

티스토리 뷰
Paper/Language Model
[Paper 리뷰] CosyVoice3: Towards In-the-Wild Speech Generation via Scaling-up and Post-Training
feVeRin 2025. 7. 27. 09:00반응형
CosyVoice3: Towards In-the-Wild Speech Generation via Scaling-up and Post-Training
- 앞선 CosyVoice2는 language coverage, domain diversity, data volume 측면에서 한계가 있음
- CosyVoice3
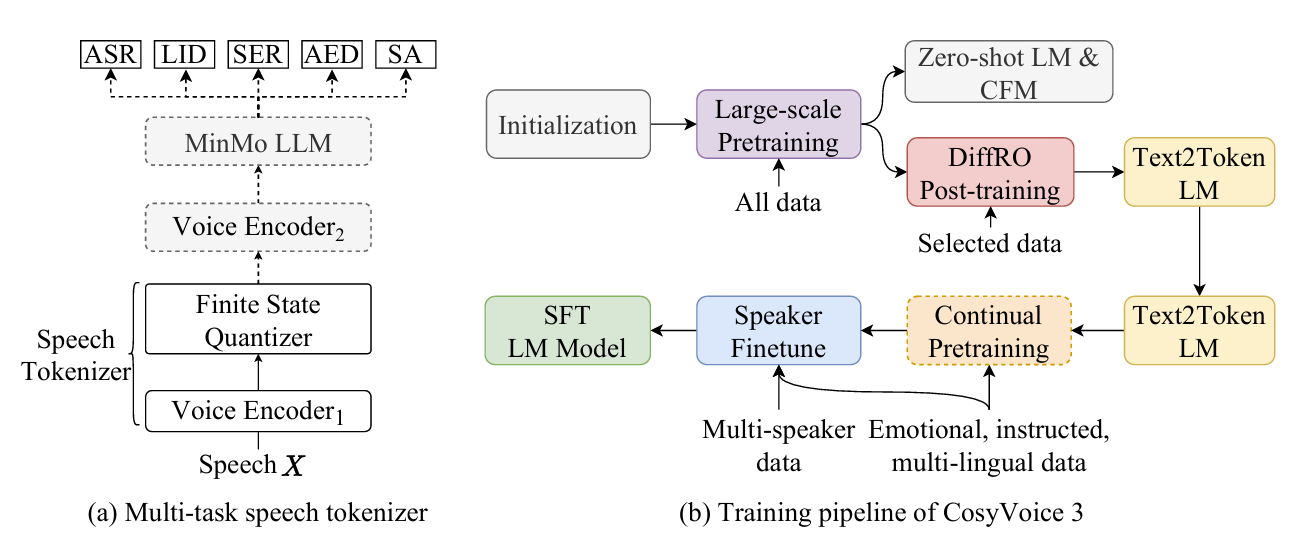
- Supervised multi-task training에 기반한 speech tokenizer를 도입
- Differentiable reward model을 위한 post-training을 적용
- Data size, model size scaling을 통해 다양한 domain과 text format을 지원
- 논문 (Alibaba 2025) : Paper Link
1. Introduction
- Zero-shot Text-to-Speech (TTS)는 any speaker의 timbre, style, prosody 등을 cloning 하는 것을 목표로 함
- 이때 zero-shot TTS model은 크게 3가지로 나눌 수 있음
- 특히 CosyVoice2는 bidirectional streaming scheme, text-based LLM, semantic token utilization optimize 등을 통해 high-quality low-latency bidirectional streaming synthesis를 지원할 수 있음
- BUT, CosyVoice2는 language coverage, domain diversity, data volume 측면에서 한계가 있음

-> 그래서 다양한 scenario와 더 많은 language를 지원하는 CosyVoice3를 제안
- CosyVoice3
- Large audio understanding language model에서 derive 된 speech tokenizer를 도입
- Speech generation을 위한 post-training strategy로써 Differentiable Reward Optimization (DiffRO)를 활용
- Dataset size, model size scaling을 통해 naturalness를 향상하고 다양한 language를 지원
< Overall of CosyVoice3 >
- CosyVoice2를 확장하여 더 많은 language coverage를 지원하는 zero-shot LLM TTS model
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
- CosyVoice2와 달리 CosyVoice3의 speech tokenizer는 pre-trained large-scale speech understanding model인 MinMo를 기반으로 함
- 특히 training pipeline은 large-scale pre-training, post-training, continual training, multi-speaker fine-tuning을 포함하여 구성됨
- Speech Tokenizer via Supervised Multi-task Training
- SenseVoice-Large ASR model에 Finite Scalar Quantization (FSQ)를 insert 한 CosyVoice2와 달리 CosyVoice3는 MinMo model의 speech encoder에 FSQ module을 insert 함
- 이때 MinMo training data의 subset을 통해 multilingual ASR, language identification, speech emotion recognition 등에 대한 supervised multi-task learning을 speech tokenizer에 적용함
- Training stage에서 input speech $X$는 $\text{Voice Encoder}_{1}$에 전달되어 intermediate representation $H$를 얻음
- 이때 $\text{Voice Encoder}_{1}$은 rotary positional embedding (RoPE)를 사용하는 12 Transformer block으로 구성됨
- 이후 intermediate representation $H$는 FSQ module에 feed 되어 quantize 되고, quantized representation은 $\text{Voice Encoder}_{2}$와 $\text{MinMo LLM}$을 포함한 MinMo module로 전달됨
- 이를 통해 text token의 posterior probability를 predict 함
- FSQ module에서 intermediate representation $H$는 $D$-dimensional low-rank space로 project 되고,
- 각 dimension은 bounded round operation $\text{ROUND}$를 사용하여 $[-K,K]$로 quantize 됨
- 이후 quantized low-rank representation $\bar{H}$는 original dimension $\tilde{H}$로 project 됨:
(Eq. 1) $ \bar{H}=\text{ROUND}(\text{Proj}_{down}(H))$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \tilde{H}=\text{Proj}_{up}(\bar{H})$ - Training 시 straight-through estimation이 FSQ module과 $\text{Voice Encoder}_{1}$의 gradient를 approximate 하기 위해 사용됨
- Speech token $\mu_{i}$는 $(2K+1)$-ary system에서 quantized low-rank representation $\bar{h}_{i}$의 index를 calculate 하여 얻어짐:
(Eq. 2) $\mu_{i}=\sum_{j=0}^{D-1}\bar{h}_{i,j}(2K+1)^{j}$
- 결과적으로 CosyVoice3의 speech tokenizer는 $\text{Voice Encoder}_{1}$, FSQ module의 low-rank projector, bounded round operation, index calculation으로 구성됨
- 해당 speech tokenizer는 25Hz token rate로 동작함
- Reinforcement Learning with Differentiable Reward Optimization
- Reinforcement learning (RL)은 speech quality를 향상하는데 효과적임
- BUT, TTS task의 resulting voice는 consistently high-similarity를 보이므로 positive/negative feedback을 differentiate 하기 어려움
- 따라서 RL을 위한 reward model을 training 하는데 한계가 있음 - 이를 해결하기 위해 논문은 synthesized audio 대신 speech token을 directly optimize 하는 Differentiable Reward Optimization (DiffRO)를 도입함
- DiffRO는 ASR training data를 기반으로 Token2Text model을 training 한 다음, posterior probability를 reward로 사용함
- 이때 논문은 Gumbel-Softmax를 사용하여 LLM이 predict 한 token을 sampling 한 다음, backpropagation을 통해 reward score를 maximize 하도록 speech token을 directly optimize 함:
(Eq. 3) $\tilde{\mu}_{t}=\text{GumbelSoftmax}P_{\pi_{\theta}}\left(\mu_{t} |\mu_{1:t-1};Y\right)$
(Eq. 4) $R_{ASR}(Y)=\log P_{ASR}(\tilde{Y}_{n}=Y_{n}|Y_{1:n-1};\tilde{\mu}_{1:T})$
- $\mu_{t},\tilde{\mu}_{t}$ : time step $t$의 ground-truth/predicted speech token
- $R_{ASR}$ : Token2Text model에 기반한 reward function
- 여기서 $R_{ASR}(Y)$는 $\tilde{\mu}$가 text에서 모든 information을 catch 하도록 유도하므로, TTS system의 text clarity와 accuracy를 향상할 수 있음 - 결과적으로 LLM을 directly optimize 하여 output token을 ASR preference와 align 하고 Kullback-Leibler (KL) divergence를 사용해 model이 reference model에서 deviate 하는 것을 방지할 수 있음
- 이때 논문은 output token-level logit에서 KL divergence를 compute 함:
(Eq. 5) $\pi_{\theta}^{*}=\max_{\pi_{\theta}}\mathbb{E}\left[ R(Y)\right]-\beta D_{KL}\left[\pi_{\theta}(\mu|Y)|| \pi_{ref}(\mu|Y)\right]$
(Eq. 6) $D_{KL}\left[\pi_{\theta}(\mu|Y)||\pi_{ref} (\mu|Y)\right]=\sum_{t=1}^{T}\sum_{k=0}^{Q} p_{\pi_{\theta}}(\mu_{t}=k)\log \left(\frac{P_{\pi_{\theta}}(\mu_{t}=k)}{P_{\pi_{ref}}(\mu_{t}=k) }\right)$
- $Q$ : FSQ module의 codebook size로써 $(2K+1)^{D-1}$과 같음
- Token2Text model 외에도 DiffRO는 SER, MOS score prediction과 같은 다른 downstream task에 대한 Multi-Task Reward (MTR) modeling에도 사용됨
- MTR은 voice attribute $\{A_{i}\}^{K}_{i=1}$이 instruction을 따르도록 하여 TTS system을 지원함:
(Eq. 7) $R_{MTR}\left(Y,\left\{ A_{i}\right\}^{K}_{i=1}\right)= \sum_{i}\log P_{task_{i}}\left(\tilde{A}_{i}=A_{i}|\tilde{\mu}\right)$
- BUT, TTS task의 resulting voice는 consistently high-similarity를 보이므로 positive/negative feedback을 differentiate 하기 어려움
- Pronunciation Inpainting
- LLM-based TTS model은 주로 BPE text tokenizer를 사용하여 raw text를 input으로 취급함
- BUT, 해당 방식은 pronunciation controllability 측면에서 한계가 있음
- 특히 polyphonic character, rare word로 인한 mispronunciation에 대해 human intervention 기반의 robust method가 필요함 - 이를 위해 CosyVoice3는 auxiliary dataset을 base training set에 add 함
- Chinese monophonic character의 경우 pinyin으로 replace 하고, English monophonic word의 경우 CMU pronunciation dictionary를 활용하여 phoneme으로 replace 함
- BUT, 해당 방식은 pronunciation controllability 측면에서 한계가 있음
- Self-Training for Text Normalization
- Text tokenization 전에, 대부분의 TTS system은 raw text를 text normalization (TN) module을 사용하여 numbers/special symbols 등을 verbailzation text로 convert 함
- BUT, 해당 방식은 hand-crafted rule에 의존하므로 coverage 측면에서 한계가 있으므로, 논문은 LLM을 활용하여 end-to-end TTS system을 구축함
- 특히 raw text를 input으로 사용하여 auxiliary training set을 다음과 같이 구성함:
- Raw text를 internal rule-based TN module에 전달하여 text-normalized text를 얻은 다음, CosyVoice2를 통해 audio를 synthesis 함
- Qwen-Max가 text normalization을 수행하도록 prompt 한 다음, CosyVoice2를 사용하여 normalized text의 audio를 synthesis 함
- Qwen-Max가 기존 text-audio pair의 text에 대해 inverse text normalization을 수행하도록 prompt 하여 unnormalized text를 얻음
- 이후 raw text와 해당 audio는 paired sample로 취급하여 base training set에 directly add 함
- 해당 extended training set을 통해 CosyVoice3는 다양한 special symbol에 대해 더 나은 robustness와 coverage를 달성할 수 있음

- Instructed Speech Generation
- CosyVoice3의 controllability, expressiveness를 향상하기 위해 high-quality instructed dataset을 integrate 하고, natural language instruction과 fine-grained instruction을 지원함
- Natural language instruction의 경우 natural language description과 special end token $\text{<|endofprompt|>}$가 input text에 prepend 됨
- Fine-grained instruction은 text token과 vocal feature tag 간의 vocal burst를 지원함
- e.g.) $\text{[laughter]},\text{[breath]}$ marker를 활용하여 noticeable laughter, breath를 생성할 수 있음 - $\text{<strong>XXX</strong>}$ tag는 specific word에 대한 emphasis를 indicate 하기 위해 사용됨

- Capability Transfer in Speaker Fine-Tuning
- Turning a Monolingual Speaker into a Polyglot
- Monolingual target speaker가 multiple language를 speak 하도록 하기 위해, 논문은 모든 supported language를 포함하는 randomly-selected speaker의 auxiliary training dataset을 활용함
- 각 utterance의 speaker ID와 language ID는 natural language instruction을 통해 specify 됨
- Transferring the Capability of Instructed Generation
- Speaker-specific data로 pre-trained model을 fine-tuning 하면 individual speaker에 대한 speech quality와 expressiveness를 향상할 수 있음
- 이를 위해 논문은 speaker ID로 partially label 된 training dataset을 활용함
- 이때 pre-training instruction-follwoing dataset과 target speaker의 high-quality dataset도 포함됨
- Natural language instruction prompt에서는 speaker prompt와 style prompt를 specify 함
- Speaker ID/style label이 없는 경우, prompt에서 해당 field를 blank로 처리함
- Fine-tuning 시에는 speaker prompt/style prompt를 randomly mask 하여 transfer capability를 향상함
- 이를 통해 다양한 speaker에 대한 instruction coverage를 보장하고 instructed generation의 catastrophic forgetting을 방지함
3. Experiments
- Settings
- Dataset : 아래 표/그림 참고
- Comparisons : CosyVoice, CosyVoice2, MaskGCT, E2-TTS, F5-TTS 등

- Results
- SEED dataset에 대해 CosyVoice3가 가장 우수한 TTS 성능을 달성함
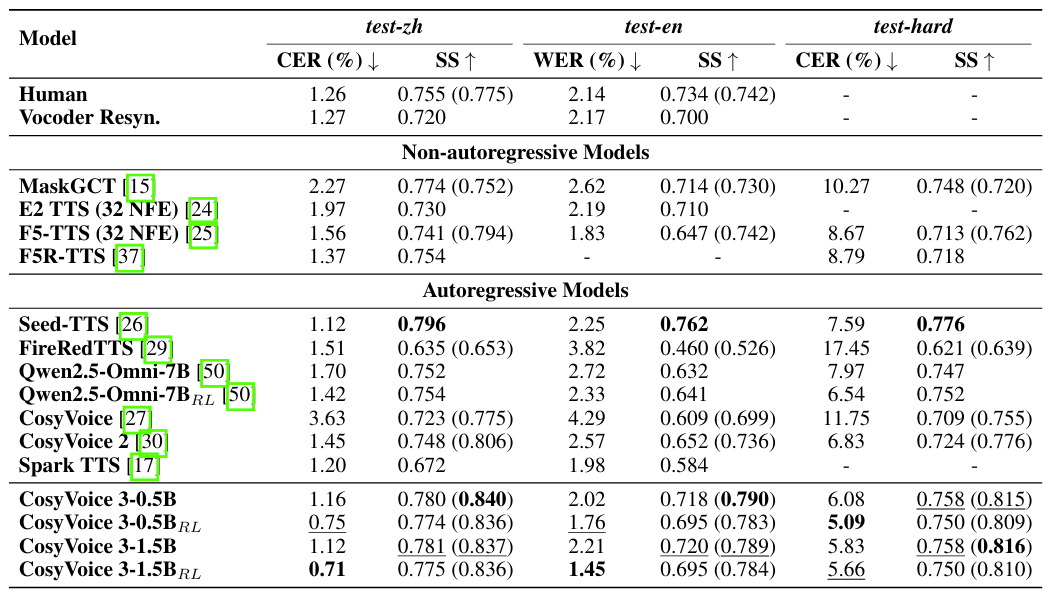
- Results of Multilingual Voice Cloning
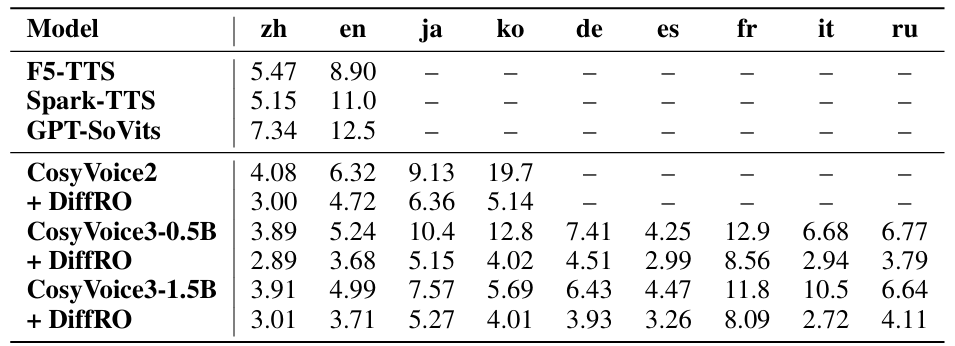
- Multilingual voice cloning에서도 CosyVoice3가 가장 뛰어난 성능을 달성함
- Hard sample에 대한 voice cloning에서도 우수한 성능을 보임

- Results of Cross-Lingual Voice Cloning
- Cross-lingual voice cloning에서도 CosyVoice3의 성능이 가장 우수함

- WER, Speaker Similarity (SS) 측면에서도 우수한 성능을 보임

- Results of Emotional Voice Cloning
- Emotional voice cloning에서도 CosyVoice3의 성능이 가장 뛰어남
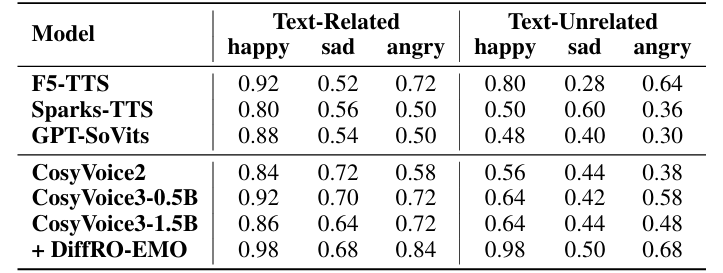
- Subjective evaluation 측면에서도 CosyVoice3가 가장 우수함

- Ablation of Speech Tokenizer
- Multi-task learning-based speech tokenizer는 multilingual ASR capability를 effectively maintain 함
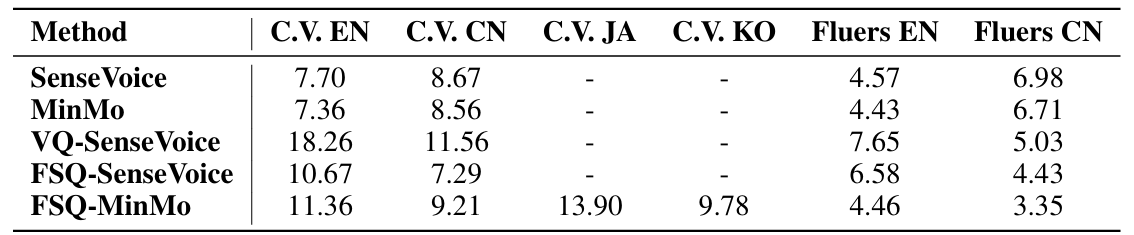
- AIR-Bench benchmark에서도 CosyVoice3의 FSQ가 더 나은 성능을 보임

- Downstream TTS task에 대해, CosyVoice3의 speech tokenizer를 사용하면 SoundStream, HuBERT, W2V-BERT 등 보다 우수한 성능을 달성할 수 있음

- Pronunciation Inpainting
- Pronunciation inpainting 측면에서도 높은 correction rate를 달성함

- Instructed Generation
- Instructed TTS task도 마찬가지로 CosyVoice3의 성능이 더 우수함

- Results on Speaker Fine-Tuned Models
- Training data의 volume, diversity가 증가할수록 fine-tuned model의 error rate는 감소함

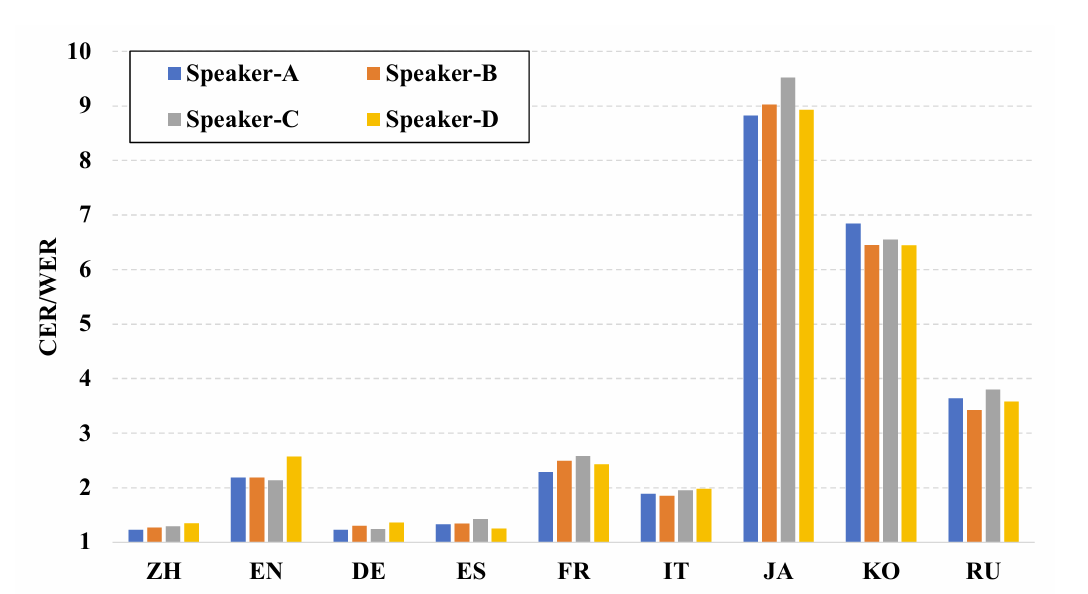
- Results on Turning a Monolingual Speaker into a Polyglot
- CosyVoice3는 Chinese, English, German, Spanish, French Italian, Russian에 대해서는 monolingual speaker 변경에 큰 영향을 받지 않음
- 반면 Japanese, Korean의 경우 CER/WER이 $9\%$ 정도로 저하됨
반응형
'Paper > Language Model' 카테고리의 다른 글
댓글