

티스토리 뷰
Paper/Representation
[Paper 리뷰] Wav2Vec: Unsupervised Pre-Training for Speech Recognition
feVeRin 2025. 3. 22. 09:07반응형
Wav2Vec: Unsupervised Pre-Training for Speech Recognition
- Raw audio representation을 학습하여 speech recognition에 unsupervised pre-training을 도입할 수 있음
- Wav2Vec
- Unlabeled audio data를 기반으로 training 하고, resulting representation을 acoustic model training을 개선하는 데 사용
- Noise contrastive binary classification을 통해 simple multi-layer convolutional neural network를 optimize
- 논문 (INTERSPEECH 2019) : Paper Link
1. Introduction
- Speech recognition model은 large transcribed audio data를 요구함
- 한편으로 pre-training을 활용하면 labeled data가 scarce 한 경우 general representation을 학습해 downstream task의 성능을 개선할 수 있음
- 특히 speech processing에서 pre-training은 emotion recognition, speaker identification, phoneme discrimination 등에 사용됨
- BUT, supervised speech recognition task에 대해서는 unsupervised representation이 사용되지 않음
- 한편으로 pre-training을 활용하면 labeled data가 scarce 한 경우 general representation을 학습해 downstream task의 성능을 개선할 수 있음
-> 그래서 unsupervised pre-training을 활용해 speech recognition task를 개선한 Wav2Vec을 제안
- Wav2Vec
- Raw audio를 input으로 하여 speech recognition system에 input 되는 general representation을 compute 하는 convolutional neural network
- True future audio sample과 negatives를 distinguish 하는 contrastive loss를 활용
- Frame-wise phoneme classification을 뛰어넘는 learned representation을 적용하여 speech recognition system을 개선
- Raw audio를 input으로 하여 speech recognition system에 input 되는 general representation을 compute 하는 convolutional neural network
< Overall of Wav2Vec >
- Fully convolutional architecture와 unsupervised pre-training method에 기반하여 speech recognition을 개선
- 결과적으로 기존보다 뛰어난 recognition 성능을 달성
2. Method
- Input으로 audio signal이 주어지면 Wav2Vec은 주어진 signal context로부터 future sample을 predict 함
- 이를 위해서는 data distribution $p(\mathbf{x})$를 accurately modeling 해야 함
- 따라서 논문은 raw speech sample $\mathbf{x}$를 lower temporal frequency에서 feature representation $\mathbf{z}$로 encoding 한 다음, density ratio $p(\mathbf{z}_{i+k}|\mathbf{z}_{i}...\mathbf{z}_{i-r})/p(\mathbf{z}_{i+k})$를 implicitly modeling 함
- Model
- Wav2Vec은 raw audio signal을 input으로 사용하는 2개의 network를 활용함
- Encoder network는 audio signal을 latent space에 embed 하고 context network는 encoder의 multiple time step을 combine 하여 contextualized representation을 얻음
- 먼저 raw audio sample $\mathbf{x}_{i}\in\mathcal{X}$가 주어지면, 5-layer convolutional network로 parameterize 된 encoder network $f:\mathcal{X}\mapsto\mathcal{Z}$를 적용함
- 여기서 encoder layer는 $(10,8,4,4,4)$의 kernel size와 $(5,4,2,2,2)$의 stride를 가짐
- Encoder output은 low frequency feature representation $\mathbf{z}_{i}\in\mathcal{Z}$로써, 16kHz audio의 30ms를 encode 하고 striding result는 10ms마다 representation $\mathbf{z}_{i}$를 생성함
- 다음으로 context network $g:\mathcal{Z}\mapsto \mathcal{C}$를 encoder network output에 적용하여 multiple latent representation $\mathbf{z}_{i}...\mathbf{z}_{i-v}$를 receptive field size $v$에 대한 single contextualized tensor $\mathbf{c}_{i}=g(\mathbf{z}_{i}...\mathbf{z}_{i-v})$로 mix 함
- Context network는 kernel size 3, stride 1의 9-layer로 구성되고, total receptive field는 210ms - Encoder/Context network layer는 512 channel의 causal convolution, group normalization layer, ReLU nonlinearity로 구성됨
- 이때 각 sample에 대해 feature/temporal dimension을 모두 normalize 하고, input scaling과 offset에 invariant 한 normalization scheme을 선택해야 generalized representation을 얻을 수 있음 - 추가적으로 larger dataset training을 위해 12-layer로 구성된 larger context network를 사용하는 Wav2Vec-large model을 고려할 수 있음
- 이 경우 aggregator에 skip connection을 도입하여 사용하고, total receptive field는 810ms를 가짐
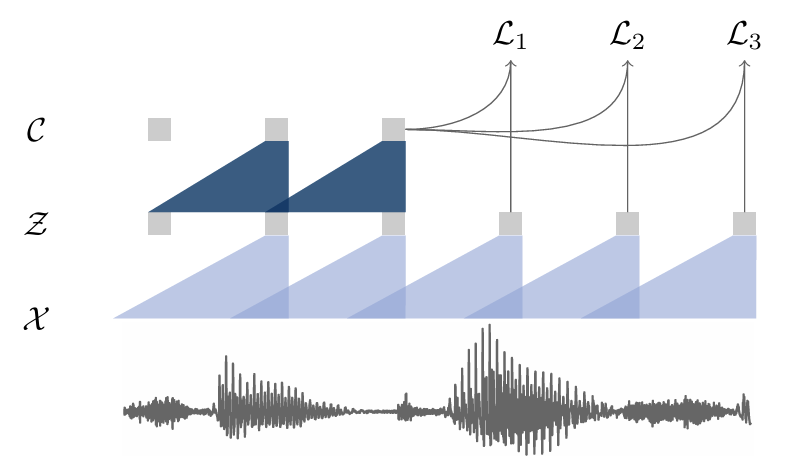
- Objective
- 논문은 propsal distribution $p_{n}$에서 추출한 distractor sample $\tilde{\mathbf{z}}$와 $k$-step future의 sample $\mathbf{z}_{i+k}$를 distinguish 하기 위해 model을 training 함
- 즉, 각 step $k=1,...,K$에 대한 contrastive loss를 minimize 함:
(Eq. 1) $\mathcal{L}_{k}=-\sum_{i=1}^{T-k}\left(\log \sigma(\mathbf{z}^{\top}_{i+k}h_{k}(\mathbf{c}_{i}))+ \lambda\mathbb{E}_{\tilde{\mathbf{z}}\sim p_{n}}[\log \sigma(-\tilde{\mathbf{z}}^{\top}h_{k}(\mathbf{c}_{i}))]\right)$
- $\sigma(x)=1/(1+\text{exp}(-x))$ : sigmoid function, $\lambda$ : negatives 수
- $\sigma(\mathbf{z}_{i+k}^{\top}h_{k}(\mathbf{c}_{i}))$ : $\mathbf{z}_{i+k}$가 true sample이 될 probability - 여기서 각 step $k$에 대해 $\mathbf{c}_{i}$에 적용되는 step-specific affine transformation $h_{k}(\mathbf{c}_{i})=W_{k}\mathbf{c}_{i}+\mathbf{b}_{k}$을 고려할 수 있음
- 결과적으로 논문은 loss $\mathcal{L}=\sum_{k=1}^{K}\mathcal{L}_{k}$를 optimize 하여 서로 다른 step size에 걸쳐 (Eq. 1)을 summation 함
- 이때 각 audio sequence에서 distractor를 uniformly choosing 하여 10-negative examples를 sampling 한 다음, expectation을 approximate 함
- 즉, $T$를 sequence length라고 할 때, $p_{n}(\mathbf{z})=\frac{1}{T}$
- Training 이후 log-mel filterbank 대신 context network에서 생성된 representation $\mathbf{c}_{i}$를 acoustic model에 input 함
- 즉, 각 step $k=1,...,K$에 대한 contrastive loss를 minimize 함:
- Decoding
- Acoustic model output을 decoding 하기 위해 WSJ dataset에서만 train 된 language model을 고려할 수 있음
- 이를 위해 논문은 beam search decoder를 채택하여 (Eq. 2)를 maximize 하는 방식으로 context network $\mathbf{c}$나 log-mel filter bank output으로부터 word sequence를 decode 함:
(Eq. 2) $\max_{\mathbf{y}}f_{AM}(\mathbf{y}|\mathbf{c})+\alpha\log p_{LM}(\mathbf{y})+\beta|\mathbf{y}|-\gamma\sum_{i=1}^{T}[\pi_{i}=\text{'|'}]$
- $f_{AM}$ : acoustic model, $p_{LM}$ : language model
- $\pi=\pi_{1},...,\pi_{L}$ : $\mathbf{y}$의 character
- $\alpha,\beta,\gamma$ : 각각 language model weights, word penality, silence penalty - WSJ를 decoding 하기 위해 hyperparameter를 tuning 하고 random search를 적용함
- Word-based language model의 경우 4000 beam size, 250 score threshold를 사용하고, character-based language model의 경우 1500 beam size, 40 score threshold를 사용함
- 이를 위해 논문은 beam search decoder를 채택하여 (Eq. 2)를 maximize 하는 방식으로 context network $\mathbf{c}$나 log-mel filter bank output으로부터 word sequence를 decode 함:
3. Experiments
- Settings
- Dataset : TIMIT, WSJ
- Comparisons : DeepSpeech2
- Results
- Pre-Training for the WSJ Benchmark
- 전체적으로 Wav2Vec이 가장 우수한 성능을 보임

- 특히 더 많은 data에 대해 pre-training 하는 경우 더 나은 성능을 얻을 수 있음

- Pre-Training for TIMIT
- TIMIT dataset에 대해서도 Wav2Vec의 성능이 가장 우수함

- Ablations
- Negative sample 수는 최대 10 sample까지만 유용하고 그 이상은 성능 향상에 큰 영향을 주지 못함
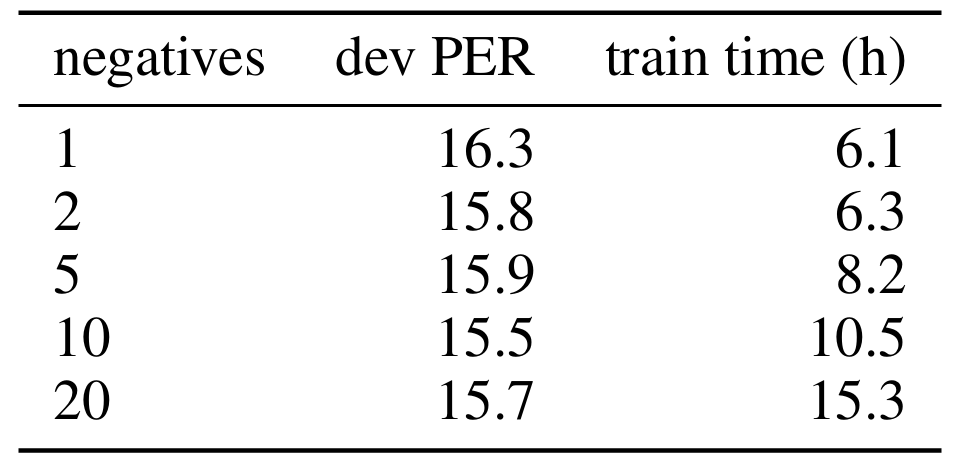
- $150k$ frame의 crop size를 사용할 때 최적의 성능을 달성함

- 최대 12-step을 predicting ahead 하는 경우 최적의 성능을 달성할 수 있음
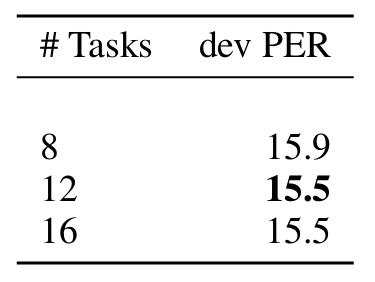
반응형
'Paper > Representation' 카테고리의 다른 글
댓글