

티스토리 뷰
Paper/TTS
[Paper 리뷰] DecoupledSynth: Enhancing Zero-Shot Text-to-Speech via Factors Decoupling
feVeRin 2025. 6. 17. 17:20반응형
DecoupledSynth: Enhancing Zero-Shot Text-to-Speech via Factors Decoupling
- 기존의 Zero-Shot Text-to-Speech model은 intermediate representation의 linguistic, para-linguistic, non-linguistic information을 balancing 하는데 어려움이 있음
- DecoupledSynth
- 다양한 self-supervised model을 combine 하여 comprehensive, decoupled representation을 추출
- Decoupled processing stage를 활용하여 nuanced synthesis를 지원
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- Wav2Vec, HuBERT와 같은 speech representation은 synthesis process를 text-to-intermediate representation, intermediate representation-to-speech stage로 decompose 하여 zero-shot Text-to-Speech (TTS)를 지원함
- 이때 일반적으로 intermediate representation은 3가지 category로 나눌 수 있음:
- Overall Speech Representation
- YourTTS, VALL-E와 같이 whole audio에 대한 information을 coupling 하는 representation - Semantic Feature
- UniAudio와 같이 pre-trained model을 통해 얻어지는 intermediate representation - Disentangled Representation
- HierSpeech, NaturalSpeech3와 같이 content, prosody, acoustic detail 등으로 disentangle되는 speech representation
- Overall Speech Representation
- BUT, speech는 inherently complex하므로 앞선 representation framework는 linguistic, para-linguistic, non-linguistic information을 balancing 하는데 어려움이 있음
- Overall speech representation의 경우 모든 aspect를 represent 하지 못하므로 information loss가 발생하고, Semantic representation의 경우 prosody와 같은 para-linguistic을 반영하지 못함
- Decoupled representation의 경우 training하는데 많은 resource가 필요하고 self-supervised output이 incomplete disentanglement를 가질 수 있음
- 이때 일반적으로 intermediate representation은 3가지 category로 나눌 수 있음:
-> 그래서 다양한 self-supervised speech model을 integrate 하여 speech reconstruction과 disentanglement를 확보한 DecoupledSynth를 제안
- DecoupledSynth
- 다양한 self-supervised model을 combine하여 disentangled intermediate representation인 Decom Feature를 추출하는 Decom Features Extractor를 도입
- 이를 통해 data requirment를 줄이고 speech에 대한 comphrehensive representation을 제공함 - Decom Feature를 기반으로 linguistic, para-linguistic, non-linguistic feature를 separately capture 하는 3-stage TTS framework를 적용
- 다양한 self-supervised model을 combine하여 disentangled intermediate representation인 Decom Feature를 추출하는 Decom Features Extractor를 도입
< Overall of DecoupledSynth >
- Disentangled intermediate representation을 기반으로 하는 zero-shot TTS model
- 결과적으로 기존보다 우수한 성능을 달성
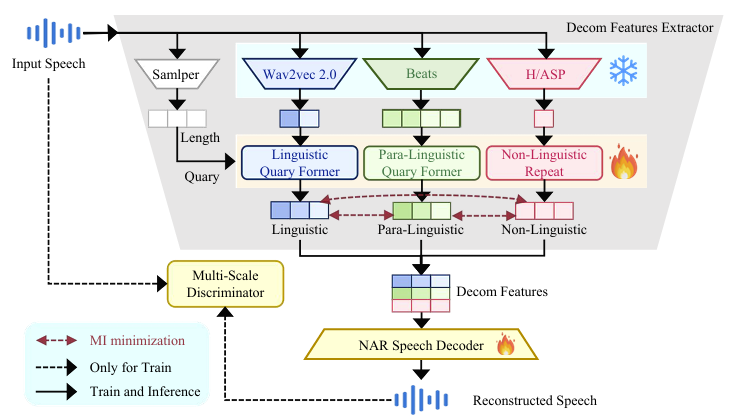
2. Decoupled Components Features
- Decoupled Components Feature (Decom Feature)는 DecoupledSynth에서 다양한 pre-trained feature의 decoupling과 optimization을 위해 사용됨
- 먼저 pre-trained Wav2Vec 2.0과 BEATs는 input speech로부터 linguistic, para-linguistic feature를 추출하기 위해 사용됨
- 해당 feature는 Linguistic/Para-Linguistic Query Former module을 통해 further refine 됨
- 여기서 Query Former는 cross-attention layer와 4개의 Transformer encoder block으로 구성됨 - Transformer encoder block은 feature를 optimize, decouple 하는 데 사용되고, cross-attention layer는 time dimension에 따라 feature length를 aligning 하기 위해 사용됨
- 해당 alignment는 feature가 speech input에서 sampling 된 length로 initialize 된 Query Length feature length에 match 되도록 보장함
- 해당 feature는 Linguistic/Para-Linguistic Query Former module을 통해 further refine 됨
- Non-linguistic feature는 pre-trained H/ASP model을 통해 추출됨
- 해당 model output은 repeat layer를 통해 Query length feature와 동일한 length를 가지고, 모든 pre-trained model은 training stage에서 frozen 됨 - 추가적으로 논문은 VQMIVC의 Mutual Information (MI) minimization loss를 사용하여 linguistic, para-linguistic, non-linguistic feature를 decouple 함
- 이때 NAR Speech Decoder는 normalized flow, posterior encoder, HiFi-GAN vocoder로 구성됨
- 특히 multi-scale discriminator는 Decom Feature가 original speech를 reconstruct 하도록 보장함 - 결과적으로 얻어지는 Decom Feature extractor의 training loss는:
(Eq. 1) $\mathcal{L}_{total}=\mathcal{L}_{MI}+\mathcal{L}_{rec}$
- $\mathcal{L}_{MI}$ : MI minimization loss로써, feature 간의 disentanglement를 measure 함
- $\mathcal{L}_{rec}$ : reconstruction loss로써, multi-scale discriminator로부터 얻어짐
- 이때 NAR Speech Decoder는 normalized flow, posterior encoder, HiFi-GAN vocoder로 구성됨
- 먼저 pre-trained Wav2Vec 2.0과 BEATs는 input speech로부터 linguistic, para-linguistic feature를 추출하기 위해 사용됨
3. Method
- DecoupledSynth는 앞선 Decom Features를 기반으로 3가지 stage로 구성된 framework를 활용함
- Decoupled Prompt Extracting stage에서는 input text, reference speech를 process 함
- Text-to-Decom Features stage에서는 processed text input과 decoupled prompt를 Decom Feature로 변환하여 다양한 linguistic, para-linguistic, non-linguistic element를 capture 함
- Decom Features-to-Speec stage에서는 reconstructed Decom Feature를 final speech output으로 합성함
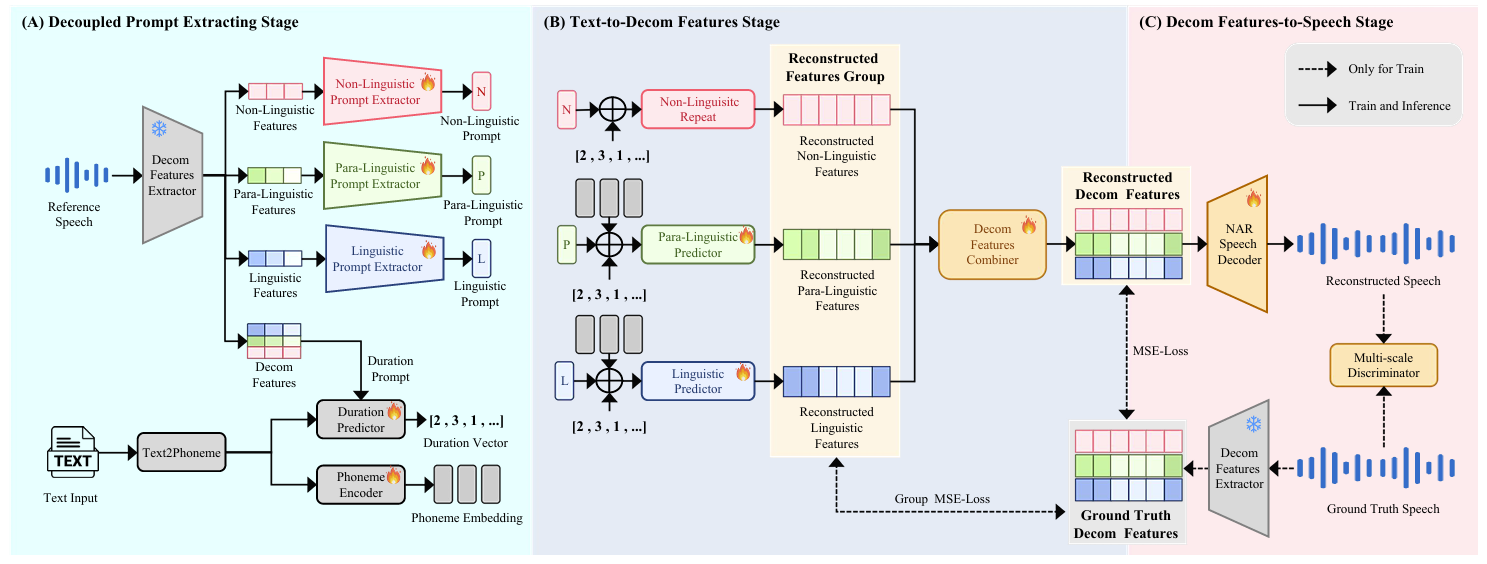
- Decoupled Prompt Extracting Stage
- Decoupled Prompt Extracting stage에서는 input text, reference speech로부터 phoneme embedding, duration vector, multi-perspective prompt를 생성함
- 먼저 reference speech는 앞선 pre-trained Decom Feature extractor를 통해 linguistic, para-linguistic, non-linguistic feature에 대한 3가지 distinct prompt로 decouple 됨
- 이후 해당 feature는 Prompt Extractor를 통해 one-dimensional prompt feature로 변환됨
- 구조적으로 Prompt Extractor는 initial convolutional layer와 multi-head attention block으로 구성됨 - 한편으로 input text는 phoneme으로 변환되고 해당 phoneme은 Phoneme Encoder에 전달되어 phoneme feature를 생성함
- Duration Predictor는 phoneme과 Decom Feature를 input으로 사용하여 각 phoneme의 duration을 represent 하는 duration vector를 predict 함
- Training 시 target duration vector는 Monotonic Alignment Search (MAS)를 통해 얻어짐
- Text-to-Decom Features Stage
- Text-to-Decom Features stage에서는 Decom Feature를 predict 하는 것을 목표로 함
- 먼저 phoneme embedding, duration vector, multi-perspective prompt는 각각 Linguistic Predictor, Para-Linguistic Predictor, Non-Linguistic repeat layer를 통해 process 됨
- 이를 통해 linguistic, para-linguistic, non-linguistic feature를 생성하고, 해당 feature는 Decom Feature Combiner를 통해 combine 되어 reconstructed Decom Feature를 생성함 - Linguistic Predictor는 length regulator, multiple-layer BiLSTM, feature decoder로 구성됨
- Para-Linguistic Predictor는 length regulator, pitch/energy와 같은 para-linguistic information을 위한 variance adaptor, feature decoder로 구성됨
- Predictor의 length regulator, variance adpator는 JETS를 따름 - Decom Feature Combiner는 Postnet network architecture를 사용함
- Para-Linguistic Predictor는 length regulator, pitch/energy와 같은 para-linguistic information을 위한 variance adaptor, feature decoder로 구성됨
- 이때 얻어지는 Text-to-Decom Feature stage loss $\mathcal{L}_{T2D}$는:
(Eq. 2) $\mathcal{L}_{T2D}=\mathcal{L}_{Group}+\mathcal{L}_{Total}$
- $\mathcal{L}_{Group}$ : Group loss로써, decoupled feature의 각 component에 대한 reconstructed feature group과 ground-truth 간의 Mean Squared Error (MSE)로 얻어짐
- $\mathcal{L}_{Total}$ : total loss로써 reconstructed Decom Feature와 ground-truth 간의 MSE에 해당함
- 먼저 phoneme embedding, duration vector, multi-perspective prompt는 각각 Linguistic Predictor, Para-Linguistic Predictor, Non-Linguistic repeat layer를 통해 process 됨
- Decom Features-to-Speech Stage
- Decom Features-to-Speech stage에서는 Decom Feature를 speech로 reconstruct 함
- 여기서 multi-scale discriminator는 reconstructed speech와 ground-truth를 differentiate 하는 데 사용됨
- Training 이전에 NAR Speech Decoder는 pre-trained weight로 initialize 됨 - 그러면 Decom Features-to-Speech stage의 loss function은:
(Eq. 3) $\mathcal{L}_{D2S}=\mathcal{L}_{KL}+\mathcal{L}_{Rec}$
- $\mathcal{L}_{KL}$ : KL-divergence로써, flow model의 output distribution과 Decom Feature의 prior distribution 간의 divergence에 해당함
- $\mathcal{L}_{Rec}$ : reconstruction loss로써, multi-scale discriminator의 adversarial loss와 reconstructed speech, ground-truth 간의 MSE loss를 포함함
- 여기서 multi-scale discriminator는 reconstructed speech와 ground-truth를 differentiate 하는 데 사용됨
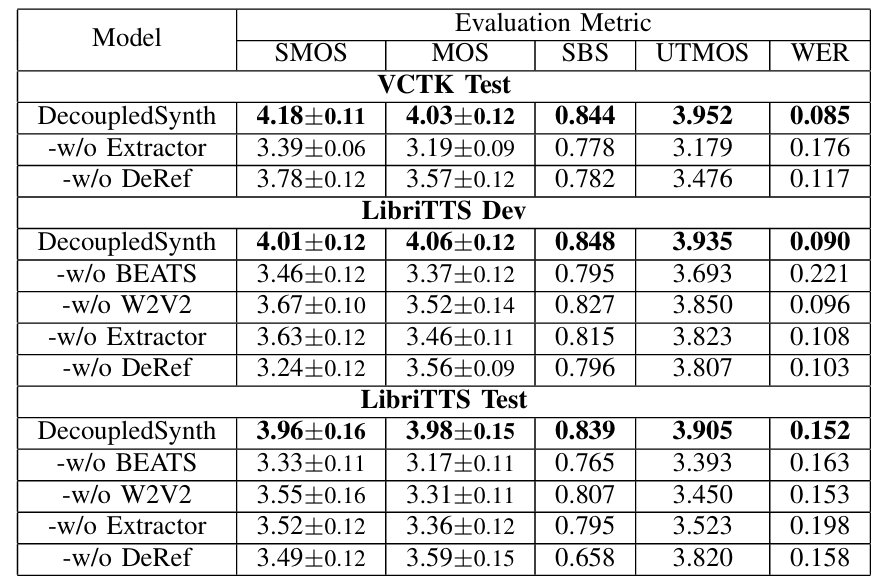
4. Experiments
- Settings
- Results
- 전체적으로 DecoupledSynth의 성능이 가장 우수함

- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함
반응형
'Paper > TTS' 카테고리의 다른 글
댓글