

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] SoundStream: An End-to-End Neural Audio Codec
feVeRin 2024. 4. 21. 13:45반응형
SoundStream: An End-to-End Neural Audio Codec
- Speech-tailored codec이 목표로 하는 bitrate로 음성, 음악, general audio를 효율적으로 compress 할 수 있도록 neural audio codec이 필요함
- SoundStream
- Fully-convolutional encoder/decoder와 residual vector quantizer로 구성된 architecture를 활용하여 end-to-end 방식으로 training 됨
- Training 시에는 adversarial loss와 reconstruction loss를 결합하여 quantized embedding에서 고품질 audio를 생성할 수 있도록 함
- Quantizer layer에 structured dropout을 적용하여 3 kbps에서 18 kbps 까지의 variable bitrate에서 동작함
- 논문 (TASLP 2021) : Paper Link
1. Introduction
- Audio codec은 크게 waveform codec과 parametric codec으로 나눌 수 있음
- Waveform codec은 decoder에서 input audio sample을 reconstruction 하는 것을 목표로 함
- 해당 codec은 주로 invertible 한 transform coding에 의존하여 input time-domain waveform을 time-frequency domain으로 mapping 함
- 이후 coefficient를 quantize 하고 entropy coding 하고, decoder에서 transform을 invert 하여 time-domina waveform을 reconstruct 함 - 최근에는 medium bitrate, narrow signal bandwidth에서 time-domain의 linear predictive coding과 transform coding을 결합하여 사용함
- 여기서 encoder의 bit allocation은 quantization process를 결정하는 perceptual model을 통해 수행됨 - 일반적으로 waveform codec은 medium-to-high bitrate로 고품질의 audio를 생성할 수 있지만, low bitrate에서는 coding artifact가 발생하는 경향이 있음
- 해당 codec은 주로 invertible 한 transform coding에 의존하여 input time-domain waveform을 time-frequency domain으로 mapping 함
- 한편으로 parametric codec은 encoding 할 source audio에 대한 특정 가정을 기반으로 parametric model 형태로 strong prior를 도입하는 방식을 사용함
- Encoder는 모델의 parameter를 추정한 다음 quantize 하고 decoder는 quantized parameter에 의해 동작하는 synthesis model을 사용하여 time-domain waveform을 생성함
- Waveform codec과 달리 parametric codec은 sample-by-sample로 reconstruction 하는 것이 아닌 원본과 perceptually similar 한 audio를 생성하는 것을 목표로 함
- 기존의 parametric, waveform codec은 주로 signal processing이나 psycho-acoustics를 활용했음
- BUT, 최근에는 neural network의 등장으로 data-driven 방식이 기존보다 더 우수한 성능을 보임
- 대표적으로 LPCNet의 경우 WaveRNN을 채택하여 낮은 bitrate에서 동작하면서 높은 reconstruction 성능을 달성
- Waveform codec은 decoder에서 input audio sample을 reconstruction 하는 것을 목표로 함

-> 그래서 neural codec을 기반으로 더 효율적으로 audio를 compress 할 수 있는 SoundStream을 제안
- SoundStream
- Neural network를 기반으로 learnable quantization module을 도입해 위 그림과 같이 low-to-medium bitrate에서도 기존보다 높은 perceptual quality를 달성
- Fully convolutional encoder는 time-domain waveform을 input으로 receive 하여 더 낮은 sampling rate로 embedding sequence를 생성한 다음, residual vector quantizer로 quantize
- Fully convolutional decoder는 quantized embedding을 receive 하고 original waveform을 reconstruction - 이때 모델은 reconstruction, adversarial loss를 모두 사용하여 end-to-end training
- 이를 위해 하나 이상의 discriminator를 사용하여 jointly training 함
- Neural network를 기반으로 learnable quantization module을 도입해 위 그림과 같이 low-to-medium bitrate에서도 기존보다 높은 perceptual quality를 달성
< Overall of SoundStream >
- Encoder, decoder, quantizer로 neural codec을 구성하고 reconstruction loss, adversarial loss를 적용하여 end-to-end로 training 함
- Residual vector quantizer를 도입하고 single model이 다양한 bitrate를 처리할 수 있도록 quantizer dropout 방법을 제시함
- Mel-spectrogram feature로 encoder를 학습하는 경우 coding efficiency를 크게 향상할 수 있음을 보임
- 결과적으로 다양한 bitrate에서 기존 모델들보다 뛰어난 품질을 달성하고, 짧은 latency로 동작가능한 streamable inference를 지원
- 추가적인 latency 없이 joint audio compression과 enhancement를 수행할 수 있는 SoundStream의 variant를 제시

2. Model
- Duration $T$를 가지고 $f_{s}$에서 sample 된 single channel recording $x\in \mathbb{R}^{T}$가 있다고 하자
- SoundStream은 다음의 3가지 component로 구성됨
- Encoder : $x$를 embedding sequence에 mapping 하는 역할
- Residual Vector Quantizer : 각 embedding을 finite codebook set의 합으로 대체하여 representation을 target bit 수로 compressing 하는 역할
- Decoder : quantized embedding으로부터 lossy reconstruction $\hat{x}\in\mathbb{R}^{T}$를 생성하는 역할
- Encoder : $x$를 embedding sequence에 mapping 하는 역할
- 이때 SoundStream은 adversarial loss와 reconstruction loss를 결합한 loss를 통해 discriminator와 함께 end-to-end training 됨
- 추가적으로 conditioning signal을 사용하여 denoising을 encoder-side/decoder-side에 적용하는 것을 결정할 수 있음
- SoundStream은 다음의 3가지 component로 구성됨
- Encoder Architecture
- Encoder architecture는 SEANet encoder를 기반으로 함
- $C_{enc}$ channel의 1D convolution layer와 $B_{enc}$개의 convolution block으로 구성됨
- 각 block은 dilation rate가 1, 3, 9인 dilated convolution과 strided convolution form의 downsampling layer를 포함하는 3개의 residual unit으로 구성
- 이때 $C_{enc}$에서 시작하여 downsampling 할 때마다 channel 수는 2배로 늘어남 - 이후 embedding dimension $D=256$을 설정하기 위해 kernel size가 3이고 stride가 1인 final 1D convolution layer를 추가
- 추가적으로 encoder는 ELU activation을 채택하고 normalization은 사용하지 않음
- 각 block은 dilation rate가 1, 3, 9인 dilated convolution과 strided convolution form의 downsampling layer를 포함하는 3개의 residual unit으로 구성
- 여기서 real-time 추론을 보장하기 위해 모든 convolution은 causal 하게 구성함
- 즉, training, offline 추론 모두에서 padding은 past에만 적용되고 future에는 적용되지 않음 - 결과적으로 convolution block 수 $B_{enc}$와 해당 stride sequence는 input waveform과 embedding 사이의 temporal resampling ratio를 결정함
- e.g.) $B_{enc}=4$이고 $(2,4,5,8)$을 stride로 사용하는 경우, 각 $M=2\cdot 4\cdot 5\cdot 8 = 320$개의 input sample마다 하나의 embedding이 계산됨
- 따라서 encoder는 $S=T/M$인 $\mathrm{enc}(x)\in \mathbb{R}^{S\times D}$를 output 함
- $C_{enc}$ channel의 1D convolution layer와 $B_{enc}$개의 convolution block으로 구성됨
- Decoder Architecture
- Decoder architecture는 아래 그림과 같이 1D convolution layer 다음에 $B_{dec}$개의 convolution block으로 이어짐
- Decoder block은 upsampling을 위한 transposed convolution과 3개의 residual unit으로 구성됨
- 이때 encoder와 동일한 stride를 사용하지만, 역순으로 적용되어 input waveform과 동일한 resolution으로 waveform을 reconstruction 함 - Upsampling을 수행할 때마다 channel 수는 절반으로 줄어드므로 마지막 decoder block은 $C_{dec}$ channel을 output 함
- 이후 최종적으로 kernel size 7, stride 1을 가지는 final 1D convolution layer를 통해 embedding을 waveform domain으로 project 하여 waveform $\hat{x}$를 생성함 - 여기서 encoder, decoer 모두 동일한 수의 channel ($C_{enc}=C_{dec}=C$)를 가지도록 구성할 수도 있지만, $C_{enc}\neq C_{dec}$와 같이 구성하는 경우, computationally lighter 한 구조를 얻을 수 있음
- Decoder block은 upsampling을 위한 transposed convolution과 3개의 residual unit으로 구성됨

- Residual Vector Quantizer
- Quantizer의 목표는 encoder output $\mathrm{enc}(x)$을 bitrate $R$로 compress 하는 것
- SoundStream은 end-to-end 방식으로 동작하므로 quantizer는 backpropagation을 통해 encoder, decoder와 함께 jointly training 되어야 함
- 이때 vector quantizer (VQ)는 joint training을 지원하기 위해 $\mathrm{enc}(x)$의 각 $D$-dimensional frame을 encoding 하는 $N$개 vector의 codebook을 학습함
- 결과적으로 encoded audio $\mathrm{enc}(x)\in \mathbb{R}^{S\times D}$는 $S\log_{2}N$ bit를 사용하여 represent 되는 $S\times N$ shape의 one-hot sequence에 mapping 됨
- SoundStream은 end-to-end 방식으로 동작하므로 quantizer는 backpropagation을 통해 encoder, decoder와 함께 jointly training 되어야 함
- Limitations of Vector Quantization
- Bitrate $R=6000$ bps에 대한 codec이 있다고 하자
- Striding factor $M=320$을 사용하는 경우, audio는 각 초마다 sampling rate $f_{s}=24000$Hz에서 encoder output에 대해 $S=75$ frame으로 represent 됨
- 이는 각 frame에 $r=6000/75=80$ bit가 allocate 되는 것에 해당함 - Plain vector quantizer를 사용하면 $N=280$ vector로 codebook을 storing 하므로, 위는 결과적으로 unfeasible 함
- Bitrate $R=6000$ bps에 대한 codec이 있다고 하자
- Residual Vector Quantizer
- 위 한계점을 해결하기 위해 SoundStream은 VQ의 $N_{q}$ layer를 cascade로 배열하는 Residual Vector Quantizer를 채택함
- 먼저 unquantized input vector는 첫 번째 VQ를 통과한 다음, quantization residual을 계산함
- 이후 아래의 [Algorithm 1]과 같이 additional $N_{q-1}$ vector quantizer에 의해 iteratively quantize 됨
- 여기서 total rate budget은 $r_{i}=r/N_{q}=\log_{2}N$으로 각 VQ에 uniformly allocate 됨
- e.g.) $N_{q}=8$인 경우, 각 quantizer는 $N=2^{r/N_{q}} = 2^{80/8}=1024$ size의 codebook을 사용함 - 각 quantizer의 codebook은 exponential moving average로 업데이트됨
- Original VQ-VAE layer나 Gumbel-Softmax를 고려할 수도 있지만, SoundStream에서는 나쁜 성능을 보임 - 한편으로 codebook 사용을 개선하기 위해 다음의 추가적인 2가지 방법을 적용함
- Codebook vector에 대해 random initialization을 사용하는 대신, 첫 번째 training batch에서 $k$-means algorithm을 적용하여 learned centroid를 initialization으로 사용함
- 이를 통해 codebook은 initialization 시 해당하는 input 분포에 더 가까워짐 - Codebook vector에 여러 batch에 대한 input frame이 할당되지 않은 경우, current batch 내에서 randomly sample 된 input frame으로 대체함
- 구체적으로, 각 vector에 대한 assignment의 exponential moving average를 추적해서 해당 statistics가 2 미만으로 떨어지는 vector를 대체
- Codebook vector에 대해 random initialization을 사용하는 대신, 첫 번째 training batch에서 $k$-means algorithm을 적용하여 learned centroid를 initialization으로 사용함
- 위 한계점을 해결하기 위해 SoundStream은 VQ의 $N_{q}$ layer를 cascade로 배열하는 Residual Vector Quantizer를 채택함

- Enabling Bitrate Scalability with Quantizer Dropout
- Residual Vector Quantization은 각 codebook의 fixed size $N$과 VQ layer 수 $N_{q}$로 bitrate를 결정함
- Vector quantizer는 encoder/decoder와 jointly train 되므로 각 target bitrate에 대응하기 위해서는 각각 서로 다른 모델을 training 해야 함
- 이러한 접근 방식은 상당히 비효율적이므로, 여러 target bitrate에서 동작할 수 있는 single bitrate scalable model을 구성하는 것이 합리적임 - 이를 위해 SoundStream은 앞선 [Algorithm 1]을 아래와 같이 수정함
- Input example에 대해 $n_{q}$를 $[1;N_{q}]$에서 uniformly sample 하고, $i=1...n_{q}$에 대해서만 quantizer $Q_{i}$를 사용함
- 이는 quantization layer에 적용되는 structured dropout으로 볼 수 있음 - 결과적으로 모델은 $n_{q}=1 ... N_{q}$ range에 해당하는 모든 target bitrate에 대해 audio를 encoding/decoding 하도록 training 됨
- 추론 시에는 desired bitrate에 따라 $n_{q}$가 선택됨
- Input example에 대해 $n_{q}$를 $[1;N_{q}]$에서 uniformly sample 하고, $i=1...n_{q}$에 대해서만 quantizer $Q_{i}$를 사용함
- 이전의 neural compression 모델은 product quantization이나 여러 VQ layer output을 concatenate 하여 사용했음
- BUT, 이러한 기존 방식은 bitrate가 변경되면 encoder/decoder의 architecture를 변경하거나 적절한 codebook을 retraining 해야 함
- SoundStream에 적용된 residual vector quantizer는 embedding dimension이 bitrate에 따라 변경되지 않음
- 실제로 VQ layer의 output에 대한 additive composition은 동일한 shape를 유지하면서 quantized embedding을 progressively refine 하므로 encoder/decoder의 변경이 필요하지 않음
- 결과적으로 주어진 bitrate에 대해 scalable 한 single SoundStream 모델을 활용 가능
- Residual Vector Quantization은 각 codebook의 fixed size $N$과 VQ layer 수 $N_{q}$로 bitrate를 결정함
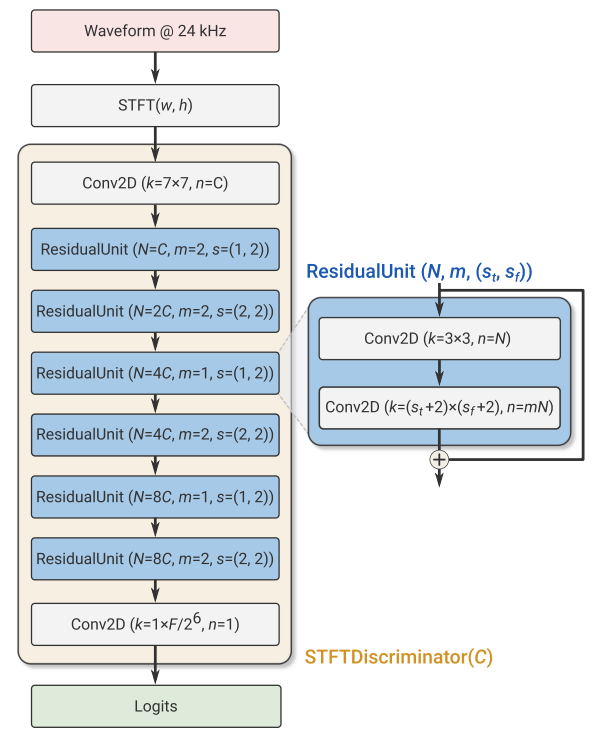
- Discriminator Architecture
- SoundStream은 adversarial loss를 계산하기 위해,
- 다음의 2가지의 discriminator를 사용함
- Wave-based discriminator : single waveform을 input으로 함
- STFT-based discriminator : 실수부, 허수부로 표현된 input waveform의 complex-valued STFT값을 input으로 함
- 두 discriminator 모두 fully-convolutional 하므로 output logit 수는 input audio length에 비례함
- HiFi-GAN과 마찬가지로 wave-based discriminator가 고품질의 음성을 reconstruction 하는데 유용한 것으로 나타남
- 이때 wave-based, STFT-based discriminator를 모두 사용하면 음악을 compress 할 때 artifact를 줄일 수 있음 - Wave-based Discriminator의 경우,
- MelGAN에서 제안된 multi-resolution convolutional discriminator를 사용함
- 여기서 구조적으로 동일한 3개의 discriminator가 서로 다른 resolution의 input audio에 적용됨 (Original, $2\times$ downsample, $4\times$ downsample)
- 각 single-scale discriminator는 initial plain convolution과 4개의 grouped convolution으로 구성되고
- 이때 각 convolution의 group size는 4, downsampling factor는 4, channel multiplier는 4, 최대 1024개의 output channel을 가짐 - 이후 final output (logit)을 생성하기 위해 2개의 plain convolution이 추가됨
- MelGAN에서 제안된 multi-resolution convolutional discriminator를 사용함
- STFT-based Discriminator의 경우,
- 먼저 아래 그림과 같이 single scale에서 동작하고 $W=1024$의 window length, $H=256$ hop size로 STFT를 계산함
- 구조적으로 kernel size $7\times 7$, 32 channel을 가지는 2D convolution 다음에는 residual block들이 추가됨
- 각 block은 $3\times 3$ convolution으로 시작하여 $(1,2), (2,2)$의 stride를 사용한 $3\times 4, 4\times 4$ convolution이 이어짐
- $(s_{t}, s_{f})$ : time, frequency axis에 따른 downsampling factor - 이후 총 6개의 residual block에 대해 $(1,2), (2,2)$ stride를 번갈아 적용하고, channel 수는 network depth에 따라 progressively increase 함
- 마지막 residual block의 output은 $T/(H\cdot 2^{3})\times F/2^{6}$ shape를 가짐
- $T$ : time domain의 sample 수, $F=W/2$ : frequency bin의 수 - 최종 layer는 downsampled time-domain에서 1D signal을 얻기 위해 fully-connected layer를 사용하여 downsampled frequency bin에 걸쳐 logit을 aggregate 함
- 다음의 2가지의 discriminator를 사용함
- Training Objective
- $\mathcal{G}(x)=\mathrm{dec}(Q(\mathrm{enc}(x))$를 input waveform $x$에 대해 encoder, quantizer, decoder를 적용한 SoundStream generator라고 하고, $\hat{x}=\mathcal{G}(x)$를 decoded waveform이라고 하자
- SoundStream은 perception-distortion trade-off에 따라 reconstruction fidelity와 perceptual quality를 모두 달성하기 위해 여러 loss들을 결합하여 SoundStream을 training 함
- 우선 adversarial loss는 perceptual quality를 개선하기 위해 사용되고 여러 discriminator에 대해 time에 따라 평균한 logit의 hinge loss로 정의됨
- $k\in\{0,...,K\}$가 개별 discriminator에 대한 index를 나타낸다고 하자
- 여기서 $k=0$은 STFT-based discriminator이고 $k\in \{1,...,K\}$는 서로 다른 resolution의 waveform-based discriminator (논문에서는 $K=3$으로 설정) - $T_{k}$를 time dimension에 따른 $k$-th discriminator의 logit 수라고 하면, discriminator는 다음을 최소화하여 original과 decoded audio를 classify함:
(Eq. 1) $\mathcal{L}_{D}=E_{x}\left[ \frac{1}{K}\sum_{k}\frac{1}{T_{k}}\sum_{t}\max(0,1-\mathcal{D}_{k,t}(x))\right]+E_{x}\left[\frac{1}{K}\sum_{k}\frac{1}{T_{k}}\sum_{t}\max(0,1+\mathcal{D}_{k,t}(\mathcal{G}(x)))\right]$ - 여기서 generator에 대한 adversarial loss는:
(Eq. 2) $\mathcal{L}^{adv}_{\mathcal{G}}=E_{x}\left[\frac{1}{K}\sum_{k,t}\frac{1}{T_{k}}\max(0,1-\mathcal{D}_{k,t}(\mathcal{G}(x)))\right]$
- $k\in\{0,...,K\}$가 개별 discriminator에 대한 index를 나타낸다고 하자
- 추가적으로 original signal $x$에 대한 decoded signal $\hat{x}$의 fidelity를 향상하기 위해 2가지 additional loss를 사용함
- Feature loss $\mathcal{L}^{feat}_{\mathcal{G}}$ : discriminator에 의해 정의된 feature space에서 계산됨
- 구체적으로 생성된 audio에 대한 discriminator의 internal layer output과 해당 target audio 간의 average absolute difference로 계산됨:
(Eq. 3) $\mathcal{L}_{\mathcal{G}}^{feat}=E_{x}\left[\frac{1}{KL}\sum_{k,l}\frac{1}{T_{k,l}}\sum_{t}\left| \mathcal{D}^{(l)}_{k,t}(x)-\mathcal{D}_{k,t}^{(l)}(\mathcal{G}(x)) \right|\right]$
- $L$ : internal layer 수, $\mathcal{D}^{(l)}_{k,t} (l\in\{1,...,L\})$ : discriminator $k$의 layer $l$의 $t$-th output, $T_{k,l}$ : time dimension에서 layer의 length - Multi-scale spectral reconstruction loss $\mathcal{L}_{\mathcal{G}}^{rec}$
- 수식적으로 Multi-scale spectral reconstruction loss는:
(Eq. 4) $\mathcal{L}_{\mathcal{G}}^{rec}=\sum_{s\in 2^{6},...,2^{11}}\sum_{t}||\mathcal{S}_{t}^{s}(x)-\mathcal{S}_{t}^{s}(\mathcal{G}(x))||_{1}+\alpha_{s}\sum_{t}|| \log\mathcal{S}_{t}^{s}(x)-\log \mathcal{S}_{t}^{s}(\mathcal{G}(x))||_{2}$
- $\mathcal{S}_{t}^{s}(x)$ : window length가 $s$이고 hop length가 $s/4$인 64-bin mel-spectrogram의 $t$-th frame
- $\alpha_{s} = \sqrt{s/2}$로 설정
- Feature loss $\mathcal{L}^{feat}_{\mathcal{G}}$ : discriminator에 의해 정의된 feature space에서 계산됨
- 결과적으로 overall generator loss는 각 loss component들의 weighted sum으로써:
(Eq. 5) $\mathcal{L}_{G}=\lambda_{adv}\mathcal{L}_{\mathcal{G}}^{adv}+\lambda_{feat}\mathcal{L}_{\mathcal{G}}^{feat}+\lambda_{rec}\mathcal{L}_{\mathcal{G}}^{rec}$
- $\lambda_{adv} =1, \lambda_{feat}=100, \lambda_{rec}=1$
- Joint Compression and Enhancement
- 기존의 audio processing pipeline에서 compression과 enhancement는 서로 다른 module로 수행됨
- 여기서 각 processing step은 채택된 specific algorithm으로 결정된 expected frame length로 input audio를 buffering 하기 때문에 end-to-end latency에 영향을 줌
- 따라서 SoundStream은 전체 latency를 늘리지 않고 동일한 모델로 compress와 enhancement를 수행하도록 함
- 먼저 enhancement는 training data의 선택에 따라 결정될 수 있으므로 SoundStream은 compress와 background noise suppression을 결합하여 사용함
- 구체적으로, 2가지 mode를 나타내는 conditioning signal을 제공하여 추론 시 denoising을 enable/disable 하는 방식으로 모델을 training 함
- 이를 위해 $(\text{input},\,\text{targets},\, \text{denoise})$ 형식의 tuple로 구성된 training data를 활용
- $\mathrm{denoise = false}$ 이면 $\mathrm{targets = inputs}$이고, $\mathrm{denoise = true}$이면 해당 input에는 clean speech component가 포함됨 - 결과적으로 network는 conditioning signal이 disable 되면 noisy speech를 reconstruct 하고, enable 되면 noisy input의 clean version을 생성하도록 training 됨
- Input이 clean audio인 경우, $\mathrm{target=input}$이고 $\mathrm{denoise}$는 $\text{true}$이거나 $\text{false}$일 수 있음
- 이는 denoising이 enable 된 경우 SoundStream이 clean audio에 adversely affecting 하는 것을 방지하기 위해 수행됨
- Conditioning signal을 처리하기 위해 network feature를 input으로 하여 다음 식과 같이 변환하는 Feature-wise Linear Modulation (FiLM) layer를 residual unit 사이에 적용함:
(Eq. 6) $\tilde{\alpha}_{n,c}=\gamma_{n,c}a_{n,c}+\beta_{n,c}$
- $a_{n,c}$ : $c$-th channel의 $n$-th activation
- $\gamma_{n,c}, \beta_{n,c}$ : denoising mode를 결정하는 2D one-hot encoding을 input으로 사용하는 linear layer에 의해 계산됨
- 결과적으로 이를 통해 time이 지남에 따라 denoising level을 adjust 할 수 있음 - 이때 FiLM layer는 encoder/decoder architecture 어느 곳에서나 사용할 수 있음
- BUT, SoundStream에서는 실험적으로 encoder/decoder-side의 bottleneck에 conditioning을 적용하는 것이 효과적인 것으로 나타남
- 여기서 각 processing step은 채택된 specific algorithm으로 결정된 expected frame length로 input audio를 buffering 하기 때문에 end-to-end latency에 영향을 줌
3. Experiments
- Settings
- Dataset : LibriTTS, FreeSound, MagnaTagATune
- Comparisons : OPUS, EVS
- Results
- Comparison with Other Codecs
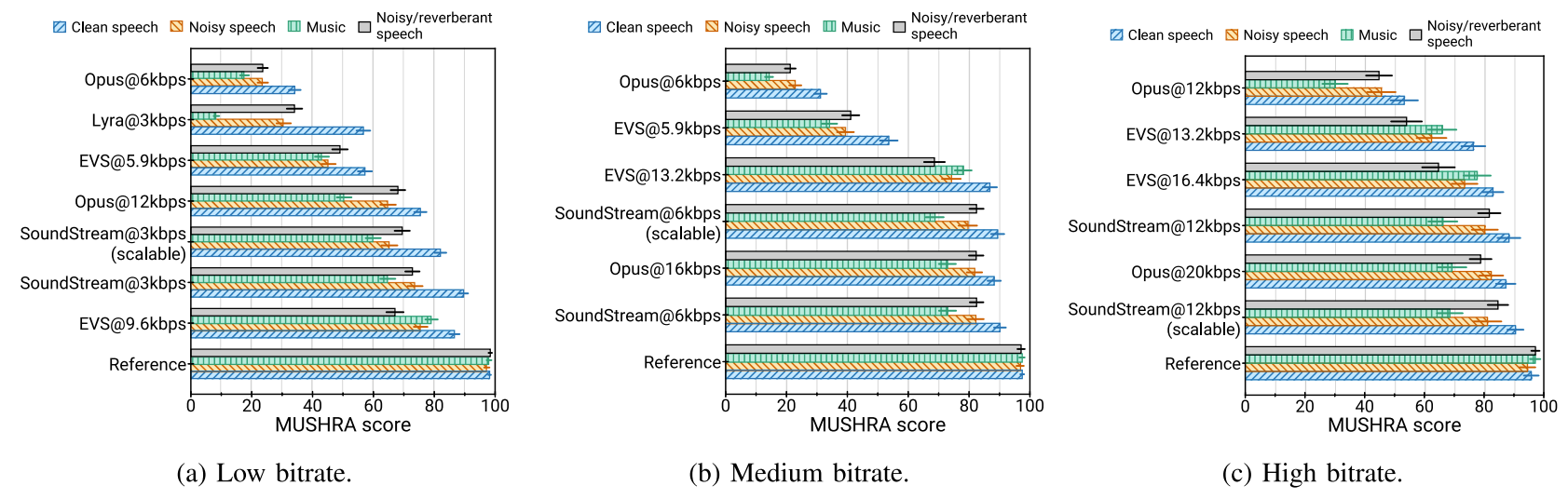
- MUSHRA 측면에서 SoundStream은 기존 bitrate의 절반인 3 kbps를 사용함에도 불구하고 6 kbps의 OPUS, EVS보다 뛰어난 성능을 보임
- 기존 codec을 SoundStream의 성능과 일치시키기 위해서는 EVS는 최소 9.6 kpbs, OPUS는 12 kbps의 bitrate가 필요함

- Content type 별 MUSHRA 성능을 비교해 보면
- Clean, noisy speech 모두에서 SoundStream을 일관되게 우수한 encoding 품질을 보임
- 특히 SoundStream은 3 kbps의 작은 bitrate로 음악을 encoding 할 수 있음
- Objective Quality Metrics
- SoundStream의 rate-quality curve를 확인해 보면, ViSQOL은 bitrate가 감소함에 따라 점차 감소하지만 가장 낮은 bitrate에서도 3.7 이상의 성능을 유지하는 것으로 나타남
- 한편으로 다양한 content type 별로 encoding 했을 때 rate-quality trade-off를 비교해 보면, 당연하게도 clean speech를 encoding 할 때 가장 좋은 품질을 보임
- Bitrate Scalability
- 서로 다른 bitrate $R$을 가지는 SoundStream을 비교해 보면, training과 추론 사이에 큰 차이가 있을수록 품질 저하가 발생함
- 이때 quantizer dropout을 사용하는 경우, 해당 격차가 사라지는 것으로 나타남
- 특히 bitrate scalable model은 9 kbps, 12 kpbs에서 bitrate specific model 보다 더 나은 성능을 보임
- 즉, quantizer dropout은 regularizer의 역할을 할 수 있음

- Ablation Study
- Advantage of Learning the Encoder : SoundStream의 learnable encoder를 fixed mel-filterbank로 대체하면, ViSQOL이 크게 저하되는 것으로 나타남
- Encoder and Decoder Capacity
- Encoder의 channel 수 $C_{enc}$와 decoder의 channel 수 $C_{dec}$가 computational efficiency에 미치는 영향을 확인해 보면,
- $C_{enc}=C_{dec}=16$으로 설정하여 capacity를 줄이면 reconstruction 품질은 크게 영향이 없지만 RTF는 크게 향상되는 것으로 나타남
- 한편으로 더 작은 encoder를 사용하면 품질 저하 없이 큰 속도 향상을 달성할 수 있음
- Advantage of Learning the Encoder : SoundStream의 learnable encoder를 fixed mel-filterbank로 대체하면, ViSQOL이 크게 저하되는 것으로 나타남

- Vector Quantizer Depth and Codebook Size
- $N_{q}$를 quantizer 수, $N$을 codebook size라고 했을 때, $N_{q}, N$의 조합에 따라 동일한 target bitrate를 달성할 수 있음
- 여기서 더 큰 codebook을 가지는 더 적은 수의 vector quantizer를 사용하면 complexity를 희생하면서 높은 coding efficiency를 달성할 수 있음
- 이때 codebook size를 늘리면 memory 문제가 발생할 수 있음 - 따라서 작은 codebook을 가지는 많은 quantizer를 사용하는 것이 neural codec에서는 더 효율적임

- Latency
- Architectural latency $M$은 stride의 곱으로써, default configuration에서 $M=2\cdot 4\cdot 5\cdot 8 =320$
- Single frame의 encoding/decoding이 더 긴 audio sample에 해당하므로 latency를 늘리면 real-time factor가 증가함

- Joint Compression and Enhancement
- 먼저 encoder, decoder 모두에서 denoising이 사용되었을 때 품질이 크게 향상되는 것으로 나타남
- Encoder-side denoising과 fixed denoising 모두 decoder-side denoising과 비교했을 때, substantial bitrate saving 효과를 제공함
- 즉, quantizer 전에 denoising을 적용하면 더 적은 bit로 encoding 할 수 있는 representation이 생성됨

- Joint vs. Disjoint Compression and Enhancement
- Denoising을 disable 한 SoundStream으로 compress 하고 dedicated denoising model로 enhancement 하는 경우와 비교해 보면
- Joint compression을 위해 training 된 single model은 2개의 disjoint model을 사용하는 것과 거의 동일한 품질을 달성함
- 특히 전자는 절반의 computation cost만 필요하므로 추가적인 architecture latency가 발생하지 않음

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글