

티스토리 뷰
Paper/TTS
[Paper 리뷰] StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
feVeRin 2024. 3. 17. 13:45반응형
StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
- Human-level text-to-speech를 위해 large speech language model (SLM)을 활용할 수 있음
- StyleTTS2
- Diffusion model을 통해 style을 latent random variable로 모델링하여 reference speech 없이 text에 적합한 style을 생성
- End-to-End training을 위해 differentiable duration modeling이 가능한 discriminator를 도입하고 large pre-trained SLM을 사용하여 naturalness를 향상
- 논문 (NeurIPS 2024) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 더 expressive 한 합성을 위해 발전하고 있지만, 아직 human-level TTS 까지는 한계가 있음
- Diverse하고 expressive한 speech, Out-of-Domain (OOD) text에 대한 robustness가 여전히 부족하기 때문
- 특히 고성능의 zero-shot TTS를 위해서는 대규모의 dataset이 필요함
-> 그래서 human-level TTS를 위해 style-based generative model인 StyleTTS2를 제안
- StyleTTS2
- Speech style을 latent random variable로 모델링하고, stochastic diffusion model을 통해 sampling
- 이를 통해 model이 reference audio 없이도 realistic 한 음성을 합성할 수 있도록 함 - 이때 entire speech를 latent variable로 사용하지 않고 style vector만 sampling 하면 되기 때문에, StyleTTS2는 다른 diffusion TTS model 보다 더 빠르고 효율적인 합성이 가능함
- 특히 StyleTTS2는 HuBERT, WavLM과 같은 large pre-trained speech language model (SLM)을 differentiable duration modeling과 함께 discriminator로써 사용함
- 이러한 end-to-end (E2E) training을 통해 SLM의 knowledge를 transferring 하고, SLM representation을 통해 naturalness를 향상함
- Speech style을 latent random variable로 모델링하고, stochastic diffusion model을 통해 sampling
< Overall of StyleTTS2 >
- Diffusion model을 통해 style을 latent random variable로 모델링하여 reference speech 없이 text에 적합한 style을 생성
- End-to-End training을 위해 large pre-trained SLM과 differentiable duration modeling을 사용하는 discriminator를 도입해 naturalness를 향상
- 결과적으로 우수한 합성 품질과 zero-shot TTS 성능을 보임
2. Method
- StyleTTS Overview
- StyleTTS는 style encoder를 사용하여 reference audio에서 style vector를 파생하는 non-autoregressive TTS model
- Style vector는 Adaptive Instance Normalization (AdaIN)을 사용하여 decoder, duration/prosody predictor에 incorporate 됨
- 이를 통해 다양한 duration, prosody, emotion을 가진 음성을 생성함 - 모델은 크게 3가지 category로 나눌 수 있음
- Speech generation system (Acoustic module) : Text encoder, Style encoder, Speech decoder를 포함
- TTS prediction system : Duration/Prosody predictor를 포함
- Training을 위한 utility system : Discriminator, Text aligner, Pitch extractor를 포함
- Style vector는 Adaptive Instance Normalization (AdaIN)을 사용하여 decoder, duration/prosody predictor에 incorporate 됨
- 이때 StyleTTS는 two-stage training process를 활용
- First Stage : 먼저 mel-spectrogram reconstruction을 위한 acoustic module을 training
- Text encoder $T$는 input phoneme $t$를 phoneme representation $h_{text} = T(t)$로 encoding
- Text aligner $A$는 input speech $x$와 phoneme $t$에서 speech-phoneme alignment $a_{algn}=A(x,t)$를 추출하여 dot product를 통해 얻어지는 aligned phoneme representation $h_{algn}=h_{text}\cdot a_{algn}$을 생성
- Style encooder $E$는 style vector $s=E(x)$를 얻고, Pitch extractor $F$는 energy $n_{x} = ||x||$와 함께 pitch curve $p_{x} = F(x)$를 추출함
- Speech decoder $G$는 $\hat{x}=G(h_{algn},s,p_{x},n_{x})$를 reconstruct 함
- 이때 $L_{1}$ reconstruction loss $\mathcal{L}_{mel}$과 adversarial objective $\mathcal{L}_{adv}, \mathcal{L}_{fm}$을 Discriminator $D$와 함께 사용하여 input $x$와 match 되도록 training 됨
- 추가적으로 optimal alignment를 학습하기 위해 Transferable Monotonic Aligner (TMA) objective도 적용됨
- Second Stage : 앞서 training 된 fixed acoustic module을 사용하여 TTS predictor module을 학습함
- Discriminator $D$를 제외한 모든 component를 fix 하고 duration/prosdy predictor만 training 함
- Duration predictor $S$는 $d_{pred}=S(h_{text},s)$로 phoneme duration을 예측하고, Prosody predictor $P$는 $\hat{p}_{x},\hat{n}_{x} = P(h_{text},s)$로 pitch와 energy를 예측함
- Duration predictor는 $L_{1}$ loss $\mathcal{L}_{dur}$를 갖는 time axis를 따라 alignment $a_{algn}$의 summed monotonic version으로부터 얻어진 ground-truth duration $d_{gt}$와 예측된 duration이 match 되도록 학습됨
- Prosody predictor는 $L_{1}$ loss $\mathcal{L}_{f0}, \mathcal{L}_{n}$을 사용하여 pitch extractor $F$에서 파생된 ground-truth pitch $p_{x}$, energy $n_{x}$와 예측된 pitch, energy $\hat{p}_{x},\hat{n}_{x}$가 match 되도록 학습됨 - 추론 시 $d_{pred}$는, $\ell_{i-1}$에서 $d_{pred}[i]$에 대해 value 1을 repeating 하여 얻은 predicted alignment $a_{pred}$를 사용하여 $h_{text}$를 upsampling 함
- $\ell_{i}$ : $k\in \{1,...,i\}$에 대해 $d_{pred}[k]$를 summing 하여 계산된 $i$-th phoneme $t_{i}$의 end position
- $d_{pred}[i]$ : $t_{i}$의 predicted duration - Mel-spectrogram은 $x_{pred}$의 style에 영향을 미치는 arbitrary reference audio $\tilde{x}$를 반영하여 $x_{pred}=G(h_{text}\cdot a_{pred}, E(\tilde{x}), \hat{p}_{\tilde{x}}, \hat{n}_{\tilde{x}})$으로 합성되고, pre-trained vocoder를 사용하여 waveform으로 변환됨
- First Stage : 먼저 mel-spectrogram reconstruction을 위한 acoustic module을 training
- StyleTTS2
- StyleTTS2는 StyleTTS를 개선하여 human-level quality와 out-of-distribution 성능을 갖춘 expressive TTS 모델을 제공함
- 이를 위해 differentiable duration modeling을 통해 제공되는 large speech language model (SLM)을 사용한 adversarial training을 통해 모든 component를 jointly optimize 하는 end-to-end training process를 도입
- 이때 speech style은 diffusion model을 통해 sampling 된 latent variable로 모델링 되므로 reference audio 없이도 다양한 음성 생성이 가능
- End-to-End Training
- End-to-End (E2E) training은 mel-spectrogram을 waveform으로 변환하는 vocoder와 같은 fixed component에 의존하지 않고 전체 TTS system을 최적화하는 방식
- 이를 위해 StyleTTS2는 style vector, aligned phoneme representation, pitch/energy curve로부터 waveform을 직접 생성할 수 있도록 decoder $G$를 수정
- 따라서 mel-spectrogram projection layer를 제거하고 waveform decoder를 추가함 - 이때 decoder로써 HiFi-GAN-based, iSTFTNet-based 두 가지 방식을 활용할 수 있음
- HiFi-GAN은 waveform을 직접 생성할 수 있고, iSTFTNet은 inverse STFT를 사용하여 magnitude와 phase를 생성해 더 빠른 추론이 가능함
- 다음으로 waveform 생성에 효과적인 snake activation function을 도입하고, AdaIN module은 기존의 StyleTTS decoder와 유사하게 각 activation function 다음에 추가됨
- 결과적으로 mel-discriminator를 LSGAN loss와 함께 Multi-Period Discriminator (MPD), Multi-Resolution Discriminator (MRD)로 대체하고, 음질을 향상하기 위해 truncated pointwise relative loss function을 도입
- 이때 well-trained acoustic module은 TTS prediction module의 training process를 가속화할 수 있음
- 따라서 모든 component를 jointly optimize 하기 이전에, $N$ epoch에 대한 $\mathcal{L}_{mel}, \mathcal{L}_{adv}, \mathcal{L}_{fm}$과 TMA objective를 통해 pitch extractor, text aligner와 함께 acoustic module을 pre-training 함
- 이때 $N$은 training set size에 따라 결정됨 - Acoustic module에 대한 pre-training 이후 $\mathcal{L}_{mel}, \mathcal{L}_{adv}, \mathcal{L}_{fm}, \mathcal{L}_{dur}, \mathcal{L}_{f0}, \mathcal{L}_{n}$을 jointly optimize 함
- 여기서 $\mathcal{L}_{mel}$은 예측된 pitch $\hat{p}_{x}$, energy $\hat{n}_{x}$에서 reconstruction 된 waveform의 mel-spectrogram과 match 되도록 modify 됨
- Joint training 중에는 style encoder가 acoustic, prosodic information 모두를 encoding 해야 하므로 diverging gradient로 인해 stability issue가 발생함
- 이를 해결하기 위해, 기존 acoustic style encoder $E_{a}$와 prosody style encoder $E_{p}$를 활용 - 이때 $s_{a}=E_{a}(x)$ 대신 predictor $S, P$는 $s_{p}=E_{p}(x)$를 input style vector로 사용하고, style diffusion model은 augmented style vector $s=[s_{p},s_{a}]$를 생성
- 결과적으로 해당 modification을 통해 sample 품질이 향상됨
- 추가적으로 acoustic module과 predictor를 decouple 하기 위해,
- 기존 acoustic text encoder $T$의 phoneme representation $h_{text}$를 prosodic text encoder인 BERT transformer를 기반으로 하는 text encoder $B$의 $h_{bert}$로 대체함
- Prosodic text encoder로써 Wikipedia article로 pre-train 된 phoneme-level BERT를 사용함
- 이를 통해 StyleTTS의 naturalness를 향상 가능
- StyleTTS2는 differentiable upsampling과 fast style diffusion을 통해, training 중에 fully differentiable 하게 음성 sample을 생성할 수 있음
- 해당 sample은 joint training 중에 parameter를 업데이트하기 위해 $\mathcal{L}_{slm}$을 최적화하는데 사용됨
- Style Diffusion
- StyleTTS2는 분포 $p(s|t)$를 따르는 latent variable $s$를 통해 음성 $x$를 conditional 분포 $p(x|t)=\int p(x|t,s)p(s|t)ds$로써 모델링함
- 여기서 latent variable $s$를 prosody, lexical stress 등을 나타내는 generalized speech style이라고 함 - 따라서 combined probability flow와 time-varying Langevin dynamics를 따르는 EDM으로 $s$를 sampling 할 수 있음:
(Eq. 1) $s = \int -\sigma(\tau)[\beta(\tau)\sigma(\tau)+\dot{\sigma}(\tau)]\nabla_{s}\log p_{\tau}(s|t)d\tau+\int \sqrt{2\beta(\tau)}\sigma(\tau)d\tilde{W}_{\tau}$
- $\sigma(\tau)$ : noise level schedule, $\dot{\sigma}(\tau)$ : time derivative, $\beta(\tau)$ : stochasticity term
- $\tilde{W}_{\tau}$ : $\tau\in[T,0]$에서 backward Wiener process, $\nabla_{s}\log p_{\tau}(s|t)$ : time $\tau$에서의 score function - 이때 아래와 같이 pre-condition 된 denoiser $K(s;t,\sigma)$를 사용하는 EDM formulation을 활용:
(Eq. 2) $K(s;t,\sigma):=\left( \frac{\sigma_{data}}{\sigma^{*}}\right)^{2}s+\frac{\sigma \cdot \sigma_{data}}{\sigma^{*}}\cdot V\left(\frac{s}{\sigma^{*}};t,\frac{1}{4}\ln \sigma \right)$
- $\sigma$ : $P_{mean}=-1.2, P_{std}=1.2$인 log-normal 분포 $\ln \sigma \sim \mathcal{N}(P_{mean},P_{std}^{2})$
- $\sigma^{*}:=\sqrt{\sigma^{2}+\sigma^{2}_{data}}$ : scaling term, $\sigma_{data}=0.2$는 style vector standard deviation에 대한 경험적 추정치 - 여기서 $V$는 아래와 같이 training 된 $t, \sigma$에 대해 condition 된 3-layer transfromer:
(Eq. 3) $\mathcal{L}_{edm}=\mathbb{E}_{x,t,\sigma,\xi\sim\mathcal{N}(0,I)}\left[ \lambda(\sigma) || K(E(x)+\sigma\xi;t,\sigma) -E(x)||_{2}^{2} \right]$
- $E(x) := [E_{a}(x), E_{p}(x)], \lambda(\sigma):=(\sigma^{*}/(\sigma\cdot \sigma_{data}))^{2}$ : weighting factor - 해당 framework에서 $\nabla_{x}\log p(x;\sigma(t))=(D(x;\sigma)-x)/\sigma^{2}$은 score function이 $\tau$ 대신 $\sigma$에 의존하는 ODE가 됨:
(Eq. 4) $\frac{ds}{d\sigma}=-\sigma\nabla_{s}\log p_{\sigma}(s|t)=\frac{s-K(s;t,\sigma)}{\sigma},\,\,\, s(\sigma(T))\sim \mathcal{N}(0,\sigma(T)^{2}I)$
- 2nd-order Heun method를 사용하는 경우와 달리, StyleTTS2는 더 빠르고 다양한 sampling을 위해 ancestral DPM-2 solver를 사용하여 (Eq. 4)를 solve 함
- 이때 $\sigma_{\min}=0.0001, \sigma_{\max}=3, \rho=9$인 scheduler를 사용
- 이를 통해 3 step만으로 고품질 음성 합성을 위한 style vector를 sampling 할 수 있음 - 추가적으로
- Noisy input $E(x)+\sigma\xi$와 concatenate 된 $t$부터 $h_{bert}$까지의 $V$ condition과 $\sigma$는 sinusoidal positional embedding을 통해 condition 됨
- Multi-speaker에서는 $p(s|t,c)$를 $K(s;t,c,\sigma)$로 모델링하고, additional speaker embedding $c=E(x_{ref})$를 사용
- 이때 $x_{ref}$는 target speaker의 reference audio이고, speaker embedding $c$는 adaptive layer normalization에 의해 $V$에 inject 됨
- StyleTTS2는 분포 $p(s|t)$를 따르는 latent variable $s$를 통해 음성 $x$를 conditional 분포 $p(x|t)=\int p(x|t,s)p(s|t)ds$로써 모델링함

- SLM Discriminators
- Speech Language Model (SLM)은 acoustic, semantic을 포함한 valuable information을 encoding 하고, 이러한 SLM representation은 human perception을 모방할 수 있음
- 따라서 StyleTTS2는 discriminator로 94k hours의 data로 pre-train 된 12-layer WavLM을 사용하여 adversarial training을 통해 SLM encoder의 knowledge를 transfer 함
- 이때 WavLM의 parameter 수가 StyleTTS2 보다 크기 때문에 discriminator overpowering을 방지하기 위해, pre-trained WavLM $W$를 fix 하고 CNN $C$를 discriminative head로 추가함
- 즉, SLM discriminator $D_{SLM}=C\dot W$로 나타낼 수 있음 - Generator component ($T,B,G,S,P,V$를 $\mathbf{G}$로 denote)와 $D_{SLM}$을 training 하여 다음을 최적화함:
(Eq. 5) $\mathcal{L}_{slm}=\min_{\mathbf{G}}\max_{D_{SLM}}\left( \mathbb{E}_{x}[\log D_{SLM}(x)]+\mathbb{E}_{t}[\log (1-D_{SLM}(G(t)))]\right)$
- $\mathbf{G}(t)$ : text $t$로 생성된 음성, $x$ : human recording - 추가적으로:
(Eq. 6) $D^{*}_{SLM}(x)=\frac{\mathbb{P}_{W\circ\mathcal{T}}(x)}{\mathbb{P}_{W\circ\mathcal{T}}(x)+\mathbb{P}_{W\circ\mathcal{G}}(x)}$
- $D^{*}_{SLM}(x)$ : optimal discriminator, $\mathcal{T}, \mathcal{G}$ : 각각 실제 data 분포와 생성된 data 분포, $\mathbb{P}_{\mathcal{T}}, \mathbb{P}_{\mathcal{G}}$ : 각각의 density
- 이때 optimal $\mathbf{G}^{*}$는 $\mathbb{P}_{W\circ\mathcal{T}} = \mathbb{P}_{W\circ\mathcal{G}}$인 경우 달성됨
- 이는 수렴할 때 $\mathbf{G}^{*}$가 SLM representation space에서 생성된 실제 분포와 match 되어 human-level synthesis가 가능함을 의미 - (Eq. 5)에서 generator loss는 ground-truth $x$와 independent 하고 input text $t$에만 의존함
- 이를 통해 out-of-distribution (OOD) text에 대한 training이 가능함
- 실질적으로 $D_{SLM}$이 overfitting 되는 것을 방지하기 위해, training 중에 동일한 확률로 in-distribution과 OOD text를 sampling 함

- Differentiable Duration Modeling
- Duration predictor는 phoneme duration $d_{pred}$를 생성하지만, $a_{pred}$를 얻기 위한 upsampling 과정은 non-differentiable 하기 때문에 E2E training에 대한 gradient flow를 방해함
- 단순하게 $d_{gt}$에서 $d_{pred}$의 deviation으로 인한 length mismatch로 인해 extra loss term 없이 (Eq. 5)의 adversarial objective 만을 사용하여 differentiable upsampling을 구현하면, StyleTTS2의 training이 unstable 해질 수 있음
- 이러한 mismatch는 soft dynamic time warping을 통해 해결할 수 있지만, 계산 비용이 많이 필요 - 결과적으로 stable adversarial training과 human-level의 합성 품질을 달성하기 위해서는 non-parametric upsampling이 선호됨
- Gaussian upsampling은 non-parametric method로써, hyperparameter $\sigma$와 $c_{i}:=\ell_{i}-\frac{1}{2}d_{pred}[i]$로 centered 된 Gaussian kernel $\mathcal{N}_{c_{i}}(n;\sigma)$를 사용하여 예측 duration $d_{pred}$를 $a_{pred}[n,i]$로 변환:
(Eq. 7) $\mathcal{N}_{c_{i}}(n;\sigma):=\exp\left(-\frac{(n-c_{i})^{2}}{2\sigma^{2}}\right)$
(Eq. 8) $\ell_{i}:=\sum_{k=1}^{i}d_{pred}[k]$
- $\ell_{i}$ : end position, $c_{i}$ : $i$-th phoneme $t_{i}$의 center position - Gaussian upsampling은 $\sigma$에 의해 결정되는 Gaussian kernel의 fixed width로 인해 한계가 있음
- 해당 constraint는 $d_{pred}$에 따라 다양한 length의 alignment를 모델링하는 것을 방해함
- Gaussian upsampling은 non-parametric method로써, hyperparameter $\sigma$와 $c_{i}:=\ell_{i}-\frac{1}{2}d_{pred}[i]$로 centered 된 Gaussian kernel $\mathcal{N}_{c_{i}}(n;\sigma)$를 사용하여 예측 duration $d_{pred}$를 $a_{pred}[n,i]$로 변환:
- 따라서 다양한 alignment length를 고려하면서 additional training 없이 수행될 수 있는 새로운 non-parametric differentiable upsampler를 제안
- 먼저 각 phoneme $t_{i}$에 대해 random variable $a_{i}\in N$으로, phoneme $t_{i}$가 aligned speech frame의 index를 indicate 하도록 alignment를 모델링함
- 이후 $i$-th phoneme의 duration을 다른 random variable $d_{i}\in \{1,...,L\}$이라 하자
- 이때 $L=50$은 maximum phoneme duration hyperparameter로 1.25초에 해당 - 그러면 $a_{i}=\sum_{k=1}^{i}d_{k}$를 얻을 수 있지만, 각 $d_{k}$는 서로 dependent 하므로 summation을 모델링하기 어려움
- 대신 $a_{i}=d_{i}+\ell_{i-1}$로 근사하면, $a_{i}$의 근사 probability mass function (PMF)는 다음과 같이 얻어짐:
(Eq. 9) $f_{a_{i}}[n]=f_{d_{i}+\ell_{i-1}}[n]=f_{d_{i}}[n]*f_{\ell_{i-1}}[n]=\sum_{k}f_{d_{i}}[k]\cdot \delta_{\ell_{i-1}}[n-k]$
- $\delta_{\ell_{i-1}}$은 $\ell_{i-1}$에서의 PMF로, (Eq. 8)에서 정의된 constant
- 해당 delta function은 non-differentiable 하므로 (Eq. 7)에서 $\sigma=1.5$로 정의된 $\mathcal{N}_{\ell_{i-1}}$로 대체
- $f_{d_{i}}$를 모델링하기 위해, duration predictor를 modify 하여 $q[k,i]$를 output 함
- 이는 $k\in\{1,...,L\}$에 대해 적어도 $k$의 duration을 가지는 $i$-th phoneme의 확률로써, cross-entropy loss를 사용하여 $d_{gt}\geq k$일 때 1이 되도록 최적화됨
- 위 방식은 $d_{gt}, \mathcal{L}_{dur}$를 서로 match 하도록 training 된 $d_{pred}[i]:=\sum_{k=1}^{L}q[k,i]$로 근사할 수 있음
- 여기서 vector $q[:,i]$는 interval $[1, d_{i}]$에 걸쳐 uniformly distribute 되도록 train 되었지만, $f_{d_{i}}$의 unnormalized version으로도 볼 수 있음 - Speech frame 수 $M$은 일반적으로 input phoneme 수 $N$보다 크기 때문에, 해당 uniform 분포는 single phoneme을 multiple speech frame으로 align 할 수 있음
- 마지막으로, phoneme axis에 걸쳐 differentiable approximation $\tilde{f}_{a_{i}}[n]$을 normalize 하여 softmax function을 통해 $a_{pred}$를 얻음:
(Eq. 10) $a_{pred}[n,i]:=\frac{e^{(\tilde{f}_{a_{i}}[n])}}{\sum_{i=1}^{N}e^{(\tilde{f}_{a_{i}}[n])}}$
(Eq. 11) $\tilde{f}_{a_{i}}[n]:=\sum_{k=0}^{\hat{M}}q[n,i]\cdot \mathcal{N}_{\ell_{i-1}}(n-k;\sigma)$
- $\hat{M} := \lceil \ell_{N} \rceil$ : predicted total duration, $n\in\{1,...,\hat{M}\}$

3. Experiments
- Settings
- Results
- Model Performance
- LJSpeech에서 StyleTTS2는 NaturalSpeech 보다 1.07 더 높은 CMOS-N를 달성함 ($p\ll 0.01$)
- 마찬가지로 VCTK에서 StyleTTS2는 VITS 보다 높은 CMOS 결과를 보임
- Zero-shot 환경에서 VALL-E와 비교하여 StyleTTS2는 +0.67 CMOS-N로 자연스러운 합성이 가능하지만, CMOS-S 측면에서는 -0.47로 similarity는 다소 낮음

- Out-of-Domain (OOD) text에 대한 합성 품질을 비교해 보면, StyleTTS2는 OOD text에 대해 어떠한 성능 저하도 발생하지 않았지만 다른 모델들은 품질 저하가 나타남

- Style Diffusion
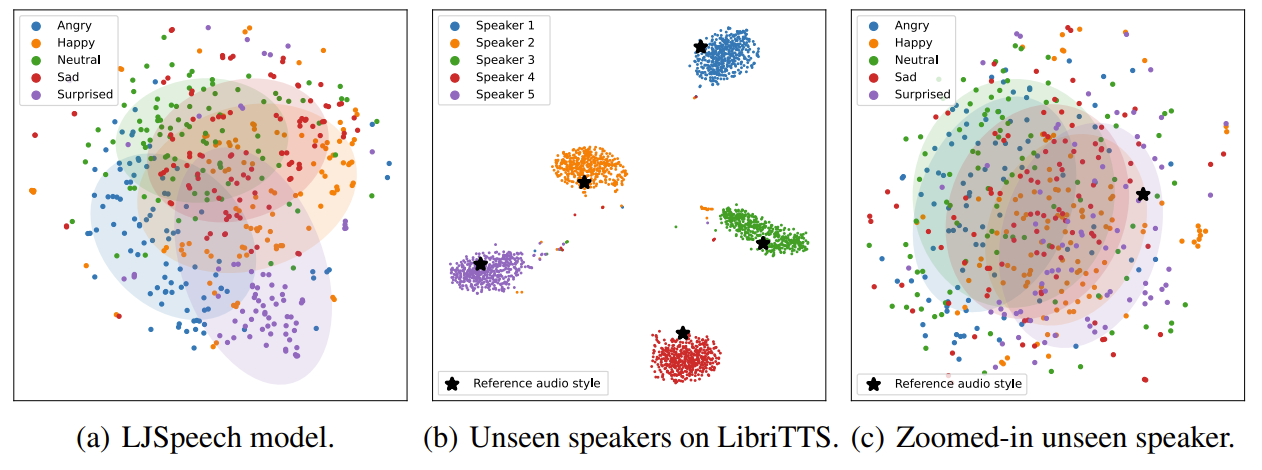
- Style diffusion process를 통해 생성된 style vector에 대한 t-SNE 결과를 확인해 보면
- LJSpeech model의 style vector는 input text sentiment에 response 하여 distinct emotional style을 드러냄
- LibriTTS model에서도 distinct cluster가 형성되어 single reference audio에서 파생된 stylistic diversity를 보여줌
- First speaker에 대한 nuanced view 측면에서, 일부 overlap에도 불구하고 visible emotion-based cluster가 나타나는 것을 확인할 수 있음
- 이는 reference audio tone에 관계없이 unseen speaker의 emotional tone을 manipulate 할 수 있다는 것을 의미
- 동일한 input text에 대해 coefficient of variation of duration $\mathrm{CV_{dur}}$과 pitch curve $\mathrm{CV_{f0}}$를 사용하여 합성된 음성의 diversity를 비교해 보면
- StyleTTS2가 가장 높은 variation을 나타내므로 다양한 음성을 생성할 수 있음
- 추가적으로 RTF 측면에서도 StyleTTS2는 diffusion-based 임에도 불구하고 가장 빠른 추론 속도를 보임

- Ablation Study
- Style vector가 random encoding으로 대체되는 경우, CMOS의 저하가 나타남
- 마찬가지로 differentiable upsampler, SLM discriminator, prosodic style encoder를 제거하는 경우에도 품질 저하가 발생
- 추가적으로 adversarial training에서 OOD text를 제외하는 경우에도 CMOS 저하가 발생함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글