

티스토리 뷰
Paper/TTS
[Paper 리뷰] F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
feVeRin 2025. 6. 23. 17:07반응형
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
- Diffusion Transformer를 기반으로 fully non-autoregressive text-to-speech system을 구성할 수 있음
- F5-TTS
- Input을 ConvNeXt로 modeling 하여 text representation을 refine 하고 easier align을 보장
- Sway Sampling을 Flow Matching-based model에 적용하여 효과적인 training/inference를 지원
- 논문 (ACL 2025) : Paper Link
1. Introduction
- VALL-E와 같은 Text-to-Speech (TTS) model은 few seconds의 audio prompt 만으로도 speaker를 mimic 할 수 있음
- 특히 ELLA-V, VALL-T, VoiceCraft 등의 autoregressive (AR)-based TTS는 next token을 consecutively predict 하여 뛰어난 zero-shot TTS 성능을 달성할 수 있음
- 한편으로 non-autoregressive (NAR) model은 parallel processing을 통해 빠른 추론이 가능함
- 대표적으로 VoiceBox, VoiceFlow, Matcha-TTS 등은 Flow Matching-Optimal Transport (FM-OT)를 사용하여 TTS system을 구축함
- BUT, NAR model에서 input text, synthesized speech 간의 alignment는 naturalness를 방해할 수 있음
- 이를 위해 DiTTo-TTS는 pre-trained language model의 encoded text로 condition 된 Diffusion Transformer (DiT)를 활용하지만 여전히 alignment robustness 측면에서 한계가 있음
-> 그래서 simple pipeline을 유지하면서 text-speech alignment를 향상한 NAR TTS model인 F5-TTS를 제안
- F5-TTS
- DiT와 ConvNeXt block을 사용하여 in-context learning의 text-speech alignment를 개선
- 추가적으로 naturalness, intelligibility, similarity를 향상할 수 있는 Sway Sampling을 도입
< Overall of F5-TTS >
- Flow Matching framework를 기반으로 text-speech alignment를 개선한 zero-shot NAR TTS model
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Preliminary
- Flow Matching
- Flow Matching (FM) objective는 standard Normal distribution $p(x)=\mathcal{N}(x|0,I)$와 같은 simple distribution으로부터 probability path $p_{t}$를 match 함
- 즉, FM loss는 neural network $v_{t}$를 사용하여 vector field $u_{t}$를 regress 함:
(Eq. 1) $\mathcal{L}_{FM}(\theta)=\mathbb{E}_{t,p_{t}(x)}||v_{t}(x)-u_{t}(x)||^{2}$
- $\theta$ : neural network parameter, $t\sim \mathcal{U}[0,1]$, $x\sim p_{t}(x)$
- $v_{t}$는 entire flow step, data range에서 training 되고, initial distribution에서 target distribution으로의 entire transformation process를 handling 함 - 이때 $p_{t}, u_{t}$를 approximate 하기 위한 prior knowledge가 없으므로, 실제로는 conditional probability path $p_{t}(x|x_{1})=\mathcal{N}(x|\mu_{t}(x_{1}), \sigma_{t}(x_{1})^{2}I)$를 고려함
- 그러면 Conditional Flow Matching (CFM) loss는 $\theta$에 대한 gradient와 identical 함
- $x_{1}$ : training data에 대한 random variable, $\mu,\sigma$ : Gaussian distribution의 time-dependent mean, scalar standard deviation - Flow Matching은 initial simple distribution에서 data sample의 target distribution을 construct 해야 함
- 이를 위해 conditional form으로 $\mu_{0}(x_{1})=0,\sigma_{0}(x_{1})=1,\mu_{1}(x_{1})=x_{1},\sigma_{1}(x_{1})=0$인 flow map $\psi_{t}(x)=\sigma_{t}(x_{1})x+\mu_{t}(x_{1})$을 구성함
- 그러면 모든 conditional probability path는 start, end에서 $p_{0},p_{1}$으로 converge 됨 - 결과적으로 flow는 vector field $d\psi_{t}(x_{0})/dt=u_{t}(\psi_{t}(x_{0})|x_{1})$를 제공하고, $x_{0}$로 $p_{t}(x|x_{1})$을 reparameterize 하면:
(Eq. 2) $\mathcal{L}_{CFM}(\theta)=\mathbb{E}_{t,q(x_{1}),p(x_{0})}\left|\left| v_{t}(\psi_{t}(x_{0}))-\frac{d}{dt} \psi_{t}(x_{0})\right|\right|^{2}$ - Optimal Transport (OT) form $\psi_{t}(x)=(1-t)x+tx_{1}$을 활용한 OT-CFM loss는:
(Eq. 3) $\mathcal{L}_{CFM}(\theta)=\mathbb{E}_{t,q(x_{1}),p(x_{0})}\left|\left| v_{t}((1-t)x_{0}+tx_{1})-(x_{1}-x_{0})\right|\right|^{2}$
- 이를 위해 conditional form으로 $\mu_{0}(x_{1})=0,\sigma_{0}(x_{1})=1,\mu_{1}(x_{1})=x_{1},\sigma_{1}(x_{1})=0$인 flow map $\psi_{t}(x)=\sigma_{t}(x_{1})x+\mu_{t}(x_{1})$을 구성함
- 해당 loss를 flow step $t$ 대신 log Signal-to-Noise Ratio (log-SNR) $\lambda$ 측면에서 보기 위해 $x_{1}-x_{0}$ 대신 $x_{0}$를 predict 하도록 parameterize 하면, CFM loss는 cosine schedule을 가지는 v-prediction loss와 equivalent 함
- 추론 시에는 initial distribution $p_{0}$의 sampled noise $x_{0}$, flow step $t\in [0,1]$에 대해 Ordinary Differential Equation (ODE) solver를 사용하여 $\psi_{0}(x_{0})=x_{0}$을 가지는 $d\psi_{t}(x_{0})/dt$의 integration을 evaluate 하여 $\psi_{1}(x_{0})$를 구함
- 여기서 Number of Function Evaluation (NFE)는 neural network를 통과하는 횟수로써, integration을 approximate 하기 위해 $[0,1]$의 multiple flow step을 input으로 제공함
- 즉, FM loss는 neural network $v_{t}$를 사용하여 vector field $u_{t}$를 regress 함:
- Classifier-Free Guidance
- Classifier-Free Guidance (CFG)는 explicit classifier와 graident를 directly compute 하지 않고 implicit classifier로 replace 함
- 이때 classifier gradient는 conditional generation probability, unconditional generation probability의 combination으로 얻어짐
- Training 시에는 certain rate로 condition을 dropping 하고 condition $c$가 주어졌을 때/주어지지 않았을 때의 inference output을 linear extrapolate 하여 final guided result를 얻을 수 있음:
(Eq. 4) $ v_{t,CFG}=v_{t}\left(\psi_{t}(x_{0}),c\right)+\alpha\left(v_{t}(\psi_{t}(x_{0}),c)-v_{t}(\psi_{t}(x_{0}))\right)$
- $\alpha$ : CFG strength
3. Method
- 논문은 high-level TTS를 목표로 VoiceBox와 같은 text-guided speech-infilling task로 model을 training 함
- 이때 DiTTo-TTS, E1-TTS와 같이 phoneme-level duration predictor 없이 training을 수행하면 zero-shot generation에서 higher naturalness를 달성할 수 있음
- Piepeline
- Training
- Infilling task는 surrounding audio와 full text에 따라 speech segment를 predict 함
- 먼저 audio sample을 $x$, transcript를 $y$, data pair를 $(x,y)$라고 하자
- 그러면 acoustic input은 mel-dimension $F$, sequence length $N$에 대해, audio sample $x$에서 추출된 mel-spectrogram feature $x_{1}\in\mathbb{R}^{F\times N}$으로 주어짐
- CFM으로부터 논문은 noisy speech $(1-t)x_{0}+tx_{1}$과 masked speech $(1-m)\odot x_{1}$을 model에 전달함
- $x_{0}$ : sampled Gaussian noise, $t$ : sampled flow step, $m\in \{0,1\}^{F\times N}$ : binary temporal mask
- 이후 raw text를 character sequence로 break 하고 mel-frame과 동일한 length로 filler token $\langle F\rangle$을 pad 하여 $i$-th character를 denote 하는 $c_{i}$ extended sequence $z$를 얻음:
(Eq. 5) $z=(c_{1},c_{2},...,c_{M}, \underset{(N-M)\,\, \text{times}}{\underbrace{\langle F\rangle,..., \langle F\rangle}})$ - 결과적으로 model은 $(1-m)\odot x_{1}, z$를 사용하여 $m\odot x_{1}$을 reconstruct 하도록 training 됨
- 이는 real data distribution $q$를 approximate 하기 위해 $P(m\odot x_{1}|(1-m)\odot x_{1},z)$ form으로 target distribution $p_{1}$을 학습하는 것과 같음
- Inference
- Desired content로 speech를 generate 하기 위해서는 audio prompt mel-spectrogram feature $x_{ref}$, transcription $y_{ref}$, text prompt $y_{gen}$이 필요함
- Audio prompt는 speaker characteristic을 제공하고, text prompt는 generated speech의 content를 guide 함 - Duration에 해당하는 sequence length $N$은 sample generation을 위한 desired length를 model에 informaing 하는 역할을 함
- 이때 $x_{ref}, y_{ref}, y_{gen}$을 기반으로 duration을 predict 하는 separate model을 활용할 수 있음
- BUT, 논문은 $y_{gen}, y_{ref}$의 characteristic 수에 대한 ratio를 기반으로 duration을 estimate 함
- Character length는 mel length 보다 길지 않으므로, filler token으로 padding을 적용함
- Learned distribution에서 sampling을 수행하기 위해, 논문은 converted mel-feature $x_{ref}$를 extended character sequence $z_{ref\cdot gen}$과 concatenate 하고 (Eq. 4)의 condition으로 사용함:
(Eq. 6) $v_{t}\left(\psi_{t}(x_{0}),c\right)=v_{t}\left((1-t)x_{0}+tx_{1}|x_{ref},z_{ref\cdot gen}\right)$ - 결과적으로 논문은 ODE solver를 사용하여 $\psi_{0}(x_{0})=x_{0}$에서 $\psi_{1}(x_{0})=x_{1}$으로 gradually integration을 수행함
- $d\psi_{t}(x_{0})/dt=v_{t}\left(\psi_{t}(x_{0}),x_{ref},z_{ref\cdot gen}\right)$ - 추론 시에는 model $v_{t}$와 ODE solver를 사용하여 mel을 생성하고, vocoder를 사용하여 waveform으로 convert 함
- Desired content로 speech를 generate 하기 위해서는 audio prompt mel-spectrogram feature $x_{ref}$, transcription $y_{ref}$, text prompt $y_{gen}$이 필요함

- F5-TTS
- 기존 E2-TTS는 padded charcater sequence를 input speech sequence와 directly concatenate 함으로써 semantic, acoustic entangling이 발생함
- 따라서 F5-TTS는 해당 model의 slow convergence, low robustness 문제를 해결하는 것을 목표로 함
- 특히 inference-time Sway Sampling은 성능을 maintain 하면서 faster inference를 지원할 수 있음
- 따라서 F5-TTS는 해당 model의 slow convergence, low robustness 문제를 해결하는 것을 목표로 함
- Model
- 논문은 zero-initialized Adaptive Layer Norm (AdaLN-zero)를 가지는 latent Diffusion Transformer (DiT)를 backbone으로 사용함
- 추가적으로 model alignment ability를 향상하기 위해 ConvNeXt-V2 block을 도입함 - Model input으로는 character sequence, noisy speech, masked speech를 사용하고, feature dimension에서 concatenate 하기 전에 character sequence는 ConvNeXt block으로 처리됨
- 해당 individual modeling은 text input이 in-context learning 이전에 prepare 될 수 있도록 함
- 한편으로 VoiceBox와 달리 text에 대한 rigid boundary는 explicitly introduce 되지 않음
- 대신 semantic, acoustic feature가 entire model에서 jointly learning 됨
- CFM에 대한 flow step $t$는 AdaLN-zero에 대한 condition으로 제공되고, flow step은 sinusoidal position을 통해 embedding 됨
- Concatenated input sequence에는 convolutional position embedding이 add 되고 self-attention에는 Rotary Position Embedding (RoPE)가 사용됨
- Extended character sequence $z$의 경우, ConvNeXt block input 이전에 absolute sinusoidal position embedding이 적용됨
- 결과적으로 F5-TTS는 AdaLN-zero를 포함한 DiT를 기반으로 phoneme-level duration predictor/explicit alignment process 없이 text input에 individual modeling space를 제공함
- 논문은 zero-initialized Adaptive Layer Norm (AdaLN-zero)를 가지는 latent Diffusion Transformer (DiT)를 backbone으로 사용함
- Sampling
- CFM은 cosine schedule을 가지는 v-prediction으로 볼 수 있음
- 특히 intermediate flow step에 weight를 주고 frequently sampling 하면, learning difficulty를 서로 다른 flow step $t\in [0,1]$에 evenly distribute 할 수 있음
- 따라서 논문은 uniformly sampled flow step $t\sim \mathcal{U}[0,1]$로 model을 training 하는 대신, 추론 시에는 non-uniform sampling을 적용함 - 이때 Sway Sampling function은 coefficient $s\in [-1,\frac{2}{\pi-2}]$를 가지고 monotonic 하게 주어짐:
(Eq. 7) $f_{sway}(u;s)=u+s\cdot \left(\cos\left(\frac{\pi}{2}u\right)-1+u\right)$
- 특히 intermediate flow step에 weight를 주고 frequently sampling 하면, learning difficulty를 서로 다른 flow step $t\in [0,1]$에 evenly distribute 할 수 있음
- 구체적으로 논문은 $u\sim \mathcal{U}[0,1]$을 sampling 한 다음, Sway Sampling function을 적용하여 sway sampled flow step $t$를 얻음
- $s<0$ 이면 sampling은 left로 sway 하고, $s>0$ 이면 right로 sway 하고, $s=0$ 이면 uniform sampling과 같음
- 특히 CFM은 early stage ($t\rightarrow 0$)에서는 pure noise로부터 speech contour를 sketching 하는데 focus 하고, 이후에는 fine-grained detail에 focus 함
- 즉, speech, text 간의 alignment는 first few generated result에 의해 결정됨 - 결과적으로 $s<0$의 scale parameter를 통해 smaller $t$에서 model inference를 더 많이 수행하면, ODE solver의 initial integration step에서 precise evaluation을 위한 startup information을 제공할 수 있음
- CFM은 cosine schedule을 가지는 v-prediction으로 볼 수 있음
4. Experiments
- Settings
- Dataset : Emilia
- Comparisons : VALL-E2, MELLE, VoiceBox, DiTTo-TTS, NaturalSpeech3, MaskGCT, CosyVoice
- Results
- 전체적으로 F5-TTS의 성능이 가장 우수함

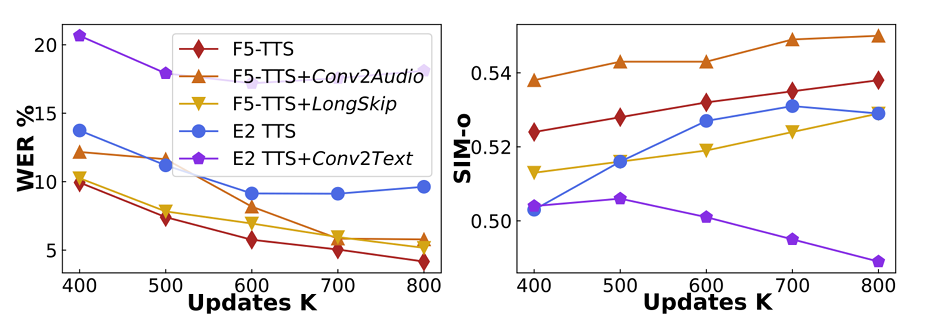
- Model Architecture
- F5-TTS는 small model에 대해서도 더 나은 성능을 보임
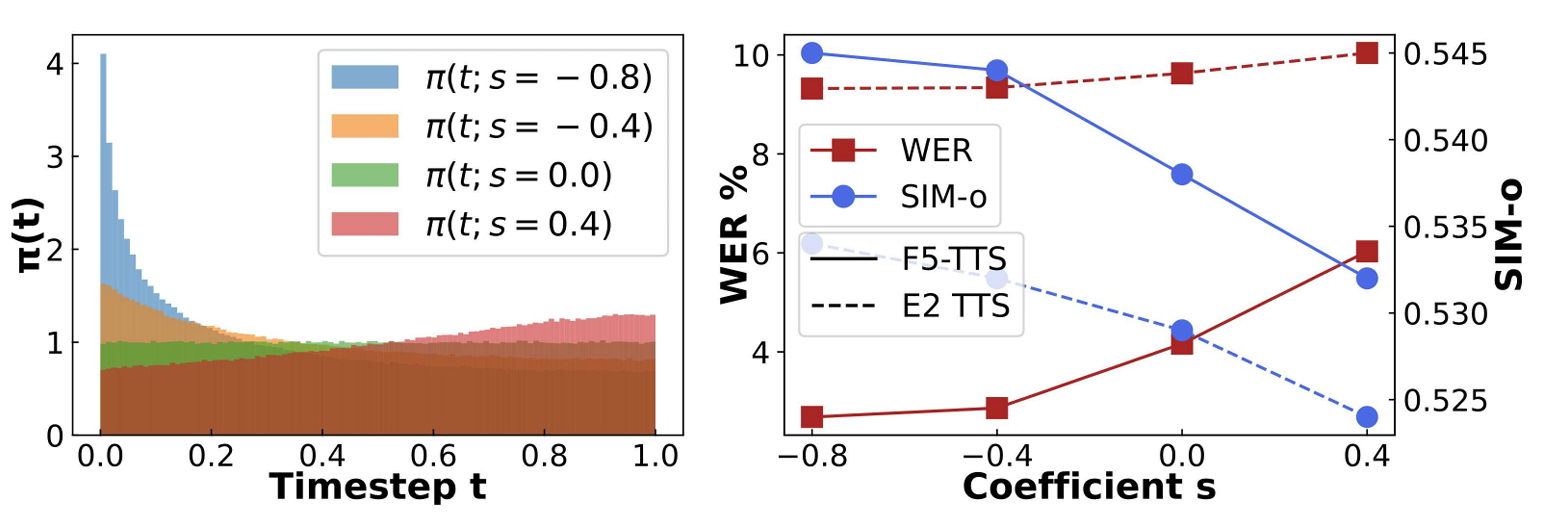
- Sway Sampling
- Negative $s$ value를 가지는 Sway Sampling을 사용하면 성능을 더 향상할 수 있음
반응형
'Paper > TTS' 카테고리의 다른 글
댓글