

티스토리 뷰
Paper/TTS
[Paper 리뷰] CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
feVeRin 2024. 4. 28. 12:14반응형
CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
- Denoising Diffusion Probabilistic Model은 음성 합성에서 우수한 성능을 보이고 있지만, 고품질의 sample을 얻기 위해서는 많은 iterative step이 필요함
- 결과적으로 추론 속도 저하로 이어짐 - CoMoSpeech
- Single diffusion sampling step만으로 고품질의 합성을 수행하는 Consistency model-based 음성 합성 모델
- Consistency constraint는 diffusion-based teacher model에서 consistency model을 distill 하기 위해 사용됨
- 논문 (MM 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS)와 Singing Voice Synthesis (SVS) 모두 realistic audio를 합성하는 것을 목표로 함
- 일반적으로 two-stage pipeline으로 구성되어 acoustic model이 text 등의 information을 mel-spectrogram과 같은 acoustic feature로 변환한 다음, vocoder를 통해 waveform으로 변환함
- 이때 acoustic model에 의해 생성된 mel-spectrogram과 같은 acoustic feature의 품질은 합성 품질에 크게 영향을 미침
- 이를 위해 기존에는 FastSpeech와 같이 CNN이나 Transformer를 활용했음
- 한편으로 diffusion model은 기존보다 더 우수한 품질의 sample을 생성할 수 있다는 장점이 있음 - Diffusion model은 data를 점진적으로 noise로 perturb 하는 diffusion process와 noise를 다시 data로 변환하는 reverse process를 활용함
- BUT, diffusion model의 주요한 한계점은 고품질 생성을 위해 많은 iteration이 필요하다는 것임
- 대표적으로 Grad-TTS는 Stochastic Differential Equation (SDE)를 활용하여 고품질의 sample을 얻을 수 있지만, reverse process에서 1000 step의 많은 iteration이 필요함
- 한편으로 SVS 작업에서 DiffSinger는 well-designed diffusion model을 통해 100 step만으로 우수한 합성 품질을 달성했지만, 여전히 많은 iteration이 필요함
- 결과적으로 TTS, SVS 작업에서 generative model은 다음의 요구사항을 만족해야 함
- High Audio Quality : 합성된 audio는 artifact나 distortion 없이 높은 naturalness와 expressiveness를 달성해야 함
- Fast Inference Speed : real-time application을 위해 빠른 합성이 가능해야 함
- Beyond Speech : 단순한 음성 합성 외에도 pitch, expression, rhythm, timbre 등에 대한 complex modeling이 가능해야 함
- BUT, 기존의 diffusion model들은 여전히 합성 품질과 추론 속도 간의 trade-off 문제를 가지고 있음
- 이는 기존 방식들이 느린 추론 속도 문제를 근본적으로 해결하는 것보다는 완화하는 것에 목표를 두고 있기 때문 - 이때 위 요구사항을 만족하기 위해, sampling process를 describing 하는 SDE를 Ordinary Differential Equation (ODE)로 표현하고, ODE의 trajectory에 대한 consistency constraint를 enforcing 하는 consistency model을 고려할 수 있음
- 특히 consistency model을 활용하여 고품질의 이미지 합성과 빠른 추론 속도를 모두 달성할 수 있다는 것이 제시되었지만, 음성 작업에서는 아직 적용되지 않음
-> 그래서 consistency model을 TTS, SVS 작업에 적용한 CoMoSpeech를 제안
- CoMoSpeech
- Pre-trained teacher model로부터 consistency distillation을 통해 CoMoSpeech를 얻음
- 여기서 teacher model은 SDE를 활용하여 mel-spectrogram을 Gaussian noise distribution으로 변환한 다음, 해당 score function을 학습함
- Training 이후에는 numerical ODE solver를 통해 consistency distillation에 사용되는 teacher denoiser function을 얻음
< Overall of CoMoSpeech >
- Pre-trained diffusion-based teacher model에서 distillation을 통해 얻어지는 consistency model을 음성 합성에 활용
- 결과적으로 single-step sampling 만으로도 TTS, SVS 작업 모두에서 고품질의 audio를 합성할 수 있음
2. Background of Consistency Model
- Consistency model의 설명을 위해, 먼저 $p_{data}(x)$라는 data distribution이 있다고 하자
- 여기서 diffusion model은 data에 Gaussian noise를 점진적으로 추가한 다음, reverse denoising process를 통해 noise로부터 sample을 생성하는 방식
- $p_{0}(\mathbf{x})=p_{data}(\mathbf{x})$인 diffusion process에서 noisy data $\{\mathbf{x}\}_{t=0}^{T}$는 $p_{T}(\mathbf{x})$의 Gaussian distribution에 infinitely close 하고, $T$를 time constant라 했을 때 forward diffusion process는 SDE로써 다음과 같이 나타낼 수 있음:
(Eq. 1) $d\mathbf{x}=f(\mathbf{x},t)dt+g(t)d\mathbf{w}$
- $\mathbf{w}$ : standard Wiener process, $f(\cdot, \cdot)$ : drift, $g(\cdot)$ : diffusion coefficient - 이때 $f(\mathbf{x},t)$는 $f(\mathbf{x},t)=f(t)\mathbf{x}$와 같이 동작하므로:
(Eq. 2) $d\mathbf{x}=f(t)\mathbf{x}dt+g(t)d\mathbf{w}$ - 위의 SDE는 time $t$에서 SDE의 sampling trajectory distribution을 나타내는 probability flow ODE에 해당한다는 property를 가짐:
(Eq. 3) $d\mathbf{x}=\left[f(t)\mathbf{x}-\frac{1}{2}g(t)^{2}\nabla \log p_{t}(\mathbf{x})\right]dt$
- $\nabla \log p_{t}(\mathbf{x})$ : $p_{t}(\mathbf{x})$의 score function
- Probability flow ODE는 stochastic $\mathbf{w}$를 제거하여 deterministic sampling trajectory를 생성함
- $p_{0}(\mathbf{x})=p_{data}(\mathbf{x})$인 diffusion process에서 noisy data $\{\mathbf{x}\}_{t=0}^{T}$는 $p_{T}(\mathbf{x})$의 Gaussian distribution에 infinitely close 하고, $T$를 time constant라 했을 때 forward diffusion process는 SDE로써 다음과 같이 나타낼 수 있음:
- Score function $\nabla \log p_{t}(\mathbf{x})$이 known이면, (Eq. 3)의 probability flow ODE를 sampling에 사용할 수 있음
- $D(\mathbf{x}_{t},t)$를 step $t$에서 sample $\mathbf{x}_{t}$의 noise를 제거하는 denoiser라고 하면, score function은 denoising error $|| D(\mathbf{x}_{t},t) -\mathbf{x}||^{2}$를 최소화함으로써 얻을 수 있음:
(Eq. 4) $\nabla \log p_{t}(\mathbf{x})=(D(\mathbf{x}_{t},t)-\mathbf{x}_{t})/\sigma_{t}^{2}$
- 이때 $\sigma_{t}^{2} = \int g(t)^{2}dt$ - Probability flow ODE-based sampling은 noise distribution에서 sampling 한 다음, Euler/Heun과 같은 numerical ODE solver를 사용하여 denoising을 수행하여 true sample을 얻을 수 있음
- BUT, ODE solver는 많은 iteration이 필요하므로 sampling 속도의 저하로 이어짐
- $D(\mathbf{x}_{t},t)$를 step $t$에서 sample $\mathbf{x}_{t}$의 noise를 제거하는 denoiser라고 하면, score function은 denoising error $|| D(\mathbf{x}_{t},t) -\mathbf{x}||^{2}$를 최소화함으로써 얻을 수 있음:
- 이때 sampling을 가속하거나 sampling drift를 최소화하기 위해, diffusion model에 consistency property를 $\forall t, t'$에 대해 적용하면:
(Eq. 5) $D(\mathbf{x}_{t},t)=D(\mathbf{x}_{t'},t')$
- 그리고,
(Eq. 6) $D(\mathbf{x}_{0},0)=\mathbf{x}_{0}$ - 위를 통해 consistency model을 얻을 수 있고, probability flow ODE의 sampling trajectory에 있는 모든 point가 trajectory의 origin $p_{0}(\mathbf{x})$와 directly link 되므로 one-step sampling $D(\mathbf{x}_{T},T)$를 얻을 수 있음
- Consistency model은 pre-trained diffusion-based teacher model을 distill 하거나 isolation 하여 얻어짐
- 이때 일반적으로 distillation을 사용하는 것이 더 나은 성능을 제공함
- 여기서 diffusion model은 data에 Gaussian noise를 점진적으로 추가한 다음, reverse denoising process를 통해 noise로부터 sample을 생성하는 방식
3. CoMoSpeech
- CoMoSpeech는 TTS, SVS를 위한 one-step 음성 합성 모델로써, 아래 그림과 같이 구성됨
- First stage에서는 diffusion-based teacher model을 training 하여 textual/musical score input에 따라 condition 된 audio를 생성함
- Second stage에서는 consistency property를 forcing 하여 teacher model의 distillation으로부터 CoMoSpeech를 얻음

- Teacher Model
- Diffusion model을 teacher model로 활용하려면 specific criteria를 만족해야 함
- 특히 CoMoSpeech는 one-step generation을 위해 denoiser를 채택하므로, 해당 function은 noise가 아닌 clean data를 point 할 수 있어야 함
- 따라서 teacher model은 gradient-based가 아닌 generator-based로 구성되어야 함
- 이를 위해 논문에서는 Grad-TTS를 수정하여 teacher model로 사용하고, further consistency distillation을 보장하기 위해 diffusion model에 대한 design choice로써 EDM을 따름 - Schedule $\sigma(t)$와 EDM의 scaling coefficient를 각각 $t, 1$로 사용하여 (Eq. 2)의 $\mathbf{x}$를 mel-spectrogram으로 설정하자
- 이를 (Eq. 4)에 대입하면 ODE는 다음과 같이 formulate 됨:
(Eq. 7) $d\mathbf{x}_{t}=\left[ (\mathbf{x}_{t}-D_{\theta}(\mathbf{x}_{t},t,cond)/t)\right]dt$
- $cond$ : conditional input - 여기서 $D_{\theta}(\mathbf{x}_{t},t,cond)$는 다음과 같이 $t$-dependent skip connection을 사용하여 neural network를 pre-condition 하도록 설계됨:
(Eq. 8) $D_{\theta}(\mathbf{x}_{t},t,cond)=c_{skip}(t)\mathbf{x}_{t}+c_{out}(t)F_{\theta}(\mathbf{x}_{t},t,cond)$
- $F_{\theta}$ : 학습할 network (WaveNet이나 U-Net architecture를 사용할 수 있음) - $c_{skip}(t), c_{out}(t)$ : skip connection을 modulate 하고 $F_{\theta}$의 magnitude를 scale 하는 데 사용됨:
(Eq. 9) $c_{skip}(t)=\frac{\sigma^{2}_{data}}{(t-\epsilon)^{2}+\sigma^{2}_{data}},\,\,\,\,\,\, c_{out}(t)=\frac{\sigma_{data}(t-\epsilon)}{\sqrt{\sigma^{2}_{data}+t^{2}}}$
- $\sigma_{data}=0.5$ : $c_{skip}, c_{out}$ 간의 balancing을 위해 사용, $\epsilon=0.002$ : sampling 중 가장 작은 time instant
- 위 식은 $c_{skip}(\epsilon)=1, c_{out}(\epsilon)=0$이므로 (Eq. 6)을 만족함
- 추가적으로 두 scaling factor가 $F_{\theta}$의 예측 결과를 unit variance로 scale 하므로, 서로 다른 noise level에서의 gradient magnitude의 large variation을 방지할 수 있음
- 이를 (Eq. 4)에 대입하면 ODE는 다음과 같이 formulate 됨:
- $D_{\theta}$를 train 하기 위한 loss function은:
(Eq. 10) $\mathcal{L}_{\theta}=||D_{\theta}(\mathbf{x}_{t},t,cond)-\mathbf{x}_{0}||^{2}$
- 예측된 mel-spectrogram $pred_{mel}$과 ground-truth mel-spectrogram $gt_{mel}$ 간의 weighted $\mathcal{L}_{2}$ loss
- 이때 EDM에서 제시된 바와 같이, 서로 다른 $t$에 대해 loss function을 re-weight 함 - 결과적으로 teacher model은 아래의 [Algorithm 1]에 따라 합성된 mel-spectrogram을 sampling 할 수 있음
- Teacher model의 추론을 위해서, $\mathcal{N}(\mu, I)$에서 $\mathbf{x}_{N}$을 sampling 한 다음, $N$ Euler step에 대한 numerical ODE solver를 반복함

- Consistency Distillation
- Consistency distillation을 기반으로 한 teacher model에 one-step diffusion sampling-based model을 further train 하여 CoMoSpeech를 얻음
- 먼저 (Eq. 5)와 (Eq. 6)에서 정의된 constraint를 re-exame 하자
- (Eq. 9)에서 $c_{skip}(t), c_{out}(t)$의 choice가 주어지면 teacher model의 denoiser $D_{\theta}$는 (Eq. 6)을 이미 만족하므로 remaining training objective는 (Eq. 5)의 property를 충족하는 것이 됨 - 여기서 momentum-based distillation을 CoMoSpeech의 training에 사용할 수 있고, 이때 consistency distillation loss는:
(Eq. 11) $\mathcal{L}_{\theta}=|| D_{\theta}(\mathbf{x}_{i+1},t_{i+1},cond)-D_{\theta^{-}}(\hat{\mathbf{x}}_{i}^{\phi},t_{i},cond)||^{2}$
- $\theta, \theta^{-}$ : teacher model에서 inherit 된 CoMoSpeech의 initialized weight
- $\phi$ : teacher model의 fixed ODE solver
- $i$ : $N$에서 1까지의 전체 ODE step에서 uniformly sample 된 step-index
- $\hat{\mathbf{x}}_{i}^{\phi}$ : $\mathbf{x}_{i}^{1}$에서 ODE solver $\phi$에 의해 추정됨 - Training 중에 weight $\theta$는 loss function에 의해 directly optimize 되고, $\theta^{-}$는 다음과 같이 recursively update 됨:
(Eq. 12) $\theta^{-}\leftarrow \mathrm{stopgrad}(\alpha\theta^{-}+(1-\alpha)\theta)$
- $\alpha=0.95$ : momentum coefficient
- 먼저 (Eq. 5)와 (Eq. 6)에서 정의된 constraint를 re-exame 하자

- Distillation 이후 consistency property를 활용하여 original data point $\mathbf{x}_{0}$는 위 그림처럼 ODE trajectory의 any point $\mathbf{x}_{t}$로 부터 변환될 수 있음
- 따라서 다음을 통해 $t_{N}$ step에서 distribution $\mathbf{x}_{N}$으로부터 target sample을 directly generate 함:
(Eq. 13) $mel_{pred}=D_{\theta}(\mathbf{x}_{N},t_{N}, cond)$ - 결과적으로 위 식을 통해 one-step mel-spectrogram generation이 가능하고, 한편으로 기존 stochastic sampler와 비슷하게 [Algorithm 2]를 사용하여 multi-step synthesis를 수행할 수도 있음
- 따라서 다음을 통해 $t_{N}$ step에서 distribution $\mathbf{x}_{N}$으로부터 target sample을 directly generate 함:

- Conditional Input
- CoMoSpeech의 conditional input $cond$는 TTS와 SVS 모두를 고려함
- 먼저 TTS, SVS의 basic input으로써 phoneme을 채택하고, phoneme feature를 embedding 하기 위해 look-up table이 사용됨
- 이때 SVS의 경우 phoneme에 대해 time-aligned 된 note level을 specify 하는 musice score를 추가함
- Note feature extraction 시에는 categorical feature note pitch와 slur indicator를 embedding method로 사용하고 continuous feature note duration을 얻기 위해 linear layer를 적용함 - 모든 feature sequence를 summing 하기 위해 FastSpeech의 encoder structure와 variance adaptor를 도입
- 구조적으로 phoneme hidden sequence를 추출하기 위해 $N$개의 feed-forward transformer (FFT) block을 stack 하여 사용
- Duration predictor는 각 phoneme의 duration $d_{pred}$을 추정하는 데 사용되고, 이때 해당 loss function은:
(Eq. 14) $\mathcal{L}_{duration}=|| \log(d_{pred})-\log (d_{gt})||^{2}$
- $d_{gt}$ : ground-truth phoneme duration - Length regulator는 phoeneme hidden sequence를 mel-spectrogram domain의 hidden sequence로 project 하고, prior mel-spectrogram $\mu$는 다음의 prior loss로 예측됨:
(Eq. 15) $\mathcal{L}_{prior}=||\mu-gt_{mel}||^{2}$
- $hidden_{mel}$ : phoneme duration
- 여기서 $hidden_{mel}$의 동일한 phoneme에 속하는 expanded feature가 반복되기 때문에, 예측된 $prior_{mel}$은 phoneme sequence를 기반으로 하여 $gt_{mel}$의 time-frequency structure를 대략적으로 근사할 수 있음
- Mel-spectrogram의 detail은 diffusion model을 통해 모델링 됨
- 먼저 TTS, SVS의 basic input으로써 phoneme을 채택하고, phoneme feature를 embedding 하기 위해 look-up table이 사용됨
- Training Procedure
- 전체 procss는 teacher model training과 consistency distillation의 two-stage로 구성됨
- First stage는 teacher model training으로써, loss term은 (Eq. 14)의 duration loss, (Eq. 15)의 prior loss, (Eq. 10)의 denoising loss로 구성
- 해당 loss term은 extra weight 없이 summation 됨
- Teacher model training의 목표는 고품질 audio 생성과 further consistency distillation이 가능한 모델을 구축하는 것 - Second stage는 consistency distillation으로 (Eq. 11)의 loss function을 사용하여 consistency property를 학습함
- Parameter는 teacher model을 통해 initialize 되고, training 중에는 encoder의 parameter는 fix 되어 denoiser의 weight만 update 함
- Distillation 이후 (Eq. 13)의 one-step synthesis로 고품질 합성이 가능함
- First stage는 teacher model training으로써, loss term은 (Eq. 14)의 duration loss, (Eq. 15)의 prior loss, (Eq. 10)의 denoising loss로 구성
4. Experiments
- Settings
- Dataset : LJSpeech, OpenCPop
- Comparisons : FastSpeech2, DiffGAN-TTS, ProDiff, Grad-TTS, FFTSinger, HiFiSinger, DiffSinger
- Results
- Performances on Text-to-Speech
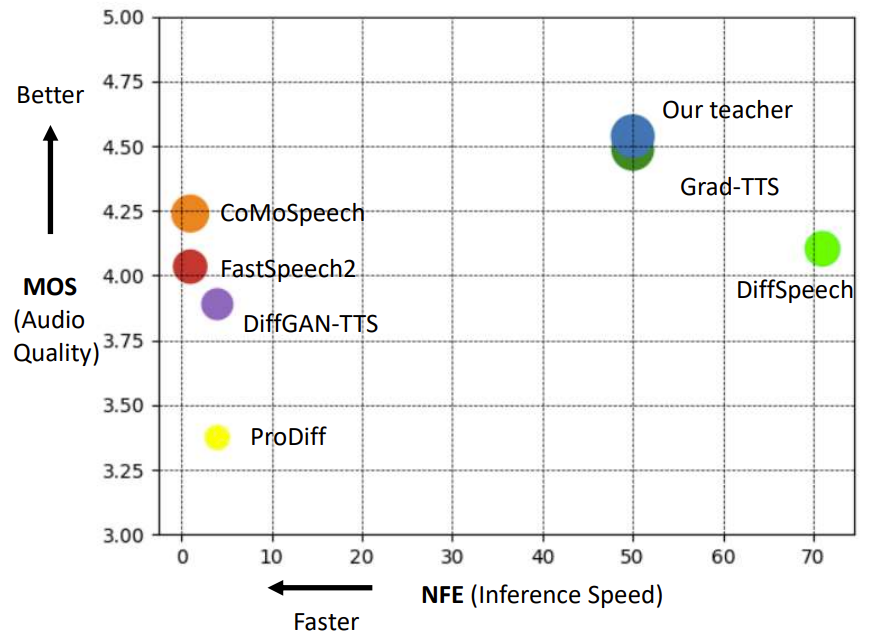
- Teacher model은 가장 좋은 MOS를 달성했고, distill 된 CoMoSpeech는 3번째로 높은 MOS 성능을 보임
- 특히 추론 속도 측면에서 CoMoSpeech는 다른 diffusion-based 모델들보다 빠른 속도를 보임

- Performances on Singing Voice Synthesis
- SVS 작업에 대해서도 CoMoSpeech는 가장 우수한 MOS 품질을 보임
- 마찬가지로 추론 속도 측면에서도 CoMoSpeech는 one-step inference를 통해 diffusion model들보다 훨씬 빠르고 non-iterative method와 비슷한 수준의 속도를 달성함
- Ablation Studies of Consistency Model
- Consistency distillation 전/후에 대한 mel-spectrogram을 비교해 보면,
- $t_{N}$ step에서 distillation 전의 denoiser function은 smooth mel-spectrogram을 생성함
- BUT, distillation 이후에는 detail 한 mel-spectrogram을 생성함으로써 보다 natural 한 음성을 생성할 수 있음

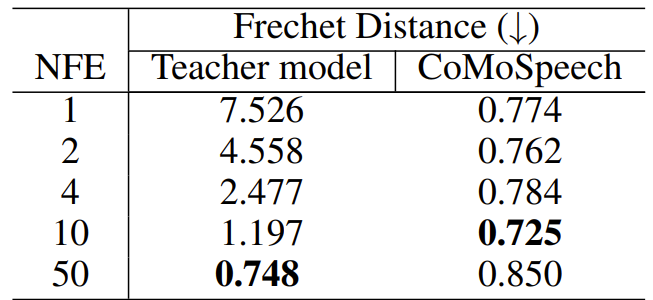
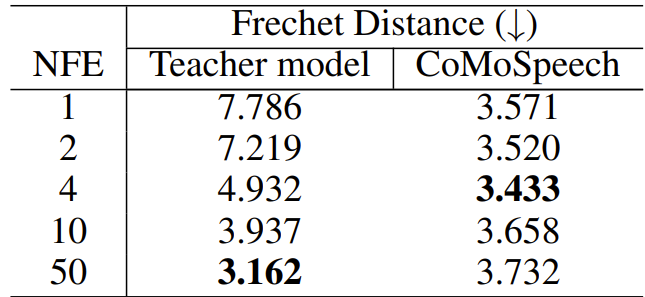
- 한편으로 teacher model의 경우 iteration step이 증가하면 Frechet distance가 감소함
- 이때 distillation을 통해 추론 속도와 sample 품질 간의 trade-off를 만족할 수 있음
- 특히 CoMoSpeech는 one-step만으로도 거의 최고 수준의 성능을 달성할 수 있고, TTS에서는 4-step, SVS에서는 10-step에서 가장 높은 성능을 얻음
- 10-step 이후로는 trade-off property가 사라지는 경향이 있음
반응형
'Paper > TTS' 카테고리의 다른 글
댓글