

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
feVeRin 2023. 10. 17. 11:16반응형
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
- Generative Adversarial Network (GAN)을 활용한 음성 합성은 autoregressive에 비해 낮은 품질을 보임
- 하지만 GAN을 활용하면 sampling과 메모리 효율성을 향상할 수 있음
- HiFi-GAN
- 다양한 period를 가지는 sinusoidal pattern을 모델링
- Autoregressive 모델보다 더 빠르고 고품질의 음성을 합성
- 논문 (NeurIPS 2020) : Paper Link
1. Introduction
- 대부분의 음성 합성 모델은 two-stage 구조를 가짐
- Text로 부터 mel-spectrogram이나 linguistic feature 같은 intermediate representation을 예측
- Intermediate representation에서 raw waveform 오디오를 합성
- Two-stage 모델의 합성 품질 향상을 위해 WaveNet과 같은 autoregressive (AR) 모델을 주로 활용함
- AR 모델은 high temporal resolution의 오디오를 합성하는데 시간이 오래 걸림
- 각 forward operation 마다 하나의 sample을 생성하기 때문 - Flow-based 모델은 AR 모델의 생성 속도를 개선할 수 있음
- 동일한 크기의 noise sequence를 변환하여 raw waveform으로 모델링
- 여전히 많은 parameter가 필요한 단점 - 음성 합성을 위해 Generative Adversarial Network (GAN)을 활용할 수도 있음
- MelGAN generator는 CPU에서 real-time 합성을 가능하게 할 만큼 빠른 음성 합성을 지원함
- GAN-TTS 같은 모델은 WaveNet보다 더 적은 FLOP을 가짐
- BUT, GAN의 효율성에 비해 sample 합성 품질은 AR 모델이나 Flow-based 모델에 비해 낮음
- AR 모델은 high temporal resolution의 오디오를 합성하는데 시간이 오래 걸림
-> 그래서 AR 모델이나 Flow-based 모델보다 더 계산 효율적이고 높은 sample 품질을 달성할 수 있는 모델인 HiFi-GAN을 제안
- HiFi-GAN
- 다양한 period를 가지는 sinusoidal 신호로 구성된 음성 오디오의 periodic pattern을 모델링
- 더 사실적인 음성 오디오를 생성 가능 - 오디오의 서로 다른 part를 추출하여 discriminator에 반영
- 다양한 length의 pattern을 병렬적으로 observe하는 multiple residual block을 generator에 적용
- 다양한 period를 가지는 sinusoidal 신호로 구성된 음성 오디오의 periodic pattern을 모델링
< Overall of HiFi-GAN >
- Raw waveform의 specific periodic part를 추출하는 sub-discriminator들로 구성된 discriminator 구조
- Unseen speaker와 end-to-end 방식에 대한 일반화 가능성 제시
- 기존 모델들보다 더 빠른 sampling과 높은 합성 품질을 지원
2. HiFi-GAN
- Overview
- 1개의 generator와 2개의 discriminator (multi-scale, multi-period)로 구성
- Generator와 discriminator는 학습 안정성을 위해 2개의 additional loss을 기반으로 적대적으로 학습됨
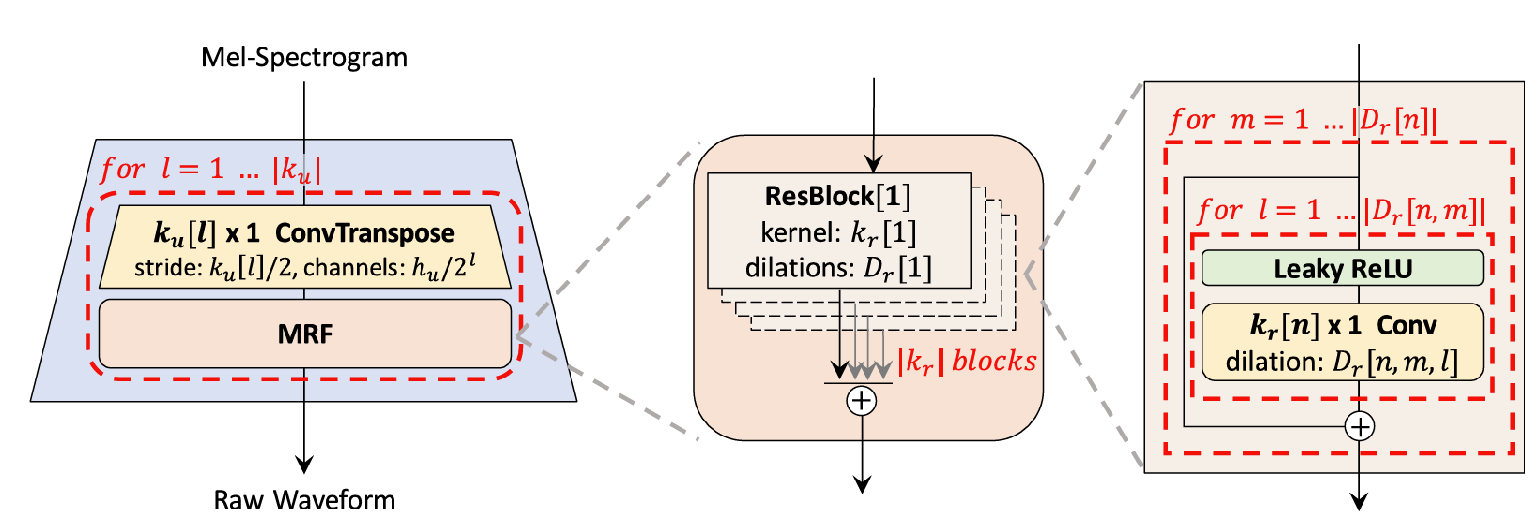
- Generator
- Generator는 fully convolutional neural network로 구성
- Mel-spectrogram을 입력으로 output sequence의 length가 raw waveform의 temporal resolution과 일치할 때까지 transposed convolution을 통해 upsampling
- 각 transposed convolution 다음에는 multi-receptive field fusion (MRF) 모듈이 적용됨
- Multi-Receptive Field Fusion
- 다양한 length의 pattern을 병렬적으로 observe하는 generator용 모듈
- MRF 모듈은 multiple residual block의 output 합을 반환 - 다양한 receptive field pattern을 얻기 위해 각 residual block에 대해 서로 다른 kernel size, dilation rate를 적용
- Hidden dimension $h_{u}$, transposed convolution의 kernel size $k_{u}$, kernel size $k_{r}$, dilation rate $D_{r}$을 조절 가능
- 다양한 length의 pattern을 병렬적으로 observe하는 generator용 모듈
- Discriminator
- 사실적인 음성 오디오 합성을 위해서는 long-term dependency를 캡처하는 것이 중요
- Adjacent sample들 간의 높은 상관 관계
- Generator와 discriminator의 receptive field를 증가시키면 해결 가능 - 음성 오디오는 다양한 period를 가지는 sinusoidal 신호로 구성되므로 모델은 여러 period pattern을 인식해야 함
- 입력 오디오의 periodic 신호를 처리하는 여러 개의 sub-discriminator들로 구성된 Multi-Period Discriminator (MPD)를 활용
- Consecutive pattern과 long-term dependency를 캡처하기 위해 MelGAN의 Multi-Scale Discriminator (MSD)를 추가적으로 도입
- Adjacent sample들 간의 높은 상관 관계
- Multi-Period Discriminator
- MPD는 여러 sub-discriminator들로 구성되고, 각 discriminator는 동일한 간격의 입력 오디오 sample만을 허용
- 이때 오디오 간격은 period $p$로 주어짐
- Sub-discriminator는 입력 오디오에서 서로 다른 implicit structure를 캡처하도록 설계됨 - MPD의 구조
1. 길이 $T$의 1D raw audio를 height $T_{p}$, width $p$로 reshape 한 다음, 2D convolution을 적용
- 이때 각 convolution layer에서 periodic sample을 독립적으로 처리하기 위해, width axis의 kernel size를 1로 설정
2. Sub-discriminator는 ReLU activation을 활용하는 stride convolution layer의 stack
- Weight normalization 적용 - 오디오의 periodic 신호를 sampling 하는 대신 입력 오디오를 2D data로 reshape 함으로써, MPD의 gradient는 입력 오디오의 모든 time step에 전달 가능
- MPD는 여러 sub-discriminator들로 구성되고, 각 discriminator는 동일한 간격의 입력 오디오 sample만을 허용
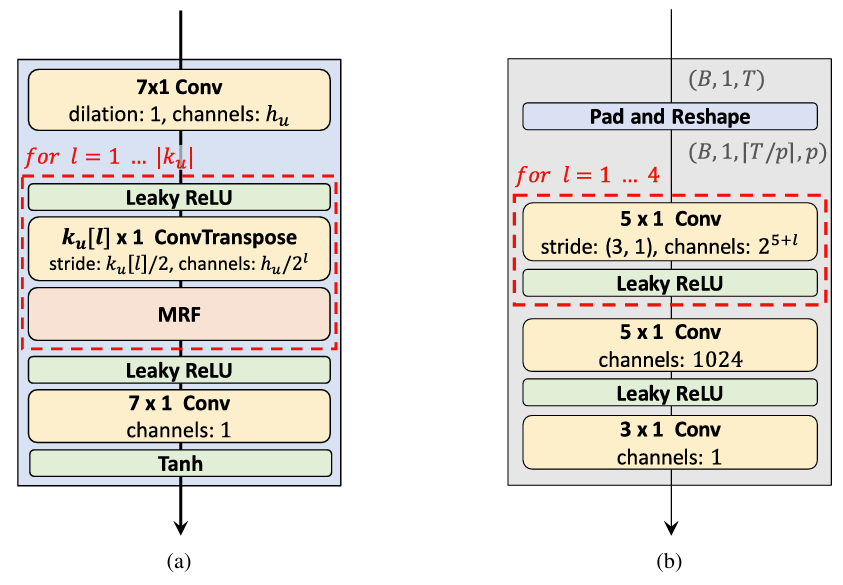
- Multi-Scale Discriminator
- MPD의 각 sub-discriminator은 disjoint sample만을 허용하므로 MSD를 통해 오디오의 연속성을 반영
- MSD는 smoothed waveform에서 동작 - MSD의 구조
- Raw audio, 2개의 average-pooled audio, 4개의 average-pooled audio의 서로 다른 입력 scale에서 작동하는 3개의 sub-discriminator로 구성
- MSD의 각 sub-discriminator는 LeakyReLU activation과 stride, grouped convolution으로 구성
- Stride를 줄이고 layer를 늘리면 discriminator의 size가 증가
- Raw audio에 동작하는 첫 번째 sub-discriminator에는 spectral normalization을 적용해 학습을 안정화
- 나머지 sub-discriminator들에 대해서는 weight normalization을 적용
- HiFi-GAN에서 사용되는 MPD와 MSD를 혼합한 discriminator 구조는 Markovian window 기반의 fully unconditional discriminator임
- MPD의 각 sub-discriminator은 disjoint sample만을 허용하므로 MSD를 통해 오디오의 연속성을 반영

- Training Loss Terms
- GAN Loss
- MPD와 MSD을 하나의 discriminator로 두면, 기존 GAN의 objective에서 binary cross-entropy를 non-vanishing gradient flow에 대한 least squares loss로 대체한 LSGAN의 objective를 따름
- Discriminator는 ground-truth sample을 1로, generator에서 합성된 sample을 0으로 분류하도록 학습
- Generator는 분류할 sample을 1과 비슷하게 생성하여 discriminator를 속이도록 학습 - Generator $G$와 Discriminator $D$의 GAN loss는,
: $L_{Adv}(D;G) = E_{(x,s)}[(D(x)-1)^{2}+(D(G(s)))^{2}]$
: $L_{Adv}(G;D) = E_{s}[(D(G(s))-1)^{2}]$
- $x$ : ground-truth audio, $s$ : input condition (ground-truth audio의 mel-spectrogram)
- MPD와 MSD을 하나의 discriminator로 두면, 기존 GAN의 objective에서 binary cross-entropy를 non-vanishing gradient flow에 대한 least squares loss로 대체한 LSGAN의 objective를 따름
- Mel-Spectorgram Loss
- GAN loss 외에 추가적으로 mel-spectrogram loss를 도입
- GAN 모델에 reconstruction loss를 사용하면 더 현실적인 결과를 생성 가능
- 특히 mel-spectrogram loss는 human auditory system과 연관되어 perceptual quality를 향상 가능 - Mel-spectrogram loss는 generator에 의해 생성된 waveform의 mel-spectrogram과 ground-truth mel-spectrogram 사이의 L1 distance
: $L_{Mel}(G) = E_{(x,s)}[ ||\Phi(x) - \Phi(G(s))||_{1}]$
- $\Phi$ : waveform을 mel-spectrogram으로 변환하는 함수 - Mel-spectrogram loss는 generator가 input condition에 해당하는 waveform을 합성하는 것을 돕고, 초기 단계의 적대적 학습 과정을 안정화
- GAN loss 외에 추가적으로 mel-spectrogram loss를 도입
- Feature Matching Loss
- Feature Matching Loss는 ground-truth sample과 생성된 sample 간의 discriminator feature 차이로 계산됨
- Discriminator의 intermediate feature를 추출하고, 각 feature space에서 ground-truth sample과 생성된 sample 사이의 L1 distance를 계산 - Feature Match Loss 식은,
: $L_{FM}(G;D) = E_{(x,s)}[ \sum^{T}_{i=1} \frac{1}{N_{i}} || D^{i}(x) - D^{i}(G(s)) ||_{1}]$
- $T$ : discriminator의 layer 개수
- $D^{i}$, $N_{i}$ : 각각 $i$-th layer의 feature와 feature 개수
- Feature Matching Loss는 ground-truth sample과 생성된 sample 간의 discriminator feature 차이로 계산됨
- Final Loss
- HiFi-GAN의 generator와 discriminator를 학습시키기 위한 최종 Loss 식은,
: $L_{G} = L_{Adv}(G;D) + \lambda_{fm}L_{FM}(G;D) + \lambda_{mel}L_{Mel}(G)$
: $L_{D} = L_{Adv}(D;G)$
- $\lambda_{fm}$은 2, $\lambda_{mel}$은 45로 설정 - 이때 discriminator는 MPD와 MSD의 sub-discriminator 집합이므로, 위 loss는 sub-discriminator에 대해 다음과 같이 나타낼 수 있음
: $L_{G} = \sum^{K}_{k=1} [ L_{Adv}(G;D_{k}) + \lambda_{fm}L_{FM}(G;D_{k})] + \lambda_{mel}L_{Mel}(G)$
: $L_{D} = \sum^{K}_{k=1} L_{Adv}(D_{k};G)$
- $D_{k}$ : MPD와 MSD의 $k$-th sub-discriminator
- HiFi-GAN의 generator와 discriminator를 학습시키기 위한 최종 Loss 식은,
3. Experiments
- Settings
- Dataset : LJSpeech, VCTK (for unseen speaker test)
- Comparisons : WaveNet, WaveGlow, MelGAN
- HiFi-GAN V1, V2, V3는 parameter 구성 차이
- Results
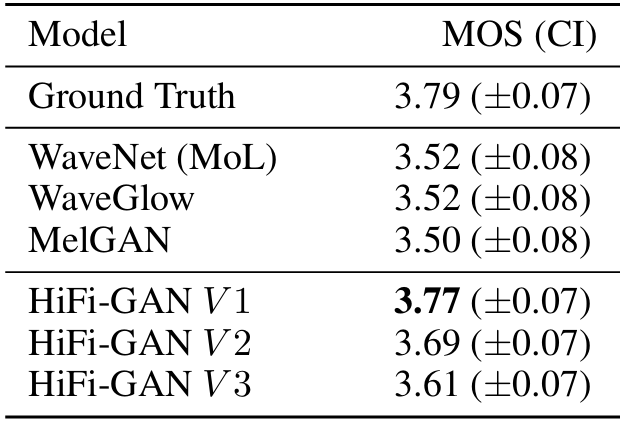
- Audio Quality and Synthesis Speed
- HiFi-GAN이 다른 비교 모델들보다 좋은 MOS 점수를 받음
- 합성 속도 측면에서도, HiFi-GAN이 빠른 합성이 가능함
- 특히 HiFi-GAN V2의 경우, 4.23의 높은 합성 품질을 보이면서 0.92M의 parameter만 사용함
- HiFi-GAN V3의 경우, CPU에서 13.44배, GPU에 1186배의 합성 속도 향상이 이루어짐

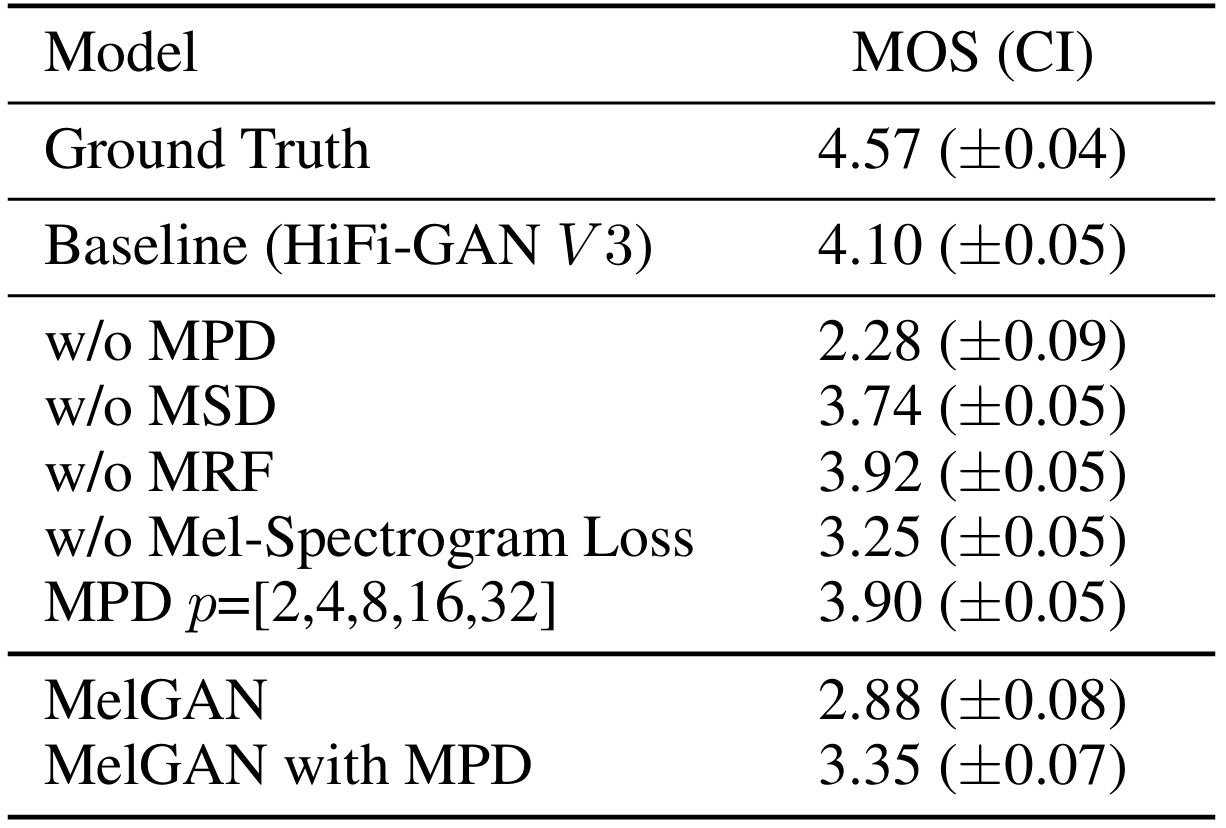
- Ablation Study
- MPD를 제거한 경우, perceptual quality에 대한 품질이 상당히 저하됨
- MSD를 제거했을 때 MPD의 경우에 비해서는 비교적 적지만, 마찬가지로 합성 품질 저하가 발생함
- MRF 모듈을 제거하거나 Mel-spectrogram loss를 사용하지 않았을 때도, 품질 저하가 발생
- Periodic Signal Discrimination Experiments
- Periodic 신호를 캡처하는 MPD의 효과를 확인하기 위한 실험을 수행하기 위해, MPD와 MSD에 projection layer를 추가하고 sinusoidal data에 대한 분류 결과를 비교
- MPD가 MSD보다 periodic 신호를 식별하는데 더 뛰어난 성능을 보임

- Frequency Response Analysis of Input Signals of Discriminators
- Discriminator를 통한 periodic pattern 모델링의 중요성을 확인하기 위한 실험을 수행
- MPD와 MSD가 Sinc 함수를 모델링하도록 generator를 학습시킴 - MPD의 경우 aliasing을 제외하고는 입력된 신호의 frequency response가 왜곡되지 않음
- MSD의 경우 downsampling 될 때마다 smoothing이 발생함
- Average pooling의 low-pass filtering으로 인해 고주파 영역에서 amplitude가 감소하기 때문 - 학습된 generator의 출력을 비교했을 때, MPD는 ground-truth와 유사한 sample을 만들지만 MSD는 합성된 신호에 noise를 포함하고 있음
- MSD가 sub-optimal 한 이유는, downsampling 과정의 average pooling 때문
- 결과적으로 MPD가 MSD보다 입력 신호의 periodic pattern을 더 잘 캡처할 수 있음
- Discriminator를 통한 periodic pattern 모델링의 중요성을 확인하기 위한 실험을 수행

- Generaliztion to Unseen Speakers
- VCTK dataset을 통해 실험했을 때, HiFi-GAN이 AR이나 flow-based 모델보다 좋은 성능을 보임
- End-to-End Speech Synthesis
- Two-stage 방식이 아닌 End-to-End 모델들과도 비교 실험을 수행
- Fine-tuning 되지 않은 경우, HiFi-GAN이 WaveGlow보다 좋은 성능을 보이긴 하지만, 3점대의 MOS로 합성 품질이 뛰어나지는 않음
- 생성된 waveform과 Tacotron2의 mel-spectrogram을 비교해 본 결과, pixel별 차이는 미미한 것으로 나타남
- Fine-tuning 미적용으로 인해 Tacotron2에서 예측된 mel-spectrogram이 이미 noisy하기 때문에 전체 품질이 낮게 측정된 것으로 볼 수 있음 - Fine-tuning을 적용한 경우, HiFi-GAN의 합성 품질은 크게 향상됨
- End-to-End 모델에 대해서도 잘 동작함


반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글