

티스토리 뷰
Paper/TTS
[Paper 리뷰] HierSpeech: Bridging the Gap between Text and Speech by Hierarchical Variational Inference using Self-Supervised Representations for Speech Synthesis
feVeRin 2024. 3. 29. 11:29반응형
HierSpeech: Bridging the Gap between Text and Speech by Hierarchical Variational Inference using Self-Supervised Representations for Speech Synthesis
- Text로부터 raw waveform을 직접 생성하는 end-to-end pipeline은 고품질의 합성이 가능하지만, mispronunciation이나 over-smoothing 문제가 종종 발생함
- HierSpeech
- 고품질의 end-to-end text-to-speech를 위해 self-supervised speech representation을 활용하는 hierarchical variational autoencoder 구조
- Self-supervised speech representation의 추출을 통해 text와 speech 사이의 information gap을 줄여 mispronunciation 문제를 회피
- 논문 (NeurIPS 2022) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 일반적으로 acoustic model과 vocoder의 two-stage 방식으로 구성됨
- BUT, 이러한 two-stage 방식은 아래의 한계점이 있음
- One-to-many mapping 문제로 인해 음성의 다양한 attribute를 반영하지 못함
- Pipeline에서 각 구성요소들이 개별적으로 training 되므로 품질이 저하됨
- 한편으로 single-stage end-to-end TTS 모델은 앞선 한계점을 극복하기 위해 제안됨
- 대표적으로 VITS는 normalizing flow와 adversarial training을 활용하여 우수한 TTS 성능을 달성했음
- BUT, end-to-end TTS 모델은 종종 text와 speech 간의 information gap으로 인해 mispronunciation이나 over-smothing 문제가 발생함 - 이때 text와 speech 간의 information gap을 줄이기 위해 self-supervised speech representation을 additional linguistic representation으로 사용할 수 있음
- Large-scale speech dataset으로 train 된 해당 representation은 labeled data 없이도 유용한 information을 반영할 수 있음
- 특히 pre-trained model의 middle layer에는 pronunciation characteristic을 가지는 rich linguistic information이 포함되어 있음
- 결과적으로 이러한 representation을 TTS 모델에 적용하면 성능을 크게 향상할 수 있음
- Large-scale speech dataset으로 train 된 해당 representation은 labeled data 없이도 유용한 information을 반영할 수 있음
- BUT, 이러한 two-stage 방식은 아래의 한계점이 있음
-> 그래서 end-to-end TTS 모델에서 self-supervised speech representation을 활용하는 hierarchical conditional variational autoencoder인 HierSpeech를 제안
- HierSpeech
- Self-supervised speech representation을 활용하여 latent representation의 linguistic information을 풍부하게 만들고, 각 attribute를 hierarchical 하게 학습함
- 특히 end-to-end TTS 모델에 대해 self-supervised representation을 반영하여 speech와 text 간의 information gap을 해소함
- 추가적으로 pre-trained HierSpeech를 기반으로 adaptive TTS를 위한 HierSpeech-U를 확장
< Overall of HierSpeech >
- Text와 speech 간의 information gap을 해소하여 reconstruction 품질을 크게 향상하는 self-supervised representation을 hierarchical conditional variational autoencoder에 통합
- 추가적으로 untranscribed speech data에 대한 TTS를 가능하게 하는 HierSpeech-U로 모델을 확장
- 결과적으로 기존 모델들 보다 우수한 합성 품질을 달성
2. HierSpeech
- HierSpeech는 end-to-end TTS에 대해 self-supervised representation을 사용하는 hierarchical conditional variational autoencoder 구조
- Latent representation의 linguistic information을 개선하고 각 representation을 hierarchical 하게 학습하기 위해 self-supervised speech representation을 채택
- 추가적으로 HierSpeech를 HierSpeech-U로 확장하여 text transcript 없이 모델을 adapt 함

- Speech Representations
- Acoustic Representations
- 일반적으로 mel-spectrogram은 STFT를 통해 waveform으로부터 얻어지는 intermediate acoustic feature로 자주 활용됨
- BUT, 이러한 acoustic feature는 pronunciation과 같은 linguistic information과 rhythm, timbre 등과 같은 style information으로 구분됨 - 따라서 acoustic representation의 rich feature를 text 만으로 합성하면 one-to-many 문제가 exacerbate 되고, spectrogram으로부터 expressive linguistic information을 추출하기 어려워짐
- 이를 해결하기 위해, text와 acoustic feature를 mapping 하는 additional linguistic feature를 채택해야 함
- 일반적으로 mel-spectrogram은 STFT를 통해 waveform으로부터 얻어지는 intermediate acoustic feature로 자주 활용됨
- Linguistic Representations
- Text와 speech 사이의 gap을 완화하기 위해, additional intermediate linguistic feature에 대한 self-supervised speech representation을 사용함
- 특히 wav2vec 2.0과 같은 pre-trained 모델에서 추출된 feature에는 rich linguistic information이 포함되어 있고, 이를 통해 speech recognition, translation과 같은 다양한 task를 향상할 수 있음
- 추가적으로 wave2vec 2.0의 middle layer에는 pronunciation과 관련된 linguistic information이 상당히 포함되어 있는 것으로 나타남 - 따라서 HierSpeech는 large-scale cross-lingual speech dataset으로 pre-train 된 wav2vec 2.0인 XLS-R의 12th layer에서 self-supervised speech representation을 추출하여 사용함

- Hierarchical Variational Inference
- HierSpeech는 end-to-end TTS를 위해 VITS에 기반한 conditional variational autoencoder 구조를 채택함
- 이때 VITS는 data log $p_{\theta}(x|c)$의 intractable margnial log-likelihood에 대한 Evidence Lower BOund (ELBO)를 최대화하도록 학습됨:
(Eq. 1) $\log p_{\theta}(x|c)\geq \mathbb{E}_{q_{\phi}(z|x)}\left[\log p_{\theta}(z|x)-\log\frac{q_{\phi}(z|x)}{p_{\theta}(z|c)}\right]$
- $p_{\theta}(z|c)$ : condition $c$가 주어졌을 때 latent variable $z$에 대한 prior 분포
- $p_{\theta}(x|z)$ : latent $z$가 주어졌을때 data $x$를 생성하는 likelihood function으로써, decoder의 역할
- $q_{\phi}(z|x)$ : 근사 posterior
- 이때 VITS는 normalizing flow를 사용하여 waveform domain에서 prior 분포의 expressiveness를 향상함 - HierSpeech는 해당 VITS의 conditional variational autoencoder를 사용하여 speech representation의 disentangled latent variable로써 multi-level intermediate representation을 연결하고, 이를 end-to-end 방식으로 학습함
- 이때 서로 conditioning 하는 top-down path newtork 방식 대신 개별적으로 speech representation을 근사함
- 예시로 acoustic posterior와 linguistic posterior 분포는 각각 acoustic encoder $\phi_{a}$와 linguistic encoder $\phi_{l}$에 의해 개별적으로 encoding 됨 - 각 latent variable을 disentangle 하기 위해 rich acoustic representation $z_{a}$에 대해 target speech의 linear-scale spectrogram $x_{spec}$을 사용하고, rich linguistic representation $z_{l}$에 대해 XLS-R의 12-th layer output $x_{w2v}$을 사용함
- 결과적으로 HierSpeech의 optimization objective는:
(Eq. 2) $\log p_{\theta}(x|c)\geq\mathbb{E}_{q_{\phi}(z|x)}\left[\log p_{\theta_{d}}(x|z_{a})-\log \frac{q_{\phi_{a}}(z_{a}|x_{spec})}{p_{\theta_{a}}(z_{a}|z_{l})}-\log\frac{q_{\phi_{l}}(z_{l}|x_{w2v})}{p_{\theta_{l}}(z_{l}|c)}\right]$
- $z=[z_{a},z_{l}], \theta=[\theta_{d},\theta_{a},\theta_{l}], \phi=[\phi_{a},\phi_{l}]$
- $q_{\phi_{a}}(z_{a}|x_{spec}), q_{\phi_{l}}(z_{l}|x_{w2v})$ : 각각 acoustic, linguistic representation에 대한 근사 posterior
- $p_{\theta_{l}}(z_{l}|c)$ : 주어진 condition $c$에 대한 linguistic latent variable $z_{l}$에 대한 prior 분포
- $p_{\theta_{a}}(z_{a}|z_{l})$ : acoustic latent variable $z_{a}$에 대한 prior 분포
- 여기서 $z_{l}$은 $q_{\phi_{l}}(z_{l}|x_{w2v})$에서 sampling 되고, $p_{\theta_{d}}(x|z_{a})$는 decoder $\theta_{d}$로써 latent variable $z_{a}$가 주어지면 data $x$를 생성하는 likelihood function - Reconstruction loss의 경우 STFT와 mel-scale transformation을 사용하여 ground-truth와 reconstructed waveform 간의 mel-spectrogram의 $l1$ distance를 최소화하는 mel-reconstruction loss $\mathcal{L}_{rec}$를 사용함
- 이때 VITS는 data log $p_{\theta}(x|c)$의 intractable margnial log-likelihood에 대한 Evidence Lower BOund (ELBO)를 최대화하도록 학습됨:
- Acoustic Encoder and Waveform Decoder
- Acoustic encoder $\phi_{a}$는 gated activation과 skip connection을 가지는 dilated convolution을 사용하는 non-casual WaveNet으로 구성됨
- 이후 output은 reparameterization trick을 사용하여 posterior 분포의 평균, 분산으로부터 acoustic representation $z_{a}$를 sampling 하는 projection layer로 제공됨
- Training 중에 sliced $z_{a}$는 raw audio $x$를 reconstruct 하기 위해 waveform decoder에 공급됨 - HierSpeech는 waveform decoder $\theta_{d}$로써 HiFi-GAN generator $G$를 사용함
- Adversarial feedback은 multi-period discriminator $D$를 사용하여 waveform의 다양한 periodic feature를 capture 함:
(Eq. 3) $\mathcal{L}_{adv}(D)=\mathbb{E}_{(x,z_{a})}\left[(D(x)-1)^{2}+D(G(z_{a}))^{2}\right]$
(Eq. 4) $\mathcal{L}_{adv}(\phi_{a},\theta_{d})=\mathbb{E}_{(z_{a})}\left[(D(G(z_{a}))-1)^{2}\right]$
- $x$ : ground-truth waveform
- Stable training을 위해 ground-truth와 reconstructed waveform 사이의 각 discriminator feature의 $l1$ loss를 최소화하는 feature matching loss $\mathcal{L}_{fm}$을 추가함
- Acoustic encoder $\phi_{a}$는 gated activation과 skip connection을 가지는 dilated convolution을 사용하는 non-casual WaveNet으로 구성됨
- Linguistic Encoder and Phoneme Predictor
- Linguistic encoder $\phi_{l}$은 acoustic encoder와 동일한 구조를 가짐
- 대신, pre-trained XLS-R에서 얻어진 self-supervised speech representation $x_{w2v}$을 linguistic encoder의 input으로 사용하여 linguistic representation $z_{l}$을 추출함
- 이때 linguistic characteristic을 enforce 하기 위해 $z_{l}$은 auxiliary phoneme predictor에 제공됨 - Linguistic encoder와 phoneme predictor를 최적화하기 위해 Connectionist Temporal Classification (CTC) loss $\mathcal{L}_{ctc}$를 최소화함
- 여기서 additional projection layer를 제거하기 위해 linguistic encoder의 projected 평균과 분산을 $\theta_{a}, \phi_{l}$ 사이의 weight-sharing을 통해 acoustic prior 분포로 사용함 - Hierarchy를 유지하기 위해 representation $z_{a}$는 normalizing flow를 통해 변환되고, 결과적으로 acoustic prior와 posterior 간의 KL-divergence는:
(Eq. 5) $\mathcal{L}_{kl1}=\log q_{\phi_{a}}(z_{a}|x_{spec})-\log p_{\theta_{a}}(z_{a}|x_{w2v})$ - Acoustic prior 분포는 linguistic information으로부터 얻어지기 때문에, 분포의 gap을 줄이기 위해 normalizing flow를 사용하여 acoustic posterior를 disentangle 하고 acoustic piror 분포의 expressiveness를 향상함:
(Eq. 6) $p_{\theta_{a}}(z_{a}|x_{w2v})=\mathcal{N}(f_{a}(z_{a});\mu_{\theta_{a}}(x_{w2v}),\sigma_{\theta_{a}}(x_{w2v})) | \det(\partial f_{a}(z_{a})/\partial z_{a}) |,$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,z_{a}\sim q_{\phi_{a}}(z_{a}|x_{spec})=\mathcal{N}(z_{a};\mu_{\phi_{a}}(x_{spec}),\sigma_{\phi_{a}}(x_{spec}))$
- Linguistic encoder $\phi_{l}$은 acoustic encoder와 동일한 구조를 가짐
- Text Encoder
- Text encoder $\theta_{l}$은 relative positional representation을 사용하는 stacked feed-forward Transformer network로 구성됨
- Phoneme sequence $c_{text}$는 text encoder에 공급되고, projection layer는 linguistic prior 분포에 대한 평균, 분산을 생성하는 데 사용됨 - Text를 음성의 linguistic representation과 align 하기 위해 data의 likelihood를 최대화하여 alignment $A$를 search 하는 Monotonic Alignment Search (MAS)를 사용함:
(Eq. 7) $\mathcal{L}_{kl2}=\log q_{\phi_{l}}(z_{l}|x_{w2v})-\log p_{\theta_{l}}(z_{l}|c_{text},A)$ - 추가적으로 linguistic prior 분포의 expressiveness를 높이기 위해 normalizing flow를 사용함:
(Eq. 8) $p_{\theta_{l}}(z_{l}|c_{text},A)=\mathcal{N}(f_{l}(z_{l});\mu_{\theta_{l}}(c_{text},A),\sigma_{\theta_{l}}(c_{text},A))| \det (\partial f_{l}(z_{l})/\partial z_{l})|,$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,z_{l}\sim q_{\phi_{l}}(z_{l}|x_{w2v})=\mathcal{N}(z_{l};\mu_{\phi_{l}}(x_{w2v}),\sigma_{\phi_{l}}(x_{w2v}))$ - 주어진 phoneme의 duration을 sampling 하기 위해 maximum likelihood estimation으로 training 된 flow-base stochastic duration predictor를 채택함
- 해당 predictor의 negative variational lower bound를 duration loss $\mathcal{L}_{dur}$로 사용
- Multi-speaker의 경우 acoustic residual block에 global embedding을 추가함
- Text encoder $\theta_{l}$은 relative positional representation을 사용하는 stacked feed-forward Transformer network로 구성됨
- Total Loss
- 최종적으로 HierSpeech의 final objective는:
(Eq. 9) $\mathcal{L}_{total}=\mathcal{L}_{kl1}+\lambda_{kl2}\mathcal{L}_{kl2}+\lambda_{rec}\mathcal{L}_{rec}+\lambda_{ctc}\mathcal{L}_{ctc}+\lambda_{dur}\mathcal{L}_{dur}+\lambda_{adv}\mathcal{L}_{adv}(\phi_{a},\theta_{d})+\lambda_{fm}\mathcal{L}_{fm}$
- 최종적으로 HierSpeech의 final objective는:
- Untranscribed Text-to-Speech
- Untranscribed TTS 모델 (HierSpeech-U)의 경우, 음성에서 style embedding을 global conditioning으로써 추출하는 style encoder를 사용하여 training 함
- 이때 style encoder의 input으로 linear scale spectrogram을 사용하고, multi-speaker dataset으로 pre-training 한 다음 text transcript 없이 adaptation을 수행함
- Pre-trained linguistic encoder는 self-supervised speech representation을 통해 text transcript 없이도 음성에서 rich linguistic representation을 추출할 수 있음
- 결과적으로 HierSpeech-U는 speech data 만으로 acoustic encoder, acoustic prior의 normalizing flow, decoder를 fine-tuning 하여 새로운 speaker style로 음성을 합성함
3. Experiments
- Settings
- Dataset : VCTK, LibriTTS
- Comparisons : Tacotron2, Glow-TTS, PortaSpeech, VITS
- Results
- Analysis of Self-Supervised Representations
- Speaker encoder의 input으로 linear spectrogram, XLS-R의 첫 번째 layer와 12번째 layer를 비교
- Linear spectrogram이 XLS-R representation 보다 더 나은 transfer performance를 보임
- 결과적으로 linear spectrogram에는 speaker characteristic에 대한 high-resolution information이 포함되어 있다고 볼 수 있음

- XLS-R의 speech disentanglement 성능을 알아보기 위해, linguistic latent variable $z_{l}$에 대해 frame-level speaker classification을 수행
- 각 layer의 representation에는 classify 할 speaker information이 포함되어 있음
- Speaker information은 linguistic encoder를 통해 reduce 되므로 12번째 XLS-R layer의 $z_{l}$은 가장 낮은 accuracy를 보임
- 이때 23-th layer를 제외한 모든 representation은 VITS와 비교하여 HierSpeech의 TTS 성능을 향상함
- 모든 representation에 large-scale speech dataset으로 학습된 rich information이 포함되어 있음을 의미

- Evaluation on TTS
- HierSpeech는 VCTK, LibriTTS 모두에 대해서 기존 모델보다 우수한 성능을 보임
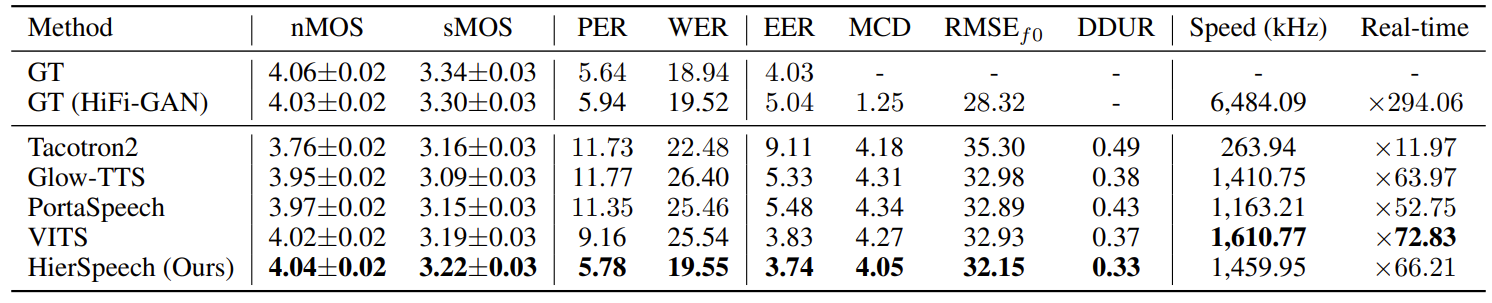

- 마찬가지로 각 dataset으로 학습된 모델 간의 CMOS 비교에서도, HierSpeech는 VITS 보다 뛰어난 성능을 보임

- Untranscribed Text-to-Speech
- Few-shot speaker adaptation 성능을 비교해 보면, HierSpeech-U는 text transcript 없이도 HierSpeech와 유사한 수준의 합성 성능을 보임
- 이는 self-supervised speech representation을 활용하여 speaker adaptation이 가능하기 때문

- 다양한 수의 adaptation sample을 사용하여 adaptation 품질을 평가해 보면, sample 수가 늘어날수록 Equal Error Rate (EER)은 감소하는 것으로 나타남

- Ablation Study
- Normalizing flow의 수를 늘리는 것이 항상 성능 향상으로 이어지지는 않음
- 이때 Phoneme Predictor (PP)를 posterior encoder에 추가하면 alignment search를 guiding 하여 PER, WER을 향상할 수 있음

- Evaluation on VC
- Speech disentanglement 성능을 평가하기 위해 voice conversion 모델과 비교해 보면
- 결과적으로 HierSpeech가 다른 모델들에 비해 우수한 성능을 보임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글