

티스토리 뷰
Paper/TTS
[Paper 리뷰] FastPitch: Parallel Text-to-Speech with Pitch Prediction
feVeRin 2023. 12. 14. 10:44반응형
FastPitch: Parallel Text-to-Speech with Pitch Prediction
- Pitch contour를 예측하면 utterance의 semantic을 일치시키고 풍부한 음성 표현력을 얻을 수 있음
- FastPitch
- FastSpeech 기반의 fully-parallel text-to-speech 모델
- Pitch 조절을 통한 자연스러운 음성 변조와 frequency contour를 condition으로 한 합성 품질의 향상
- 논문 (ICASSP 2021) : Paper Link
1. Introduction
- Neural Text-to-Speech (TTS)는 합성 품질 향상을 위해 다양한 방법들을 꾸준히 제시하고 있음
- TTS 모델은 linguistic feature나 fundamental frequency를 condition으로 활용 가능
- 특히 fundamental frequency의 경우 neural TTS 모델의 성능을 크게 향상할 수 있음
- 일반적으로는 $F_{0}$에 대한 conditioning이 사용됨
-> 그래서 Pitch contour라는 fundamental frequency를 condition으로 활용한 FastPitch를 제안
- FastPitch
- FastSpeech 기반의 feed-forward TTS 모델
- 모든 input symbol에 대해 추정된 fundemental frequency (Pitch contour)를 conditioning
- Pitch contour에 대한 명시적인 모델링을 통해 feed-forward transformer 구조를 개선
- Text 입력의 경우 linguistic information이 부족한 상황에서 동일한 phonetic unit의 서로 다른 pronunciation을 collapsing 할 수 있기 때문
- 결과적으로 수렴성을 향상하고 FastSpeech의 knowledge-distillation을 제거 가능
< Overall of FastPitch >
- Kernel-level 최적화 없이도 60배 빠르게 mel-spectrogram을 합성하는 TTS 모델
- 모든 input symbol에 대해 하나의 값으로 pitch를 예측하기 때문에 대화식 pitch 조절이 가능
- FastPitch를 통한 $F_{0}$의 constant offsetting은 speaker의 identity를 보존하면서 자연스러운 variation을 생성 가능
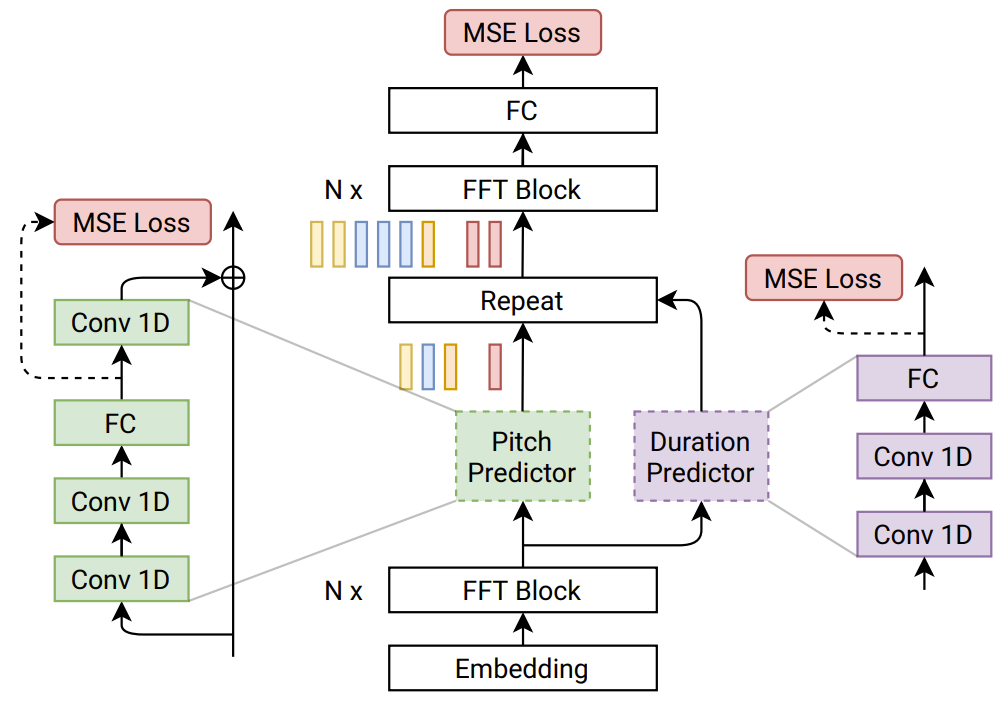
2. Model Description
- FastSpeech를 기반으로 하여 두 개의 Feed-Forward Trasnformer (FFTr) stack으로 구성
- 첫 번째 FFTr stack은 input token의 resolution에서 동작하고 두 번째 FFTr stack은 output frame의 resolution에서 동작
- $x = (x_{1}, ..., x_{n})$ : Sequence of input lexical units, $y = (y_{1}, ..., y_{t})$ : Sequence of target mel-spectrogram frames라고 했을 때
- 첫 번째 FFTr stack은 hidden representation $h = FFTr(x)$를 생성
- Hidden representation $h$는 1D CNN을 활용해 모든 character의 duration과 average pitch를 예측
: $\hat{d} = DurationPredictor(h)$, $\hat{p} = PitchPredictor(h)$
- $\hat{d} \in \mathbb{N}^{n}, \hat{p} \in \mathbb{R}^{n}$ - Pitch는 hidden representation $h \in \mathbb{R}^{n \times d}$의 차원과 일치하도록 projection 된 다음 $h$에 더해짐
: $g = h + PitchEmbedding(p)$ - Resulting sum $g$는 개별적으로 upsampling되고, output FFTr로 전달되어 output mel-spectrogram sequence를 생성
: $\hat{y} = FFTr( [ \underset{ d_{1} } { \underbrace{g_{1}, ..., g_{1}}}, ... \underset{ d_{n} } { \underbrace{g_{n}, ..., g_{n}}} ] )$
- 첫 번째 FFTr stack은 hidden representation $h = FFTr(x)$를 생성
- Ground truth $p, d$는 training 과정에서 사용되고 예측된 $\hat{p}, \hat{d}$는 inference 과정에서 사용
- 모델은 예측과 ground truth 간의 Mean Squared Error (MSE)로 최적화됨
: $L = || \hat{y} - y ||^{2}_{2} + \alpha || \hat{p} - p ||^{2}_{2} + \gamma || \hat{d} - d || ^{2}_{2}$
- Duration of Input Symbols
- Input symbol의 duration은 LJSpeech dataset에서 학습된 Tacotron2를 사용하여 추정됨
- $ A \in \mathbb{R}^{n \times t}$를 final Tacotron2 attention matrix라고 하면,
- $i$th input symbol의 duration은, $d_{i} = \sum^{t}_{c=1} [argmax_{r} A_{r,c} = i]$
- Tacotron2는 single attention matrix를 가지고 있기 때문에 multi-head transformer의 attention head를 선택할 필요는 없음 - FastPitch는 alignment에 대해 robust한 특징을 보임
- 서로 다른 Tacotron2에서 추출된 duration은 서로 다르게 나타나는 경향이 있음
-> BUT, FastPitch는 서로 다른 alignment에 대해서도 비슷한 품질의 음성을 합성해냄
- $ A \in \mathbb{R}^{n \times t}$를 final Tacotron2 attention matrix라고 하면,

- Pitch of Input Symbols
- Accurate autocorrelation method를 활용한 acoustic periodicity detection을 통해 ground truth pitch value를 얻음
- 알고리즘은 candidate frequency 중에서 normalized autocorrelation function의 maixum array를 찾는 방식으로 동작
- Candiate array에 대한 lowest-cost path는 Viterbi 알고리즘을 통해 계산됨
- Path는 candiate frequency 간의 transition을 최소화하는 역할 - $F_{0}$ 값은 추출된 duration $d$를 사용하여 모든 input symbol에 대한 평균으로 계산됨
- Unvoiced 값은 제외되고, 평균 0, 표준편차 1로 standardized 됨
- 특정 symbol에 대해 voiced $F_{0}$ 추정치가 없는 경우, 해당 pitch는 0으로 설정됨
- 알고리즘은 candidate frequency 중에서 normalized autocorrelation function의 maixum array를 찾는 방식으로 동작

3. Experiments
- Settings
- Datasets : LJSpeech
- Comparisons : Tacotron2, Flowtron
- Evaluation
- MOS 측면에서 Tacotron2와 비교하면, FastPitch가 더 높은 품질의 음성을 합성할 수 있음
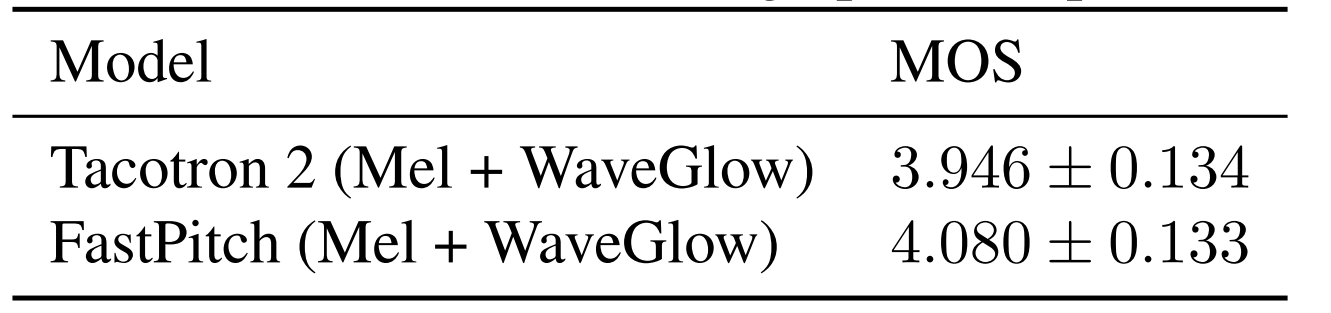
- Pariwise Comparisons
- 1/2/4개의 attention head, 6/10개의 transformer layer를 가지는 FastPitch의 변형에 대해서 예측된 pitch들을 비교
- 1개의 attention head, 6개의 transformer를 사용한 FastPitch 모델이 가장 pitch를 잘 예측함

- Multiple Speakers
- Multiple speaker 환경으로 FastPitch를 확장해서 결과를 비교
- Tacotron2, Flowtron과 비교했을 때 FastPitch가 우수한 합성 품질을 보임

- Pitch Conditioning and Inference Performance
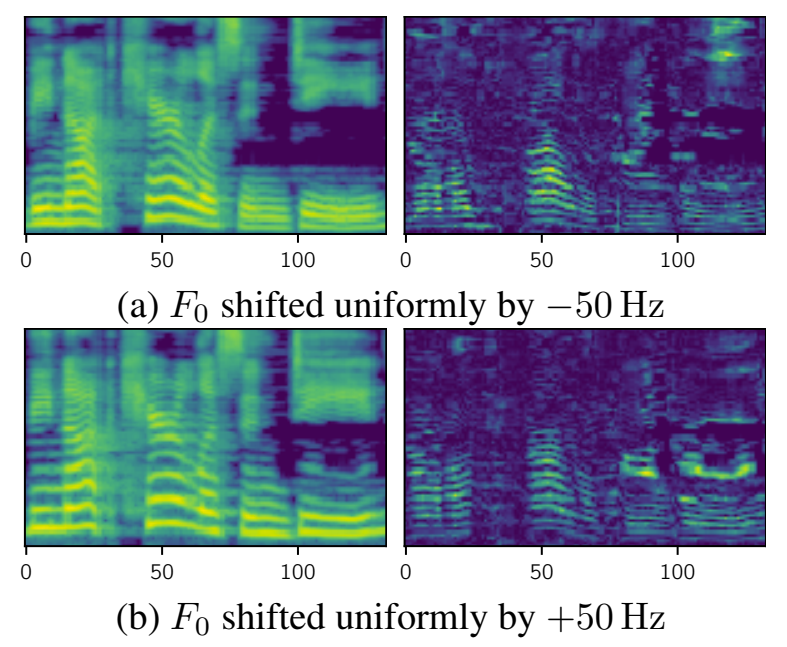
- 예측된 pitch contour는 추론 과정에서 수정하여 생성된 음성을 제어할 수 있음
- $F_{0}$를 높이거나 낮추면서 음성의 표현력과 pitch의 variation을 높일 수 있음
- Frequency를 50Hz 만큼 shift 한 경우에 대해,
- FastPitch는 speaker의 identity를 보존하면서 음성의 변조 중에 발생하는 vocal chord를 모델링할 수 있음
- FastPitch의 추론 성능은 GPU에서 첫 2048개 utterance에 대해 real-time factor (RTF)는 912x로 측정됨
- CPU의 경우 108x로 측정됨

반응형
'Paper > TTS' 카테고리의 다른 글
댓글