6) $\mathbf{y}_{b} = \mathbf{z}_{b}$
(Eq. 7) $\mathbf{y} = concat(\mathbf{y}_{a}, \mathbf{y}_{b})$
- $split()$ : input tensor를 절반으로 split, $concat()$ : output tensor concatenation
- $NN()$ : non-linear transformation
- Affine coupling layer는 forward/reverse가 모두 계산 효율적이고 log-determinant를 가지는 invertible transformation으로:
- Invertible $1\times 1$ Convolutional Layer
- Channel ordering을 permute 하기 위해 $1\times 1$ invertible convolution layer가 affine coupling layer 앞에 적용됨
- 이때 weight matrix를 log-determinant가 0인 random orthogonal matrix로 initialize
- Multi-Scale Architecture
- Multi-scale architecture는 deep flow step을 학습하는데 유용함
- Flow-TTS는 4 step flow를 활용 - 각 scale 후에 tensor의 일부 channel이 flow step에서 drop 되고, 모든 flow step이 지난 다음 한 번에 concatenate 됨
- Multi-scale architecture는 deep flow step을 학습하는데 유용함
- Coupling Block
- Coupling block은 $NN()$ transformation의 역할을 수행함
- Coupling block은 kernel size 1의 1D convolution layer와 Gated Tanh Unit (GTU) layer로 구성됨:
(Eq. 8) $\mathbf{z} = \tanh (\mathbf{W}_{f,k}*\mathbf{y}) \odot \sigma(\mathbf{W}_{g,k}*\mathbf{c})$
- $k$ : layer index, $f$ : filter, $g$ : gate, $c$ : attention context vector
- $\mathbf{W}$ : 1D convolution layer - Deep network 구성을 위해 GTU layer에는 residual connection이 사용됨
- 이후 channel size를 맞추기 위해 kernel size가 1인 1D convolution layer가 끝에 추가됨
- 마지막 convolution layer의 weigh는 0으로 initialize 되어 각 affine coupling layer가 초기에 identity function으로 동작하도록 함
3. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : FastSpeech, Tacotron2
- Results
- MOS 측면에서 합성 품질을 비교해 보면, Flow-TTS가 가장 우수한 성능을 보이는 것으로 나타남

- Mel-Cepstral Distortion (MCD) 측면에서 정량적인 평가를 수행해 보면, 마찬가지로 Flow-TTS가 가장 우수한 성능을 기록

- 합성된 mel-spectrogram을 ground-truth와 비교해 보면Flow-TTS로 합성된 음성의 prosody는 ground-truth와 유사하게 나타남

- F0 trajectory 측면에서도 Flow-TTS는 ground-truth와 가장 비슷한 결과를 보임
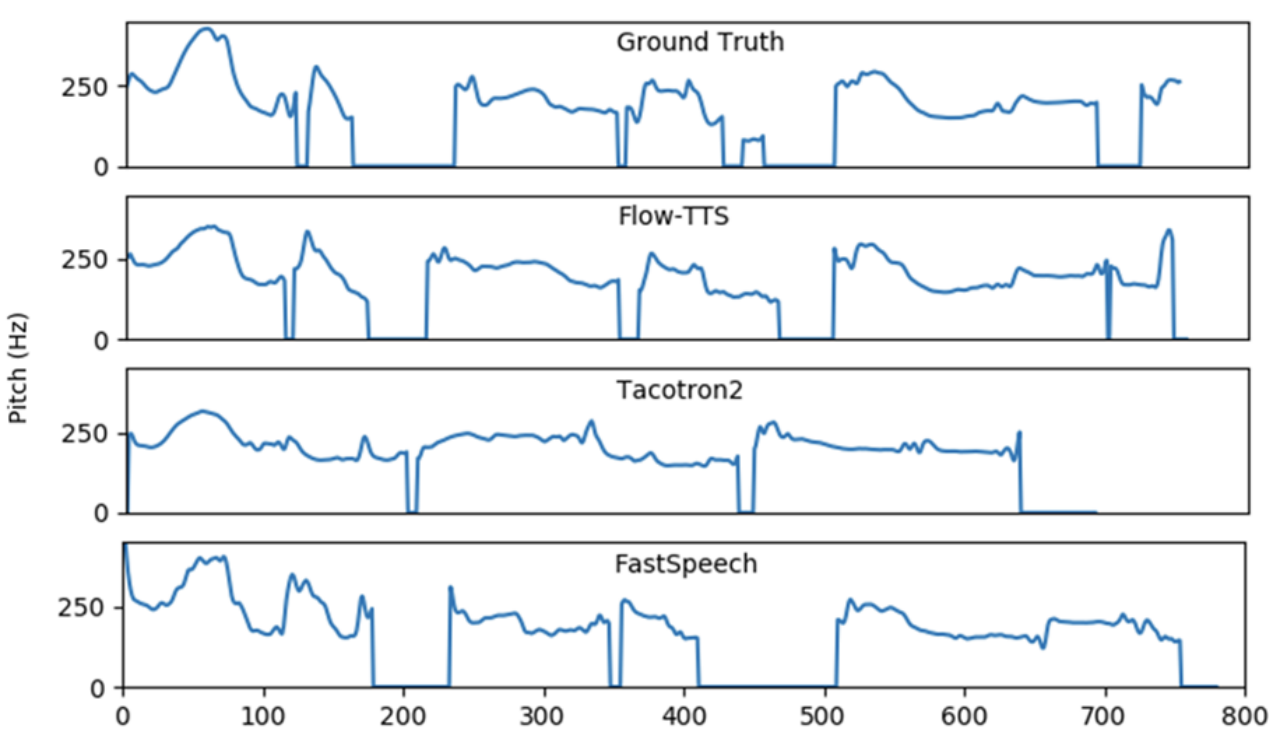
- 추론 속도 측면에서 Flow-TTS의 latency는 0.021초인 반면 Tacotron2는 0.483초로, 23배의 가속 효과를 얻을 수 있음
- FastSpeech의 0.025초와 비교했을 때도 Flow-TTS가 근소하게 더 우수한 추론 속도를 보임
반응형
'Paper > TTS' 카테고리의 다른 글
댓글