

티스토리 뷰
Paper/TTS
[Paper 리뷰] TTS-Transducer: End-to-End Speech Synthesis with Neural Transducer
feVeRin 2025. 6. 20. 17:14반응형
TTS-Transducer: End-to-End Speech Synthesis with Neural Transducer
- Text-to-Speech를 위해 neural transducer를 활용할 수 있음
- TTS-Transducer
- Transducer architecture를 사용하여 tokenized text, speech codec token 간의 first codebook에 대한 monotonic alignment를 학습
- Non-autoregressive Transformer를 기반으로 transducer loss에서 추출된 alignment를 사용해 remaining code를 predict
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 input text sequence에 condition 된 speech sequence를 생성하는 sequence-to-sequence task에 해당함
- 이때 TTS synthesis는 monotonic 하고 input text와 output speech 간의 order를 preserving 함
- BUT, speech는 frame-level에서 생성되므로 하나의 phoneme이 multiple frame에 해당할 수 있고, output length는 speaker style에 따라 달라질 수 있음
- 특히 일반적으로 사용되는 Non-Autoregressive (NAR), Autoregressive (AR) model은 각각 text token duration predictor에 대한 의존성과 word skipping/repeating 문제를 가짐
- 한편으로 Automatic Speech Recognition (ASR)에서 자주 활용되는 Transducer (RNNT)는 monotonic alignment constriant를 enforce 할 수 있음
- BUT, Transducer는 discrete unit prediction 수행하지만, speech는 continuous form으로 represent 되므로 TTS task에서 활용하기 어려움
- 이때 EnCodec, DAC와 같은 neural codec을 활용하면 audio prediction task를 discrete unit prediction task로 transform 할 수 있지만, Transducer가 모든 code를 sequentially predict 해야 함
- 결과적으로 loss computation이 많은 memory를 소모하게 됨
- 이때 TTS synthesis는 monotonic 하고 input text와 output speech 간의 order를 preserving 함
-> 그래서 discrete audio token에 end-to-end training을 도입한 TTS-Transducer를 제안
- TTS-Transducer
- First codebook code를 predict하는 Transducer를 도입하여 end-to-end training을 지원
- Aligned encoder output과 predicted previous codebook code를 사용하여 remaining code를 iteratively predict하는 Residual Codebook Head (RCH)를 적용
< Overall of TTS-Transducer >
- Tokenized text에서 audio code를 predict하는 end-to-end TTS-Transducer model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- TTS-Transducer는 VALL-E를 따라 2개의 component로 구성됨
- 먼저 VALL-E는:
- Autoregressive Transformer를 통해 input text, prompt에서 first codebook의 code를 predict 함
- 이후 non-autoregressive Transformer는 first component의 input text, prompt를 기반으로 다른 residual codebook의 code를 predict 함
- TTS-Transducer의 경우:
- Text unit이 주어졌을 때 first codebook code를 predict 할 수 있도록 neural Transducer를 도입하여 text, audio 간의 alignment를 학습함
- 이후 non-autoregressive Transformer에 해당하는 Residual Codebook Head (RCH)를 통해 aligned encoder output, previously predicted coder를 기반으로 remaining code를 iteratively predict 함
- 이때 Transducer encoder, RCH는 speaker embedding에 따라 condition 됨 - 모든 code가 predict 되면 audio codec model의 decoder를 사용하여 audio를 생성함
- 먼저 VALL-E는:
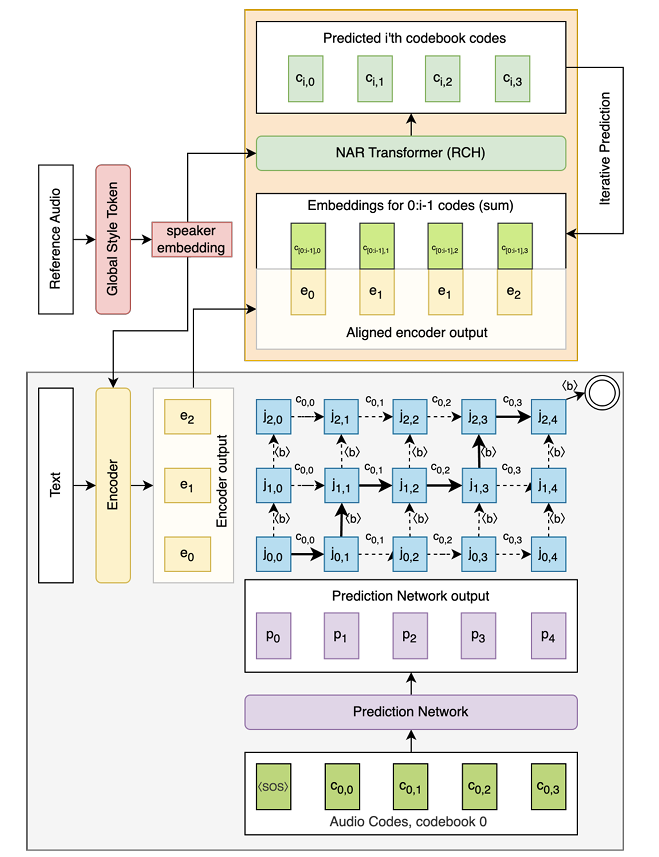
- Codebook Prediction
- First codebook $c_{0,i}$에 대한 prediction은 neural Transducer를 통해 학습됨
- 이때 encoder는 non-autoregressive Transformer로써 tokenized text $t_{i}$를 vector $e_{i}$ sequence로 변환함
- Training 시에는 Byte-Pair Encoding (BPE)를 사용하고, encoder에 conditional LayerNorm을 추가하여 speaker embedding conditioning을 반영함 - 한편으로 prediction network는 autoregressive Transformer-decoder로써, $\langle \text{SOS}\rangle$로 prepend 된 audio code $c_{0,i}$의 sequence를 vector $p_{j}$ sequence로 변환함
- 여기서 각 vector $e_{i},p_{j}$ combination에 대해 다음의 joint network가 적용됨:
(Eq. 1) $j_{i,j}=\text{Softmax}\left(\text{Linear}\left(\text{ReLU}(e_{i}+p_{j})\right)\right)$ - Joint network output은 $\langle \text{blank}\rangle$ symbol로 augment 된 first codebook에 대한 probability distribution과 같음
- 여기서 각 vector $e_{i},p_{j}$ combination에 대해 다음의 joint network가 적용됨:
- 논문은 $1$에서 $n$까지 모든 residual codebook을 predict 하기 위해,
- Previously predicted $[0,...,i-1]$ codebook과 aligned encoder output을 사용하여 $i$-th codebook code를 predict 하는 non-autoregressive Transformer-encoder를 도입함
- 여기서 input은 previously predicted code $c_{0:i-1,j}$의 embedding sum과 encoder vector $e_{k}$를 concatenate 하여 사용함
- 이때 encoder는 non-autoregressive Transformer로써 tokenized text $t_{i}$를 vector $e_{i}$ sequence로 변환함
- Speaker Representation
- TTS system은 일반적으로 speaker verification model의 fixed embedding을 사용하지만, 해당 embedding은 unseen speaker에 대해서는 generalize 되지 않음
- 따라서 논문은 Global Style Token (GST)를 사용하여 speaker style을 capture 함
- Target speaker의 reference speech는 mel-spectrogram으로 변환되어 speaker representation module에 전달됨 - Speaker representation module은 style token을 학습하는 convolutional RNN-based encoder로 구성됨
- Multi-head attention layer는 learned style token을 combine 하여 speaker embedding을 생성함
- 따라서 논문은 Global Style Token (GST)를 사용하여 speaker style을 capture 함
- End-to-End Training
- 각 training step에서 먼저 WFST-based RNNT loss를 사용하여 first component에 대한 forward pass를 수행함
- 이후 calculated RNNT lattice로부터 audio code와 encoder output의 alignment를 추출할 수 있고, 추출된 alignment에 따라 encoder frame을 distribute 함
- 특히 모든 residual codebook $[1:n]$에서 $i$를 randomly select 한 다음, second component로 $i+1$ codebook code를 predict 함
- 이때 cross-entropy loss $\lambda_{CE}$를 적용하여 optimize 함 - 결과적으로 total loss는 first, second component의 weighted sum으로 얻어짐:
(Eq. 2) $\lambda_{total}=(1-\alpha)*\lambda_{RNNT}+\alpha*\lambda_{CE}$
- $\alpha=0.4$
- Decoding
- Decoding 시에는 RNNT component를 evaluate 하여 first codebook prediction을 얻음
- 이때 efficient decoding을 위해 label-looping greedy decoding algorithm을 채택하여 각 step에서 greedy label selection을 nucleus sampling으로 replace 함
- 특히 TTS-Transducer의 prediction network는 non-autoregressive Transformer이므로 decoding을 speed up 하기 위해 key-value cache를 사용함 - 이후 $i$에서 $n$까지 remaining codebook에 대해, aligned encoder output을 활용하여 second component를 evaluate 함
- 이때 efficient decoding을 위해 label-looping greedy decoding algorithm을 채택하여 각 step에서 greedy label selection을 nucleus sampling으로 replace 함
3. Experiments
- Settings
- Dataset : LibriTTS, VCTK
- Comparisons : Bark, VALL-E-X, SpeechT5
- Results
- TTS-Transducer는 codec에 상관없이 모두 robust 한 성능을 달성함

- 12 encoder layer, 6 predictor layer, 12 Residual Codebook Head를 사용하면 intelligible speech를 얻을 수 있음

- 결과적으로 TTS-Transducer는 기존보다 뛰어난 성능을 달성함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글