

티스토리 뷰
Paper/TTS
[Paper 리뷰] E2-TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
feVeRin 2025. 6. 25. 17:06반응형
E2-TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
- High speaker similarity, intelligibility를 가지는 zero-shot Text-to-Speech model이 필요함
- E2-TTS
- Text input을 filler token을 가지는 character sequence로 convert 하여 사용
- Flow-Matching-based mel-spectrogram generator를 audio infilling task를 기반으로 training 하고 duration model과 같은 additional component에 대한 의존성을 제거
- 논문 (SLT 2024) : Paper Link
1. Introduction
- VALL-E, SpeechX, VALL-T와 같은 zero-shot Text-to-Speech (TTS)는 short audio prompt로부터 any speaker의 natural speech를 생성하는 것을 목표로 함
- Neural codec language-model-based zero-shot TTS의 경우 우수한 성능에 비해 autoregressive (AR) architecture로 인해 다음의 단점을 가짐:
- Codec token을 sequentially sampling 해야 하므로 inference latency가 증가함
- Text, audio token 모두에 대한 best tokenizer가 필요함
- Long audio codec sequence를 stably handle 할 수 있어야 함
- 한편으로 nont-autoregressive (NAR) zero-shot TTS의 경우 parallel processing을 통해 빠른 추론이 가능함
- 대표적으로 NaturalSpeech2, NaturalSpeech3는 diffusion model을 기반으로 audio codec의 latent vector를 estimate 하는 방식을 활용함
- VoiceBox, Matcha-TTS의 경우 flow-matching model을 활용함 - 특히 대부분의 NAR model은 input text, audio 간의 alignment를 위해 Monotonic Alignment Search (MAS), additional duration model 등을 활용함
- BUT, high-quality zero-shot TTS에서 해당 technique은 naturalness를 저해할 수 있음 - 추가적으로 text tokenizer는 input을 constrain 하고 grapheme-to-phoneme converter에 의존하게 함
- 대표적으로 NaturalSpeech2, NaturalSpeech3는 diffusion model을 기반으로 audio codec의 latent vector를 estimate 하는 방식을 활용함
- Neural codec language-model-based zero-shot TTS의 경우 우수한 성능에 비해 autoregressive (AR) architecture로 인해 다음의 단점을 가짐:
-> 그래서 simple architecture로 구성된 zero-shot TTS model인 E2-TTS를 제안
- E2-TTS
- Text input을 filler token을 가지는 character sequence로 convert 하여 input character sequence와 output mel-filterbank sequence를 match
- U-Net style skip connection을 가지는 vanilla Transformer로 구성된 Flow-Matching-based mel-spectrogram generator를 speech-infilling task로 training
< Overall of E2-TTS >
- Flow-Matching과 speech infilling을 활용한 simple zero-shot TTS model
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
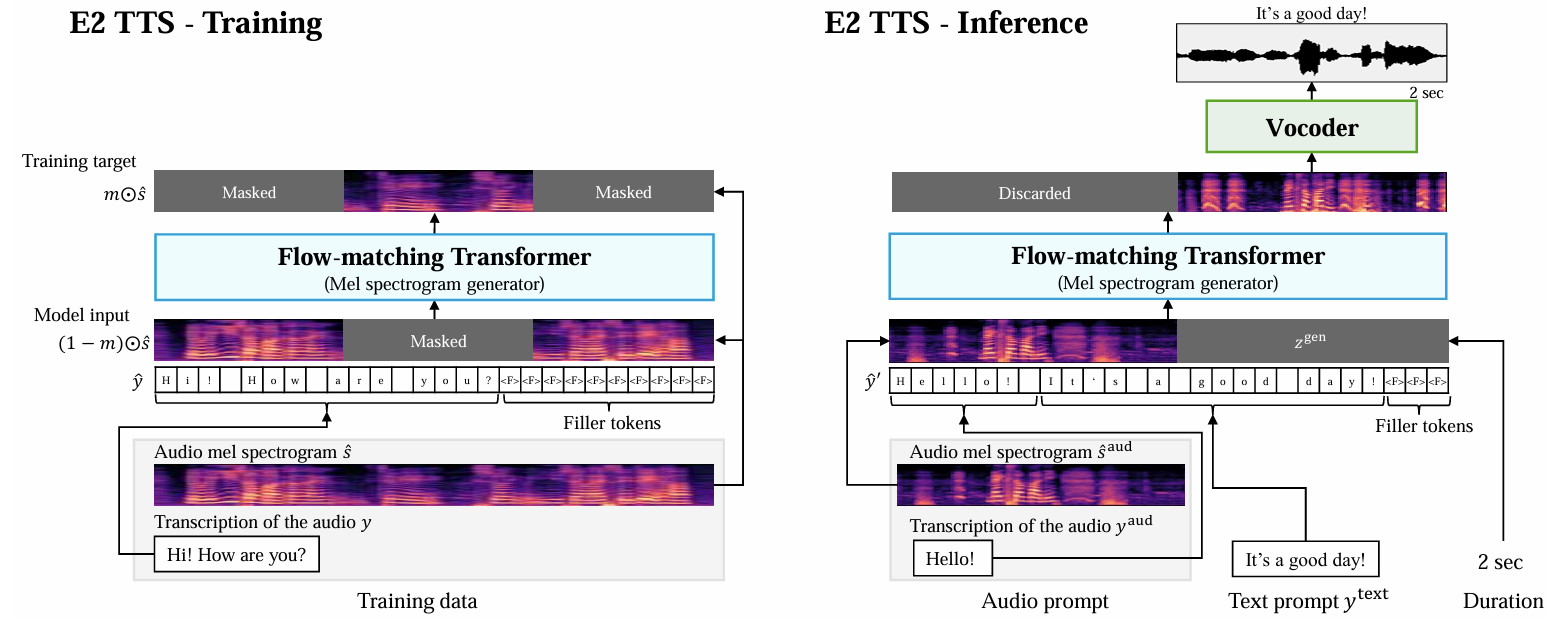
- Training
- Transcription의 $i$-th character $c_{i}$에 대해, training audio sample $s$와 해당 transcription $y=(c_{1},c_{2},...,c_{M})$이 주어진다고 하자
- 먼저 논문은 mel-filterbank feature $\hat{s}\in\mathbb{R}^{D\times T}$를 추출함
- $D$ : feature dimension, $T$ : sequence length - 이후 special filler token $\langle F\rangle$을 append 하여 $y$의 length $T$에 match 한 extended character sequence $\hat{y}$를 생성함:
(Eq. 1) $ \hat{y}=(c_{1},c_{2},...,c_{M},\underset{(T-M)\,\,\text{times}}{\underbrace{\langle F\rangle, ..., \langle F\rangle}})$ - Spectrogram generator는 U-Net style skip connection을 가지는 vanilla Transformer로 구성되고, speech infilling task를 통해 training 됨
- 이때 model은 distribution $P(m\odot \hat{s}|(1-m)\odot \hat{s},\hat{y})$을 학습하도록 training 됨
- $m\in\{0,1\}^{D\times T}$ : binary temporal mask, $\odot$ : Hadamard product - E2-TTS는 conditional Flow-Matching을 사용하여 해당 distribution을 학습함
- 이때 model은 distribution $P(m\odot \hat{s}|(1-m)\odot \hat{s},\hat{y})$을 학습하도록 training 됨
- 먼저 논문은 mel-filterbank feature $\hat{s}\in\mathbb{R}^{D\times T}$를 추출함
- Inference
- 추론 시에는 text prompt $y^{text}=(c''_{1},c''_{2},...,c''_{M^{text}})$와 함께 audio prompt $s^{aud}$와 해당 transcription $y^{aud}=(c'_{1},c'_{2},...,c'_{M^{aud}})$가 speaker characteristic을 mimic 하기 위해 주어짐
- Target duration의 경우 frame length $T^{gen}$으로 internally represent 됨
- 먼저 $s^{aud}$에서 mel-filterbank feature $\hat{s}^{aud}\in\mathbb{R}^{D\times T^{aud}}$를 추출함
- 이후 $y^{aud},y^{text}$, repeated $\langle F\rangle$을 concatenate 하여 extended character sequence $\hat{y}'$을 생성함:
(Eq. 2) $\hat{y}'=(c'_{1},c'_{2},...,c'_{M^{aud}},c''_{1},c''_{2},...,c''_{M^{text}}, \underset{\mathcal{T}\,\, \text{times}}{\underbrace{\langle F\rangle,...,\langle F\rangle}})$
- $\mathcal{T}=T^{aud}+T^{gen}-M^{aud}-M^{text}$ : $\hat{y}'$의 length가 $T^{aud}+T^{gen}$이 되도록 보장함 - Mel-spectrogram generator는 $P(\tilde{s}[\hat{s}^{aud};z^{gen}],\hat{y}')$의 learned distribution을 기반으로 mel-filterbank feature $\tilde{s}$를 생성함
- $z^{gen}$ : $D\times T^{gen}$ shape의 all-zero matrix, $[;]$ : $T^{*}$ dimension에 대한 concatenation operation - 최종적으로 $\tilde{s}$의 generated part는 vocoder를 통해 speech signal로 convert 됨
- 이후 $y^{aud},y^{text}$, repeated $\langle F\rangle$을 concatenate 하여 extended character sequence $\hat{y}'$을 생성함:
- Flow-Matching-based Mel-Spectrogram Generator
- E2-TTS는 simple initial distribution $p_{0}$를 complex target distribution $p_{1}$으로 transform 하는 Conditional Flow-Matching을 활용함
- Transformation은 $t\in[0,1]$에 대해 time-dependent vector field $v_{t}(x;\theta)$를 estimate 하는 $\theta$로 parameterize 된 neural network를 사용하여 수행됨
- 해당 vector field로부터 $p_{0}$를 $p_{1}$으로 transition 하는 flow $\phi_{t}$를 derive 할 수 있음
- Neural network training은 Conditional Flow-Matching objective를 사용하여 수행됨:
(Eq. 3) $\mathcal{L}^{CFM}(\theta)=\mathbb{E}_{t,q(x_{1}),p_{t}(x|x_{1})} \left|\left| u_{t}(x|x_{1})-v_{t}(x;\theta)\right|\right|^{2}$
- $p_{t}$ : time $t$에서의 probability path, $u_{t}$ : $p_{t}$에 대한 designated vector field
- $x_{1}$ : training data에 대한 random variable, $q$ : training data distribution
- Training phase에서는 optimal transport path $p_{t}(x|x_{1})=\mathcal{N}(x|tx_{1},(1-(1-\sigma_{\min})t)^{2}I ), u_{t}(x|x_{1})=\frac{(x_{1}-(1-\sigma_{\min})x )}{(1-(1-\sigma_{\min})t)}$를 사용하여 training data로부터 probability path, vector field를 construct 함
- 추론 시에는 initial distribution $p_{0}$에서 start 하여 log mel-filterbank feature를 생성하기 위해 Ordinary Differential Equation (ODE) solver를 사용함 - 논문은 VoiceBox의 audio model과 동일한 architecture를 사용하는 대신, frame-wise phoneme sequence를 $\hat{y}$로 replace 함
- 특히 backbone에는 U-Net style skip connection을 사용하는 Transformer를 적용함 - Mel-spectrogram generator input은 $(1-m)\odot \hat{s},\hat{y}$ flow step $t$, noisy speech $s_{t}$로 구성됨
- $\hat{y}$는 character embedding sequence $\tilde{y}\in\mathbb{R}^{E\times T}$로 convert 되고, $(1-m)\odot \hat{s},s_{t},\tilde{y}$는 stack 되어 $(2\cdot D+E)\times T$ shape의 tensor를 구성함
- 이후 $D\times T$ shape의 tensor를 output 하는 linear layer가 적용됨
- 최종적으로 $t$의 embedding representation $\hat{t}\in\mathbb{R}^{D}$를 append 하여 $\mathbb{R}^{D\times (T+1)}$ shape의 Transformer input tensor를 구성함
- Transformer는 $\mathcal{L}^{CFM}$을 기반으로 vector field $v_{t}$를 output 하도록 training 됨
- Transformation은 $t\in[0,1]$에 대해 time-dependent vector field $v_{t}(x;\theta)$를 estimate 하는 $\theta$로 parameterize 된 neural network를 사용하여 수행됨
- Relationship to VoiceBox
- VoiceBox 관점에서 E2-TTS는 conditioning에 사용되는 frame-wise phoneme sequence를 filler token이 포함된 character sequence로 replace 한 것과 같음
- 이를 통해 E2-TTS는 grapheme-to-phoneme converter, phoneme aligner, phoneme duration model에 대한 의존성을 eliminate 하고 model을 simplify 할 수 있음
- 한편으로 E2-TTS의 mel-spectrogram generator는 VoiceBox의 audio model과 grapheme-to-phoneme converter, phoneme duration model에 대한 joint model로 볼 수 있음
- 해당 joint modeling을 통해 E2-TTS는 speaker similarity를 maintain 하면서 naturalness를 개선함

- Extension of E2-TTS
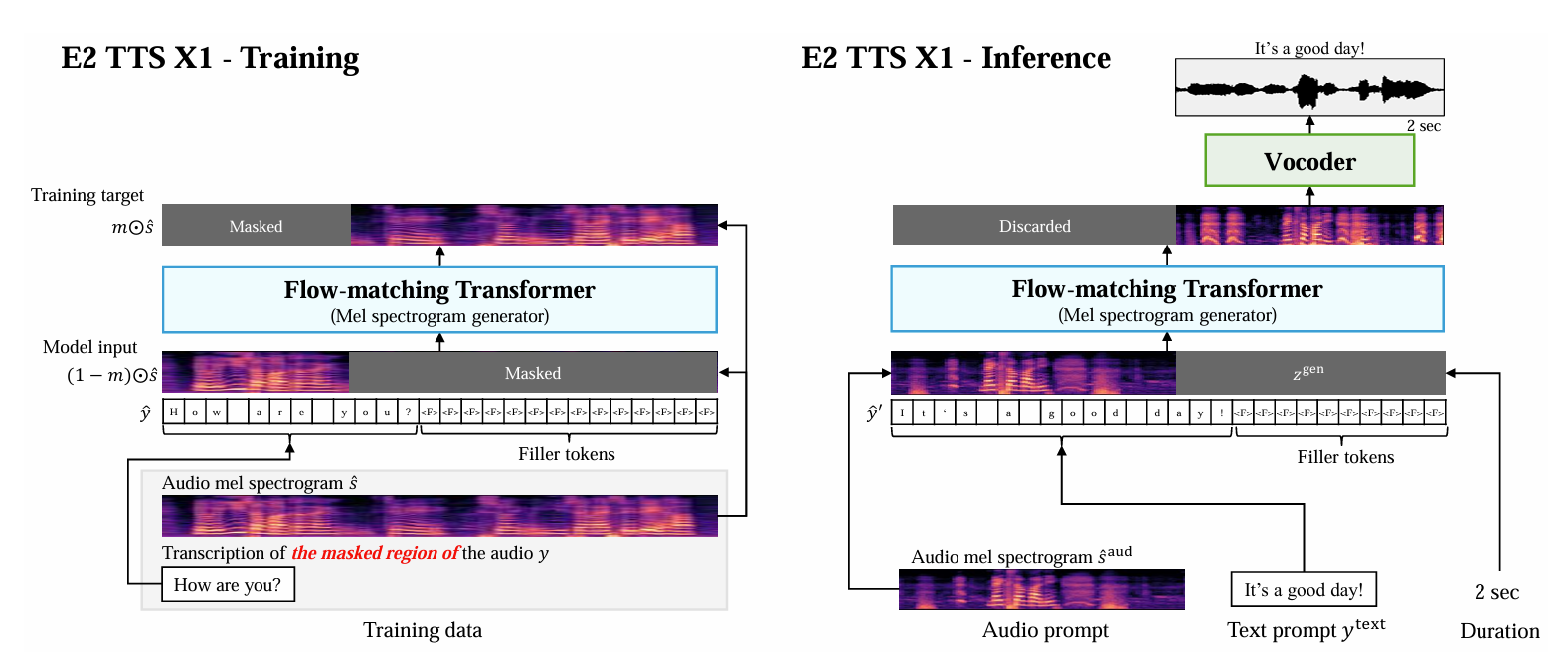
- Extension1: Eliminating the Need for Transcription of Audio Prompts in Inference
- 특정 환경에서는 audio prompt를 얻는 것이 어려울 수 있으므로, audio prompt에 대한 transcription requirement를 eliminate 하기 위해 아래 그림과 같은 E2-TTS-X1을 구성함
- 이때 audio의 masked region에 대한 transcription에 access 할 수 있다고 가정하고, 이를 $y$로 사용함
- 추론 시 extended character sequence $\hat{y}'$는 $y^{aud}$ 없이 생성됨:
(Eq. 4) $\hat{y}'=(c''_{1},c''_{2},...,c''_{M^{text}},\underset{\mathcal{T}\,\, \text{times}}{\underbrace{\langle F\rangle, ...,\langle F\rangle}})$
- 한편으로 masked region의 transcription은 masked region에 Automatic Speech Recognition (ASR)을 적용하여 straightforward 하게 얻을 수 있음
- BUT, 해당 방식은 expensive 하므로 논문은 Montreal Forced Aligner를 사용하여 training sample 내의 word에 대한 start/end time을 결정함
- 특정 환경에서는 audio prompt를 얻는 것이 어려울 수 있으므로, audio prompt에 대한 transcription requirement를 eliminate 하기 위해 아래 그림과 같은 E2-TTS-X1을 구성함
- Extension2: Enabling Explicit Indication of Pronunciation for Parts of Words in a Sentence
- Specific word의 prounciation을 반영하기 위해 E2-TTS-X2의 extension을 고려함
- 이를 위해 E2-TTS-X2는 위 그림과 같이 $y$의 word를 parentheses를 포함한 phoneme sequence로 substitute 하여 training 됨
- 특히 논문은 $y$의 word를 $15\%$의 probability로 CMU pronouncing dictionary로 replace 함 - 추론 시에는 target word를 parentheses를 포함한 phoneme sequence로 simply replace 함
- 이를 위해 E2-TTS-X2는 위 그림과 같이 $y$의 word를 parentheses를 포함한 phoneme sequence로 substitute 하여 training 됨
- 여기서 $y$는 여전히 simple character sequence에 해당하고, character의 word/phoneme representation은 parantheses 여부에 따라 달라짐
- Specific word의 prounciation을 반영하기 위해 E2-TTS-X2의 extension을 고려함
3. Experiments
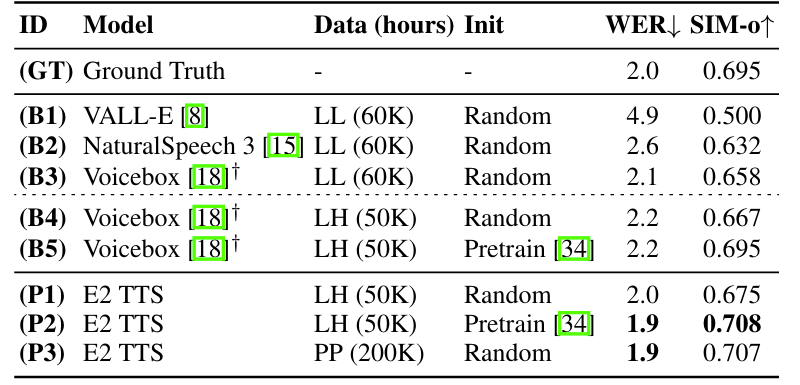
- Settings
- Dataset : LibriHeavy
- Comparisons : VALL-E, NaturalSpeech3, VoiceBox
- Results
- 전체적으로 E2-TTS의 성능이 가장 우수함
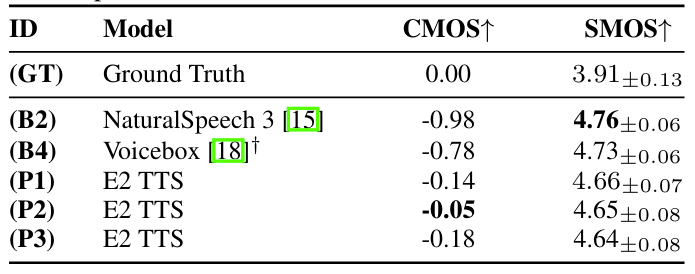
- E2-TTS는 MOS 측면에서도 뛰어난 성능을 보임
- Evaluation of the Extension1
- Audio prompt를 사용하지 않는 E2-TTS-X1은 E2-TTS baseline과 비슷한 성능을 가짐

- Evaluation of the Extension2
- Extension2의 경우 $50\%$의 word를 phoneme으로 replace 하여도 성능 저하가 크게 나타나지 않음

- Training Progress
- E2-TTS는 training이 진행됨에 따라 더 나은 WER을 달성함
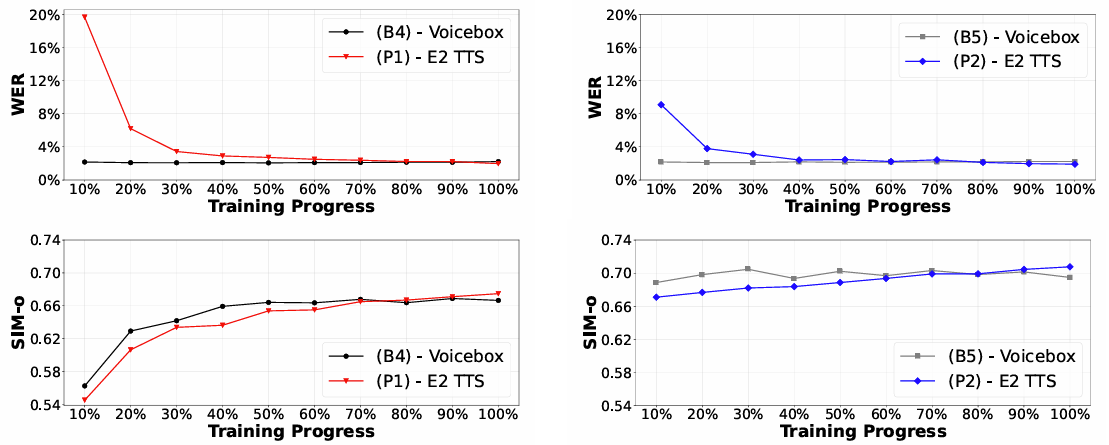
- Impact of Audio Prompt Length
- Audio prompt length가 길어질수록 SIM-o가 개선됨

- Impact of Changing the Speech Rate
- E2-TTS는 $\text{sr}=0.7, \text{sr}=1.3$에서도 robust 한 성능을 보임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글