

티스토리 뷰
Paper/Language Model
[Paper 리뷰] MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
feVeRin 2025. 2. 23. 12:27반응형
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
- Large-scale text-to-speech system은 autoregressive/non-autoregressive 방식으로 나눌 수 있음
- Autoregressive 방식은 robustness와 duration controllability 측면에서 한계가 있음
- Non-auotregressive 방식은 training 중에 text, speech 간의 explicit alignment information이 필요함 - MaskGCT
- Text, speech supervision 간의 explicit alignment information과 phone-level duration prediction이 필요 없는 fully non-autoregressive text-to-speech model
- Two-stage framework를 활용하여 text로부터 semantic token을 예측한 다음, 해당 semantic token을 condition으로 하는 acoustic token을 예측
- Mask-and-predict learning을 통해 주어진 condition과 prompt에 따라 masked token을 생성
- 논문 (ICLR 2025) : Paper Link
1. Introduction
- SpearTTS, VALL-E, CLaM-TTS, VoiceCraft 등의 large-scale zero-shot text-to-speech (TTS) system은 주로 autoregressive (AR), non-autoregressive (NAR) model을 활용하여 구성됨
- 먼저 AR-based system은 speech를 discrete token으로 quantize 한 다음, decoder-only model을 사용하여 token을 autoregressively generate 함
- BUT, 해당 AR 방식은 poor robustness, slow speed의 문제가 있음 - 한편 VoiceBox, Mega-TTS2와 같이 diffusion, GAN, flow matching을 활용하는 NAR-based system은 explict alignment information과 phoneme-level duration이 필요하므로 pipeline이 복잡해지고 less diverse speech가 생성됨
- 최근에는 AR, NAR model 대신 masked generative transformer가 뛰어난 generation 성능을 보이고 있음
- Masked generative transformer는 mask-and-predict paradigm을 통해 training 되고 추론 시에는 iterative parallel decoding을 활용함
- 특히 SoundStorm은 speech semantic token을 condition으로 SoundStream에서 추출한 multi-layer acoustic token을 predict 하기 위해 masked generative transformer를 도입했음
- BUT, AR model의 semantic token을 input으로 receive 하므로 masked generative model을 활용하지 못함
- 그 외에도 speech-text alignment supervision과 phone-level duration prediction이 필요함
- 먼저 AR-based system은 speech를 discrete token으로 quantize 한 다음, decoder-only model을 사용하여 token을 autoregressively generate 함

-> 그래서 TTS를 위한 masked generative transformer 기반의 fully non-autoregressive model인 MaskGCT를 제안
- MaskGCT
- Mask-and-Predict learning paradigm을 활용한 two-stage framework를 채택
- First stage에서 text-to-semantic (T2S) model은 explicit duration prediction 없이 text token sequence와 prompt speech semantic token sequence를 prefix로 사용함
- 이후 in-context learning을 통해 masked semantic token을 predict 함 - Second stage에서 semantic-to-acoustic (S2A) model은 semantic token을 사용하여, prompt acoustic token이 있는 RVQ-based speech codec에서 추출된 masked acoustic token을 predict 함
- 추론 시에는 text sequence가 주어졌을 때, few iteration step으로 다양한 specified length의 semantic token을 생성함
- First stage에서 text-to-semantic (T2S) model은 explicit duration prediction 없이 text token sequence와 prompt speech semantic token sequence를 prefix로 사용함
- 추가적으로 기존의 $k$-means 대신 VQ-VAE를 채택하여 speech self-supervised semantic token embedding을 quantize
- 이를 통해 single codebook으로도 semantic feature의 information loss를 minimize 함
- Mask-and-Predict learning paradigm을 활용한 two-stage framework를 채택
< Overall of MaskGCT >
- Masked Generative Transformer를 활용한 fully non-autoregressive TTS model
- 결과적으로 기존보다 뛰어난 합성 성능을 달성
2. Method
- Background: Non-Autoregressive Masked Generative Transformer
- Some data의 discrete representation sequence $\mathbf{X}$가 주어졌을 때, $\mathbf{X}_{t}=\mathbf{X}\odot \mathbf{M}_{t}$를 $\mathbf{X}$의 token subset을 해당 binary mask $\mathbf{M}_{t}=[m_{t,i}]^{N}_{i=1}$으로 mask 하는 process라고 하자
- $m_{t,i}=1$인 경우, $x_{i}$를 special $\text{[MASK]}$ token으로 replace 하고, $m_{t,i}=0$인 경우, $x_{i}$를 unmask 함
- 여기서 각 $m_{t,i}$는 parameter $\gamma(t)$를 가지는 Bernoulli distribution에 따라 independently identically distribute 됨
- $\gamma(t) \in(0,1]$ : mask schedule function, $\mathbf{X}_{0}=\mathbf{X}$
- e.g.) $\gamma(t)=\sin\left(\frac{\pi t}{2T}\right),\,\, t\in(0,T]$ - Non-autoregressive masked generative transformer는 unmasked token과 condition $\mathbf{C}$를 기반으로 masked token을 predict 함
- 즉, $p_{\theta}(\mathbf{X}_{0}|\mathbf{X}_{t},\mathbf{C})$로 modeling 됨
- 그러면 parameter $\theta$는 masked token의 negative log-likelihood를 minimize 하도록 optimize 됨:
(Eq. 1) $\mathcal{L}_{mask}=\mathbb{E}_{\mathbf{X}\in\mathcal{D},t\in[0,T]}-\sum_{i=1}^{N}m_{t,i}\cdot \log (p_{\theta}(x_{i}|\mathbf{X}_{t},\mathbf{C}))$
- 추론 시에는 iterative decoding을 통해 token을 parallel decode 함
- 먼저 fully masked sequence $\mathbf{X}_{T}$에서 시작하자
- $1$에서 $S$까지 각 step $i$에 대한 total decoding step을 $S$라고 하면, $p_{\theta}(\mathbf{X}_{0}|\mathbf{X}_{T-(i-1)\cdot\frac{T}{S}},\mathbf{C})$에서 $\hat{\mathbf{X}}_{0}$를 sampling 할 수 있음
- 이후 confidence score에 따라 $\left\lfloor N\cdot \gamma\left(T-i\cdot\frac{T}{S}\right)\right\rfloor$ token을 sampling 하고, remask 하여 $\mathbf{X}_{T-i\cdot\frac{T}{S}}$를 얻음
- $N$ : $\mathbf{X}$의 total token 수 - $\hat{\mathbf{X}}_{0}$의 $\hat{x}_{i}$에 대한 confidence score는 $x_{T-(i-1)\cdot\frac{T}{S},i}$가 $\text{[MASK]}$ token인 경우 $p_{\theta}(x_{i}|\mathbf{X}_{T-(i-1)\cdot \frac{T}{S}},\mathbf{C})$에 assign 됨
- 그렇지 않은 경우 $\hat{x}_{i}$의 confidence score를 $1$로 설정하여 $\mathbf{X}_{T-(i-1)\cdot\frac{T}{S}}$에서 already unmasked token이 remask 되지 않도록 함
- Model Overview
- MaskGCT는 two-stage framework로 구성됨
- 일반적으로 first stage에서는 text를 사용하여 content information과 partial prosody information을 포함하는 speech semantic representation token을 predict 함
- Second stage에서는 더 많은 acoustic information을 학습하도록 training 됨 - 한편으로 기존의 SpearTTS, VALL-E 등은 first stage에서 autoregressive model을 사용함
- BUT, MaskGCT는 text-speech alignment supervision과 phone-level duration prediction 없이 두 stage 모두에 non-autoregressive masked generative modeling을 도입함
- First stage model의 경우 $\mathbf{S}^{p}, \mathbf{P}$를 condition으로 하여 $p_{\theta_{s1}}(\mathbf{S}|\mathbf{S}_{t},(\mathbf{S}^{p},\mathbf{P}))$를 학습하도록 training 됨
- $\mathbf{S}$ : semantic codec에서 얻은 speech semantic representation token sequence
- $\mathbf{S}^{p}$ : prompt semantic token sequence
- $\mathbf{P}$ : text token sequence - Second stage model은 $p_{\theta_{s2}}(\mathbf{A}|\mathbf{A}_{t},(\mathbf{A}^{p},\mathbf{S}))$을 학습하도록 training 됨
- $\mathbf{A}$ : DAC, SoundStream과 같은 speech acoustic codec의 multi-layer acoustic token sequence
- 구조적으로는 SoundStrom과 유사함
- First stage model의 경우 $\mathbf{S}^{p}, \mathbf{P}$를 condition으로 하여 $p_{\theta_{s1}}(\mathbf{S}|\mathbf{S}_{t},(\mathbf{S}^{p},\mathbf{P}))$를 학습하도록 training 됨
- 일반적으로 first stage에서는 text를 사용하여 content information과 partial prosody information을 포함하는 speech semantic representation token을 predict 함

- Speech Semantic Representation Codec
- Discrete speech representation은 semantic token과 acoustic token으로 나눌 수 있음
- 일반적으로 semantic token은 speech Self-Supervised Learning (SSL) feature를 discretizing 하여 얻어짐
- 특히 기존의 large TTS system은 text를 사용하여 semantic token을 predict 한 다음, 다른 model을 사용하여 acoustic token/feature를 predict 하는 방식을 사용함
- Semantic token이 text/phoneme과 highly correlate 되어 있으므로 acoustic token을 directly predict 하는 것보다 prediction이 더 straightforward 하기 때문
- BUT, 기존에 사용된 $k$-means-based semantic discretization은 information loss가 발생할 수 있음
- 결과적으로 high-quality speech reconstruction과 precise acoustic token prediction을 어렵게 함
- 따라서 MaskGCT는 information loss를 minimize 하면서 semantic representation을 discretize 하는 것을 목표로 함
- 이를 위해 RepCodec과 같이 VQ-VAE를 활용하여 speech SSL model에서 speech semantic representation을 reconsturct 하는 vector quantization codebook을 학습함 - Speech semantic representation sequence $\mathbf{S}\in\mathbb{R}^{T\times d}$의 경우, vector quantizer는 encoder $\mathcal{E}(\mathbf{S})$의 output을 $\mathbf{E}$로 quantize 하고 decoder는 $\mathbf{E}$를 다시 $\hat{\mathbf{S}}$로 reconstruct 함
- 이때 $\mathbf{S}, \hat{\mathbf{S}}$ 간의 reconstruction loss를 사용하여 encoder, decoder를 optimize 하고 codebook loss를 사용하여 codebook을 optimize 하고, commitment loss를 사용해 straight-through method로 encoder를 optimize 함 - 결과적으로 semantic representation codec을 training 하기 위한 total loss는:
(Eq. 2) $\mathcal{L}_{total}=\frac{1}{Td}(\lambda_{rec}\cdot ||\mathbf{S}-\hat{\mathbf{S}}||_{1}+\lambda_{codebook}\cdot || \text{sg}(\mathcal{E}(\mathbf{S}))-\mathbf{E}||_{2}+\lambda_{commit}\cdot || \text{sg}(\mathbf{E})-\mathcal{E}(\mathbf{S})||_{2})$
- $\text{sg}$ : stop-gradient - 구조적으로는 w2v-BERT의 17th layer의 hidden state를 speech encoder의 semantic feautre로 활용함
- 여기서 Encoder, Decoder는 multiple ConvNeXt block으로 구성됨
- 추가적으로 DAC를 따라 factorized code를 사용하여 encoder output을 low-dimensional latent variable space로 project 함
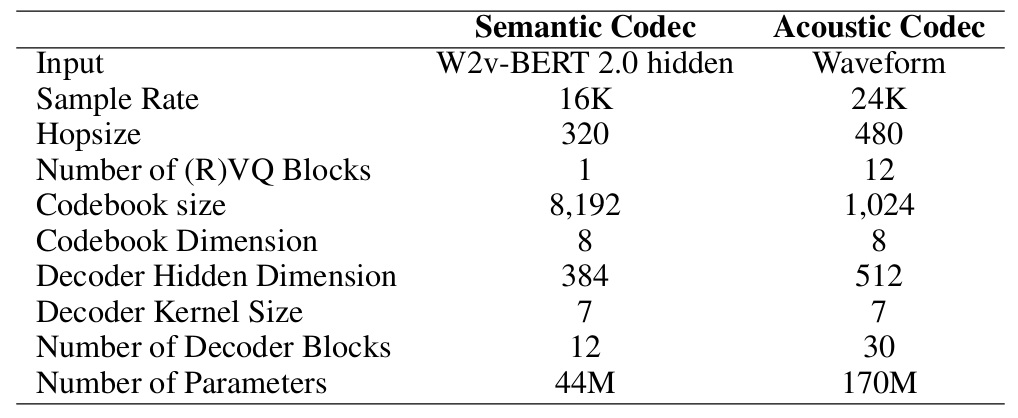
- Codebook에는 각각 dimension이 8인 8192 entry가 포함됨
- Text-to-Semantic Model
- MaskGCT는 autoregressive model이나 text-to-speech alignment information 없이 non-autoregressive maksed generative transformer를 사용하여 Text-to-Semantic (T2S) model을 training 함
- Training 중에 semantic token sequence의 prefix를 randomly extract 하여 $\mathbf{S}^{p}$로 나타냄
- 이후 text token sequence $\mathbf{P}$를 $\mathbf{S}^{p}$와 concatenate 하여 condition을 구성함
- 이때 단순히 $(\mathbf{P},\mathbf{S}^{p})$를 prefix sequence로 input masked semantic token sequence $\mathbf{S}_{t}$에 add 한 다음, language model의 in-context learning ability를 활용함
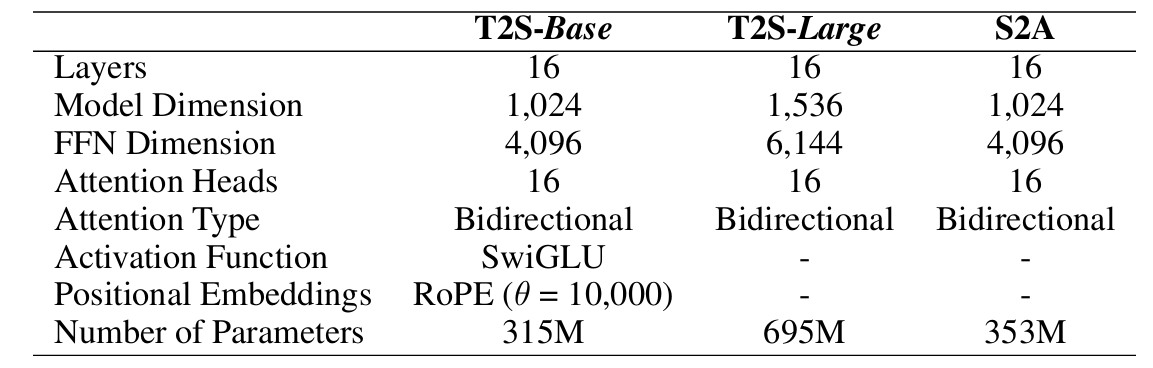
- 구조적으로는 GELU activation, rotation position encoding 등을 활용하는 Llama-style transformer를 model backbone으로 사용하고, causal attention을 bidirectional attention으로 대체함
- 추가적으로 timestep $t$를 condition으로 하는 adaptive RMSNorm을 사용함 - 추론 시에는 text, prompt semantic token sequence를 condition으로 specified length의 target semantic token sequence를 생성함
- 여기서 text, prompt speech duration에 따라 total duration을 predict 하기 위해 flow matching-based duration prediction model을 도입하여 in-context learning을 지원함
- Training 중에 semantic token sequence의 prefix를 randomly extract 하여 $\mathbf{S}^{p}$로 나타냄
- Semantic-to-Acoustic Model
- Semantic token에 따라 condition 된 masked generative codec transformer를 사용하여 Semantic-to-Acoustic (S2A) model을 training 함
- 해당 S2A model은 multi-layer acoustic token sequence를 생성하는 SoundStrom을 기반으로 함
- 먼저 acoustic token sequence $\mathbf{A}^{1:N}$의 $N$ layer가 주어지면, training 중에 $1$에서 $N$ 사이에서 하나의 layer를 select 함
- 여기서 acoustic token sequence의 $j$-th layer를 $\mathbf{A}^{j}$라 하고, $\mathbf{A}^{j}$를 timestep $t$에서 $\mathbf{A}^{j}$를 mask 하여 $\mathbf{A}^{j}_{t}$를 얻음
- 이후 model은 prompt $\mathbf{A}^{p}$, semantic token sequence $\mathbf{S}$, acoustic token의 $j$보다 작은 모든 layer에 따라 $\mathbf{A}^{j}$를 predict 하도록 training 됨
- 즉, $p_{\theta_{s2a}}(\mathbf{A}^{j}|\mathbf{A}_{t}^{j},(\mathbf{A}^{p},\mathbf{S},\mathbf{A}^{1:j-1}))$과 같음 - 이후 $j$를 linear schedule $p(j)=1-\frac{2j}{N(N+1)}$에 따라 sampling 함
- S2A model input의 경우 semantic token sequence의 frame 수가 prompt acoustic sequence와 target acoustic sequence의 frame 수 합과 같음
- 따라서 semantic token의 embedding과 layer $1$에서 $j$까지의 acoustic token embedding을 summation 하여 사용함 - 추론 시에는 각 layer 내에서 iterative parallel decoding을 사용하여 coarse-to-fine의 각 layer에 대한 token을 생성함

- Speech Acoustic Codec
- Speech acoustic codec은 speech information을 preserve 하면서 speech waveform을 multi-layer discrete token으로 quantize 하도록 training 됨

- Other Applications
- MaskGCT는 duration-controllable speech translation (cross-lingual dubbing), emotion control, speech content editing, zero-shot TTS 등에 사용될 수 있음

3. Experiments
- Settings
- Dataset : Emilia, LibriSpeech, SeedTTS
- Comparisons : NaturalSpeech, VALL-E, VoiceBox, VoiceCraft, XTTS, CosyVoice
- Results
- Zero-Shot TTS
- 전체적으로 MaskGCT의 성능이 가장 뛰어남

- Autoregressive vs. Masked Generative Models
- AR + SoundStorm으로 구성된 model과 비교하여 MaskGCT가 더 robust 한 성능을 보임

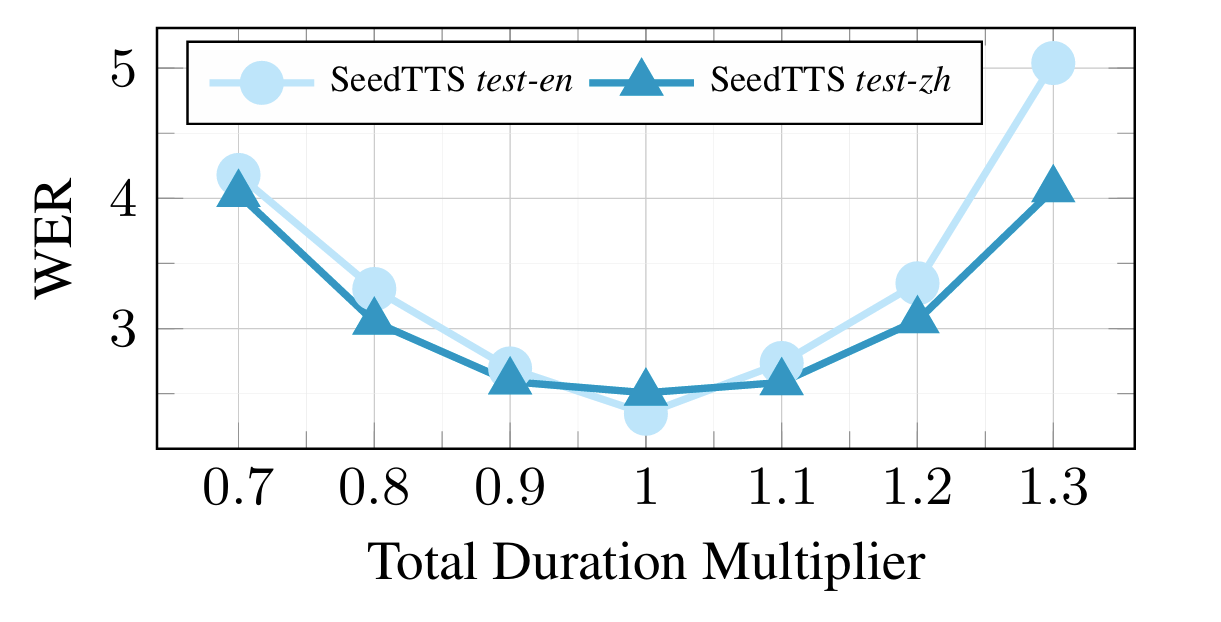
- Duration Length Analysis
- Duration multiplier가 $1.0$인 경우 가장 낮은 WER을 달성함
- Speech Style Imitation
- MaskGCT는 accent, emotion과 같은 speech style을 효과적으로 반영할 수 있음


- Choice of Semantic Representation Codec
- VQ-based semantic token과 $k$-menas-based semantic token을 비교해 보면
- VQ-based token을 사용하는 경우, speech reconstruction의 성능을 더욱 향상할 수 있음

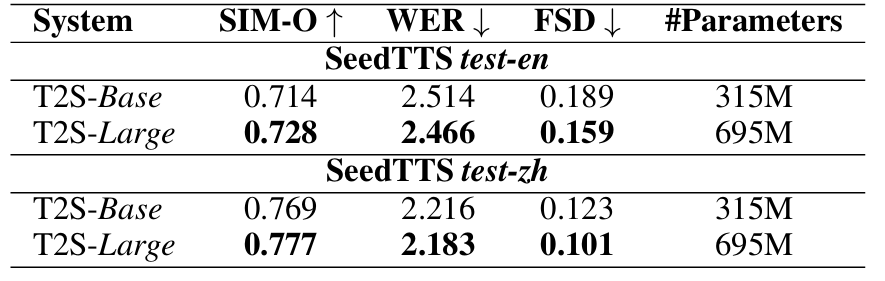
- Ablation Study
- Base model을 사용하더라도 Large model에 비해 성능 저하가 크지 않음
반응형
'Paper > Language Model' 카테고리의 다른 글
댓글