

티스토리 뷰
Paper/Language Model
[Paper 리뷰] Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
feVeRin 2024. 7. 6. 13:20반응형
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
- Large-scale generative model은 고품질의 output을 생성할 수 있지만, scale과 task generalization 측면에서 한계가 있음
- Voicebox
- 주어진 audio context와 text를 기반으로 speech를 infill 하도록 train 된 non-autoregressive flow-matching model
- In-context learning을 통해 cross-lingual zero-shot synthesis, noise removal, content editing, style conversion 등의 다양한 task를 지원
- 논문 (NeurIPS 2023) : Paper Link
1. Introduction
- VALL-E와 같은 large-scale generative model은 explicitly train 되지 않은 새로운 task를 수행할 수 있는 general-purpose model로 확장되고 있음
- 특히 해당 generative model은 주어진 context를 활용하여 missing data를 예측하는 방식을 활용하고, training 이후 contextual question-answering를 적용할 수 있음
- 이때 large-scale model이 모든 task에 대해서 좋은 성능을 발휘하기 위해서는, $p(\text{missing data} | \text{context})$에 대한 추정이 모든 context에 대해서 정확해야 함
- 즉, scale과 diversity는 general-purpose model을 구축하는 데 있어 가장 중요한 요소임 - BUT, 다른 domain과 달리 speech generative model은 여전히 large-scale dataset을 필요로 함
- 대표적으로 FastSpeech2, Grad-TTS, VITS 등은 VCTK와 같은 highly curated dataset에 의존적임
- 따라서 대부분의 speech model은 emotion/voice/background noise/acoustic condition 등의 variation을 합성하는데 한계가 있고 explicitly train 되지 않은 task에 대한 generalization이 부족함
-> 그래서 다양한 text-conditioned speech generative task를 수행할 수 있는 Voicebox를 제안
- Voicebox
- Surrounding audio와 text transcript를 고려하여 masked speech를 생성하는 text-guided speech infilling task를 기반으로 training 됨
- 이때 해당 문제를 audio style이 audio context로부터 추론되고 transcript를 통해 textual content가 specify 되는 guided in-context learning으로 취급하여 audio style label에 대한 의존성을 제거
- 해당 text-guided speech infilling approach를 통해 일반적인 generative task를 지원하고 더 scalable 하도록 지원
- 구조적으로는 non-autoregressive (NAR) continuous normalizing flow (CNF)를 기반으로 함
- 특히 simple vector field regression loss를 통해 CNF를 효율적으로 training 할 수 있는 flow-matching을 활용
- 추가적으로 inference time에서 flow step을 control 하여 flexible 한 quality-efficiency trade-off를 지원
- 특히 simple vector field regression loss를 통해 CNF를 효율적으로 training 할 수 있는 flow-matching을 활용
- Surrounding audio와 text transcript를 고려하여 masked speech를 생성하는 text-guided speech infilling task를 기반으로 training 됨
< Overall of Voicebox >
- 주어진 audio context와 text를 기반으로 speech를 infill 하도록 train 된 non-autoregressive flow-matching model
- 결과적으로 cross-lingual zero-shot text-to-speech, noise removal 등의 다양한 task에서 우수한 성능을 달성

2. Method
- Background: Flow Matching with an Optimal Transport Path
- $\mathbb{R}^{d}$를 unknown distribution $q(x)$에서 추출된 datapoint $x\in \mathbb{R}^{d}$가 있는 data space라고 하자
- Continuous Normalizing Flow (CNF)는 normal distribution과 같은 simple prior distribution에서 datapoint $p_{1}\approx q$로의 변환을 학습하는 generative model
- 여기서 CNF는 time-dependent vector field $v_{t}:[0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}^{d}$를 parameterize 하여 prior에서 target distribution으로 point를 push 하는 flow $\phi_{t}:[0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}^{d}$를 구성함
- Relationship은 Ordinary Differential Equation (ODE) $d\phi_{t}(x)/dt=v_{t}(\phi_{t}(x)), \,\, \phi_{0}(x)=x$를 통해 정의됨
- Flow $\phi_{t}$에서 probability path (time-dependent probability density function) $p:[0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}_{>0}$은 variable change formula $p_{t}(x)=p_{0}(\phi_{t}^{-1}(x))\det [\partial \phi_{t}^{-1}/\partial x]$를 통해 얻어짐
- $p_{t}(x)$에서 sampling을 수행하기 위해서는, 먼저 $p_{0}$에서 $x_{0}$를 추출한 다음 $\phi_{t}(x_{0})$가 주어졌을 때 $d\phi_{t}(x)/dt= v_{t}(\phi_{t}(x)), \,\, \phi_{0}(x)=x_{0}$에 대한 initial value problem (IVP)를 solve 함
- $p_{t}$를 probability path로 하고 $u_{t}$를 $p_{t}$를 생성하는 vector field라고 하자
- 그러면 neural network $\theta$로 parameterize 된 vector field $v_{t}(x;\theta)$는 Flow Matching objective로 training 될 수 있음:
(Eq. 1) $\mathcal{L}_{FM}(\theta)=\mathbb{E}_{t,p_{t}(x)}|| u_{t}(x)-v_{t}(x;\theta)||^{2}$
- $t\sim \mathcal{U}[0,1], x\sim p_{t}(x)$ - BUT, 실제로 해당 objective는 $p_{t}$나 $v_{t}$에 대한 prior knowledge가 없으므로 loss나 gradient estimator를 직접 계산할 수 없음
- 그러면 neural network $\theta$로 parameterize 된 vector field $v_{t}(x;\theta)$는 Flow Matching objective로 training 될 수 있음:
- 따라서 $x_{1}$을 data distribution $q$를 따르는 random variable이라고 하면, Probability path $p_{t}(x)$는 vector field $u_{t}(x|x_{1})$을 쉽게 계산할 수 있는 simpler conditional path $p_{t}(x|x_{1})$의 mixture를 통해 구성됨
- 이때 $p_{t}(x)$를 구성하기 위한 conditional path는:
- $p_{0}(x|x_{1})=p_{0}(x)$
- $p_{1}(x|x_{1})=\mathcal{N}(x|x_{1},\sigma^{2}I)$ : 충분히 작은 $\sigma = 10^{-5}$를 가지는 $x_{1}$ centered Gaussian distribution
- 이를 기반으로 marginal path는 $\int p_{t}(x|x_{1})q(x_{1})dx_{1}$으로 계산되고, 이는 $t=1$에서 $q(x_{1})$에 근사함
- 결과적으로 Conditional Flow Matching (CFM) obejctive는 다음과 같이 정의됨:
(Eq. 2) $\mathcal{L}_{CFM}(\theta) =\mathbb{E}_{t,q(x_{1}),p_{t}(x|x_{1})}|| u_{t}(x|x_{1})-v_{t}(x;\theta)||^{2}$ - 한편 FM과 CFM은 $\theta$에 대해 동일한 gradient를 가짐
- 즉, $p_{t}(x|x_{1})$에서 sample을 추출하고 $u_{t}(x|x_{1})$을 계산하여 unbiased gradient estimator를 얻을 수 있음
- 이때 $p_{t}(x)$를 구성하기 위한 conditional path는:
- How to Choose Conditional Flow
- Flow는 trajectory를 정의하므로 각 point가 $p_{0}$와 $p_{1}$ 사이를 어떻게 이동하는지를 dictate 함
- 특히 simpler trajectory (straight line)은 더 빨리 학습될 수 있으므로 IVP를 더 정확하고 효율적으로 solve 할 수 있음
- 따라서 Voicebox는 point가 constant speed와 direction으로 flow 할 수 있는 Optimal Transport path (OT)를 채택함:
(Eq. 3) $p_{t}(x|x_{1})=\mathcal{N}(x|tx_{1},(1-(1-\sigma_{\min})t)^{2}I), \,\, u_{t}(x|x_{1})=(x_{1}-(1-\sigma_{\min})x)/(1-(1-\sigma_{\min})t)$
- Problem Formulation
- Audio sample $x$와 transcript $y$에 대한 transcribed speech data $(x,y)$가 주어졌을 때, 논문은 in-context learning을 통해 다양한 text-guided speech generation task를 수행할 수 있는 single model을 구축하는 것을 목표로 함
- 즉, Voicebox는 surrounding audio와 complete text transcript를 고려하여 speech segment를 예측하는 text-guided speech infilling task에 generative model을 training 함
- $m$을 $x$와 동일한 length를 가진 binary temporal mask라고 하고, $x_{mis}=m\odot x, x_{ctx}=(1-m)\odot x$를 $x$의 complementary mask라고 하자
- 이때 generative model은 $p(x_{mis}|y,x_{ctx})$를 학습하는 것을 목표로 함
- $y, x_{ctx}$ : context, $x_{mis}$ : missing data
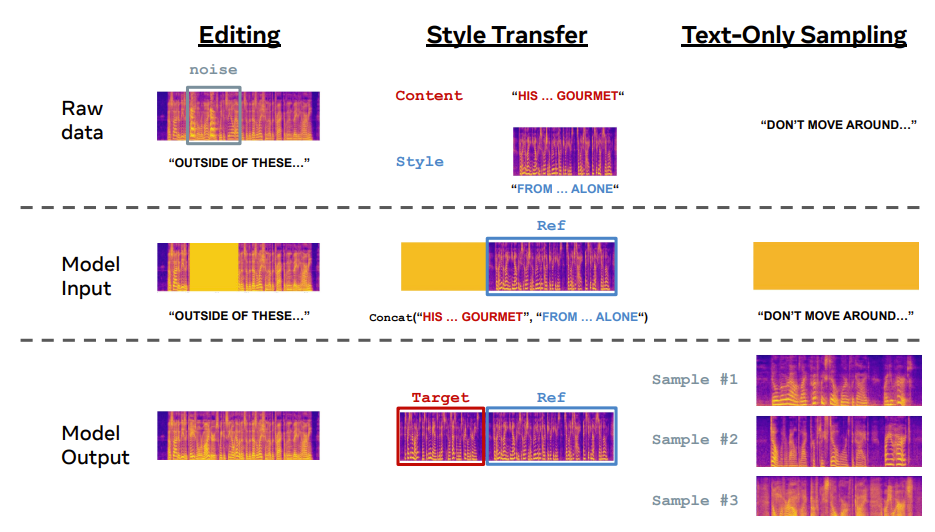
- Model and Training
- Speech와 text 간의 fine-grained alignment를 위해 Voicebox는 audio model, duration model의 두 component로 구성됨
- 먼저 $x=(x^{1},x^{2}, ..., x^{N})$을 $N$개 frame의 audio sample, $y=(y^{1}, y^{2},..., y^{M})$을 $M$개 phoneme의 text sequence, $l=(l^{1}, l^{2},..., l^{M})$을 per-phoneme duration이라고 하자
- $l^{j}$ : $y^{j}$에 해당하는 audio frame 수, $\sum_{j=1}^{M}l^{j}=N$ - 그리고 $z=\text{rep}(y,l)= (z^{1},z^{2},...,z^{N})$을 frame-level phone transcript라고 하면, 이는 각 $y^{j}$를 $l^{j}$번 repeat 하는 것을 의미함
- $z^{i}$ : audio frame $x^{i}$의 phone label - 그러면 $(x,y)$ pair에 대해 $l,z$는 Speech Recognition model을 사용하여 forced alignment를 통해 추정될 수 있음
- 결과적으로 $q(x_{mis}|y,x_{ctx})$에 대한 추정은 audio model $q(x_{mis}|z,x_{ctx})$와 duration model $q(l_{mis}|y, l_{ctx})$로 분해됨
- $l_{mis}, l_{ctx}$ : $m'$과 $1-m'$으로 mask 된 $l$
- $m'$은 $l$을 기반으로 $m$에서 downsampling 되어 얻어짐
- 먼저 $x=(x^{1},x^{2}, ..., x^{N})$을 $N$개 frame의 audio sample, $y=(y^{1}, y^{2},..., y^{M})$을 $M$개 phoneme의 text sequence, $l=(l^{1}, l^{2},..., l^{M})$을 per-phoneme duration이라고 하자
- Audio Model
- Context $z$와 length $N$인 $x_{ctx}$가 주어졌을 때, $x_{mis}$의 distribution은 $x_{mis}$가 large temporal span을 가질 때 highly stochastic 함
- 따라서 Voicebox는 CNF로 parameterize 하고 OT path를 사용한 flow matching objective를 활용하여 training 됨
- 이를 위해 먼저 audio $x$를 100Hz frame rate로 추출된 80-dimensional log-mel spectrogram $x^{i}\in \mathbb{R}^{80}$으로 represent 하자
- 그러면 $m^{i}=1, x^{i}_{ctx}=x^{i}$일 때 audio context $x_{ctx}^{i}=0$
- 이때 Simpler conditioning을 위해 masked frame $x_{mis}$가 아니라 모든 frame $x$의 conditional distribution $q(x|z,x_{ctx})$를 모델링함
- 이후 neural network를 통해 conditional vector field $v_{t}(x_{t},x_{ctx}, z;\theta)$를 parameterize 하고, $x_{ctx}, z$를 input으로 사용함
- $x_{t}$는 flow step $t$에서의 sample이고 $x=x_{1}$
- Input $x_{ctx}\in \mathbb{R}^{N\times F}, x_{t}\in \mathbb{R}^{N\times F}$, phoneme sequence $z\in [K]^{N}$, time step $t\in [0,1]$이 주어지면, transformer를 통해 vector field $v_{t}$를 parameterize 할 수 있음 ($K$ : phoneme class 수)
- 그리고 lookup table $L\in \mathbb{R}^{K\times H}$를 사용하여 phoneme sequence $z$를 embedding 하고, embedded sequence $z_{emb}\in \mathbb{R}^{N\times H}$를 얻음
- $z_{emb}^{i}=L(z^{i})$, $i\in 1,...,N$ - 세 가지 sequence $(x_{t}, x_{ctx}, z_{emb})$는 frame-by-frame으로 concatenate 되고, matrix $W_{p}\in \mathbb{R}^{(2F+H)\times D}$를 통해 project 되어 sequence $H_{c}\in \mathbb{R}^{N\times D}$를 얻음
- $D$ : transformer의 embedding dimension - 다음으로 flow step을 embed 하기 위해, 논문은 sinusoidal positional encoding을 적용하여 $t\in [0,1]$을 $h_{t}\in \mathbb{R}^{D}$로 mapping 함
- 여기서 transformer의 input으로 사용되는 sequence $\tilde{H}_{c}\in \mathbb{R}^{(N+1)\times D}$는 time dimension을 따라 $H_{c}$를 vector $h_{t}$와 concatenating 하여 얻어짐
- 그리고 lookup table $L\in \mathbb{R}^{K\times H}$를 사용하여 phoneme sequence $z$를 embedding 하고, embedded sequence $z_{emb}\in \mathbb{R}^{N\times H}$를 얻음
- 그러면 $H_{c}$에 해당하는 sub-sequence인 transformer의 output $v_{t}(x_{t},x_{mis},z;\theta)\in \mathbb{R}^{N\times F}$가 주어졌을 때, 해당 loss는 다음의 reparameterization으로 얻어짐:
(Eq. 4) $\mathcal{L}_{audio\text{-}CFM}(\theta)=\mathbb{E}_{t,m,q(x,z), p_{0}(x_{0})}|| u_{t}(x_{t}|x)-v_{t}(x_{t},x_{ctx}, z;\theta)||^{2}$ - Training 중에 audio sample $x$와 prior sample $x_{0}$가 주어지면 $x_{t}=(1-(1-\sigma_{\min})t)x_{0}+x_{t}$, $u_{t}(x_{t}|x)=x-(1-\sigma_{\min})x_{0}$가 됨
- 해당 function은 mask 되지 않고 추론 중에 필요하지 않은 frame을 포함한 모든 frame의 loss를 계산함 - 결과적으로 논문은 다음의 $\mathcal{L}_{audio\text{-}CFM}$에 대한 masked version을 활용함:
(Eq. 5) $\mathcal{L}_{audio\text{-}CFM\text{-}m}(\theta) =\mathbb{E}_{t,m,q(x,z),p_{0}(x_{0})} || m\odot (u_{t}(x_{t}|x)-v_{t}(x_{t},x_{ctx}, z;\theta)||^{2}$
- 해당 loss는 masked frame에서만 계산됨
- Duration Model
- 논문에서는 2가지 solution을 고려함
- 첫 번째 solution은 audio model을 따라 conditional vector field를 통해 $q(l|y, l_{ctx})$를 모델링함
- 해당 conditional vector field는 $(x,x_{ctx},z)$를 $(l,l_{ctx}, y)$로 swap 한 것과 같음
- $l, l_{ctx}\in \mathbb{R}^{M\times1}$, $y\in [K]^{M}$이고 CFM loss의 masked version을 training에 사용함 - 두 번째 solution은 FastSpeech2, FastPitch와 같이 regression duration model을 활용하는 방법
- 이를 위해 context duration $l_{ctx}$와 phonetic transcript $y$가 주어진 경우, masked duration $l_{mis}$를 regress 함
- 구조적으로는 transformer를 기반으로 time embedding 없이 2개의 input sequence만을 사용함
- 첫 번째 solution은 audio model을 따라 conditional vector field를 통해 $q(l|y, l_{ctx})$를 모델링함
- 결과적으로 duration model은 masked phone에서 $L1$ regression loss로 training 됨:
(Eq. 6) $\mathcal{L}_{dur\text{-}regr\text{-}m}(\theta)= \mathbb{E}_{m,q(l,y)} || m' \odot (l_{mis}-g(l_{ctx},y;\theta))||_{1}$
- $g$ : FastSpeech2의 regression-based duration model을 기반으로 additional duration context $l_{ctx}$를 input으로 사용하는 모델
- 논문에서는 2가지 solution을 고려함

- Inference
- Learned audio distribution $p_{1}(x|z, x_{ctx})$에서 sampling을 수행하려면, 먼저 $p_{0}$에서 noise $x_{0}$를 sampling 한 다음, ODE solver를 통해 $d\phi_{t}(x)/dt = v_{t}(\phi_{t}(x),x_{ctx}, z;\theta)$와 initial condition $\phi_{0}(x_{0})=x_{0}$가 주어졌을 때 $\phi_{1}(x_{0})$를 evaluate 함
- 여기서 ODE solver는 initial condition $\phi_{0}(x_{0})=x_{0}$가 주어졌을 때, $t=0$에서 $t=1$까지의 integration을 근사하기 위해 $v_{t}$를 $t$의 배수로 evaluating 하여 $\phi_{1}(x_{0})$를 계산함
- 한편으로 Number of Function Evaluation (NFE)는 $d\phi_{t}(x_{0})/dt$가 evaluate 되는 횟수로 정의됨
- 즉, NFE가 클수록 runtime은 길어지지만 $\phi_{1}(x_{0})$의 solution이 더 정확해짐
- 따라서 speed-accuracy 간의 trade-off를 결정할 수 있는 flexibility가 존재함
- 경험적으로 Voicebox에서는 10 이하의 NFE 만으로도 고품질의 음성 합성이 가능하므로, 기존 autoregressive model보다 빠르게 동작가능함
- Classifier-Free Guidance
- Classifier Guidance (CG)는 diffusion model post training에 대한 mode coverage와 sample fidelity의 trade-off를 만족하기 위해 사용됨
- 이때 auxiliary classifier에 대한 log-likelihood의 gradient를 포함하도록 diffusion model의 score estimate를 modify 함
- 한편 CG는 $p(x|c)p(c|x)^{\alpha}$에서 sampling을 근사하므로, conditional model과 unconditional model의 score estimate를 mixing 하여 classifier 없이 simulate 할 수 있음
- 여기서 unconditional model은 some probability로 conditioner $c$를 dropping 하여 jointly training 되고, 동일한 모델을 통해 $p(x)$와 $p(x|c)$에 대한 score estimate를 제공함 - 따라서 Voicebox에서는 해당 Classifier-Free Guidance (CFG)를 flow-matching model로 확장함
- 즉, conditioner $c$는 audio model의 경우 $(z,x_{ctx})$, duration model의 경우 $(y, l_{ctx})$와 동일해지고 training 중에 $p_{uncond}$로 drop 됨
- 추론 시 audio model의 modified vector field $\tilde{v}_{t}$는 $\tilde{v}_{t}(w,x_{mis},z;\theta)=(1+\alpha)\cdot v_{t}(w,x_{ctx},z;\theta)-\alpha\cdot v_{t}(w;\theta)$
- $\alpha$ : guidance strength, $v_{t}(w;\theta)$ : $x_{ctx}, z$를 dropping 하여 얻어짐
- Audio와 duration model의 CFG strength로는 $\alpha, \alpha_{dur}$를 사용함
- 한편 CFG를 사용하면 동일한 NFE에 대해 computation이 두배로 늘어남
- 이는 model forward가 두 번 호출되어 $\tilde{v}_{t}$를 계산하기 때문
- Applications
- Voicebox는 Large Language Model (LLM)과 유사한 in-context learning ability를 가지고 아래와 같은 다양한 application으로 확장 가능함
- Zero-shot TTS & Alignment-preserved Style Transfer
- Target text $\hat{y}$와 transcribed reference audio $(x,y)$가 주어지면, zero-shot TTS는 reference의 unseen audio style과 유사한 음성을 합성하는 것을 목표로 함
- Voicebox는 reference audio와 target speech를 target speech가 mask 된 하나의 utterance로 처리하여 task를 수행함
- $l, z$를 각각 $(x,y)$의 phoneme duration과 frame-level transcript라고 하자
- 그러면 target duration $\hat{l}$은 duration context $l$과 concatenated phone sequence $\text{cat}(y,\hat{y})$가 주어졌을 때 sampling 됨
- 이후 target speech $\hat{x}$는 context $x$와 concatenated frame-level phone $\text{cat}(z, \text{rep}(\hat{y}, \hat{l}))$을 기반으로 sampling 됨
- 추가적으로 Voicebox는 alignment $\bar{z}$를 preserve 하면서 speech $\bar{x}$의 audio style을 변환할 수 있음
- 이때 zero-shot TTS와 비슷하게 context $x$와 concatenated frame-level phone $\text{cat}(z,\bar{z})$를 고려하여 target speech $\hat{x}$를 sampling 하는 방식으로 동작함
- Transient Noise Removal & Content Editing
- Voicebox는 original frame-level transcript와 surrounding clean audio를 고려하여 noise corrupted segmenet를 regenerate 하고, transient noise를 remove 할 수 있음
- 한편으로 content editing에서는 edited phone transcript와 기존 phone duration을 고려하여 새로운 phone을 sampling 하여 edited frame-level phone transcript를 얻음
- 이후 새로운 frame-level phone transcript와 기존 frame의 audio를 기반으로 새로운 phone에 해당하는 frame의 audio를 sampling 함
- Diverse Speech Sampling & Alignment-preserved Style Shuffling
- Voicebox는 전체 utterance를 infilling 하여 다양한 speech sample을 생성할 수 있음
- 먼저 duration model을 사용해 phone transcript $\hat{y}$가 주어졌을 때의 $\hat{l}$을 sampling 함
- 이후 audio model을 사용해 $\hat{z}=\text{rep}(\hat{y}, \hat{l})$에 대한 $\hat{x}$를 sampling 함
- 여기서 style transfer와 마찬가지로 target speech clip $\hat{x}$의 frame-level transcript $\bar{z}$에 따라 $\hat{x}$를 sampling 하여 alignment-preserved style shuffling을 수행할 수도 있음
- Voicebox는 전체 utterance를 infilling 하여 다양한 speech sample을 생성할 수 있음

3. Experiments
- Settings
- Dataset : Multilingual audiobook
- English (En), French (Fr), German (De), Spanish (Es), Polish (Pl), Portuguese (Pt) - Comparisons : VALL-E, YourTTS, A3T, Demucs
- Results
- Monolingual and Cross-lingual Zero-shot TTS
- English TTS 측면에서 Voicebox-english (VB-En)가 가장 우수한 성능을 달성함
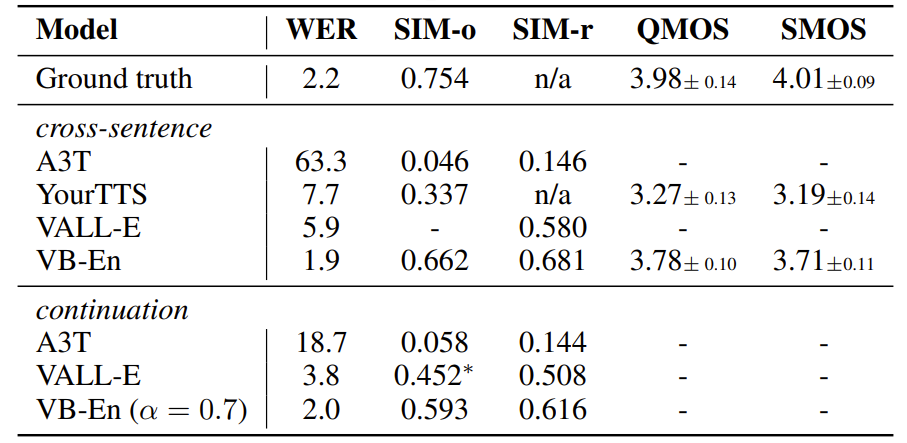
- Multilingual TTS 측면에서도 Voicebox는 YourTTS (YT) 보다 뛰어난 성능을 보임

- Transient Noise Removal
- Noisy speech에 대한 noise removal 성능 역시 Voicebox가 가장 뛰어남

- Diverse Speech Sampling and Application to ASR Data Generation
- Speech sample generation 측면에서도 Voicebox는 다른 모델들보다 우수한 성능을 달성함

- 각 모델에서 얻어진 synthetic speech를 통해 ASR model을 training 해보면
- VITS, YourTTS 등에서 얻어진 synthetic data는 non-realistic 하고 representative 하지 않기 때문에 ASR model에서 효과적이지 못함
- 반면 Voicebox로 얻어진 synthetic data를 활용하면 ASR model의 성능을 개선가능함

- Inference Efficiency versus Performance
- Guidance strength $\alpha$와 NFE에 대한 performance trade-off를 확인해 보면,
- NFE=2이고 CFG를 사용하지 않은 Voicebox는 0.31초를 기록하여 VALL-E보다 20배 빠른 속도를 보임

- Ablation on Generative Modeling Approaches
- Ablation study 측면에서 각 component를 제거하는 경우, monolingual/cross-lingual task 모두에서 성능 저하가 발생함


반응형
'Paper > Language Model' 카테고리의 다른 글
댓글