

티스토리 뷰
Paper/Representation
[Paper 리뷰] BEATs: Audio Pre-Training with Acoustic Tokenizers
feVeRin 2025. 6. 28. 08:38반응형
BEATs: Audio Pre-Training with Acoustic Tokenizers
- General audio representation pre-training을 위헌 Self-Supervised Learning framework가 필요함
- BEATs
- Semantic-rich acoustic tokenizer에서 얻어지는 label에 대한 discrete label prediction task를 활용
- Tokenizer와 pre-trained model에 대한 iterative pipeline을 구성
- 논문 (ICML 2023) : Paper Link
1. Introduction
- Wav2Vec 2.0, HuBERT, WavLM, Data2Vec 등의 speech Self-Supervised Learning (SSL) model은 다양한 speech processing task에 적용될 수 있음
- Speech와 달리 audio는 human voice 뿐만 아니라 nature sound, musical beats 등의 wide variation을 포함하므로 general audio modeling이 필요함
- 특히 기존의 audio SSL model은 acoustic feature reconstruction loss를 pre-training objective로 사용함
- BUT, reconstruction loss는 low-level time-frequency feature만을 고려하고 high-level audio semantic abstraction은 neglect 함 - 한편으로 discrete label prediction은 reconstruction loss에 비해 다음의 이점을 가짐:
- Low-level time-frequency detail에 focus 하기보다 high-level semantic을 추출하고 clustering 하여 audio를 understand 할 수 있음
- Semantic-rich token을 pre-training target으로 제공하여 audio modeling을 개선할 수 있음
- Language, speech, vision 간의 unification을 지원할 수 있음
-> 그래서 discrete label prediction을 활용한 general audio SSL framework인 BEATs를 제안
- BEATs
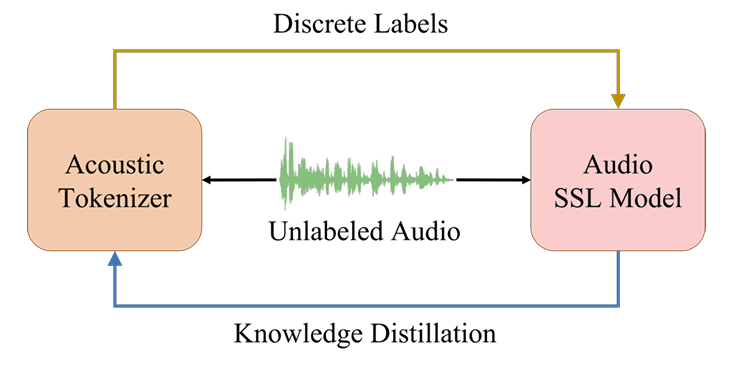
- Acoustic tokenzier와 audio SSL model을 iterative audio pre-training을 통해 optimize
- Convergence 이후 audio tokenizer는 audio SSL model을 teacher로 사용하여 knowledge distillation을 통해 audio semantic을 학습
< Overall of BEATs >
- Iterative audio pre-training과 knowledge distillation 기반의 alternating update learning을 활용한 SSL model
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
- Iterative Audio Pre-Training
- BEATs의 iterative audio pre-training framework에서 acoustic tokenizer와 audio SSL model은 iteration을 통해 optimize 됨
- 각 iteration에서 unlabeled audio가 주어지면 acoustic tokenizer를 사용하여 discrete label을 생성하고, 이를 통해 mask, discrete label prediction loss를 얻은 다음 audio SSL model을 training 함
- Convergence 이후에는 audio SSL model을 teacher로 사용하여 knowledge distillation을 통해 새로운 acoustic tokenizer를 training 함 - Audio clip이 input으로 주어지면, 해당 acoustic feature를 추출하고 regular grid patch로 split 한 다음, patch sequence $\mathbf{X}=\{\mathbf{x}_{t}\}_{t=1}^{T}$로 further flatten 함
- Audio SSL model training의 경우, acoustic tokenizer를 사용하여 patch sequence $\mathbf{X}$를 patch-level discrete label $\hat{\mathbf{Z}}=\{\hat{\mathbf{z}}_{t}\}_{t=1}^{T}$로 quantize한 다음, 이를 masked prediction target으로 사용함
- Acoustic tokenizer training의 경우에는 audio SSL model을 활용하여 patch sequence $\mathbf{X}$를 encode 하고 output sequence $\hat{\mathbf{O}}=\{\hat{\mathbf{o}}_{t}\}_{t=1}^{T}$을 knowledge distillation target으로 추출함
- 이때 acoustic tokenizer training을 위한 teacher로써 pre-trained audio SSL model이나 fine-tuned audio SSL model을 사용할 수 있음
- 특히 fine-tuned model은 audio semantic distillation에 대한 더 나은 teacher가 될 수 있음 - 결과적으로 acoustic tokenizer는 audio SSL model이 encode 한 semantic-rich knowledge를 활용하고, audio SSL model은 acoustic tokenizer가 생성한 semantic-rich discrete label을 활용할 수 있음
- 각 iteration에서 unlabeled audio가 주어지면 acoustic tokenizer를 사용하여 discrete label을 생성하고, 이를 통해 mask, discrete label prediction loss를 얻은 다음 audio SSL model을 training 함
- Acoustic Tokenizers
- Acoustic tokenizer는 BEATs pre-training의 각 iteration에 대한 discrete label을 생성하는 데 사용됨
- First iteration에서는 teacher model이 없으므로 Random-Projection Tokenizer를 사용하여 continuous acoustic feature를 discrete label로 cluster 하는 cold start를 적용함
- Second iteration부터는 last iteration에서 얻은 pre-trained/fine-tuned audio SSL model의 distilled semantic-aware knowledge를 반영한 refined discrete label을 생성하는 Self-Distilled Tokenizer를 training 함
- Cold Start: Random-Projection Tokenizer
- BEATs pre-training의 first iteration에서는 Random-Projection Tokenizer를 사용하여 각 input audio에 대한 patch-level discrete label을 생성함
- Random-Projection Tokenizer는 linear projection layer, random initialization 이후에 frozen 되는 codebook embedding set를 가짐
- Input feature의 각 patch는 linear layer를 통해 projection 된 다음, codebook embedding 중에서 nearest neighbor vector를 find 함
- Nearest neighbor index는 discrete label로 사용됨
- Input audio $\mathbf{X}=\{\mathbf{x}_{t}\}_{t=1}^{T}$에서 추출된 patch sequence에 대해,
- 논문은 먼저 randomly initialized projection layer $\mathbf{W}$를 사용하여 $\mathbf{x}_{t}$를 vector $\mathbf{Wx}_{t}$로 project 함
- 이후 random initialized vector set $\mathbf{V}=\{\mathbf{v}_{i}\}_{i=1}^{K}$에서 projected vector $\mathbf{Wx}_{t}$의 nearest neighbor를 look up 함
- $K$ : codebook size - 최종적으로 $t$-th patch의 discrete label을 nearest neighbor vector의 index로 사용함:
(Eq. 1) $ \hat{\mathbf{z}}_{t}=\arg\min_{i}\left|\left| \mathbf{v}_{i}-\mathbf{Wx}_{t}\right|\right|_{2}^{2}$
- Iteration: Self-Distilled Tokenizer
- BEATs pre-training의 second iteration 이후부터는 current iteration tokenizer learning을 teach 하기 위해 last iteration audio SSL model을 teacher로 사용함
- 여기서 self-distilled tokenizer는 각 input audio에 대한 patch-level discrete label을 생성함 - 먼저 self-distilled tokenizer는 Transformer-based tokenizer encoder를 사용하여 input patch를 learnable codebook embedding set을 가지는 discrete label로 convert 함
- 이후 Transformer-based tokenizer estimator는 teacher model output, discrete label을 input으로 사용하여 teacher model output을 predict 하도록 training 됨
- Knowledge distillation을 training target으로 사용함으로써, tokenized discrete label은 teacher model의 semantic-rich knowledge를 포함하고 input audio에 대한 redundant information은 제외하도록 optimize 됨
- 구체적으로 논문은 input patch $\mathbf{X}=\{\mathbf{x}_{t}\}_{t=1}^{T}$를 12-layer Transformer encoder에 전달하여 encoded vector sequence $\mathbf{E}=\{\mathbf{e}_{t}\}_{t=1}^{T}$를 얻음
- 이후 각 encoded vector $\mathbf{e}_{t}$에 대해 codebook embedding $\mathbf{V}=\{\mathbf{v}_{i}\}_{i=1}^{K}$에서 nearest neighbor vector $\mathbf{v}_{\hat{\mathbf{z}}_{t}}$를 finding 하는 방식으로 quantization을 수행함:
(Eq. 2) $ \hat{\mathbf{z}}_{t}=\arg\min_{i}\left|\left|\ell_{2}(\mathbf{v}_{i}) -\ell_{2}(\mathbf{e}_{t})\right|\right|_{2}^{2}$
- $\ell_{2}$ normalization은 codebook utilization을 향상하기 위해 사용됨 - 다음으로 quantized vector sequence $\mathbf{E}^{q}=\{\mathbf{v}_{\hat{\mathbf{z}}_{t}}\}_{t=1}^{T}$를 input으로 사용하여 3-layer Transformer estimator는 teacher model의 last layer output $\{\hat{\mathbf{o}}_{t}\}_{t=1}^{T}$를 predict 함
- 이때 vector quantization의 non-differentiable 문제를 해결하기 위해, 논문은 straight-through gradient mechanism을 도입함
- 즉, gradient가 backward process에서 quantized vector sequence $\mathbf{E}^{q}$로부터 encoded vector sequence $\mathbf{E}$로 directly copy 됨
- 이후 각 encoded vector $\mathbf{e}_{t}$에 대해 codebook embedding $\mathbf{V}=\{\mathbf{v}_{i}\}_{i=1}^{K}$에서 nearest neighbor vector $\mathbf{v}_{\hat{\mathbf{z}}_{t}}$를 finding 하는 방식으로 quantization을 수행함:
- Self-distilled tokenizer의 overall training objective는 tokenizer estimator output sequence $\{\mathbf{o}_{t}\}_{t=1}^{T}$와 teacher model output sequence $\{\hat{\mathbf{o}}_{t} \}_{t=1}^{T}$ 간의 cosine-similarity로 정의됨:
(Eq. 3) $\mathcal{L}=\max\sum_{\mathbf{X}\in\mathcal{D}}\sum_{t=1}^{T}\cos\left(\mathbf{o}_{t},\hat{\mathbf{o}_{t}}\right) -\left|\left| \text{sg}[\ell_{2}(\mathbf{e}_{t})]-\ell_{2}(\mathbf{v}_{\hat{\mathbf{z}}_{t}} )\right|\right|_{2}^{2}-\left|\left|\ell_{2}(\mathbf{e}_{t})-\text{sg}[\ell_{2}(\mathbf{v}_{\hat{\mathbf{z}}_{t}})] \right|\right|_{2}^{2}$
- 이때 encoded vector sequence $\mathbf{E}=\{\mathbf{e}_{t}\}_{t=1}^{T}$와 quantized vector sequence $\mathbf{E}^{q}=\{\mathbf{v}_{\hat{\mathbf{z}}_{t}} \}_{t=1}^{T}$ 간의 Mean Squared Error도 포함됨
- $\mathcal{D}$ : pre-training dataset, $\cos(\cdot,\cdot)$ : cosine-similarity, $\text{sg}[\cdot]$ : stop-gradient operation - 추가적으로 논문은 codebook embedding optimization을 위해 Exponential Moving Average를 사용하여 stable tokenizer training을 지원함
- 추론 시에는 tokenizer estimator를 discard 하고 pre-trained tokenizer encoder와 codebook embedding을 사용하여 각 input audio $\mathbf{X}=\{\mathbf{x}_{t}\}_{t=1}^{T}$를 patch-level discrete label $\hat{\mathbf{Z}}=\{\hat{\mathbf{z}}_{t}\}_{t=1}^{T}$로 convert 함
- BEATs pre-training의 second iteration 이후부터는 current iteration tokenizer learning을 teach 하기 위해 last iteration audio SSL model을 teacher로 사용함

- Audio SSL Model
- Backbone
- 논문은 linear projection layer, Transformer encoder layer stack으로 구성된 ViT를 backbone으로 채택함
- 여기서 Transformer는 bottom에 convolution-based relative position embedding을 가지고, 더 나은 position information encoding을 위해 gated relative position bias를 사용함
- 추가적으로 stable pre-training을 위해 DeepNorm이 적용됨
- 결과적으로 input audio patch $\mathbf{X}=\{\mathbf{x}_{t}\}_{t=1}^{T}$가 주어지면, linear projection network를 통해 patch embedding $\mathbf{E}=\{\mathbf{e}_{t}\}_{t=1}^{T}$로 convert 함
- 이후 patch embedding을 Transformer encoder layer에 전달하여 encoded patch representation $\mathbf{R}=\{\mathbf{r}_{t}\}_{t=1}^{T}$를 얻음
- 논문은 linear projection layer, Transformer encoder layer stack으로 구성된 ViT를 backbone으로 채택함
- Pre-Training
- Audio SSL model pre-training을 위해 Masked Audio Modeling (MAM) task를 활용함
- 즉, BEATs는 acoustic tokenizer에서 생성된 patch-level discrete label을 label predictor를 사용하여 predict 하도록 optimize 됨 - Input patch sequence $\mathbf{X}=\{\mathbf{x}_{t}\}_{t=1}^{T}$와 target discrete acoustic label $\hat{\mathbf{Z}}=\{\hat{\mathbf{z}}_{t}\}_{t=1}^{T}$가 주어지면, 먼저 input patch의 $75\%$를 randomly mask 함
- 이때 masked position은 $\mathcal{M}=\{1,...,T\}^{0.75T}$와 같음
- 이후 unmasked patch sequence $\mathbf{X}^{U}=\{\mathbf{x}_{t}:t\in\mathcal{M}\}_{t=1}^{T}$를 ViT encoder에 input 하여 encoded representation $\mathbf{R}^{U}=\{\mathbf{r}_{t}:t\in\mathcal{M}\}_{t=1}^{T}$를 얻음
- 최종적으로 non-masked patch, masked patch feature의 combination $ \{\mathbf{r}_{t}:t\in\mathcal{M}\}_{t=1}^{T}\cup\{\mathbf{0}:t\notin \mathcal{M}\}_{t=1}^{T}$을 label predictor에 전달하여 discrete acoustic label $\mathbf{Z}=\{\mathbf{z}_{t}\}_{t=1}^{T}$를 predict 함
- MAM의 pre-training objective는 cross-entropy loss로 정의됨:
(Eq. 4) $\mathcal{L}_{MAM}=-\sum_{t\in\mathcal{M}}\log p(\hat{\mathbf{z}}_{t}|\mathbf{X}^{U})$
- Audio SSL model pre-training을 위해 Masked Audio Modeling (MAM) task를 활용함
- Fine-Tuning
- Audio SSL model fine-tuning 중에 label predictor를 discard 하고 task-specific linear classifier를 ViT encoder에 append 하여 downstream classification task에 대한 label을 생성할 수 있음
- 먼저 input acoustic feature를 time, frequency dimension에서 random mask 하여 spec-augmentation을 수행한 다음 split, flatten 하여 patch sequence $\mathbf{X}=\{\mathbf{x}_{t}\}_{t=1}^{T}$를 얻음
- Pre-training과 달리 whole patch sequence $\mathbf{X}$를 ViT에 전달하여 encoded representation $\mathbf{R}=\{\mathbf{r}_{t}\}_{t=1}^{T}$를 얻음
- 최종적으로는 linear classifier를 사용하여 cateogry probability를 calculate 함:
(Eq. 5) $p(C)=\text{Softmax}\left(\text{MeanPool}\left(\mathbf{W}_{c}\mathbf{R}\right)\right)$
- $\text{Softmax}$ : Softmax operation, $\text{MeanPool}$ : Mean-pooling layer, $\mathbf{W}_{c}$ : linear projection
- 논문은 single label classification task에 대한 fine-tuning의 경우 cross-entropy loss를 사용하고, multi-label classification task의 경우 binary cross-entropy loss를 사용함

3. Experiments
- Settings
- Dataset : AudioSet
- Comparisons : Wav2Vec, Wav2Vec 2.0, Data2Vec 등
- Results
- 전체적으로 BEATs의 성능이 가장 우수함

- Comparing Different BEATs Tokenizers
- Self-distilled tokenizer를 사용하는 경우 최고의 성능을 달성할 수 있음

- Comparing Different Pre-Training Targets
- $t$-SNE 측면에서 pre-training target을 비교해 보면, BEATs는 random variation에 robust 한 것으로 나타남

- Comparing with SOTA Ensemble Models
- Ensemble model과 비교하여도 BEATs는 더 뛰어난 성능을 보임

반응형
'Paper > Representation' 카테고리의 다른 글
댓글