

티스토리 뷰
Paper/Language Model
[Paper 리뷰] CosyVoice2: Scalable Streaming Speech Synthesis with Large Language Models
feVeRin 2025. 7. 26. 11:38반응형
CosyVoice2: Scalable Streaming Speech Synthesis with Large Language Models
- 기존 CosyVoice를 추가적으로 개선할 수 있음
- CosyVoice2
- Speech token의 codebook utilization을 향상하는 finite-scalar quantization을 도입
- Pre-trained large language model을 backbone으로 사용할 수 있도록 architecture를 streamline 하고 chunk-aware causal flow matching model을 통해 streaming/non-streaming synthesis를 지원
- 논문 (Alibaba 2024) : Paper Link
1. Introduction
- Zero-shot Text-to-Speech (TTS)는 reference speech의 timbre, prosody 등을 mimic 하여 speech synthesis를 수행함
- 특히 최근에는 large-scale training data와 in-context learning (ICL) capability를 활용한 Large Language Model (LLM)이 zero-shot TTS에서 우수한 성능을 보임
- 이를 위한 zero-shot TTS model은 크게 3가지로 분류할 수 있음:
- Codec Language Model : VALL-E, SPEAR-TTS와 같이 EnCodec, SoundStream 등의 speech codec을 활용하여 discrete speech representation을 추출한 다음 LM으로 speech token을 predict 하는 방식
- Feature Diffusion Model : E2-TTS, F5-TTS와 같이 denoising diffusion model을 활용하는 방식
- Hybrid Model : CosyVoice와 같이 text-to-codec language model과 codec-to-feature diffusion model을 combine 하는 방식
- BUT, 대부분의 LM은 non-streaming mode로 동작하므로 voice chat과 같은 application에서 활용하기 어려움
-> 그래서 CosyVoice를 기반으로 streaming, non-streaming mode를 확장한 CosyVoice2를 제안
- CosyVoice2
- Streaming, non-streaming synthesis를 single framework로 unify하고 unified text-speech language model과 chunk-aware causal flow matching model을 도입
- Text encoder, speaker embedding을 remove하여 LM architecture를 simplify 하고 pre-trained textual LLM을 backbone으로 사용하여 context understanding을 향상
- Speech tokenizer의 Vector Quantization (VQ)를 Finite Scalar Quantization (FSQ)로 replace 하여 codebook utilization을 개선
< Overall of CosyVoice2 >
- 기존 CosyVoice를 개선한 streaming zero-shot TTS language model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- CosyVoice2는 CosyVoice를 따라 speech signal의 semantic, acoustic information을 separate 하고 각각 independently modeling 함
- 이때 speech generation process는 conditional information을 progressively incorporate 하는 gradual semantic decoding procedure로 redefine 됨
- 특히 text-speech LM은 semantic information에만 focus 하고 high-level text token을 supervised semantic speech token으로 decoding 함 - Flow matching model은 speaker embedding, reference speech의 acoustic detail을 반영하여 주어진 speaker에 대한 mel-spectrum으로 speech token을 convert 함
- 최종적으로 pre-trained vocoder는 mel-spectrum을 audio signal로 transform 함
- 이때 speech generation process는 conditional information을 progressively incorporate 하는 gradual semantic decoding procedure로 redefine 됨

- Text Tokenizer
- CosyVoice2는 raw text를 input으로 directly use 함
- 이때 text는 BPE-based text tokenizer로 tokenize 되어 grapheme-to-phoneme (g2p) transformation에 대한 frontend model의 필요성을 eliminate 함
- 이를 통해 data pre-processing workflow를 simplify 하고 model이 다양한 context에서 word pronunciation을 end-to-end manner로 학습할 수 있도록 함 - 특히 CosyVoice2는 일반적인 textual LLM의 tokenizer와 달리 one-to-many token을 mask out 함
- 이는 token pronunciation이 excessively long 하는 것을 방지하고 data sparsity로 인한 corner case를 reduce 함
- e.g.) BPE token이 하나 이상의 Chinese character를 encode 하는 경우, 해당 token을 mask 하고 각 character는 tokenization process에서 separately encode 됨
- English, Japanese, Korean의 경우 해당되지 않음
- 이때 text는 BPE-based text tokenizer로 tokenize 되어 grapheme-to-phoneme (g2p) transformation에 대한 frontend model의 필요성을 eliminate 함
- Supervised Semantic Speech Tokenizer
- 논문은 SenseVoice-Large model encoder에 Finite Scalar Quantization (FSQ) module을 insert 하여 사용함
- Training stage에서 input speech $X$는 $\text{Encoder}_{1}$을 통과하여 intermediate representation을 얻음
- $\text{Encode}_{1}$은 rotary positional embedding을 가진 6개의 Transformer block으로 구성됨 - Intermediate representation은 quantization을 위해 FSQ module에 input 되고, quantized representation은 $\text{Encoder}_{2}$와 $\text{ASR Decoder}$를 포함한 나머지 SenseVoice-Large module로 전달됨
- 이를 통해 해당 text token에 대한 posterior probability를 predict 함 - FSQ module에서 intermediate representation $H$는 $D$-dimensional low-rank space로 project 되고, 각 dimension value는 bounded round operation $\text{ROUND}$를 통해 $[-K,K]$로 quantize 됨
- 이후 quantized low-rank representation $\bar{H}$는 original dimension $\tilde{H}$로 project 됨:
(Eq. 1) $\bar{H}=\text{ROUND}(\text{Proj}_{down}(H))$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \tilde{H}=\text{Proj}_{up}(\bar{H})$ - Straight-through estimation은 FSQ module과 $\text{Encoder}_{1}$의 gradient를 approximate 하기 위해 사용됨
- Speech token $\mu_{i}$는 $(2K+1)$-ary system에서 quantized low-rank representation $\bar{h}_{i}$의 index를 calculate 하여 얻어짐:
(Eq. 2) $ \mu_{i}=\sum_{j=0}^{D-1}\bar{h}_{i,j}(2K+1)^{j}$
- 이후 quantized low-rank representation $\bar{H}$는 original dimension $\tilde{H}$로 project 됨:
- 결과적으로 FSQ module의 low-rank projector인 $\text{Encode}_{1}$은 bounded round operation과 index calculation을 통해 CosyVoice2의 speech tokenizer를 구성함
- 해당 tokenizer는 25Hz의 token rate로 동작함
- Training stage에서 input speech $X$는 $\text{Encoder}_{1}$을 통과하여 intermediate representation을 얻음
- Unified Text-Speech Language Model
- CosyVoice2는 pre-trained textual LLM인 Qwen2.5-0.5B를 text-speech LM으로 채택하고, input text를 prompt로 활용해 speech token을 autoregressively generate 함
- 이때 기존 CosyVoice와 달리 information leaking을 방지하기 위해 speaker embedding을 remove 함
- Utteance-level vector는 speaker identity와 language/paralanguage information을 포함하고 있어 text-speech LM의 prosody naturalness를 저해하기 때문
- 추가적으로 Qwen2.5-0.5B 만으로도 text, speech token align이 가능하므로, text encoder도 eliminate 함
- 해당 simplified text-speech LM을 기반으로 논문은 streaming/non-streaming synthesis를 위한 unified model을 구축함
- Streaming mode는 input text가 complete sentence로 주어지지 않고 continuous flow로 receive 되는 것을 의미 - CosyVoice2에서 streaming/non-streaming mode는 LM에 대한 sequence construction에 대한 차이와 같음:
- Non-streaming mode의 경우
- Start of sequence Ⓢ, all text token, turn of speech Ⓣ, all speech token, end of sequence Ⓔ가 sequentially concatenate 됨
- Ignore token은 cross-entropy objective를 minimize 하는 동안 해당 loss가 ignore 되는 것을 의미함 - Streaming mode의 경우, $N:M$의 pre-defined ratio로 text, speech token을 mix up 함 ($N=5, M=15$)
- 즉, every $N$ text token 다음에 $M$ speech token이 follow 함
- Streaming mode에서 next token이 text token인 경우 model은 text token이 아닌 filling token을 predict 해야 하고, 이는 next $N$ text token이 inference stage에서 concatenate 되어야 함을 의미함
- Text token이 run out 되면 turn of speech Ⓣ와 remaining speech token이 sequentially concatenate 되어 hybrid text-speech token sequence를 구성함
- Non-streaming mode의 경우
- 결과적으로 CosyVoice는 앞선 2가지 sequence를 text-speech LM에 simultaneously training 함으로써 single unified model 내에서 streaming/non-streaming generation을 지원함
- 이때 기존 CosyVoice와 달리 information leaking을 방지하기 위해 speaker embedding을 remove 함
- Real-world scenario에서 speaker fine-tuning (SFT)와 in-context learning (ICL)의 inference sequence는 다음과 같이 구성됨:
- ICL, Non-Streaming
- ICL에서 LM은 accent, prosody, emotion, style을 imitate 하기 위해 reference audio에서 prompt text와 speech token을 요구함
- Non-streaming mode의 경우, prompt와 to-synthesize text token이 whole entity로 concatenate 되고, prompt speech token은 pre-generated result로 취급되어 Ⓢ, prompt text, text, Ⓣ, prompt speech와 같이 fix 됨
- LM의 autoregressive generation은 end of sequence token Ⓔ가 detect 될 때까지 수행됨
- ICL, Streaming
- 해당 scenario에서는 to-generate text가 known이고 speech token이 streaming manner로 생성된다고 가정함
- 먼저 prompt와 to-generate text를 whole entity로 취급하고, prompt speech token과 $N:M$ ratio로 mix up 하여 Ⓢ, mixed text speech, Ⓣ, remaining speech를 얻음
- 만약 text length가 prompt speech token length보다 큰 경우, LM은 filling token을 생성함
- 이 경우 $N$ next token은 manually pad 됨 - Text token이 run out 되면 turn of speech token Ⓣ가 add 되고, Ⓔ가 detect 될 때까지 every $M$ token마다 generation result를 return 함
- SFT, Non-Streaming
- SFT scenario에서 LM은 specific speaker에 fine-tuning 되므로 prompt text와 speech가 필요하지 않음
- 따라서 initial sequence는 Ⓢ, text, Ⓣ로 구성됨
- 이후 text-speech LM은 Ⓣ까지 speech token을 autoregressively generate 함
- SFT, Streaming
- SFT streaming mode는 Ⓢ, first $N$ text의 initial sequence에서 speech generation을 시작함
- 이후 LM은 $M$ speech token을 생성하고, next $N$ text token을 manually pad 함 - 이는 모든 text token이 run out 될 때까지 repeat 되고, 이후 Ⓣ가 add 됨
- SFT streaming mode는 Ⓢ, first $N$ text의 initial sequence에서 speech generation을 시작함
- ICL, Non-Streaming

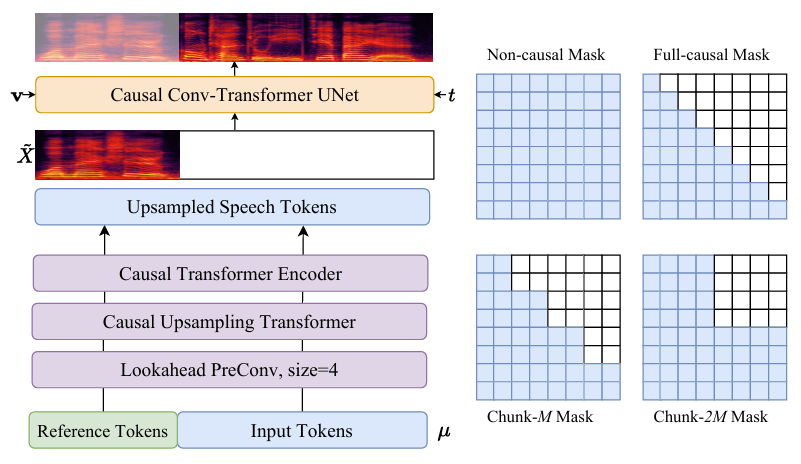
- Chunk-aware Flow Matching
- CosyVoice2는 50Hz frame rate, 24000 sampling rate의 mel-spectrogram을 acoustic feature로 사용함
- 이때 speech token과 mel-feature 간의 frame-rate mismatch로 인해 speech token을 2배 upsampling 하여 mel-spectrogram frame-rate에 match 함
- Upsampling operation 이전에는 future information을 제공하기 위해 additional look-ahead convolution layer를 add 함
- Look-ahead layer는 pad size가 $P$이고 kernel size가 $P+1$인 right-padded 1D convolution으로 구성됨 - 이후 speech token의 representation space를 acoustic feature와 match 하기 위해 chunk-aware Transformer block을 추가함
- Upsampling operation 이전에는 future information을 제공하기 위해 additional look-ahead convolution layer를 add 함
- 논문은 speech token을 speaker embedding, reference speech로 specify 된 mel-spectrogram으로 further decode 하기 위해 speech token으로 condition 되는 Conditional Flow Matching (CFM) model을 도입함
- CFM에서 target mel-spectrogram distribution은 prior distribution $p_{0}(X)$와 data distribution $q(X)$의 probability density path로 describe 됨
- 이때 probability density path는 time-dependent vector field로 정의할 수 있음 - 논문은 Ordinary Differential Equation (ODE)로 주어진 vector field $\omega_{t}$를 match 하기 위해 Optimal-Transport (OT) flow를 사용함:
(Eq. 3) $\omega_{t}\left(\phi_{t}^{OT}(X_{0},X_{1})|X_{1}\right)=X_{1}-X_{0}$
(Eq. 4) $\phi_{t}^{OT}(X_{0},X_{1})=(1-t)X_{0}+tX_{1}$
(Eq. 5) $X_{0}\sim p_{0}(X)=\mathcal{N}(0,I)$
(Eq. 6) $X_{1}\sim q(X)$ - Causal convolutional Transformer U-Net은 upsampled token $\mu$, masked mel-spectrogram $\tilde{X}_{1}$, speaker embedding $\mathbf{v}$, timestep $t$를 condition으로 한 ODE를 학습하기 위해 사용됨:
(Eq. 7) $\nu_{t}\left(\phi_{t}^{OT}(X_{0},X_{1})|\theta\right) =\text{UNet}_{\theta}\left( \phi_{t}^{OT}(X_{0},X_{1}), t;\mathbf{v},\{\mu\}_{1:L}, \tilde{X}_{1}\right)$
- CFM에서 target mel-spectrogram distribution은 prior distribution $p_{0}(X)$와 data distribution $q(X)$의 probability density path로 describe 됨
- Training 시에는 $X_{1}$의 final frame에서 $70\text{~}100\%$를 randomly mask 하여 masked mel-spectrogram을 얻고, 추론 시에는 reference speech에서 추출한 mel-spectrogram이 제공됨
- 결과적으로 predicted, ground-truth ODE 간의 $L1$ loss를 minimize 하여 U-Net parameter $\theta$를 optimize 할 수 있음:
(Eq. 8) $\theta = \arg\min_{\theta}\mathbb{E}_{p_{0}(X),q(X),t}\left| \omega_{t}\left( \phi_{t}^{OT} (X_{0},X_{1})\right)-\nu_{t}\left( \phi_{t}^{OT}(X_{0},X_{1})|\theta; \mu,\tilde{X}_{1},\mathbf{v}\right)\right|_{1}$
- Training stage에서 timestep은 uniform distribution $U[0,1]$을 따름 - 추론 시에는 initial generation stage에 더 많은 step을 제공하기 위해 cosine scheduler를 사용함:
(Eq. 9) $t:=1-\cos \left(\frac{1}{2}t\pi\right)$ - 추가적으로 추론 시 Classifier-Free Guidance (CFG)를 제공하기 위해 conditional, non-conditional situation 모두에 대해 model을 training 함:
(Eq. 10) $\tilde{\nu}_{t}\left(\phi_{t}^{OT}(X_{0},X_{1})|\theta;\Psi\right) =(1+\beta)\cdot \nu_{t}\left( \phi_{t}^{OT}(X_{0},X_{1})|\theta;\Psi\right)-\beta \cdot \nu_{t}\left(\phi_{t}^{OT}(X_{0},X_{1})|\theta\right)$
- $\Psi$ : condition $\{\mathbf{v},\mu,\tilde{X}_{1}\}$
- CFG strength $\beta$와 Number of Flow Estimation (NFE)는 각각 $0.7, 10$으로 설정됨
- 결과적으로 predicted, ground-truth ODE 간의 $L1$ loss를 minimize 하여 U-Net parameter $\theta$를 optimize 할 수 있음:
- 기존 flow matching model은 offline mode로 동작하여, 모든 speech token이 생성된 다음 mel-spectrogram이 sampling 되므로 streaming synthesis에는 적합하지 않음
- 이를 해결하기 위해 논문은 U-Net을 10번 repeat 하여 multi-step flow estimation을 stakced deeper neural network로 처리함
- 따라서 unfolded neural network를 causal 하게 만들어 streaming synthesis에 활용할 수 있음 - 여기서 논문은 다양한 application situation을 만족하기 위해 4가지의 mask를 구성함:
- Non-causal mask
- Non-causal mask는 offline mode에서 사용되어 모든 condition의 frame에 attend 함
- Non-causal mask는 latency-insensitive situation애 적합함 - Full-causal mask
- Full-causal mask는 past-frame에만 attend 하는 extremely low latency scenario를 처리하기 위해 사용됨 - Chunk-$M$ mask
- Chunk-$M$ mask는 latency와 performance 간의 trade-off를 제공하고 past, $M$ future frame의 information을 활용하도록 함
- 해당 mask는 low latency을 가지는 generation의 first chunk에 적합함 - Chunk-$2M$ mask
- Chunk-$2M$ mask는 더 많은 latency를 sacrifice 하여 offline mode 수준의 성능을 달성할 수 있음
- 해당 mask는 cascade generation chunk를 위해 사용될 수 있음
- Non-causal mask
- Mini-batch의 각 case에 대해, 논문은 4가지 mask 중 하나를 uniform distribution에 따라 randomly sampling 함
- 해당 chunk-aware training은 more context를 가진 mask가 less context를 가진 mask에 대한 teacher로 동작하도록 하여 implicit self-distillation scheme처럼 동작하도록 함
- 이때 speech token과 mel-feature 간의 frame-rate mismatch로 인해 speech token을 2배 upsampling 하여 mel-spectrogram frame-rate에 match 함
- Latency Analysis for Streaming Mode
- First-package latency는 streaming synthesis model에서 중요한 metric으로 사용됨
- TTS 측면에서 to-synthesize text는 known이므로, latency는 speech token generation, mel-spectrogram reconstruction, waveform synthesis 측면에서 발생함
- 따라서 CosyVoice2의 first-package latency $L_{TTS}$는:
(Eq. 11) $L_{TTS}=M\cdot d_{lm}+M\cdot d_{fm}+M\cdot d_{voc}$
- $d_{lm}$ : 하나의 speech token을 생성하는데 걸리는 LM computation time
- $d_{fm}$ : 하나의 speech token에 대한 mel-spectrogram frame을 생성하는데 걸리는 Flow Matching computation time
- $d_{voc}$ : 하나의 speech token에 대한 waveform을 합성하는데 걸리는 vocoder computation time - LLM-based voice chat에서는 first-package-required text의 length도 고려하므로, voice chat의 first-package latency $L_{Chat}$은:
(Eq. 12) $L_{Chat}\leq N\cdot d_{llm}+L_{TTS}$
- $d_{llm}$ : 하나의 text token을 생성하는데 걸리는 LLM computation time - CosyVoice2 text tokenizer에서 multi-character token은 mask out 되므로 text LLM에서 사용되는 text token은 항상 CosyVoice2 보다 longer raw text를 encode 함
- 결과적으로 $L_{Chat}$은 $N\cdot d_{llm}$과 $L_{TTS}$의 summation 보다 작아야 함
- Instructed Generation
- CosyVoice2의 controllability를 향상하기 위해 논문은 instructed dataset을 training set에 integrate 함
- Natural language instruction의 경우, to-synthesize input text 앞에 natural language description과 special end token $\text{<|endofprompt|>}$를 prepend 함
- Fine-grained instruction은 text token 사이에 $\text{[laughter]}, \text{[breath]}$와 같은 marker를 사용하여 vocal burst를 insert 함
- 추가적으로 논문은 pharse에 vocal feature tag를 적용함
- e.g.) $\text{<strong>XXX</strong>}$는 특정 word를 emphasis 하고, $\text{<laughter>XXX</laughter>}$는 laugther를 포함한 speaking을 의미함

- Multi-Speaker Fine-Tuning
- Specific speaker에서 pre-trained model을 fine-tuning (SFT)하면 generation quality와 speaker similarity를 향상할 수 있음
- 특히 multi-speaker fine-tuning (mSFT)는 pre-trained model이 multiple speaker에서 simultaneously fine-tuning 되는 것을 목표로 함
- 이를 통해 multiple speaker의 comprehensive prosody와 pronunciation coverage를 보장하고 pre-trained model의 catastrophic forgetting을 mitigate 함 - 이때 다양한 speaker 간의 timbre confusion을 avoid 하기 위해 input text에 $\text {Speaker A<|endofprompt|>}$와 같은 speaker-prompt tag를 prepend 함
- Training sample에 speaker가 label 되지 않은 경우, special tag $\text{unknown<|endofprompt|>}$를 사용함
- Multi-speaker fine-tuning process의 learning rate는 $1e-5$로 설정됨
- 특히 multi-speaker fine-tuning (mSFT)는 pre-trained model이 multiple speaker에서 simultaneously fine-tuning 되는 것을 목표로 함
- Reinforcement Learning for SFT
- Reinforcement learning은 LM output을 human preference와 align 하기 위해 사용됨
- 논문은 Speaker Similarity (SS)와 Word Error Rate (WER)을 reward function으로 사용하여 fine-tuning stage에서 speaker similarity와 pronunciation accuracy를 향상함
- 즉, WER, SS를 사용하여 preferred sample $x^{w}$와 rejected sample $x^{l}$을 distinguish 하고 Direct Preference Optimization (DPO)를 통해 TTS system을 optimize 함:
(Eq. 13) $\mathcal{L}_{DPO}(\pi_{\theta};\pi_{ref})=-\log \sigma\left( \beta\log \frac{\pi_{\theta}(\mu^{w}|y)}{\pi_{ref}(\mu^{w}|y)}-\beta\log \frac{\pi_{\theta}(\mu^{l}|y)}{\pi_{ref}(\mu^{l}|y)} \right)$
- $\mu^{w}, \mu^{l}$ : 각각 preferred sample $x^{w}$, rejected sample $x^{l}$에서 추출된 speech token - BUT, 해당 방식은 TTS system을 통해 audio를 repeatedly synthesis 해야 하므로 time-consuming 함
- Simplify를 위해 LM predicted token $\mu_{i}\in\{0,1,...,(2K+1)^{D}-1\}$을 quantized low-rank representation $\bar{H}$로 recover 하고, speech tokenizer의 ASR backend를 통해 input text를 re-predict 함:
(Eq. 14) $ \bar{h}_{i,j}=\left\lfloor \frac{\mu_{i}}{(2K+1)^{j}}\right\rfloor\,\text{mod}\,(2K+1)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \tilde{H}=\text{Proj}_{up}(\bar{H})$ - 이후 predicted log posterior는 text-speech LM을 optimize 하는 ASR reward function으로 취급함:
(Eq. 15) $\mathcal{L}_{ASR}=-\log P(Y|\tilde{H};\theta_{ASR})$
- $Y$ : input text, $\bar{H}$ : recovered speech low-rank representation
- Simplify를 위해 LM predicted token $\mu_{i}\in\{0,1,...,(2K+1)^{D}-1\}$을 quantized low-rank representation $\bar{H}$로 recover 하고, speech tokenizer의 ASR backend를 통해 input text를 re-predict 함:
- 여기서 $u_{i}\sim P(\mu_{i}|\mu_{1:i-1},Y;\theta_{LM})$의 sampling operation이 direct optimization을 방해하므로, differentiate를 위해 Gumbel Softmax sampling을 사용하고 $\mathcal{L}_{ASR}$을 통해 $\theta_{LM}$을 optimize 함
3. Experiments
- Settings
- Dataset : English, Chinese, Japanese, Korean Dataset (아래 표 참고)
- Comparisons : CosyVoice, MaskGCT, E2-TTS, F5-TTS, Seed-TTS, FireRedTTS 등

- Results
- Evaluation on Speech Tokenizer
- Codebook utilization 측면에서 FSQ-based tokenizer가 더 나은 성능을 보임

- $t$-SNE 결과를 확인해 보면, quantization 이전에는 아래 그림의 (a)와 같이 서로 다른 speaker는 서로 다른 distribution을 가지지만, quantized distribution은 (b)와 같이 nearly indistinguishable 함
- (c)의 결과 역시 tokenizer가 codebook을 fully utilize 하고 있음을 의미
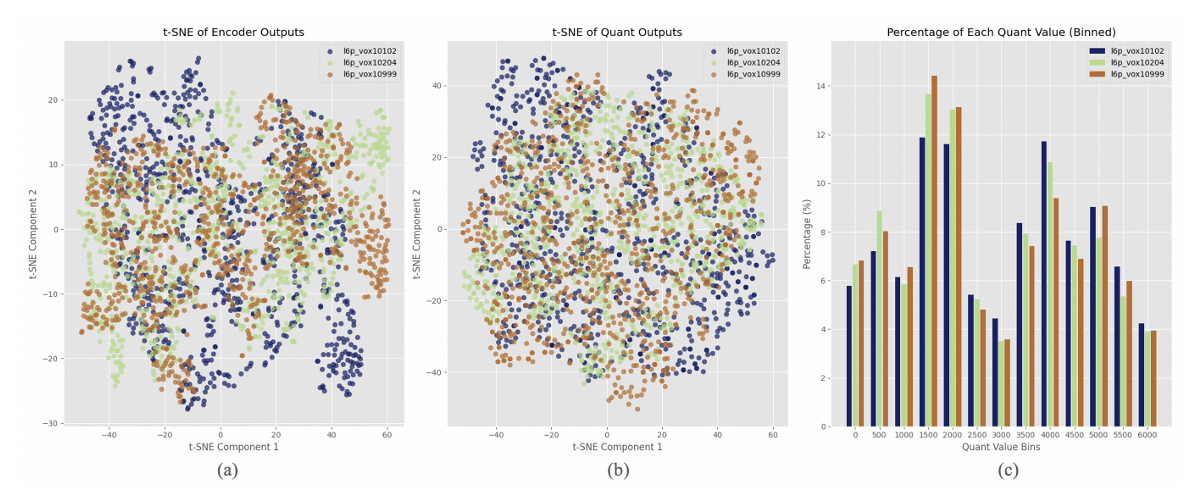
- Speaker Identification (SID) task에서, FSQ의 quantized token을 사용하면 SID layer가 converge 하지 않음
- 즉, tokenizer는 speaker information을 효과적으로 decoupling 함

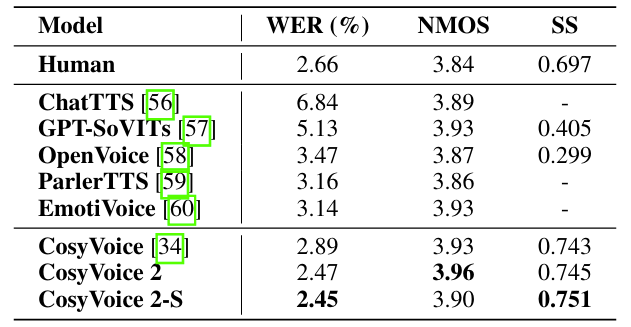
- Comparison Results with Baselines
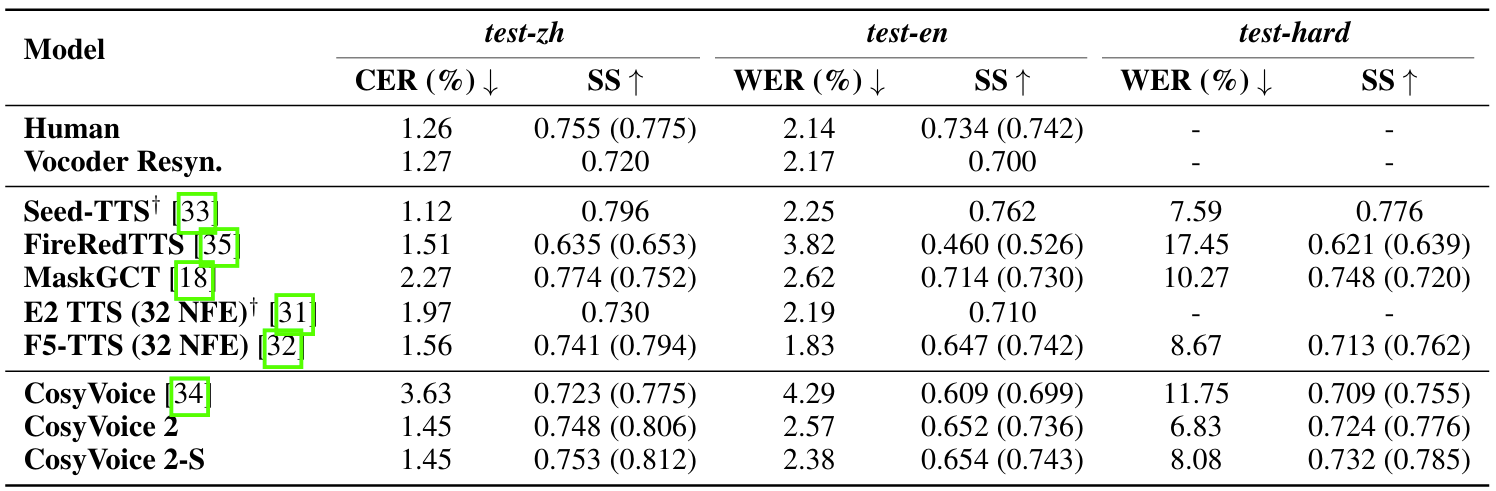
- 전체적으로 CosyVoice2의 성능이 가장 우수함
- SEED dataset에 대해서도 CosyVoice2가 우수한 성능을 보임
- Ablation Study
- 각 component는 CosyVoice의 성능 향상에 유효함
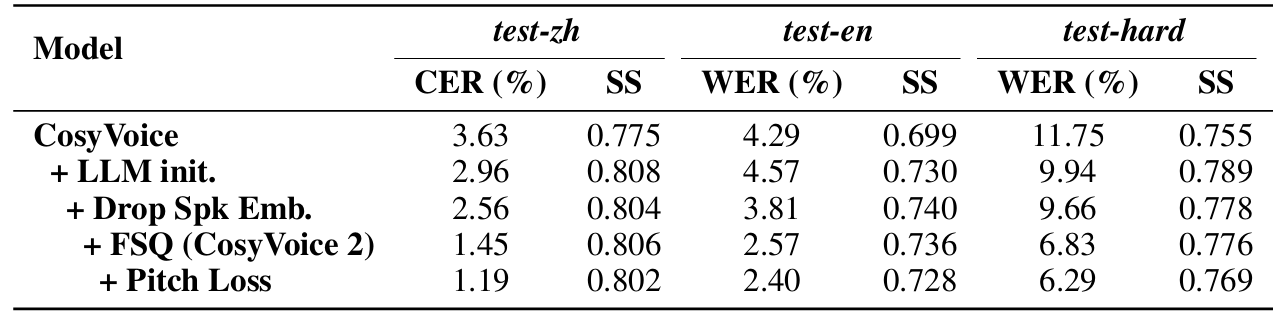
- Streaming mode에 관계없이 CosyVoice2는 consistent 한 성능을 보임

- Results on Japanese and Korean Benchmarks
- Japanese, Korean에 대해서도 우수한 성능을 달성함

- Results on Instructed Generation
- CosyVoice2는 instruction 없이도 CosyVoice-Instruct 보다 더 나은 성능을 보임

- Results on Speaker Fine-Tuned Models
- Speaker fine-tuning을 사용하면 특정 speaker에 대해 좀 더 나은 성능을 달성할 수 있음
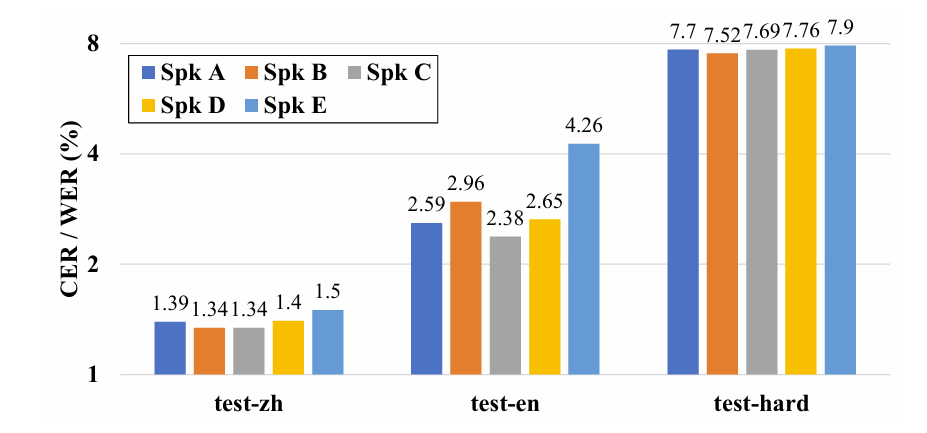
- LM Fine-Tuning with Reinforcement Learning
- CosyVoice2-SFT는 더 높은 MOS와 Speaker Similarity를 달성함
- 특히 $\mathcal{L}_{ASR}, \mathcal{L}_{DPO}$를 사용하여 추가적인 개선이 가능함

반응형
'Paper > Language Model' 카테고리의 다른 글
댓글