

티스토리 뷰
Paper/TTS
[Paper 리뷰] NaturalSpeech3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
feVeRin 2025. 5. 4. 09:33반응형
NaturalSpeech3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
- Large-scale text-to-speech system은 여전히 prosody, similarity 측면에서 한계가 있음
- NaturalSpeech3
- Speech waveform을 content, prosody, timbre, acoustic detail의 subspace로 disentangle 하는 Factorized Vector Quantization에 기반한 neural codec을 활용
- Prompt에 따라 각 subspace에서 attribute를 생성하는 factorized diffusion model을 도입
- 논문 (ICML 2024) : Paper Link
1. Introduction
- FastSpeech2, NaturalSpeech와 같은 기존 Text-to-Speech (TTS) model은 studio-recorded dataset에 의존하므로 zero-shot synthesis 측면에서 한계가 있음
- 한편으로 NaturalSpeech2, VALL-E 등은 large-scale TTS system을 통해 zero-shot TTS 수행하지만, 여전히 speech quality, similarity, prosody 측면에서 한계가 있음
- Mel-spectrogram과 같은 기존 data representation은 content, prosody, timbre 등의 intricated information을 효과적으로 represent 하지 못하기 때문 - 이를 위해서는 speech를 서로 다른 attribute를 represent 하는 disentangled subspace로 factorize 해야 함
- 대표적으로 AudioLM은 Residual Vector Quantization (RVQ)에 기반한 SoundStream, EnCodec 등의 neural audio codec을 활용하여 speech를 multi-level discrete token으로 encoding 함
- BUT, 해당 방식은 서로 다른 RVQ level에서 speech attribute information을 효과적으로 disentangle 하지 못하므로 complex coupled information을 modeling 하는데 한계가 있음
- 한편으로 NaturalSpeech2, VALL-E 등은 large-scale TTS system을 통해 zero-shot TTS 수행하지만, 여전히 speech quality, similarity, prosody 측면에서 한계가 있음
-> 그래서 더 나은 quality, prosody를 위한 zero-shot TTS model인 NaturalSpeech3을 제안
- NaturalSpeech3
- Factorized Vector Quantization (FVQ)에 기반한 neural codec인 FACodec을 활용하여 speech waveform을 content, prosody, timbre, acoustic detail의 distinct subspace로 decompose
- 해당 prompt를 기반으로 factorized speech representation을 생성하는 Factorized Diffusion Model을 도입
< Overall of NaturalSpeech3 >
- FACodec과 Factorized Diffusion Model을 활용한 zero-shot TTS model
- 결과적으로 기존보다 뛰어난 합성 성능을 달성
2. Method
- Overall Architecture
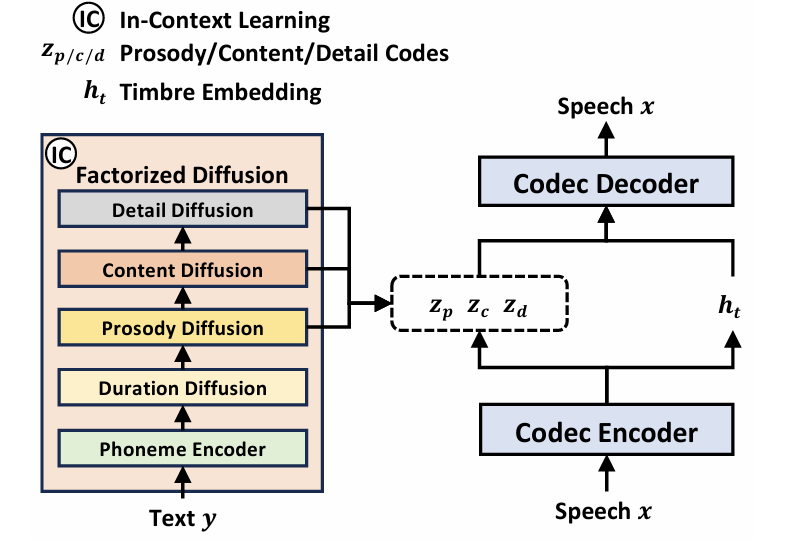
- NaturalSpeech3는 zero-shot TTS에서 high speech quality, similarity, controllability를 달성하는 것을 목표로 함
- 구조적으로는 attribute disentanglement를 위한 neural speech codec인 FACodec, factorized speech attribute를 생성하는 Factorized Diffusion Model로 구성됨
- 특히 논문은 speech waveform을 duration, prosody, content, timbre, acoustic detail의 5가지 attribute로 factorize 함
- Duration의 경우 non-autoregressive speech generation에서 explicit modeling을 지원하기 위해 사용함
- Content, prosody, timbre, acoustic detail은 FACodec을 활용하여 disentangled speech attribute subspace로써 학습됨
- 이후 Factorized Diffusion Model을 사용하여 각 speech attribute representation을 생성하고, Codec Decoder를 사용하여 waveform을 reconstruct 함
- FACodec for Attribute Factorization
- Model Overview
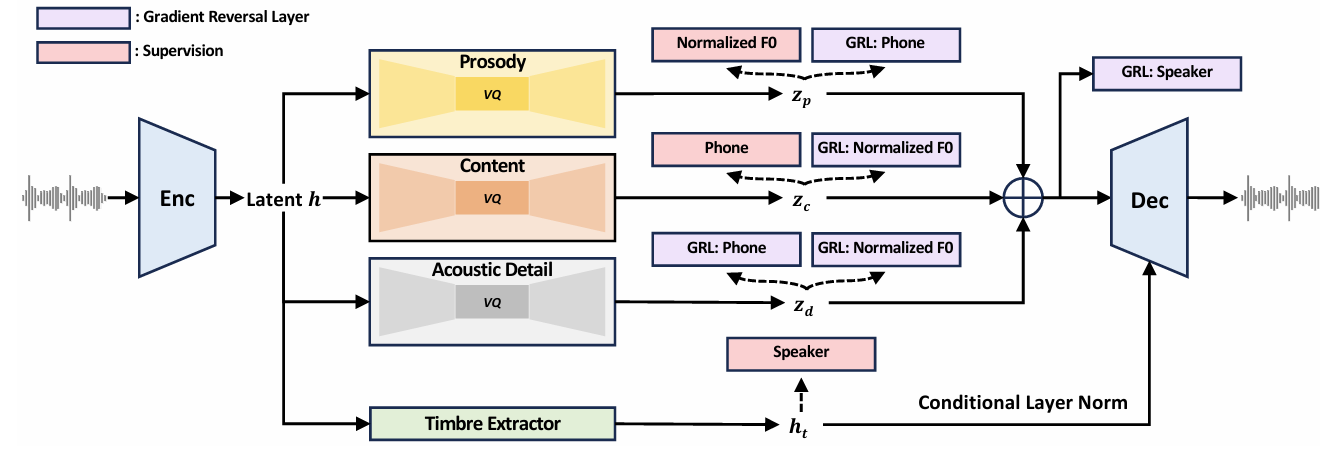
- 논문은 complex waveform을 content, prosody, timbre, acoustic detail의 disentangled subspace로 변환하고, 해당 attribute에서 reconstruction을 수행하기 위해 factorized neural speech codec인 FACodec을 도입함
- FACodec은 speech encoder, timbre extractor, factorized vector quantizer (FVQ)로 구성됨
- 먼저 speech $x$가 주어지면 SoundStream을 따라 16kHz speech data에 대해 200 downsampling rate를 가지는 speech encoder를 사용하여 pre-quantization latent $h$를 얻음
- Timbre extractor는 Transformer encoder로써 speech encoder output $h$를 timbre attribute를 represent 하는 global vector $h_{t}$로 변환함
- Prosody $p$, content $c$, acoustic detail $d$ 각각에 대한 attribute $i$는, $\text{FVQ}_{i}$를 사용하여 fine-grained speech attribute representation을 caputre 하고 discrete token $z_{i}$를 얻음
- Speech decoder는 speech encoder를 mirror 하지만 high-quality reconstruction을 위해 large parameter를 가짐
- 이때 prosody, content, acoustic detail representation을 모두 add 한 다음, conditional layer normalization을 통해 timbre information을 fuse 하여 speech decoder input $z$를 얻음
- Attribute Disentanglement
- Speech를 서로 다른 subspace로 directly factorizing 하는 것은 speech disentanglement를 보장하지 않으므로, 논문은 information bottleneck, supervision, gradient reverse, detail dropout을 고려함
- Information Bottleneck
- 먼저 model이 unnecessary information을 remove 하도록 force 하고 encoder output $h$를 low-dimensional space (8-dimensional)에 project 함
- 이후 해당 low-dimensional space에서 quantization을 수행하여 prosody, content, acoustic detail FVQ에 대한 information bottleneck을 적용함 - Quantization 이후에는 quantized vector를 latent $h$의 dimension (256-dimension)으로 다시 project 함
- 먼저 model이 unnecessary information을 remove 하도록 force 하고 encoder output $h$를 low-dimensional space (8-dimensional)에 project 함
- Supervision
- 논문은 high-quality speech disentanglement를 위해 각 attribute에 대한 auxiliary task로써 supervision을 도입함
- 먼저 prosody의 경우 pitch information을 predict 하기 위해 post-quantization latent $z_{p}$를 사용함
- 이때 각 frame에 대해 $F0$를 추출하고 normalized $F0$를 target으로 사용함 - Content의 경우 phoneme label을 target으로 사용함
- 이때 internal alignment tool을 사용하여 frame-level phoneme label을 얻음 - Timbre의 경우 spekaer ID를 predict 하여 $h_{t}$에 대해 speaker classification을 수행함
- Gradient Reversal
- Information leak를 방지하면 disentanglement를 더욱 향상할 수 있음
- 따라서 논문은 Gradient Reversal Layer (GRL)을 포함한 adversarial classifier를 채택하여 latent space에서 undesired information을 reduce 함 - Prosody의 경우 phoneme label을 predict 하는 phoneme-GRL을 적용하여 content information을 reduce 함
- Content의 경우 prosody information을 reduce 하는 $F0$-GRL을 적용함
- Acoustic detail은 phoneme-GRL, $F0$-GRL을 모두 사용하여 content, prosody information을 reduce 함
- 추가적으로 $z_{p},z_{c},z_{d}$의 summation에 speaker-GRL을 적용하여 timbre를 reduce 함
- Information leak를 방지하면 disentanglement를 더욱 향상할 수 있음
- Detail Dropout
- NaturalSpeech3에서 codec은 supervision이 없으므로 acoustic details subspace에 undesired information (content, prosody)을 preserve 하는 경향이 있음
- 이때 acoustic detail이 없다면 decoder는 prosody, content, timbre로만 reconstruction을 수행함 - 따라서 논문은 training 시 probability $p$로 $z_{d}$를 randomly masking 하는 Detail Dropout을 적용함
- 해당 detail dropout을 통해 codec의 decouple ability를 보장하고, acoustic detail이 제공되는 경우 high-quality speech를 얻을 수 있음
- NaturalSpeech3에서 codec은 supervision이 없으므로 acoustic details subspace에 undesired information (content, prosody)을 preserve 하는 경향이 있음
- Factorized Diffusion Model
- Model Overview
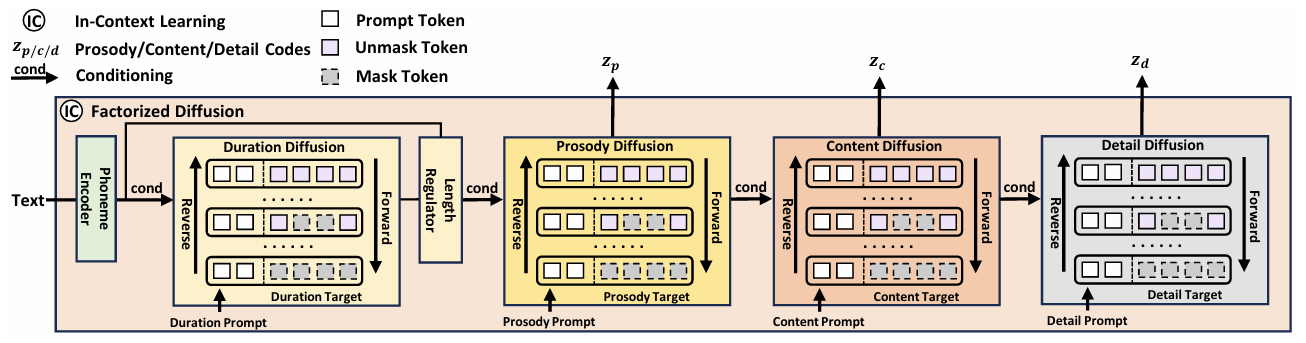
- NaturalSpeech3는 discrete diffusion을 활용함
- 이때 speech를 duration, prosody, content, acoustic detail로 factorize 하고 specific condition에 따라 sequentially generate 함
- Speech factorization design을 따라 generative model에는 attribute prompt만 제공하고 해당 subspace에 diffusion model을 적용함
- Diffusion model에서 in-context learning을 지원하기 위해 codec을 사용하여 speech prompt를 attribute prompt로 factorize하고 SoundStorm을 따라 partial noising mechanism으로 target speech attribute를 생성함
- 위를 기반으로 논문은 phoneme encoder와 동일한 discrete diffusion formulation을 가진 speech attribute (duration, prosody, content, acoustic detail) diffusion model로 구성된 Factorized Diffusion Model을 구성함
- 먼저 duration prompt를 기반으로 duration diffusion을 적용하고 phoneme encoder에 의해 encoding된 phoneme-level textual condition을 사용하여 speech duration을 생성함
- 이후 length regulator를 사용하여 frame-level phoneme condition $c_{ph}$를 얻음 - 다음으로 prosody prompt, phoneme condition $c_{ph}$를 기반으로 prosody $z_{p}$를 생성함
- 이후 생성된 prosody $z_{p}$와 phoneme $c_{ph}$를 condition으로 content prompt를 통해 content prosody $z_{c}$를 생성함
- 최종적으로는 생성된 prosody, content, phoneme $z_{p},z_{c},c_{ph}$를 condition으로 acoustic detail $z_{d}$를 생성함
- 먼저 duration prompt를 기반으로 duration diffusion을 적용하고 phoneme encoder에 의해 encoding된 phoneme-level textual condition을 사용하여 speech duration을 생성함
- 구조적으로는 condition과 함께 target sequence를 summation하고, timbre attribute를 explicitly generate 하지 않음
- FACodec의 factorization을 통해 prompt로부터 timbre를 얻을 수 있기 때문 - 추가적으로 accurate duration prediction을 위해 auxiliary phoneme-level prosody diffusion model을 활용하여 phoneme-level prosody condition을 생성함
- 결과적으로 $z_{p},z_{c},z_{d},h_{t}$를 combine 하고 Codec Decoder로 decoding 하여 target speech를 합성함
- NaturalSpeech3는 discrete diffusion을 활용함
- Diffusion Formulation
- Forward Process
- $N$이 sequence length일 때, $\mathbf{X}=[x_{i}]_{i=1}^{N}$을 target discrete token sequence, $\mathbf{X}^{p}$를 prompt discrete token sequence, $\mathbf{C}$를 condition이라고 하자
- Time $t$에서의 forward process는 $\mathbf{X}$의 token subset을 해당 binary mask $\mathbf{M}_{t}=[m_{t,i}]_{i=1}^{N}$로 masking 하는 것으로써, $\mathbf{X}_{t}=\mathbf{X}\odot \mathbf{M}_{t}$와 같음
- 이때 $m_{t,i}=1$이면 $x_{i}$를 $\text{[MASK]}$ token으로 replace 하고, $m_{t,i}=0$이면 $x_{i}$를 unmasked로 유지함
- $m_{t,i}\overset{iid}{\sim}\text{Bernoulli}(\sigma(t));\, \sigma(t)\in(0,1]$ : monotonically increasing function, $\sigma(t)=\sin\left(\frac{\pi t}{2T}\right);\, t\in(0,T]$ - 여기서 origianl token sequence는 $\mathbf{X}_{0}=\mathbf{X}$, fully masked sequence는 $\mathbf{X}_{T}$로 denote 됨
- $N$이 sequence length일 때, $\mathbf{X}=[x_{i}]_{i=1}^{N}$을 target discrete token sequence, $\mathbf{X}^{p}$를 prompt discrete token sequence, $\mathbf{C}$를 condition이라고 하자
- Reverse Process
- Reverse process는 full masked sequence $\mathbf{X}_{T}$에서 start 하여 reverse distribution $q(\mathbf{X}_{t-\Delta t}|\mathbf{X}_{0},\mathbf{X}_{t})$을 sampling 하여 $\mathbf{X}_{0}$를 gradually restore 함
- 이때 $\mathbf{X}_{0}$는 추론 시 unavailable 하므로 $\theta$로 parameterize 된 diffusion model $p_{\theta}$를 사용하여 $\mathbf{X}^{p}, \mathbf{C}$에 condition 된 masked token을 predict 함
- 즉, $p_{\theta}(\mathbf{X}_{0}|\mathbf{X}_{t},\mathbf{X}^{p},\mathbf{C})$ - Parameter $\theta$는 masked token의 negative log-likelihood를 minimize 하도록 optimize 됨:
(Eq. 1) $\mathcal{L}_{mask}=\mathbb{E}_{\mathbf{X}\in\mathcal{D},t\in[0,T]}-\sum_{i=1}^{N}m_{t,i}\cdot \log \left(p_{\theta}(x_{i}|\mathbf{X}_{t},\mathbf{X}^{p},\mathbf{C})\right)$ - 그러면 reverse transition distribution은:
(Eq. 2) $p(\mathbf{X}_{t-\Delta t}|\mathbf{X}_{t},\mathbf{X}^{p},\mathbf{C})=\mathbb{E}_{\hat{\mathbf{x}}_{0}\sim p_{\theta}(\mathbf{X}_{0}|\mathbf{X}_{t},\mathbf{X}^{p},\mathbf{C})}q(\mathbf{X}_{t-\Delta t}|\hat{\mathbf{X}}_{0},\mathbf{X}_{t})$
- Inference
- Inference 시에는 fully masked squence $\mathbf{X}_{T}$에서 starting 하여 $p(\mathbf{X}_{t-\Delta t}|\mathbf{X}_{t},\mathbf{X}^{p},\mathbf{C})$를 iteratively sampling 해 masked token을 progressively replace 함
- 즉, $p_{\theta}(\mathbf{X}_{0}|\mathbf{X}_{t},\mathbf{X}^{p},\mathbf{C})$에서 $\hat{\mathbf{X}}_{0}$을 sampling 한 다음, $q(\mathbf{X}_{t-\Delta t}|\hat{\mathbf{X}}_{0},\mathbf{X}_{t})$에서 $\mathbf{X}_{t-\Delta t}$를 sampling 함
- 이때 lowest confidence score의 $\hat{\mathbf{X}}_{0}$에서 $\left\lfloor N\cdot \sigma (t-\Delta t)\right\rfloor$ token을 remasking 함
- $m_{t,i}=1$이면 $\hat{\mathbf{X}}_{0}$에서 $\hat{x}_{i}$의 confidence score를 $p_{\theta}(\hat{x}_{i}|\mathbf{X}_{t},\mathbf{X}^{p},\mathbf{C})$로 정의하고, 그렇지 않은 경우 $x_{i}$의 confidence score를 $0$으로 설정함
- 결과적으로 $\mathcal{X}_{t}$에서 unmask 된 token은 remask 하지 않음
- Classifier-Free Guidance (CFG)
- 추가적으로 논문은 classifier-free guidance를 도입하여 training 시에는 $p_{cfg}=0.15$의 probability로 prompt를 사용하지 않음
- Inference 시에는 prompt $g_{cond}=g(\mathbf{X}|\mathbf{X}^{p})$에 의해 guide 되는 conditional generation을 향하도록 model의 logit output을 extrapolate 하고, unconditional generation $g_{uncond}=g(\mathbf{X})$과는 멀어지도록 함
- 즉, $g_{cfg}=g_{cond}+\alpha\cdot (g_{cond}-g_{uncond})$ - 이후 $g_{final}=\text{std}(g_{cond})\times g_{cfg}/\text{std}(g_{cfg})$을 통해 rescale 함
- 추가적으로 논문은 classifier-free guidance를 도입하여 training 시에는 $p_{cfg}=0.15$의 probability로 prompt를 사용하지 않음
- Forward Process
3. Experiments
- Settings
- Dataset : LibriLight
- Comparisons : VALL-E, NaturalSpeech2, VoiceBox, Mega-TTS2, UniAudio, StyleTTS2, HierSpeech++
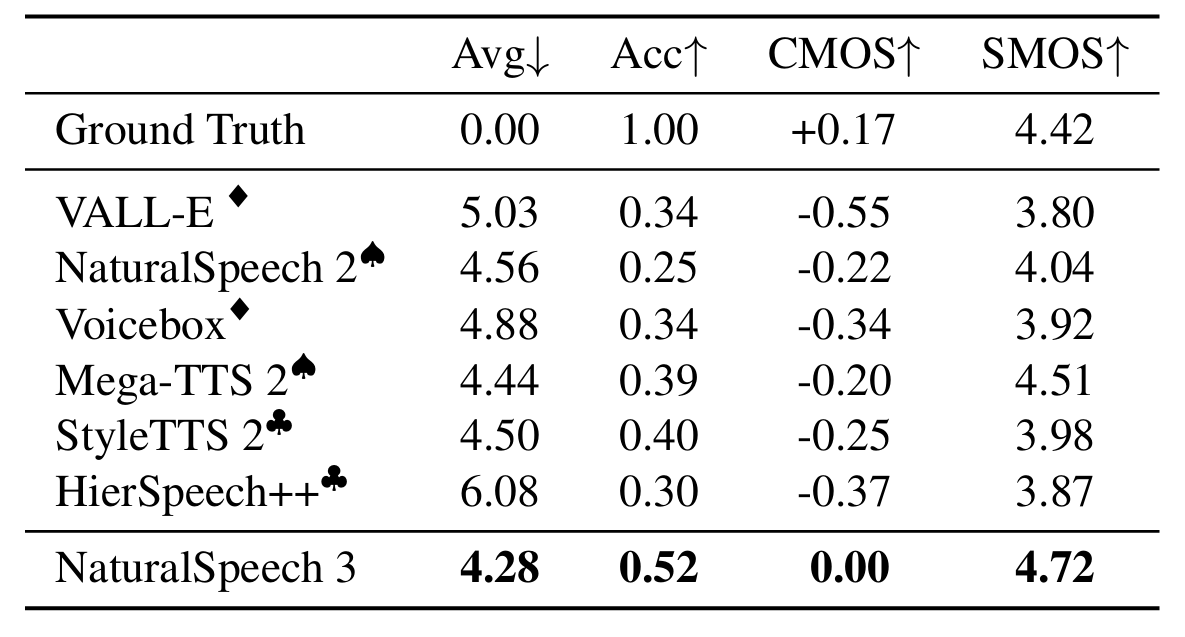
- Results
- 전체적으로 NaturalSpeech3의 성능이 가장 우수함
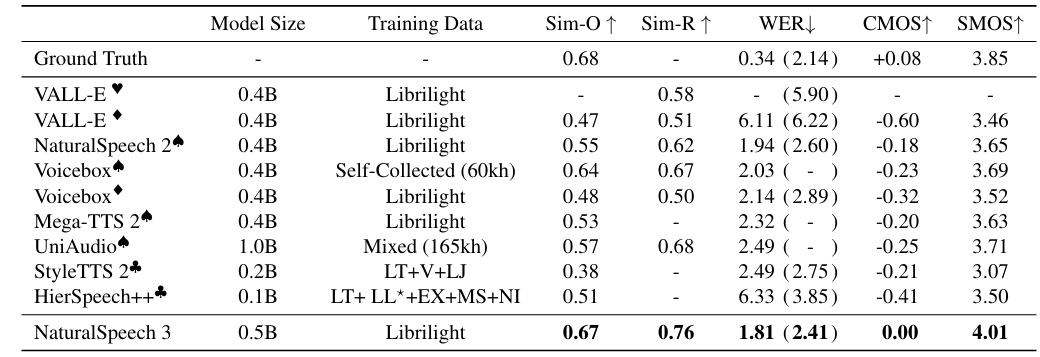
- Prosody Similarity 측면에서도 NaturalSpeech3가 우수한 성능을 보임
- Ablation Study
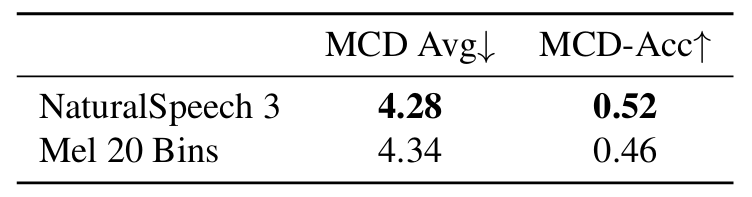
- CFG와 factorization을 제거하는 경우 성능 저하가 발생함

- Handcrafted prosody feature (20-bin mel-spectrogram)과 비교하여 NaturalSpeech3의 prosody representation은 더 나은 prosody similarity를 달성함
- Extensibility
- Factorization을 VALL-E에 적용했을 때 기존보다 더 나은 성능을 달성함

- FACodec
- FACodec을 HiFi-Codec, DAC, SoundStream, EnCodec과 비교해 보면
- FACodec은 STOI, MSTFT, MCD 측면에서 가장 뛰어난 성능을 보임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글