

티스토리 뷰
반응형
FlashSpeech: Efficient Zero-Shot Speech Synthesis
- 최근의 large-scale zero-shot speech synthesis는 language model과 diffusion을 기반으로 구축되므로 computationally intensive 하고 generation process가 느림
- FlashSpeech
- Latent consistency model을 기반으로 adversarial consistency training을 도입
- Prosody generator module을 통해 prosody diversity를 향상
- 논문 (MM 2024) : Paper Link
1. Introduction
- Text-to-Speech (TTS)에서 zero-shot synthesis는 additional training 없이 reference audio segment에서 unseen speaker characteristic을 반영하는 것을 목표로 함
- 특히 최근의 zero-shot TTS model은 일반적으로 Language Model (LM)이나 diffusion model에 기반함
- BUT, 해당 방식들은 생성 과정에서 long-time iteration이 필요하다는 단점이 있음
- 대표적으로 VALL-E는 1-second speech를 위해 75 audio token sequence를 예측하는 autoregressive LM을 사용함
- Non-autoregressive latent diffusion model을 기반으로 하는 NaturalSpeech 역시 150 sampling step이 요구됨
- 결과적으로 LM이나 diffusion은 human-like speech를 얻을 수는 있지만, 상당한 computational cost가 필요함
- 근본적으로 autoregressive nature나 여러 번의 denoising step이 필요하기 때문
- 한편으로 VoiceBox, CLaM-TTS 등은 합성 속도를 향상하기 위해 flow-matching, mel-codec 등을 도입했음
- BUT, 여전히 practical application 측면에서는 활용하기 어렵고 computational overhead가 존재함
-> 그래서 TTS에서 기존 수준의 합성 품질을 유지하면서 합성 속도를 가속할 수 있는 FlashSpeech를 제안
- FlashSpeech
- 합성 속도 향상을 위해 Latenct Consistency Model (LCM)을 도입
- 특히 Non-autoregressive TTS system인 NaturalSpeech를 기반으로 neural audio codec encoder를 도입하여 speech waveform을 latent vector로 변환한 다음 training target으로 사용 - FlashSpeech의 training을 위해 WavLM, HuBERT와 같은 pre-trained speech language model을 discriminator로 활용하는 Adversarial Consistency Training을 적용
- 추가적으로 prosody generator를 통해 stability를 유지하면서 다양한 expression과 prosody를 반영
- 합성 속도 향상을 위해 Latenct Consistency Model (LCM)을 도입
< Overall of FlashSpeech >
- Consistency Adversarial Training을 통해 LCM을 scratch training 하고 prosody generator를 통해 diversity를 개선
- 결과적으로 zero-shot scenario에서 빠른 합성 속도와 뛰어난 품질을 달성
2. Method
- Overview
- FlashSpeech는 speech synthesis efficiency를 향상하여 $\mathcal{O}(1)$의 computation cost를 달성하면서 $\mathcal{O}(T), \mathcal{O}(N)$의 기존 모델과 유사한 성능을 유지하는 것을 목표로 함
- 구조적으로는 neural codec, phoneme/prompt encoder, prosody generator, LCM으로 구성됨
- Conditional discriminator는 training 중에만 사용됨 - FlashSpeech는 VALL-E의 in-context learning paradigm을 채택하여 codec에서 추출된 latent vector $\mathbf{z}$를 $\mathbf{z}_{target}, \mathbf{z}_{prompt}$로 segment 함
- 이후 encoder는 phoneme과 $\mathbf{z}_{prompt}$를 기반으로 hidden feature를 생성하고, prosody generator는 해당 hidden feature를 기반으로 pitch, duration을 예측함
- Pitch, duration embedding은 hidden feature와 combine 되어 conditional feature로써 LCM에 전달됨
- 이때 LCM은 adversarial consistency training을 통해 scratch로 training 됨
- 결과적으로 training 이후 FlashSpeech는 1~2 sampling step 만으로도 speech synthesis가 가능함
- 구조적으로는 neural codec, phoneme/prompt encoder, prosody generator, LCM으로 구성됨

- Latent Consistency Model
- Consistency model은 one-step/few-step generation이 가능한 generative model임
- Data distribution을 $p_{data}(\mathbf{x})$라고 하면 consistency model은 PF-ODE의 trajectory에 있는 모든 point를 해당 trajectory의 origin으로 mapping하는 function을 학습하는 것을 목표로 함:
(Eq. 1) $f(\mathbf{x}_{\sigma},\sigma)=\mathbf{x}_{\sigma_{\min}}$
- $f(\cdot, \cdot)$ : consistency function, $\mathbf{x}$, $\sigma_{\min}$ : fixed small positive number
- $\mathbf{x}_{\sigma}$ : standard deviation $\sigma$를 가지는 zero-mean Gaussian noise로 perturb 된 data - 그러면 $\mathbf{x}_{\sigma_{\min}}$은 data distribution $p_{data}(\mathbf{x})$의 approximate sample로 볼 수 있고, (Eq. 1)을 만족하기 위해 consistency model은 다음과 같이 parameterize 됨:
(Eq. 2) $f_{\theta}(\mathbf{x}_{\sigma},\sigma)=c_{skip}(\sigma)\mathbf{x}+c_{out}(\sigma) F_{\theta}(\mathbf{x}_{\sigma},\sigma)$
- $f_{\theta}$ : data로부터 학습하여 consistency function $f$를 추정하는 것
- $F_{\theta}$ : parameter $\theta$를 가지는 deep neural network
- $c_{skip}(\sigma), c_{out}(\sigma)$ : boundary condition을 보장하는 differentiable function, $c_{skip}(\sigma_{\min})=1, c_{out}(\sigma_{\min})=0$ - 이때 valid consistency model은 self-consistency property를 만족해야 함:
(Eq. 3) $f_{\theta}(\mathbf{x}_{\sigma},\sigma)=f_{\theta}(\mathbf{x}_{\sigma'},\sigma'),\,\,\, \forall \sigma, \sigma'\in[\sigma_{\min},\sigma_{\max}]$
- $\sigma_{\max}=80, \sigma_{\min}=0.002$ - 그러면 model은 다음을 evaluate 하여 one-step generation이 가능함:
(Eq. 4) $\mathbf{x}_{\sigma_{\min}}=f_{\theta}(\mathbf{x}_{\sigma_{\max}},\sigma_{\max})$
- $\mathbf{x}_{\sigma_{\max}}\sim\mathcal{N}(0,\sigma^{2}_{\max}I)$ - Audio의 latent space에 consistency model을 적용하기 위해 논문은 codec의 residual quantization layer 이전에 추출된 latent feature $\mathbf{z}$를 사용함:
(Eq. 5) $\mathbf{z}=\text{CodecEncoder}(\mathbf{y})$
- $\mathbf{y}$ : speech waveform - 추가적으로 prosody generator로 얻어진 feature를 conditional feature $c$로써 추가하여 다음의 objective를 얻음:
(Eq. 6) $f_{\theta}(\mathbf{z}_{\sigma},\sigma,c)=f_{\theta}(\mathbf{z}_{\sigma'},\sigma', c), \,\,\, \forall \sigma,\sigma'\in[\sigma_{\min},\sigma_{\max}]$ - 추론 시에 synthesized waveform $\hat{\mathbf{y}}$는 codec decoder를 통해 $\hat{\mathbf{z}}$로부터 변환됨
- 이때 predicted $\hat{\mathbf{z}}$는 one-sampling step으로 얻어짐:
(Eq. 7) $\hat{\mathbf{z}}=f_{\theta}(\epsilon *\sigma_{\max},\sigma_{\max})$ - 다음의 two-sampling step을 활용할 수도 있음:
(Eq. 8) $\hat{\mathbf{z}}_{inter}=f_{\theta}(\epsilon *\sigma_{\max},\sigma_{\max})$
(Eq. 9) $\hat{\mathbf{z}}=f_{\theta}(\hat{\mathbf{z}}_{inter}+\epsilon *\sigma_{inter},\sigma_{inter})$
- $\hat{\mathbf{z}}_{inter}$ : intermediate step, $\sigma_{inter}$ : 2로 설정
- $\epsilon$ : standard Gaussian distribution에서 sample 된 값
- 이때 predicted $\hat{\mathbf{z}}$는 one-sampling step으로 얻어짐:
- Data distribution을 $p_{data}(\mathbf{x})$라고 하면 consistency model은 PF-ODE의 trajectory에 있는 모든 point를 해당 trajectory의 origin으로 mapping하는 function을 학습하는 것을 목표로 함:
- Adversarial Consistency Training
- LCM은 first stage에서 diffusion-based teacher model을 pre-train 한 다음, distillation을 통해 final model을 얻어야 하므로 training process가 복잡하고 distillation으로 인한 성능 제한이 존재함
- 따라서 FlashSpeech는 teacher model에 대한 dependency를 제거하기 위해 LCM을 scratch로 training 하는 Adversarial Consistency Training을 도입함
- 해당 Adversarial Consistency Training은 크게 3 부분으로 구성됨
- Consistency Training
- 먼저 (Eq. 3)의 property을 만족하기 위해 다음의 consistency loss를 채택하자:
(Eq. 10) $\mathcal{L}_{ct}^{N}(\theta,\theta^{-})=\mathbb{E}[ \lambda(\sigma_{i})d(f_{\theta}(\mathbf{z}_{i+1},\sigma_{i+1},c),f_{\theta^{-}}(\mathbf{z}_{i},\sigma_{i},c) )]$
- $\sigma_{i}$ : discrete time step $i$에서의 noise level, $d(\cdot, \cdot)$ : distance function
- $f_{\theta}(\mathbf{z}_{i+1},\sigma_{i+1},c), f_{\theta^{-}}(\mathbf{z}_{i},\sigma_{i},c)$ : higher noise level student, lower noise level teacher - Discrete time step $\sigma_{\min}=\sigma_{0}<\sigma_{1}<...<\sigma_{N}=\sigma_{\max}$는 time interval $[\sigma_{\min},\sigma_{\max}]$에서 divide 되고, discretization curriculum $N$은 training step이 증가함에 따라 함께 증가함:
(Eq. 11) $N(k)=\min\left(s_{0}2^{\left\lfloor \frac{k}{K'}\right\rfloor}, s_{1}\right)+1$
- $K'=\left\lfloor \frac{K}{\log_{2}\lfloor s_{1}/s_{0}\rfloor +1} \right\rfloor$
- $k$ : current training step, $K$ : total training step, $s_{1}, s_{0}$ : $N(k)$의 size를 control 하는 hyperparameter - Distance function $d(\cdot, \cdot)$은 Pseudo-Huber metric으로써:
(Eq. 12) $d(x,y)=\sqrt{||x-y ||^{2}+a^{2}}-a$
- $a$ : adjustable constant
- 즉, $\ell_{2}$ loss보다 큰 error에 대해 smaller penalty를 부과하여 outlier에 대한 training을 robust 하게 만드는 역할 - Teacher model parameter $\theta^{-}$는:
(Eq. 13) $\theta^{-}\leftarrow \text{stopgrad}(\theta)$
- Student parameter $\theta$와 동일 - Weighting function은:
(Eq. 14) $\lambda(\sigma_{i})=\frac{1}{\sigma_{i+1}-\sigma_{i}}$
- Smaller noise level의 loss를 emphasize 하는 역할 - 해당 consistency training을 통해 LCM은 few-step 만으로도 acceptable quality의 음성을 생성할 수 있지만, 기존 수준에는 도달하지 못함
- 따라서 논문은 sample quality를 더욱 향상하기 위해 adversarial training을 도입함
- 먼저 (Eq. 3)의 property을 만족하기 위해 다음의 consistency loss를 채택하자:
- Adversarial Training
- Adversarial objective를 위해 generated sample $\hat{\mathbf{z}}\leftarrow f_{\theta}(\mathbf{z}_{\sigma},\sigma,c)$와 real sample $\mathbf{z}$는 discriminator $D_{\eta}$에 전달됨
- 여기서 discriminator는 각각을 distinguish 하는 것을 목표로 함
- $\eta$ : traininable parameter - 그러면 adversarial training loss는:
(Eq. 15) $\mathcal{L}_{adv}(\theta,\eta)=\mathbb{E}_{\mathbf{z}}[\log D_{\eta}(\mathbf{z})]+ \mathbb{E}_{\sigma}\mathbb{E}_{\mathbf{z}_{\sigma}}[\log (1-D_{\eta}(f_{\theta}(\mathbf{z}_{\sigma},\sigma,c)))]$ - 구체적으로 frozen pre-trained speech language model $SLM$과 trainable lightweight discriminator head $D_{head}$를 사용하여 discriminator를 구축함
- 먼저 $SLM$은 speech waveform에서 train 되므로 codec decoder를 사용하여 $\mathbf{z},\hat{\mathbf{z}}$를 ground-truth waveform과 predicted waveform으로 변환함
- 이때 prompt audio와 generated audio 간의 similarity를 향상하기 위해 discriminator는 prompt audio feature에 따라 conditioning 됨
- 해당 prompt feature $F_{prompt}$는 prompt audio에 $SLM$을 통해 추출되고, time-axis에 average pooling을 적용하여 사용됨
- 결과적으로:
(Eq. 16) $D_{\eta}=D_{head}(F_{prompt}\odot F_{gt},F_{prompt}\odot F_{pred})$
- $F_{gt}, F_{pred}$ : $SLM$을 통해 얻어진 ground-truth/predicted waveform의 feature
- Discriminator head는 여러 개의 1D convolution layer로 구성되고, discriminator의 input feature는 $F_{prompt}$에 따라 condition 됨
- Adversarial objective를 위해 generated sample $\hat{\mathbf{z}}\leftarrow f_{\theta}(\mathbf{z}_{\sigma},\sigma,c)$와 real sample $\mathbf{z}$는 discriminator $D_{\eta}$에 전달됨
- Combined Together
- Consistency loss와 Adversarial loss 간에는 loss scale gap이 존재하므로 training instability와 failure가 발생할 수 있음
- 따라서 FlashSpeech는 다음의 adaptive weight를 적용함:
(Eq. 17) $\lambda_{adv}=\frac{|| \nabla_{\theta_{L}}\mathcal{L}_{ct}^{N}(\theta,\theta^{-})||}{|| \nabla_{\theta_{L}}\mathcal{L}_{adv}(\theta,\eta|| } $
- $\theta_{L}$ : LCM network의 last layer - 결과적으로 얻어지는 LCM의 final training loss는 $\mathcal{L}_{ct}^{N}(\theta,\theta^{-})+\lambda_{adv}\mathcal{L}_{adv}(\theta, \eta)$과 같음
- 해당 adaptive weighting은 각 term의 gradient scale을 balancing 하여 training을 stabilize 함

- Prosody Generator
- Analysis of Prosody Prediction
- FastSpeech2 등에서 사용된 prosody prediction은 unimodal distribution에 대한 가정과 deterministic mapping으로 인해 human speech prosody의 expressiveness를 반영하지 못함
- 따라서 variation이 부족하고 over-smooth 한 prediction이 발생함 - 한편으로 VoiceBox와 같은 diffusion method는 prosody diversity를 제공할 수 있지만, stability의 문제가 있음
- 추가적으로 iterative inference로 인해 real-time application에서 활용하기 어려움
- 마찬가지로 LM-based method인 Mega-TTS, VALL-E 등도 추론에 많은 시간이 필요함 - 따라서 FlashSpeech는 prosody regression module과 prosody refinement를 기반으로 one-step consistency model sampling에 대한 prosody diversity를 향상함
- FastSpeech2 등에서 사용된 prosody prediction은 unimodal distribution에 대한 가정과 deterministic mapping으로 인해 human speech prosody의 expressiveness를 반영하지 못함
- Prosody Refinement via Consistency Model
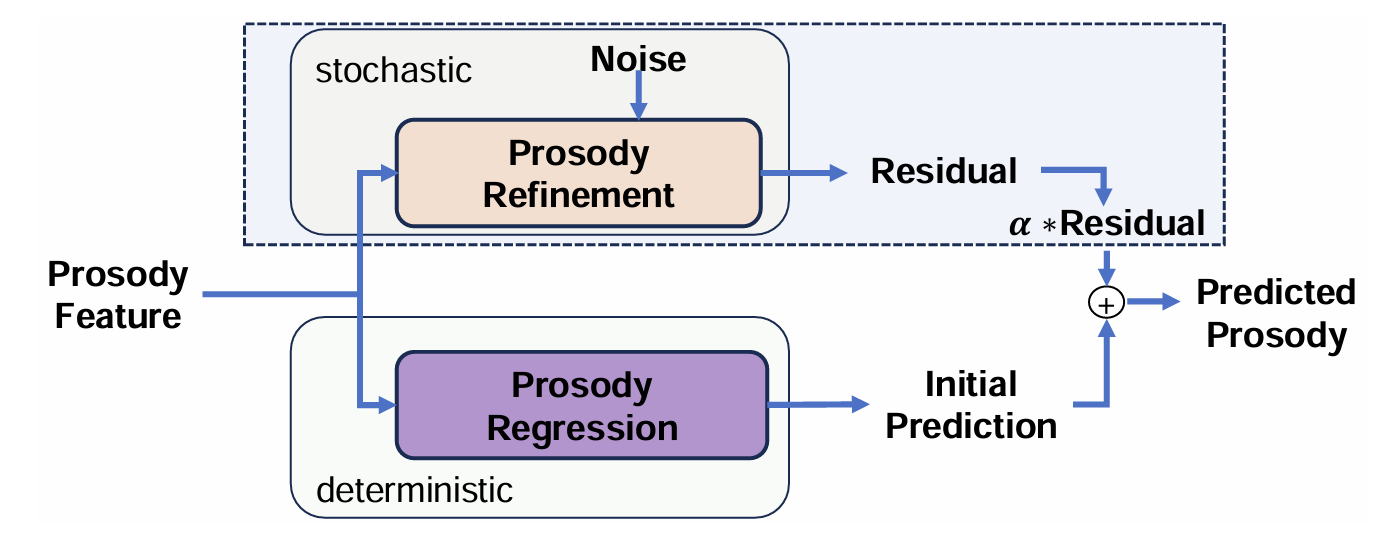
- FlashSpeech의 prosody generator는 prosody regression과 prosody refinement로 구성됨
- 먼저 prosody regression module을 통해 deterministic output을 얻음
- 이후 prosody regression module parameter를 freeze 하고 ground-truth prosody와 deterministic predicted prosody 간의 residual을 prosody refinement의 training target으로 설정함
- 이때 consistency model을 prosody refinement module로 사용 - 해당 consistency model의 conditional feature는 final projection layer 이전의 prosody regression으로 얻어진 feature에 해당함
- 따라서 stochastic sampler의 residual은 deterministic prosody regression의 output을 refine 하고 동일한 transcription과 audio prompt로부터 plausible prosody를 생성할 수 있음
- 그러면 final prosody output $p_{final}$은 다음과 같이 represent 될 수 있음:
(Eq. 18) $p_{final}=p_{res}+p_{init}$
- $p_{final}$ : final prosody output, $p_{res}$ : prosody refinement module의 residual output
- $p_{init}$ : prosody regression module의 initial deterministic prosody prediction - BUT, (Eq. 18)의 formulation은 prosody stability에 부정적인 영향을 줄 수 있음
- 구체적으로, higher diversity는 stability를 떨어트리고 unnatural prosody를 생성할 수 있음
- 따라서 논문은 prosodic output에서 stability와 diversity를 finely tuning 하는 control factor $\alpha$를 도입함:
(Eq. 19) $p_{final}=\alpha p_{res}+p_{init}$
- $\alpha$ : $[0,1]$ 사이의 scalar value
- FlashSpeech의 prosody generator는 prosody regression과 prosody refinement로 구성됨
3. Experiments
- Settings
- Dataset : Multilingual LibriSpeech (MLS)
- Comparisons : VALL-E, VoiceBox, NaturalSpeech, Mega-TTS, CLaM-TTS
- Hyperparameter
- (Eq. 12)의 $a$는 $0.03$으로 설정
- (Eq. 10)에서, $\sigma_{i}=\left(\sigma_{\min}^{1/\rho}+\frac{i-1}{N(k)-1}\left( \sigma_{\max}^{1/\rho}-\sigma_{\min}^{1/\rho}\right)\right)^{\rho}$
- $i\in[1,N(k)], \rho=7, \sigma_{\min}=0.002, \sigma_{\max}=80$ - (Eq. 11)의 $N(k)$에 대해 $s_{0}=10, s_{1}=1280, K=600k$로 설정
- Second stage에서는 $s_{1}=160, K=150k$로 설정
- Results
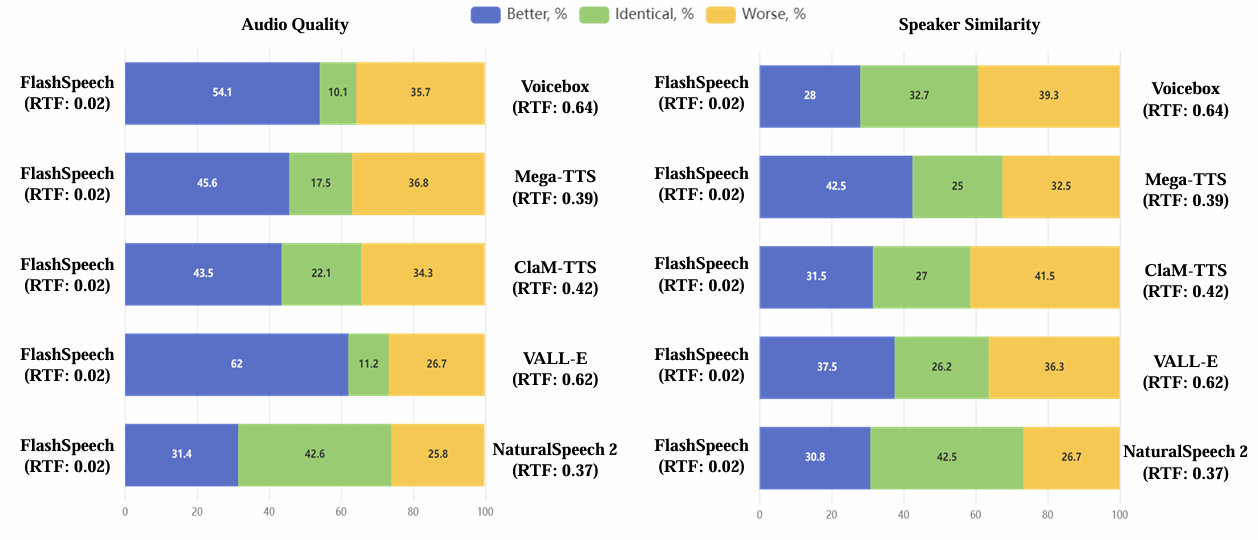
- FlashSpeech는 가장 낮은 RTF를 가지면서 뛰어난 합성 품질 (MOS)를 보임


- User preference 측면에서도 FlashSpeech가 선호됨
- Ablation Studies of LCM
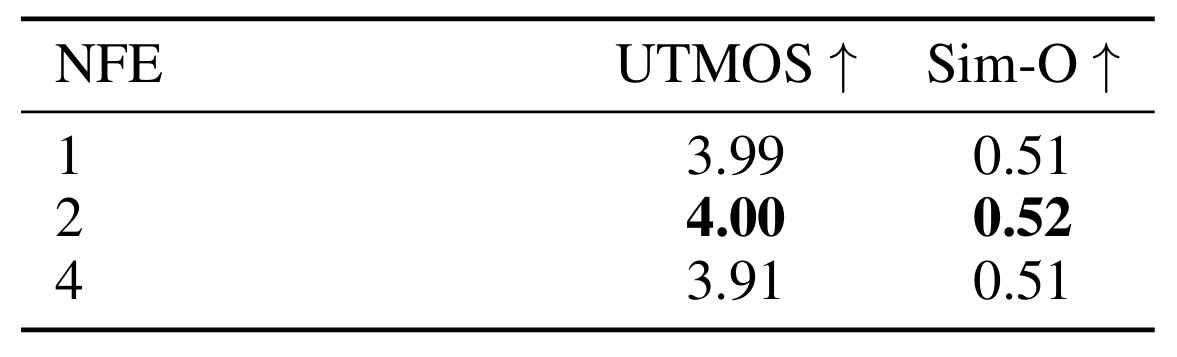
- WavLM을 discriminator로 채택하는 경우 가장 우수한 UTMOS, Sim-O를 얻을 수 있음

- LCM에 대해 $2$의 sampling step을 사용하는 경우 최적의 결과를 달성함
- Ablation Studies of Prosody Generator
- $\alpha$ 값에 따라 prosody diversity와 speech intelligibility 간 trade-off가 발생함

- Duration 측면에서도 $\alpha$에 따라 diversity, stability의 trade-off가 발생함


반응형
'Paper > TTS' 카테고리의 다른 글
댓글