
티스토리 뷰
Paper/Language Model
[Paper 리뷰] UniAudio: Towards Universal Audio Generation with Large Language Models
feVeRin 2025. 3. 2. 12:54반응형
UniAudio: Towards Universal Audio Generation with Large Language Models
- 다양한 task를 unified manner로 처리할 수 있는 universal audio generation model이 필요함
- UniAudio
- Large Language Model-based audio generation model을 구성해 phoneme, text description, audio 등의 다양한 input condition을 기반으로 speech, sound, music, singing voice 등을 생성
- Model performance와 efficiency를 향상하기 위한 audio tokenization과 language model architecture를 설계
- 논문 (ICML 2024) : Paper Link
1. Introduction
- Audio generation은 task-specific 하므로 domain knowledge에 의존하고 fixed setup에 restrict 됨
- 한편 각 task를 independent하게 처리하지 않고 unified model을 통해 multiple audio generation을 수행할 수 있음
- 해당 universal audio model을 구성하면 various source, task에서 collect 된 massive data를 활용할 수 있고 task-specific model을 구축하는 것보다 human effort를 줄일 수 있음 - 특히 최근에는 VALL-E, SpearTTS, AudioLM과 같이 audio generation에서 Large Language Model (LLM)이 도입되고 있음
- BUT, 여전히 unified model로써 multiple task를 처리할 수 있는 LLM ability는 크게 활용되지 않음
- 한편 각 task를 independent하게 처리하지 않고 unified model을 통해 multiple audio generation을 수행할 수 있음
-> 그래서 LLM paradigm에 기반한 unified audio generation model인 UniAudio를 제안
- UniAudio
- Universal audio generation을 위해 LLM을 기반으로 다양한 input modality에 따라 다양한 audio를 생성
- 먼저 여러 tokenization method를 통해 다양한 modality의 audio/condition을 discrete token으로 변환하고,
- Condition sequence에 따라 LLM을 통해 audio token sequence를 생성한 다음, generated audio token sequence를 detokenizing 하여 waveform을 생성함
- Audio tokenization과 Residual Vector Quantization (RVQ)의 overly long sequence 문제를 해결할 수 있는 CodecFormer를 설계
- Universal audio generation을 위해 LLM을 기반으로 다양한 input modality에 따라 다양한 audio를 생성
< Overall of UniAudio >
- LLM과 neural audio codec을 활용한 unified audio generation model
- 결과적으로 개별 model보다 뛰어난 합성 품질을 달성

2. Method
- Tokenization
- UniAudio에서 audio와 다른 input modality는 tokenize 되어 사용됨
- 각 modality에 대한 tokenization은 independent module에 의해 수행되고 해당 module은 optimization 과정에서 fix 됨
- Audio
- 모든 audio는 LLM에서 modeling 되기 전에 DAC, HiFi-Codec, SoundStream과 같은 neural audio codec을 통해 discrete sequence로 tokenize 됨
- 여기서 codec model은 encoder-decoder 구조를 가지고 intermediate encoder output을 discrete token으로 quantize 하는 neural network에 해당함
- 해당 discrete token의 summed embedding이 주어지면 codec decoder는 audio waveform을 recover 함
- 결과적으로 codec model의 intermediate discrete token은 AudioLM, SpearTTS와 같은 LLM-based audio generation에서 predicting target으로 사용됨
- Codec model은 hidden space에서 Residual Vector Quantization (RVQ)를 주로 채택함
- Multiple quantization layer를 사용하여 quantization error를 progressively reduce 하고 더 나은 reconstruction performance를 달성할 수 있기 때문 - RVQ를 채택하면 quality, efficiency 간의 trade-off가 발생함
- Modeling quality는 RVQ layer를 늘려 quantization error를 줄이는 방식으로 향상할 수 있지만, audio sequence length는 RVQ layer 수에 비례하여 증가하므로 LLM efficiency가 저해됨 - UniAudio는 single model로 speech, sound, music 등의 mutiple type의 audio를 생성하는 것을 목표로 하므로 codec model은 다음의 조건을 만족해야 함:
- Shared latent space에서 모든 type의 audio를 represent 할 수 있어야 함
- Encode-Quantization-Decode process는 near-lossless 해야 함
- Efficient training/inference를 위해 few RVQ layer만을 사용해야 함
- 이를 위해 UniAudio는 EnCodec의 encoder-decoder framework를 기반으로 mel-based discriminator와 sub-band STFT reconstruction loss를 적용하여 codec model을 구성함
- 결과적으로 해당 codec model은 4가지 audio type에서 가장 뛰어난 성능을 달성하는 것으로 나타남
- 모든 audio는 LLM에서 modeling 되기 전에 DAC, HiFi-Codec, SoundStream과 같은 neural audio codec을 통해 discrete sequence로 tokenize 됨
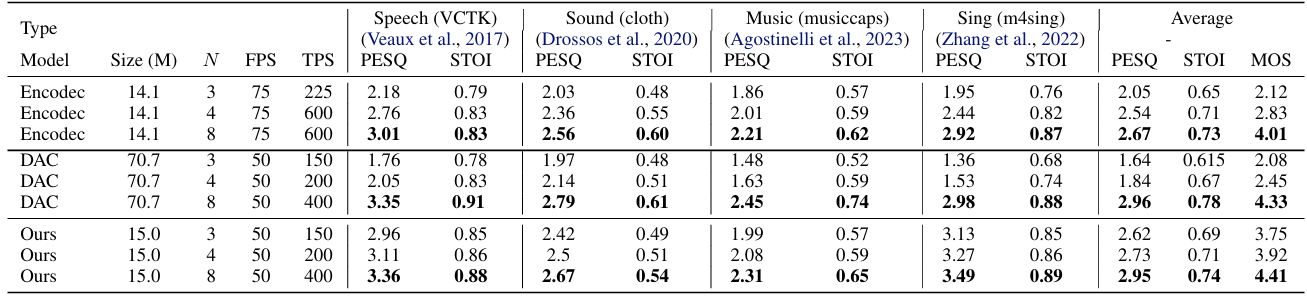
- Other Modalities
- UniAudio는 audio 외의 다른 modality도 고려함
- 마찬가지로 해당 input modality 역시 tokenization을 통해 discrete sequence로 변환됨 - Phoneme
- Phoneme은 speech pronunciation의 basic unit에 해당함
- 이때 phoneme은 다음의 multiple source를 포함함:
- Text만 사용가능한 경우, pronunciation dictionary를 통해 text-to-phoneme mapping을 수행하고 duration information이 없는 phoneme sequence를 얻을 수 있음
- Speech만 사용가능한 경우, DNN-HMM system의 beam search를 통해 duration information이 포함된 phoneme sequence를 얻음
- Text, Speech 모두 사용가능한 경우, DNN-HMM system의 forced-align operation을 통해 duration information이 포함된 phoneme sequence를 얻음
- MIDI
- MIDI는 singing voice synthesis task를 위해 사용됨
- 이때 $F0$, duration information이 MIDI에 포함됨 - 논문에서는 duration information을 사용하여 $F0$ sequence를 flatten 한 다음 frame-level $F0$ sequence를 얻음
- MIDI는 singing voice synthesis task를 위해 사용됨
- Text
- Text는 audio generation task에서 human instruction의 effective carrier로 사용됨
- 논문에서 해당 instruction은 pre-trained text T5 model에서 derive 된 continuous embedding sequence로 represent 됨
- 해당 embedding sequence는 rich textual semantic을 포함하고 있기 때문
- Semantic Token
- Semantic token은 audio Self-Supervised Learning (SSL) model이 output 한 continuous embedding으로부터 derive 됨
- 논문에서 해당 continuous representation은 $k$-means clustering을 적용하여 discretize 됨
- UniAudio는 audio 외의 다른 modality도 고려함
- Unified Task Formulation
- UniAudio는 주어진 condition과 task identifier를 기반으로 audio generation task를 수행함
- 이때 모든 task는 LLM에서 process 되는 sequential modeling task로 formulate 할 수 있음:
- Target audio와 condition을 sub-sequence로 변환한 다음, LLM 이전에 $\text{[conditions, target]}$과 같이 splice 함 - 추가적으로 ambiguity를 방지하기 위해 whole sequence의 start/end, certain modality의 각 sub-sequence start/end, task identifier를 indicate 하는 special token을 insert 함
- 각 task별 sequential format은 아래 표 참조
- 이때 모든 task는 LLM에서 process 되는 sequential modeling task로 formulate 할 수 있음:

- CodecFormer
- Audio frame 수와 RVQ layer 수를 각각 $T, N$이라고 하자
- AudioLM, SpearTTS와 같은 기존의 LLM-based audio generation model은 generation quality를 위해 flattened format으로 audio token sequence를 modeling 함
- BUT, 해당 sequence는 $T\times N$ length로 처리되므로 sequence length와 관련된 Transformer의 quadratic space complexity 문제가 존재함 - 따라서 UniAudio는 discrete audio sequence modeling을 위해 audio의 inter-/intra-correlation을 separately process 하는 CodecFormer를 도입함
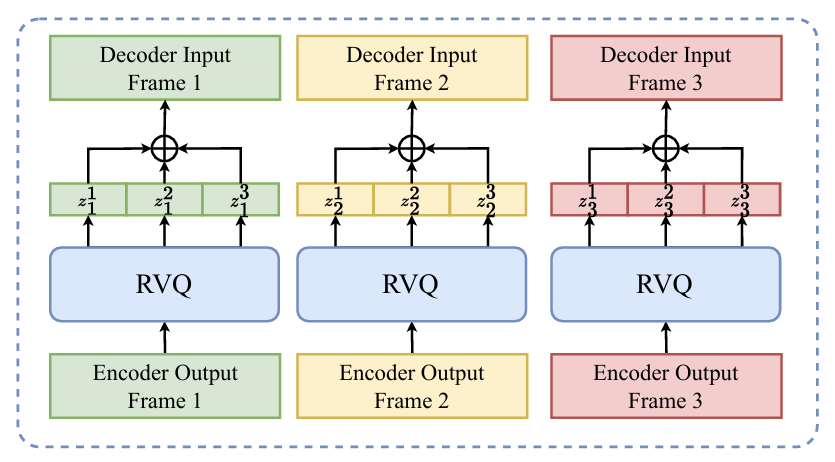
- 구조적으로 CodecFormer는 full causality를 가진 Transformer decoder-only model인 patch predictor, token predictor로 구성됨
- 여기서 $N$ consecutive token을 patch라고 하면, audio token sequence modeling에서 각 patch는 하나의 audio frame을 exactly represent 함 - 먼저 RVQ와 align 되도록 각 patch는 해당 patch 내의 all token embedding의 sum으로 represent 된 다음, patch predictor에 의해 digest 됨
- 다음으로 각 $t$-th frame $\mathbf{z}_{t}$에 대해 patch predictor는 patch $\mathbf{z}_{t}$와 all previous content를 encode 하는 continuous vector $\mathbf{h}_{t}$를 output 함
- 이후 $\mathbf{h}_{t}$를 기반으로 patch $\mathbf{z}_{t}^{1}$ 내의 token은 token predictor에 의해 auto-regressively predict 됨
- 이때 $\mathbf{h}_{t}$는 각 token의 input embedding에 simply adding 됨
- 구조적으로 CodecFormer는 full causality를 가진 Transformer decoder-only model인 patch predictor, token predictor로 구성됨
- CodecFormer architecture는 audio 외에도 discrete/continuous sequence와도 compatible 함
- Audio (phoneme, semantic, MIDI, special token)을 제외한 모든 discrete token은 각 token이 independent semantic을 가지므로 하나의 whole patch를 담당해야 함
- 따라서 해당 discrete token은 각 patch를 fill 하기 위해 $N$번 repeat 되고, continuous text embedding도 마찬가지로 $N$번 repeat 됨 - CodecFormer는 context vector $\mathbf{h}_{t}$가 patch $\mathbf{z}_{t}^{1}$ 내의 token을 predict 하기에 충분하다는 mild assumption에 기반하여 설계됨
- 여기서 해당 assumption은 codec model의 audio token에 대해 타당함
- 각 frame의 original RVQ process는 해당 frame의 encoder output에만 dependent 하기 때문 - 특히 CodecFormer는 patch predictor의 equivalent sequence length가 $T\times N$에서 $T$로 reduce 되므로 $N$에 비례하지 않음
- 결과적으로 CodecFormer는 computational complexity를 effectively reduce 할 수 있음 - Token predictor는 fixed length $N$의 short sequence에서만 동작하므로 patch predictor보다 더 적은 parameter를 가짐
- 여기서 해당 assumption은 codec model의 audio token에 대해 타당함
- AudioLM, SpearTTS와 같은 기존의 LLM-based audio generation model은 generation quality를 위해 flattened format으로 audio token sequence를 modeling 함

3. Experiments
- Settings
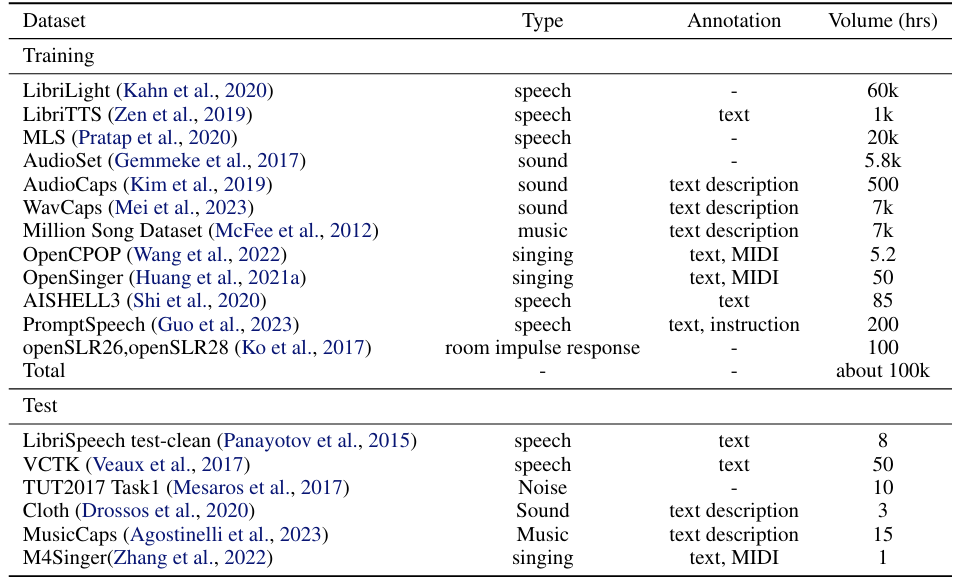
- Dataset : 아래 표 참조
- Comparisons
- Text-to-Speech : NaturalSpeech2
- Voice Conversion : LM-VC
- Speech Enhancement : Fullsubnet+
- Target Speaker Extraction : Speakerbeam
- Singing Voice Synthesis : DiffSinger
- Text-to-Sound : TANGO
- Text-to-Music : MusicGen
- Results
- 전체적으로 UniAudio의 성능이 가장 뛰어남

- Support New Tasks
- Audio edit, Speech dereverberation, prompt TTS, Speech edit task에 대해서도 fine-tuned UniAudio는 기존보다 우수한 성능을 달성함
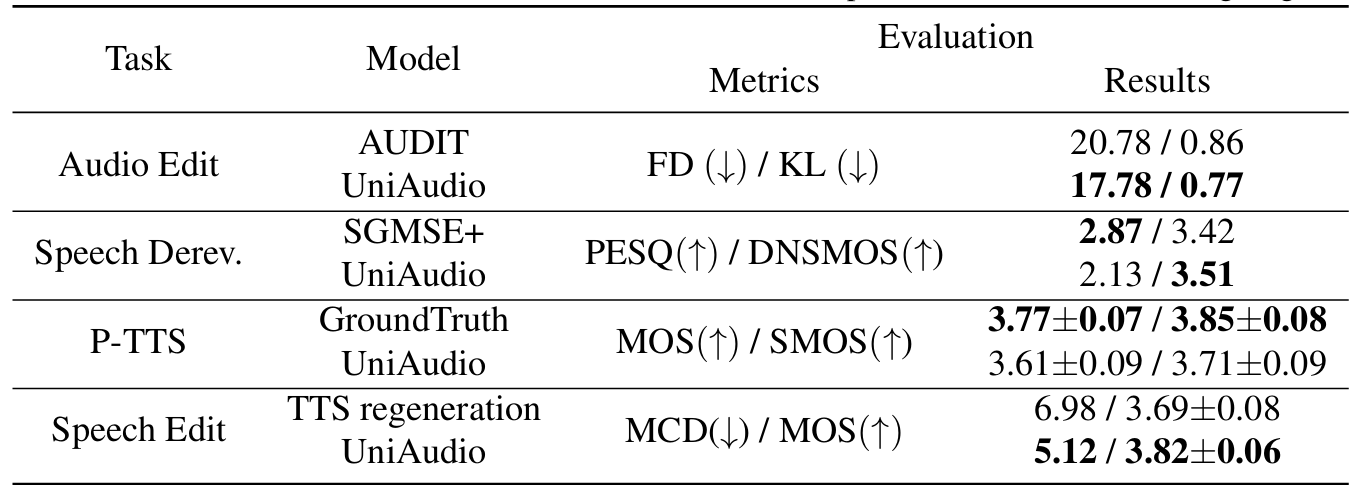
- Analysis
- Benefit of Building a Unified Model
- Single-task model보다 jointly trained model이 더 높은 성능을 보임

- Data Scale
- Training data scale이 감소할수록 UniAudio의 성능도 저하됨
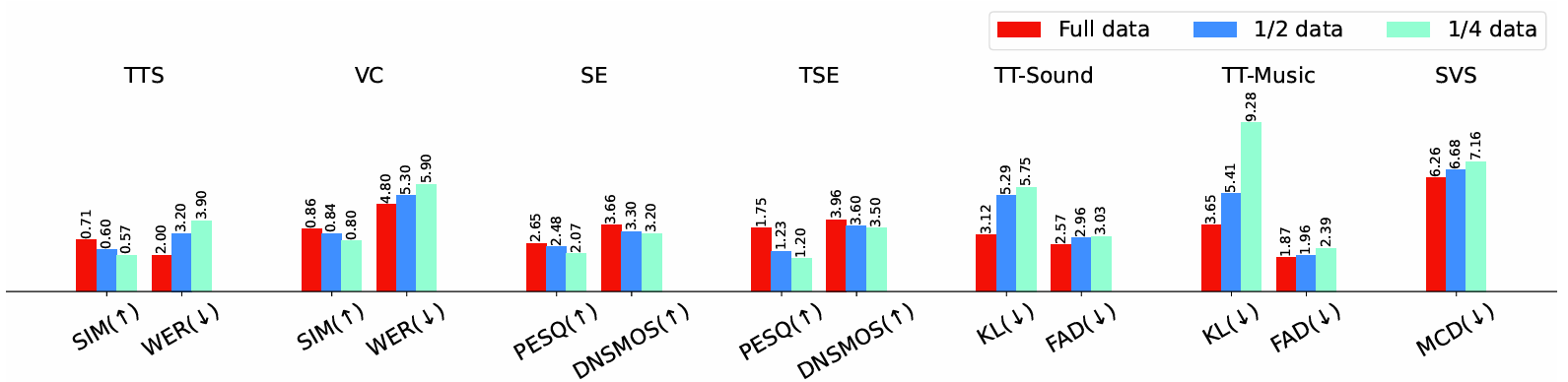
- Cross-Domain Learning
- 서로 다른 domain composition에 대해서도 UniAudio는 안정적인 성능을 달성함

- Ablation Study
- Analysis on CodecFormer

- Auto-Regression and Performance
- Flattening method의 성능은 auto-regressive property에서 기인함
- CodecFormer의 경우 auto-regressive property는 다음과 같이 reinterpret 할 수 있음:
- Current token $z_{t}^{k}$의 prediction은 prior frame의 token $\{z_{t}^{k'}|t'<t\}$와 shallower RVQ layer의 token $\{z_{t'}^{k'}|t'=t,k'<k\}$에 기반함
- Patch predictor와 token predictor에서 full causality를 채택하면 CodecFormer에서 flattening을 구현할 수 있음
- 결과적으로 해당 flattening prediction은 paralle, coarse first, delay prediction 보다 우수한 성능을 보임
- 특히 auto-regressive property를 활용한 CodecFormer는 naive flattening prediction 수준의 성능을 달성함

- Efficiency
- Naive flattening prediction은 efficiency 측면에서 sub-optimal 함:
- $T\times N$ long sequence에서 동작하는 standard Transformer decoder model을 고려했을 때 self-attention에서 $\mathcal{O}((T*N)^{2})$의 space complexity를 가짐
- 여기서 sequence length는 $N$에 비례하여 증가하므로 $N\geq 4$인 경우 naive flattening을 채택하는 것은 부적합함
- 반면 CodecFormer는 inter-/intra-frame modeling을 patch predictor와 token predictor로 distribute 하여 space complexity를 $\mathcal{O}(T^{2})$로 alleviate 함
- 즉, space complexity는 $N$과 무관하므로 CodecFormer를 사용하여 larger $N$의 sequence를 더 효율적으로 학습할 수 있음
- Naive flattening prediction은 efficiency 측면에서 sub-optimal 함:
반응형
'Paper > Language Model' 카테고리의 다른 글
댓글