

티스토리 뷰
Paper/Language Model
[Paper 리뷰] MELLE: Autoregressive Speech Synthesis without Vector Quantization
feVeRin 2025. 7. 2. 17:05반응형
MELLE: Autoregressive Speech Synthesis without Vector Quantization
- Text-to-Speech를 위해 continuous-valued token based language modeling을 활용할 수 있음
- MELLE
- Spectrogram Flux loss를 사용하여 continuous-valued token distribution을 modeling
- Variational inference를 incorporate 하여 diversity, robustness를 향상
- 논문 (ACL 2025) : Paper Link
1. Introduction
- Next-token prediction은 previous token을 condition으로 하여 next discrete token을 predict 함
- 특히 VALL-E와 같은 language model은 zero-shot Text-to-Speech (TTS)를 위해 EnCodec, SoundStream 등의 neural codec model을 활용하여 vector quantized code를 predict 함
- BUT, 해당 codec language model은 다음의 한계점이 있음:
- Quantized codec code는 bitrate가 sufficiently high 하지 않으면 lower fidelity를 보임
- Neural codec language model은 discrete token을 select 하는 random sampling strategy로 인해 robustness의 문제가 있음
- Neural codec language model은 autoregressive (AR) model을 통해 coarse primary audio token을 생성한 다음, non-autoregressive (NAR) model로 나머지 multi-codebook code를 iteratively predict 함
- 결과적으로 해당 multi-step process는 inference efficiency를 저해함
- 한편으로 discrete-token based codec language model의 문제점을 해결하기 위해 continuous representation을 고려할 수 있음
- BUT, continuous representation을 위한 objective, continuous space에서의 sampling mechanism이 필요함
-> 그래서 continuous representation을 활용한 zero-shot TTS language model인 MELLE를 제안
- MELLE
- Cross-Entropy loss를 regression loss로 substitute 하고, prediction variation을 promote 할 수 있는 Spectrogram Flux Loss를 도입
- Variational inference에서 derive 된 latent sampling module을 통해 generated audio의 diversity를 향상
- 추가적으로 reduction factor를 adjust 하여 long-sequence robustness와 inference speed를 개선
< Overall of MELLE >
- Previous token을 기반으로 continuous mel-spectrogram을 predict 하는 single-pass language model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Problem Formulation
- 논문은 TTS를 autoregressive mel-spectrogram language modeling task로 취급함
- Audio sample의 Byte-Pair-Encoded (BPE) text content $\mathbf{x}=[x_{0},x_{1},...,x_{L-1}]$이 주어지면, MELLE는 audio에서 추출한 mel-spectrogram $\mathbf{y}=[\mathbf{y}_{0},\mathbf{y}_{1},...,\mathbf{y}_{T-1}]$을 predict 함
- 즉, 각 autoregressive step에서 MELLE는 text prompt $\mathbf{x}$와 previous mel-spectrogram $\mathbf{y}_{<t}$에 condition 된 next mel-spectrogram fram $\mathbf{y}_{t}$를 predict 함
- 이는 다음 distribution을 maximize 하는 것과 equivalent 함:
(Eq. 1) $p(\mathbf{y}|\mathbf{x};\theta)=\prod_{t=0}^{T-1}p(\mathbf{y}_{t}|\mathbf{y}_{<t};\mathbf{x};\theta)$
- $\mathbf{y}_{<t}$ : $[\mathbf{y}_{0},\mathbf{y}_{1},...,\mathbf{y}_{t-1}]$, $\theta$ : MELLE paramete
- 추가적으로 각 decoding step에서 predict 되는 mel-spectrogram frame 수를 control 하기 위해 논문은 reduction factor $r$를 도입하여 computational efficiency와 generation quality를 balance 함
- 그러면 original mel-spectrogram sequence $\mathbf{y}$는 factor $r$에 따라 $\mathbf{y}^{r}=[\mathbf{y}_{0:r},\mathbf{y}_{r:2r},...,\mathbf{y}_{(T-r):T}]$로 partition 되고, 이때 likelihood function은:
(Eq. 2) $p(\mathbf{y}|\mathbf{x};\theta)=\prod_{t=0}^{T/r-1}p(\mathbf{y}_{t\cdot r:(t+1)\cdot r}| \mathbf{y}_{<t\cdot r},\mathbf{x};\theta)$ - 추론 시 MELLE는 prompt를 통해 zero-shot TTS를 수행함
- Text context $\mathbf{x}$와 speech prompt의 mel-spectrogram $\tilde{\mathbf{y}}$가 주어지면, prompt의 speaker characteristic을 preserve 하면서 $\mathbf{x}$에 해당하는 target mel-spectrogram $\mathbf{y}$를 generate 함
- 해당 process는 각 time step에서 maximum likelihood probability $ \arg\max_{\mathbf{y}}p(\mathbf{y}_{t\cdot r:(t+1)\cdot r}|[\tilde{\mathbf{x}};\mathbf{x};\tilde{\mathbf{y}};\mathbf{y}_{<t\cdot r}];\theta)$를 활용하고 $r=1$인 경우 standard mode에 해당함
- Audio sample의 Byte-Pair-Encoded (BPE) text content $\mathbf{x}=[x_{0},x_{1},...,x_{L-1}]$이 주어지면, MELLE는 audio에서 추출한 mel-spectrogram $\mathbf{y}=[\mathbf{y}_{0},\mathbf{y}_{1},...,\mathbf{y}_{T-1}]$을 predict 함
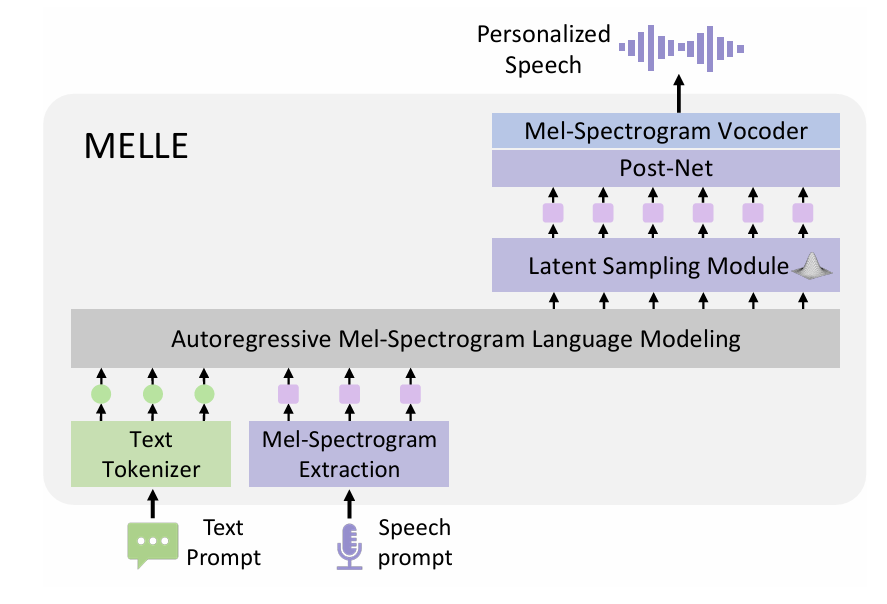
- MELLE Architecture
- Multi-layer codec code를 itertatively predict 하는 기존의 neural codec language model과는 달리 MELLE는 mel-spectrogram의 completness로 인해 additional NAR model이 필요하지 않음
- 이때 MELLE는 다음의 component로 구성됨:
- Text를 sub-word token으로 convert 하고 speech에서 mel-spectrogram을 추출하는 Pre-Net
- Language model로써 사용되는 Transformer Decoder
- Prediction distribution에서 latent embedding을 sampling 한 다음, spectrogram space로 project 하는 Latent Sampling Module
- Generation end를 결정하는 Stop Prediction Layer
- Spectrogram refinement를 위한 Convolutional Post-Net
- Generated mel-spectrogram에서 speech를 recover 하는 Vocoder
- 추가적으로 reduction factor를 adjust 하여 one step에서 multiple mel-spectrogram frame을 생성할 수 있음
- 이때 MELLE는 다음의 component로 구성됨:
- Autoregressive Language Model
- 논문은 language model로써 Transformer decoder를 활용하여 textual, acoustic prompt에 기반해 acoustic continuous token을 autoregressively generate 함
- 먼저 $\text{<EOS>}$ token이 append 된 input text token $\mathbf{x}$는 text embedding layer를 통해 embedding으로 convert 됨
- 이와 함께 논문은 mel-spectrogram $\mathbf{y}$를 language model dimension으로 project 하기 위해 multi-layer perceptron에 해당하는 Pre-Net을 도입함
- 이후 multi-head attention, feed-forward layer로 구성된 LM은 text/acoustic embedding의 concatenation을 input으로 하여 semantic, acoustic information 간의 dependency를 modeling 함
- 그러면 time step $t$의 LM output $\mathbf{e}_{t}$는 next-frame output을 생성하는 데 사용됨
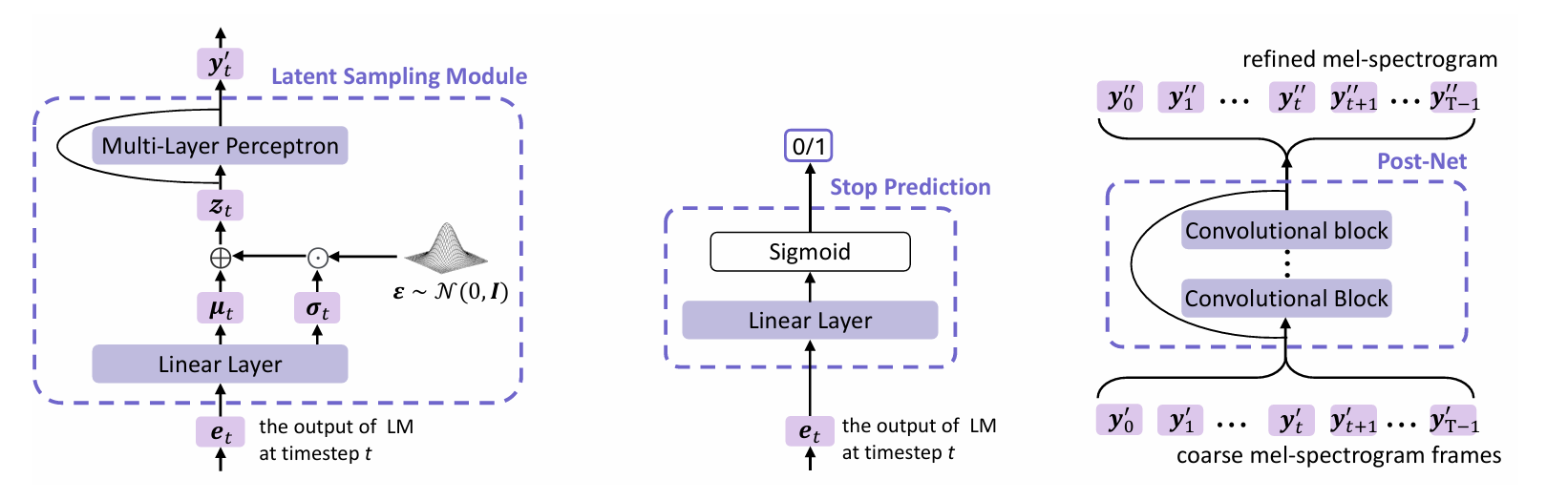
- Latent Sampling Module
- Sampling strategy는 output diversity와 generalization ability를 향상하기 위해 사용됨
- 특히 논문에서는 Variational AutoEncoder (VAE)를 기반으로 Latent Sampling Module을 integrate 하여 expressive diversity와 robustness를 향상함
- LM output $\mathbf{e}_{t}$에 대해 Latent Sampling Module은 distribution을 predict 한 다음, 해당 distribution으로부터 latent embedding $\mathbf{z}_{t}$를 sampling 함
- $\mathbf{z}_{t}$가 각 dimension이 independent 한 multivariate Gaussian distribution을 따른다고 가정하자
- 그러면 linear layer $\mathbf{W}[\cdot]+\mathbf{b}$는 $\mathbf{e}_{t}$를 기반으로 Gaussian distribution의 mean vector $\mu_{t}$와 log-magnitude variance vector $\sigma_{t}^{2}$을 predict 함
- Reparameterization trick을 사용하면, $\mathbf{z}_{t}$는 다음과 같이 sampling 됨:
(Eq. 3) $\mathbf{z}_{t}=\mu_{t}+\sigma_{t}\odot \epsilon$
- $\epsilon\sim\mathcal{N}(0,I), \left[\mu_{t},\log \sigma_{t}^{2}\right] =\mathbf{We}_{t}+\mathbf{b}$ - Probability density function은:
(Eq. 4) $ p_{\theta}(\mathbf{z}_{t}|\mathbf{e}_{t})=\mathcal{N}\left(\mathbf{z}_{t}|\mu_{t},\text{diag}( \sigma_{t}^{2})\right)$
- 이후 latent variable $\mathbf{z}_{t}$는 residual connection을 가지는 multi-layer perceptron을 통과하여 mel-spectrogram space $\mathbf{y}'_{t}$로 mapping 됨
- $t=0,1,...,T-1$
- Sampling strategy는 output diversity와 generalization ability를 향상하기 위해 사용됨
- Stop Prediction Layer and Post-Net
- 논문은 linear layer를 binary classifier로 채택하여 $\mathbf{e}_{t}$를 기반으로 generation conclude를 결정함
- 이때 $\mathbf{y}'=\{\mathbf{y}'_{0},\mathbf{y}'_{1},...,\mathbf{y}'_{T-1}\}$에 add 되는 residual을 생성하기 위해 multiple convolutional block으로 구성된 Post-Net을 도입함
- 이를 통해 refined mel-spectrogram $\mathbf{y}''=\{\mathbf{y}''_{0},\mathbf{y}''_{1},...,\mathbf{y}''_{T-1}\}$을 얻을 수 있음 - Training 시에는 teacher-forcing을 사용하여 training 되고, 추론 시 Post-Net은 AR generation이 conclude 된 다음 $\mathbf{y}'$를 process 함
- Training Objective
- MELLE의 single end-to-end autoregressive model은 training 시 다음 4가지 loss function을 사용하여 teacher-forcing manner로 optimize 됨:
(Eq. 5) $\mathcal{L}=\mathcal{L}_{reg}+\lambda \mathcal{L}_{KL}+\beta\mathcal{L}_{flux}+\gamma\mathcal{L}_{stop}$ - Regression Loss
- Regression loss는 mel-spectrogram frame의 accurate prediction을 보장함
- Regression loss $\mathcal{L}_{reg}$는 intermediate prediction $\mathbf{y}'$과 final prediction $\mathbf{y}''$ 간의 $L1, L2$ combination으로 주어짐:
(Eq. 6) $\mathcal{L}_{reg}(\mathbf{y},\mathbf{y}',\mathbf{y}'')=||\mathbf{y}-\mathbf{y}'||_{1}+ ||\mathbf{y}-\mathbf{y}'||_{2}^{2}+||\mathbf{y}-\mathbf{y}''||_{1}+||\mathbf{y}-\mathbf{y}''||_{2}^{2}$
- $\mathbf{y}$ : ground-truth spectrogram target
- KL Divergence Loss
- 논문은 variational inference에 기반한 Kullback-Leibler (KL) divergence loss를 통해 diversity와 stability를 향상함
- KL divergence는 predicted latent distribution $p_{\theta}(\mathbf{z}_{t}|\mathbf{e}_{t})$와 simpler distribution $p(\mathbf{z}_{t})$ 간의 difference를 measure 함
- 이때 논문은 $p(\mathbf{z}_{t})$를 standard Normal distribution으로 select하는 대신, $\mathbf{z}_{t}$가 mel-spectrogram과 동일한 dimensionality를 가지게하여 $p(\mathbf{z}_{t})$를 $\mathcal{N}(\mathbf{y}_{t},I)$로 정의함
- 여기서 (Eq. 4)를 combine 하면:
(Eq. 7) $\mathcal{L}_{KL}(\mathbf{y},\mathbf{z})=\sum_{t=0}^{T-1}D_{KL}\left( p_{\theta}(\mathbf{z}_{t}|\mathbf{e}_{t})|| p(\mathbf{z}_{t})\right) = \frac{1}{2}\sum_{t=0}^{T-1}\left(|| \sigma_{t}||^{2}_{2}+|| \mu_{t}-\mathbf{y}_{t}||_{2}^{2}-d-\sum_{i=1}^{d}\log \sigma_{t}^{2}[i]\right)$
- $d$ : feature space의 dimensionality
- 이때 논문은 $p(\mathbf{z}_{t})$를 standard Normal distribution으로 select하는 대신, $\mathbf{z}_{t}$가 mel-spectrogram과 동일한 dimensionality를 가지게하여 $p(\mathbf{z}_{t})$를 $\mathcal{N}(\mathbf{y}_{t},I)$로 정의함
- 해당 KL divergence loss를 통해 MELLE는 synthesis quality와 latent space regularization을 balance 하여 generated mel-spectrogram의 diversity와 robustness를 향상할 수 있음
- Spectrogram Flux Loss
- Generated frame에서 dynamic variation을 encourage 하기 위해, consecutive frame 간의 low variability를 penalize 하는 Spectrogram Flux loss를 도입함:
(Eq. 8) $\mathcal{L}_{flux}(\mathbf{y},\mu)=-\sum_{t=1}^{T-1}||\mu_{t}-\mathbf{y}_{t-1}||_{1}$
- $L1$ norm은 predicted Gaussian mean vector $\mu_{t}$와 previous ground-truth frame $\mathbf{y}_{t-1}$ 간의 difference를 measure 하는 데 사용됨 - Difference의 negative value를 summing 함으로써 loss는 generated frame의 variation을 reward 하고 overly static frame을 discourage 하여 repetition이나 prolonged silence를 방지함
- 특히 flat prediction을 penalize 하여 diverse, dynamic spectrogram을 생성하도록 incentivize 함
- Generated frame에서 dynamic variation을 encourage 하기 위해, consecutive frame 간의 low variability를 penalize 하는 Spectrogram Flux loss를 도입함:
- Stop Prediction Loss
- 논문은 LM output $\mathbf{e}_{t}$를 logit으로 project 하기 위해 linear layer를 사용하고 stop prediction을 위해 BCE loss $\mathcal{L}_{stop}$을 calculate 함
- 한편으로 각 utterance는 stop을 나타내는 하나의 positive frame 만을 가지므로, positive/negative frame은 상당히 imbalance 함
- 따라서 논문은 BCE loss에서 positive frame에 large weight $100$을 assign 함
- Inference: In-Context Learning
- 추론 시에는 mel-spectrogram을 autoregressively predict 하여 zero-shot TTS를 수행함
- Text content $\mathbf{x}$, text transcription $\tilde{\mathbf{x}}$와 mel-spectrogram $\tilde{\mathbf{y}}$를 가지는 speech prompt가 주어지면, MELLE는 각 time step $t$에서 latent embedding $\mathbf{z}_{t}$로부터 next-frame $\mathbf{y}'_{t}$를 생성함
- 이때 $\mathbf{z}_{t}$는 $\tilde{\mathbf{x}},\mathbf{x}, \tilde{\mathbf{y}},\mathbf{y}_{<t}$의 concatenation으로 condition 된 distribution에서 sampling 됨
- AR generation process 이후 coarse mel-spectrogram $\mathbf{y}'$은 Post-Net으로 전달되어 refined spectrogram $\mathbf{y}''$를 얻고, off-the-shelf vocoder를 사용하여 speech로 변환됨
- Reduction factor $r$이 설정되면, input/predicted mel-spectrogram은 $r$에 의해 grouping 됨
- VALL-E와 같은 codec language model은 multi-layer code에 대한 multi-stage iterative prediction이 필요함
- 이와 달리 MELLE는 single forward pass에서 speech synthesis를 수행하고 각 input의 learned distribution에서 automatically sampling 되므로 adaptive, consistent sampling을 보장함 - 결과적으로 LM의 strong in-context learning을 통해 MELLE는 fine-tuning 없이도 unseen speaker에 대한 high-fidelity speech를 생성할 수 있음
- Text content $\mathbf{x}$, text transcription $\tilde{\mathbf{x}}$와 mel-spectrogram $\tilde{\mathbf{y}}$를 가지는 speech prompt가 주어지면, MELLE는 각 time step $t$에서 latent embedding $\mathbf{z}_{t}$로부터 next-frame $\mathbf{y}'_{t}$를 생성함
3. Experiments
- Settings
- Results
- 전체적으로 MELLE가 가장 우수한 성능을 보임
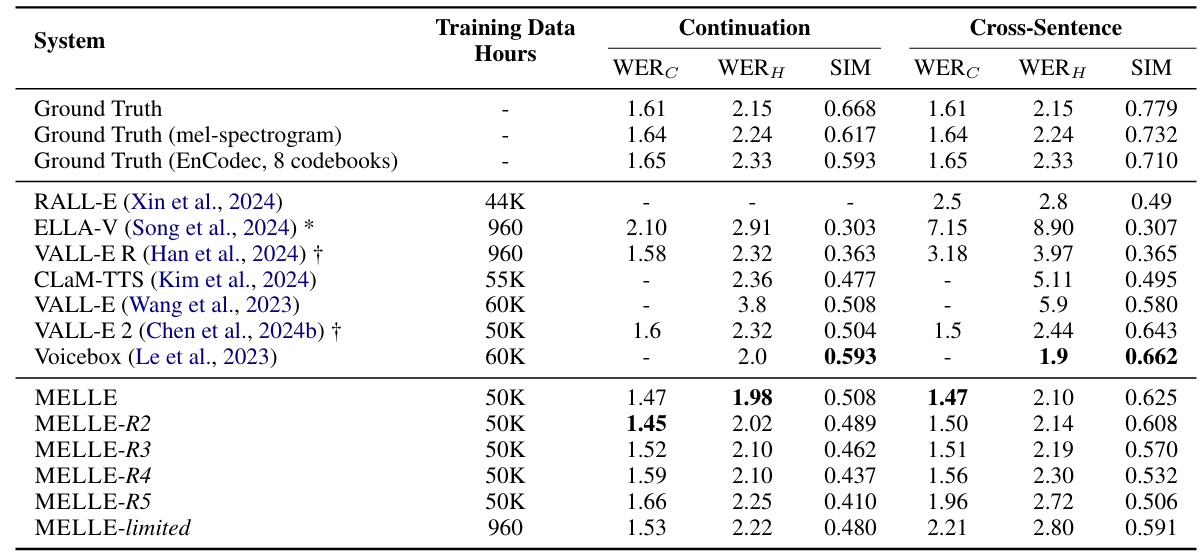
- MELLE는 다양한 reduction factor $r$에 대해서 robust 한 성능을 보임

- MOS 측면에서도 MELLE가 가장 뛰어남

- Ablation Study
- Latent Sampling (LS), Spectrogram Flux Loss (SFL)를 모두 사용하는 경우 최고의 성능을 달성할 수 있음

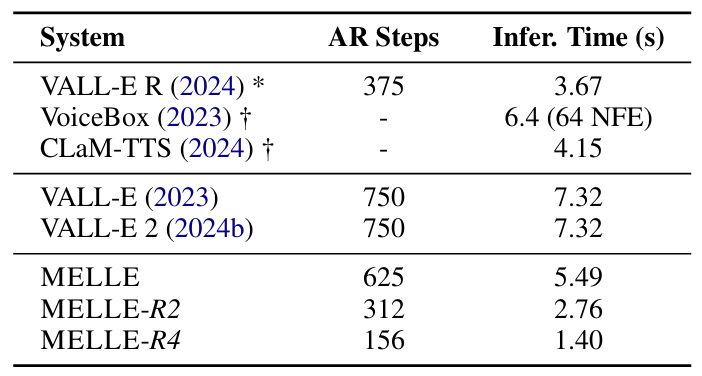
- Efficiency Comparison
- MELLE는 reduction factor $r$에 따라 latency가 감소함
반응형
'Paper > Language Model' 카테고리의 다른 글
댓글