

티스토리 뷰
Paper/TTS
[Paper 리뷰] DiTTo-TTS: Diffusion Transformers for Scalable Text-to-Speech without Domain-Specific Factors
feVeRin 2025. 3. 3. 12:10반응형
DiTTo-TTS: Diffusion Transformers for Scalable Text-to-Speech without Domain-Specific Factors
- Large-scale Latent Diffusion Model은 various modality에 대해 우수한 content generation 성능을 보여주고 있지만, text-to-speech에서는 phoneme, duration에 의존해야 하므로 scalability의 한계가 있음
- DiTTo-TTS
- Domain-specific factor를 제거한 Latent Diffusion Model 기반의 text-to-speech model
- 기존 U-Net 대신 Diffusion Transformer를 채택하고 speech length predictor를 사용한 variable-length modeling을 도입
- 추가적으로 speech latent representation의 semantic alignment가 성능 향상에 유효함을 보임
- 논문 (ICLR 2025) : Paper Link
1. Introduction
- Latent Diffusion Model (LDM)은 latent representation을 통해 lower dimension에서 input data의 essential feature를 capture 하여 diffuion model의 generation quality는 유지하면서 computational cost를 줄일 수 있음
- Text-to-Speech (TTS)는 generated speech와 input text 간의 temporal alignment를 달성해야 함
- 즉, 각 word나 phoneme이 correct time에 해당 speech audio와 synchronize 되어야 함
- 해당 문제를 위해 LDM-based model은 phoneme, duration과 같은 domain-specific factor를 사용함
- BUT, 이는 data preparation을 복잡하게 만들고 large-scale model로 확장하기 어렵게 만듦 - 한편으로 phoneme/duration prediction을 제거하고 model architecture를 simplify 할 수 있는 cross-attention mechanism을 통해 text, speech를 align 하는 pre-trained text/speech encoder를 활용할 수도 있음
- 결과적으로 LDM-based TTS는 다음의 의문점을 해결해야 함:
- LDM은 domain-specific factor에 의존하지 않고도 state-of-the-art TTS performance를 달성할 수 있는가?
- 그렇다면 해당 성능 향상의 key aspect는 무엇인가?
- Text-to-Speech (TTS)는 generated speech와 input text 간의 temporal alignment를 달성해야 함
-> 그래서 domain-specific factor 없이도 최상의 성능을 달성할 수 있는 LDM-based TTS model인 DiTTo-TTS를 제안
- DiTTo-TTS
- 기존 U-Net architecture 대신 Diffusion Transformer (DiT)를 채택하고, long skip connection, global Adaptive Layer Normalization (AdaIN) 등의 modification을 반영
- 해당 DiT를 TTS로 이식해 DiTTo-TTS를 구성 - 기존의 fixed length modeling 대신 variable speech length modeling을 도입하여 성능을 향상
- Fixed length modeling의 padding을 사용하지 않고 주어진 text, speech prompt를 기반으로 total speech length를 predict 하는 Speech Length Predictor module을 적용 - Speech data와 jointly training 된 text encoder 또는 auxiliary language modeling objective를 incorporate 한 speech autoencoder로 얻어진 semantic alignment를 활용해 latent representation을 구성
- 기존 U-Net architecture 대신 Diffusion Transformer (DiT)를 채택하고, long skip connection, global Adaptive Layer Normalization (AdaIN) 등의 modification을 반영
< Overall of DiTTo-TTS >
- Domain-specific factor 의존성을 제거한 LDM-based TTS model
- 결과적으로 기존보다 뛰어난 합성 성능을 달성
2. Method
- Preliminary
- Diffusion model은 simple noise distribution을 stochastic denoising process를 통해 complex data distribution으로 변환하는 generative model에 해당함
- 일반적으로 diffusion model은 time step이 증가함에 따라 input data에 Gaussian noise를 progressively add 하는 forward process를 define 함
- 한편 reverse process는 added noise를 추정하여 original data를 reconstruct 함 - Diffusion model은 real-world data에서 directly operate 할 수 있지만, 주로 latent space에 적용됨
- 해당 approach는 dimensionality reduce를 통해 diffusion model이 data의 semantic information에 focus 하게 하고 autoencoder는 high-frequency detail을 handle 하게 하므로 output quality를 향상할 수 있음 - 논문에서 conditional LDM은 다음과 같이 formualte 됨:
- 먼저 speech audio가 주어지면 autoencoder는 latent representation $z_{speech}$를 생성하고, diffusion model은 text token sequence $x$에 대해 각 diffusion step $t\in[1,T]$에서 $z_{speech}$를 predict 하도록 training 됨
- 여기서 noisy latent $z^{(t)}$는 $\alpha_{t}z_{speech}+\sigma_{t}\epsilon$과 같음
- $\epsilon$ : standard normal distribution에서 sampling 되는 값
- $\alpha_{t}, \sigma_{t}$ : noise schedule에 의해 define 되는 값
- $z^{(1)}$ : $z_{speech}$, $z^{(T)}$ : standard normal distribution을 따름 - 논문은 $v$-prediction을 model output $v_{\theta}(z^{(t)},x,t)$으로 사용하여 $v^{(t)}:=\alpha_{t}\epsilon-\sigma_{t}z^{(t)}$를 predict 함
- 결과적으로 해당 setting은 training loss로써 다음의 Mean Squared Error objective를 제공함:
(Eq. 1) $\mathcal{L}_{diffusion}=\mathbb{E}_{t\sim\mathcal{U}(1,T),\epsilon\sim\mathcal{N}(0,1)}\left[\left|\left| v^{(t)}-v_{\theta}(z^{(t)},x,t)\right|\right|^{2}\right]$
- 추가적으로 contextual information을 enrich 하고 zero-shot audio prompting을 지원하기 위해 random span masking을 도입함
- 먼저 $z_{mask}^{(t)}:=m\odot z^{(t)}+(1-m)\odot z_{speech}$가 model에 input 된다고 하자
- $\odot$ : element-wise multiplication - 이때 binary mask는 $0.1$의 probability로 fully mask 하거나 size가 data의 $70\%\text{~}100\%$인 random contiguous segment를 partially mask 함
- Additional model input으로써 binary span masking을 사용 - 즉, 해당 masking을 통해 model은 생성할 part를 explicitly identify 할 수 있음
- 먼저 $z_{mask}^{(t)}:=m\odot z^{(t)}+(1-m)\odot z_{speech}$가 model에 input 된다고 하자
- 결과적으로 masking을 포함한 training loss는:
(Eq. 2) $\mathcal{L}_{diffusion}=\mathbb{E}_{t\sim\mathcal{U}(1,T),\epsilon\sim\mathcal{N}(0,1)}\left[\left|\left| m\odot (v^{(t)}-v_{\theta}(z_{mask}^{(t)},m,x,t))\right|\right|^{2}\right]$
- 일반적으로 diffusion model은 time step이 증가함에 따라 input data에 Gaussian noise를 progressively add 하는 forward process를 define 함
- Model and Training
- Text Encoder
- 먼저 pre-trained encoder-decoder-based large language model $p_{\phi}$을 $\phi$로 parameterize 함
- 해당 model은 text token sequence의 log-likelihood $\log p_{\phi}(x)$를 maximize 하도록 pre-train 되고, 이후 TTS에 대한 diffusion model을 training 할 때 해당 parameter는 fix 됨 - 이를 기반으로 text encoder는 text embedding $z_{text}$를 output 함
- 먼저 pre-trained encoder-decoder-based large language model $p_{\phi}$을 $\phi$로 parameterize 함
- Neural Audio Codec
- $\psi$로 parameterize 된 neural audio codec은 3가지 component로 구성됨:
- Encoder : Speech를 latent representation sequence $z_{speech}$로 mapping 하는 역할
- Vector Quantizer : Latent vector를 discrete code representation으로 converting 하는 역할
- Decoder : Quantized latent representation sequence $\hat{z}_{speech}$에서 speech를 reconstruct 하는 역할
- TTS의 경우 text, speech embedding 간의 alignment가 중요하므로 pre-trained language model의 encoder output과 align 하여 neural audio codec을 fine-tuning 해 사용함
- 이때 $z_{speech}$의 dimension을 language model의 hidden space에 match 하기 위해 learnable linear projection $f(\cdot)$을 도입함
- 해당 projected embedding은 language model decoder의 cross-attention 내에서 pre-trained text encoder embedding을 대체함 - 결과적으로 neural audio codec은 생성된 representation에 semantic content를 infuse 하는 auxiliary loss로 fine-tuning 됨:
(Eq. 3) $\mathcal{L}(\psi)=\mathcal{L}_{NAC}(\psi)+\lambda\mathcal{L}_{LM}(\psi),\,\,\, \mathcal{L}_{LM}(\psi)=-\log p_{\phi}(x|f(z_{speech}))$
- $\mathcal{L}_{NAC}(\psi)$ : CLaM-TTS를 따라 neural audio codec pre-training에 사용되는 loss function
- $\lambda$ : LLM influence를 control 하는 parameter ($\lambda=0$ : pre-training phase)
- $\lambda>0$ 인 경우, pre-trained language decoder는 speech latent vector $z_{speech}$에 따라 text token sequence $x$에 대한 causal language modeling을 수행함
- 이때 $z_{speech}$의 dimension을 language model의 hidden space에 match 하기 위해 learnable linear projection $f(\cdot)$을 도입함
- Language model decoder의 parameter는 fix 되지만 gradient는 backpropagate 되어 linear mapping $f(z_{speech})$를 udpate 함
- 해당 training strategy를 통해 autoencoding process 중에 speech latent vector를 pre-trained language model의 linguistic latent와 align 할 수 있음
- $\psi$로 parameterize 된 neural audio codec은 3가지 component로 구성됨:
- Diffusion Model
- Text embedding $z_{text}$와 speech embedding $z_{speech}$가 주어지면 (Eq. 2)의 objective를 사용하여 diffusion model $v_{\theta}(\cdot)$을 training 하고 $x$를 $z_{text}$로 replace 함:
(Eq. 4) $\mathcal{L}_{diffusion}=\mathbb{E}_{t\sim\mathcal{U}(1,T),\epsilon\sim\mathcal{N}(0,I)}\left[\left|\left| m\odot (v^{(t)}-v_{\theta}(z_{mask}^{(t)},m,z_{text},t))\right|\right|^{2}\right]$
- $z_{mask}^{(t)}=m\odot z^{(t)}+(1-m)\odot z_{speech}$ : masked input latent
- $m$ : binary span masking, $t$ : diffusion time step - 추가적으로 Classifier-Free Guidance (CFG)와 Simple-TTS의 diffusion noise schedule을 적용함
- Text embedding $z_{text}$와 speech embedding $z_{speech}$가 주어지면 (Eq. 2)의 objective를 사용하여 diffusion model $v_{\theta}(\cdot)$을 training 하고 $x$를 $z_{text}$로 replace 함:
- Speech Length Predictor
- DiTTo-TTS는 각 phoneme duration을 추정하는 대신, 주어진 text에 대해 생성된 speech의 total length를 predict 하는 model을 도입함
- 여기서 diffusion model의 input noise는 inference time의 speech length predictor length로 설정됨 - 해당 speech length predictor를 구성하기 위해 논문은 encoder-decoder Transformer를 채택함
- Encoder는 text input을 bidirectionally process 하여 comprehensive textual context를 capture 함
- Future lookahead를 방지하기 위해 causal masking이 적용된 Decoder는 inference time의 speech prompting을 위해 nerual codec encoder에서 audio token sequence를 recevie 함
- 추가적으로 cross-attention mechanism을 사용하여 encoder의 text feature를 integrate 하고 final layer에서 softmax activation을 적용해 주어진 maximum length $N$에서 생성될 token 수를 predict 함
- Remaining audio length에 대한 ground-truth label은 각 subsequent time step마다 하나씩 감소하여 inference 중에 speech prompt를 accept 함
- 해당 model은 cross-entropy loss를 사용하여 diffusion model과 개별적으로 training 됨
- DiTTo-TTS는 각 phoneme duration을 추정하는 대신, 주어진 text에 대해 생성된 speech의 total length를 predict 하는 model을 도입함

- Model Architecture
- 논문은 TTS에 적합한 latent diffusion model로써 Diffusion Transformer (DiT)를 채택함
- 이때 GELU activation, Rotary position embedding, Cross-attention with global Adpative Layer Normalization (AdaIN)과 같은 최신 transformer variant도 integrate 함
- 특히 DiTTo는 overall speech length만 modeling 하므로 cross-attention layer 내에서 각 token의 detailed duration을 학습하여 natural, coherent speech를 생성할 수 있음 - Latent space의 경우 EnCodec 보다 $\times 7\text{~}8$만큼 audio sequence를 더 compress 할 수 있는 Mel-VAE를 채택해 high audio quality의 10.76Hz code를 생성함
- Noise scheduler와 CFG scale은 각각 $0.3, 5.0$으로 설정됨
- 이때 GELU activation, Rotary position embedding, Cross-attention with global Adpative Layer Normalization (AdaIN)과 같은 최신 transformer variant도 integrate 함
- Mel-VAE
- Mel-VAE의 text와 closely relate 된 latent audio representation은 TTS에서 EnCodec보다 더 나은 성능을 보임
- 구체적으로 Mel-VAE의 autoencoding process는:
- 먼저 encoder는 mel-spectrogram을 latent representation sequence $z_{1:T}$로 mapping 하고, Residual Vector Quantizer $\text{RQ}_{\psi}(\cdot)$으로 전달함
- Quantizer는 time $t$에서의 각 latent vector $z_{t}$를 quantized embedding $\hat{z}_{t}=\sum_{d=1}^{D}e_{\psi}(c_{t,d};d)$로 convert 함
- 그러면 depth $d$의 각 embedding $e_{\psi}(c_{t,d};d)$는 codebook embedding $\{e_{\psi}(c',d)\}^{V}_{c'=1}$에서 $||(z-\sum_{d'=1}^{d-1}e_{\psi}(c_{t,d'};d'))-e_{\psi}(c_{t,d};d)||^{2}$를 minimize 하도록 select 됨
- $V$ : codebook size - 최종적으로 decoder는 quantized latent representation $\hat{z}_{1:T}$의 sequence에서 mel-spectrogram을 reconstruct 함

3. Experiments
- Settings
- Dataset
- DiTTo-en : Multilingual LibriSpeech (MLS), GigaSpeech, LibriTTS-R, LJSpeech, VCTK, Expresso
- DiTTo-multi : AIHub, KsponSpeech, MLS (German, Dutch, French, Spanish, Italian, Portuguese, Polish) - Comparisons : VALL-E, Spear-TTS, CLaM-TTS, YourTTS, VoiceBox, Simple-TTS
- Results
- 전체적으로 DiTTo-TTS가 가장 뛰어난 성능을 달성함

- Cross-sentence task에 대해서도 DiTTo-TTS는 우수한 성능을 보임

- MOS 측면에서 DiTTo-TTS는 ground-truth 수준의 합성 품질을 달성함

- DiT Fits Better than U-Net
- Domain-specific factor가 제거된 경우, DiT가 일반적인 U-Net 보다 더 효과적임
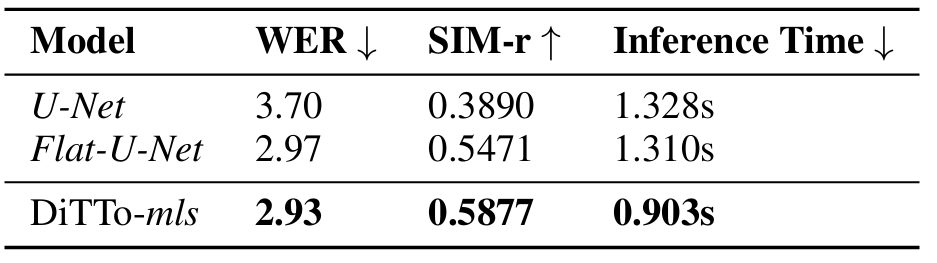
- Variable Length Modeling Outperforms Fixed Length Modeling
- Speech length modeling에 대해 다음 4가지 approach를 비교해 보면:
- Fixed-length : Target latent에 variable-length padding이 포함된 최대 20s speech로 학습
- Fixed-length-full : Maximum length 내의 모든 padding을 predict
- SLP-CE : top-$k$ sampling의 speech length predictor를 사용하는 DiTTo-mls ($k=20$)
- SLP-Regression : SLP-CE와 유사하지만 regression objective를 사용
- Fixed-length modeling에서 padding을 add 할수록 성능이 저하되고, variable-length modeling이 fixed-length modeling 보다 우수한 성능을 보임
- Speech length modeling에 대해 다음 4가지 approach를 비교해 보면:

- 특히 variable-length modeling은 생성된 speech latent의 total length를 변경하여 speech rate를 control 할 수 있음

- Aligned Text-Speech Embedding Improve Performance
- SpeechT5로 training 된 DiTTo-mls가 speech accuracy 측면에서 ByT5-base보다 더 뛰어남
- 즉, text embedding을 speech embedding과 aligning 하면 TTS 성능을 향상할 수 있음
- 따라서 speech와 jointly modeling 된 pre-trained text encoder를 사용하는 것이 좋음
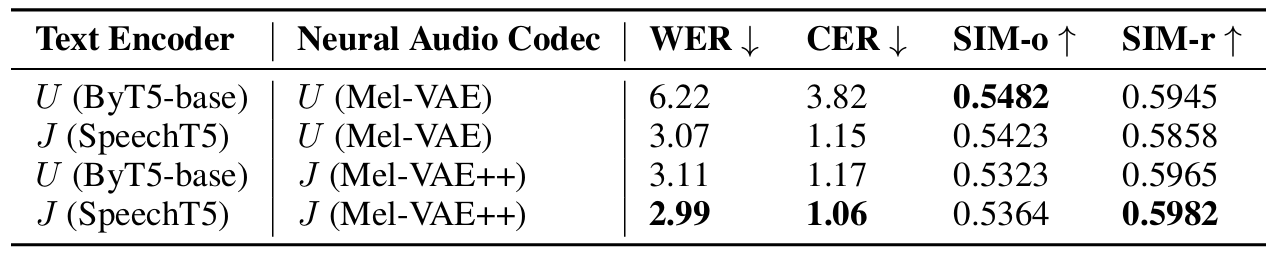
- Ablation Study

반응형
'Paper > TTS' 카테고리의 다른 글
댓글