

티스토리 뷰
Paper/Language Model
[Paper 리뷰] Differentiable Reward Optimization for LLM based TTS System
feVeRin 2025. 9. 19. 15:16반응형
Differentiable Reward Optimization for LLM based TTS System
- Neural codec language model-based Text-to-Speech system의 성능을 개선할 수 있음
- DiffRO
- Neural codec token을 기반으로 reward를 directly compute 하고 Gumbel-Softmax를 사용하여 reward function을 differentiable 하도록 구성
- 추가적으로 Multi-Task Reward model을 도입하여 다양한 perspective에서 feedback을 제공
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Neural codec token Language Modeling (LM)은 Text-to-Speech (TTS)에서 우수한 성능을 보이고 있음
- 일반적으로 pre-trained tokenizer를 사용하여 speech를 discrete token sequence로 encoding 한 다음, text input을 기반으로 해당 token을 predict 하는 decoder-only LM을 사용하여 modeling 됨
- 이후 Flow Matching (FM) model과 vocoder를 사용하여 token을 audible speech로 transform 함 - 특히 Reinforcement Learning from Human Feedback (RLHF)를 활용하면 LLM의 성능을 크게 향상할 수 있지만, TTS system에서는 다음의 문제점을 고려해야 함:
- Discrete neural codec token을 waveform audio로 convert 하는 additional backend FM, vocoder가 필요함
- 해당 backend model의 computational demand로 인해 large-scale RLHF data를 확보하기 어려움 - Generated TTS speech는 diversity가 부족하므로 reward model을 training 하기 위한 positive/negative feedback을 differentiate 하기 어려움
- TTS evaluation을 위해서는 MOS 외에도 accuracy, naturalness, speaker similarity 등을 고려해야 함
- Discrete neural codec token을 waveform audio로 convert 하는 additional backend FM, vocoder가 필요함
- 일반적으로 pre-trained tokenizer를 사용하여 speech를 discrete token sequence로 encoding 한 다음, text input을 기반으로 해당 token을 predict 하는 decoder-only LM을 사용하여 modeling 됨
-> 그래서 neural codec-based TTS model을 위한 RLHF method인 DiffRO를 제안
- DiffRO
- Neural codec token에서 reward를 directly predict 하여 backend model에 대한 computational burden을 줄이고, Gumbel-Softmax를 사용하여 reward function이 differentiable 하도록 보장
- Automatic Speech Recognition (ASR), Speech Emotion Recognition (SER), Speech Quality Assessment (SQA) 등에 대한 Multiple downstream Task Reward (MTR) model을 도입
< Overall of DiffRO >
- Neural codec token 기반의 LLM-TTS system에 대한 reward optimization method
- 결과적으로 기존보다 우수한 성능을 달성
2. Related Work
- Neural Codec LLM based TTS Systems
- Neural codec LLM-based TTS system은 주로 pre-trained speech tokenizer, neural codec token LM, FM model, acoustic vocoder로 구성됨
- 먼저 speech $X_{1:T}$와 text $Y_{1:N}$의 pair가 input으로 주어지면 speech tokenizer는 speech를 token sequence $U_{1:T}$로 encoding 함
- 다음으로 LM은 next-token prediction task를 통해 training 됨:
(Eq. 1) $U_{t}=\arg\max_{1:Q}P_{\pi}(U_{t}=q|U_{1:t-1},Y_{1:N})$
- $Q$ : tokenizer의 codebook size, $\pi$ : LM model
- Token sequence $U_{1:T}$는 대부분의 text informaiton을 포함하고 있음 - 최종적으로 TTS system은 FM과 vocoder를 사용하여 $U_{1:T}$로부터 audio $X_{1:T}$를 recover 함:
(Eq. 2) $X_{1:T}=\text{Vocoder}\left(\text{FM}(U_{1:T};\theta_{f});\theta_{v}\right)$
- $\theta_{f},\theta_{v}$ : FM, vocoder의 parameter
- RLHF for TTS
- Human/AI feedback을 얻기 위해, input $Y$는 LM에 여러 번 input 되어 서로 다른 sample strategy와 random seed를 사용한 서로 다른 audio $X^{1},X^{2},...,X^{K}$를 얻음
- Positive $X^{pos}$와 negative $X^{neg}$는 $\{X^{i}\}_{i=1}^{K}$에서 choice 되고, 해당 codec token $U^{pos}$와 $U^{neg}$는 reward model $R(X,Y)$를 training 하는 데 사용됨:
(Eq. 3) $\mathcal{L}_{R}=-\mathbb{E}\left[\log \sigma\left( R(U^{pos},Y)-R(U^{neg},Y)\right)\right]$
(Eq. 4) $\pi^{*}_{\theta}=\max_{\pi_{\theta}}\mathbb{E}\left[R(U,Y)\right]-\beta D_{KL}\left[\pi_{\theta}(U|Y)|| \pi_{ref}(U|Y)\right]$ - 이때 Proximal Policy Optimization (PPO)는 (Eq. 4)를 optimize 하고, Direct Preference Optimization (DPO)는 $U^{pos},U^{neg}$를 사용하여 (Eq. 3), (Eq. 4)을 directly optimize 함:
(Eq. 5) $\mathcal{L}_{DPO}(\pi_{\theta},\pi_{ref})=-\mathbb{E}\left[\log \sigma\left( \beta\log \frac{\pi_{\theta}(U^{pos}|Y)}{\pi_{ref}(U^{pos}|Y)}\right)-\beta\log \frac{\pi_{\theta}(U^{neg}|Y)}{\pi_{ref}(U^{neg}|Y)}\right]$
- $\pi_{\theta}$ : optimized LM, $\pi_{ref}$ : frozen reference model
- BUT, 해당 PPO/DPO는 audio output의 다양한 aspect를 반영하지 못함
- Positive $X^{pos}$와 negative $X^{neg}$는 $\{X^{i}\}_{i=1}^{K}$에서 choice 되고, 해당 codec token $U^{pos}$와 $U^{neg}$는 reward model $R(X,Y)$를 training 하는 데 사용됨:

3. Method
- DiffRO는 RL training process를 further simplify 하고 다양한 aspect의 feedback을 제공함
- Token2Reward Prediction
- DiffRO는 raw audio가 아닌 speech token으로부터 reward를 directly predict 함
- TTS system은 text를 correctly read 해야 하므로 predicted codec token $\tilde{U}$는 text의 all information을 capture 해야 함
- 따라서 ASR과 같이 neural network를 사용하여 code $U$에서 input text $Y$를 predict 할 수 있음:
(Eq. 6) $ \tilde{U}_{t}=\arg\max P_{\pi_{\theta}}(U_{t}|U_{1:n-1};Y)$
(Eq. 7) $Y_{n}^{*}=\arg\max P_{ASR}(\tilde{Y}_{n}|Y_{1:n-1};\tilde{U}_{1:T})$
- 이때 post-probability는 reward model로 취급할 수 있고, text에서 더 많은 information을 catch 하도록 $\tilde{U}$를 encourage 할 수 있음 - 추가적으로 논문에서는 (Eq. 6)의 $\arg\max$ operation을 replace 하기 위해 Gumbel-Softmax operation을 활용하여 predict token $\tilde{U}$를 sampling 함
- 그러면 reward function은 differentiable 하고, LM은 PPO/DPO strategy 없이도 reward score를 maximize 하도록 directly optimize 될 수 있음:
(Eq. 8) $R_{ASR}(Y)=\log P_{ASR}(\tilde{Y}_{n}=Y_{n}|Y_{1:n-1};\tilde{U}_{1:T})$

- Multi-Task Reward Model
- ASR reward 외에도 predicted token sequence가 requisite information을 encompass 할 수 있도록 additional downstream task를 incorporate 할 수 있음
- 이를 위해 논문은 multi-task training approach를 통해 codec-based speech understanding model을 training 하여 SER, SQA, AED 등과 같은 audio task를 수행하도록 함
- 다음으로 해당 model을 MTR model로 채택하여 TTS system이 specific instruction이나 particular characteristic을 exhibit 하도록 guide 함
- 만약 MTR model이 accessible 하다면, synthesized audio attribute $\{A_{i}\}_{i=1}^{K}$를 control 하거나 MTR model에서 predict 된 post-probability를 maximize 하여 instruction을 따르도록 할 수 있음:
(Eq. 9) $R_{MTR}(Y,\{A_{i}\}_{i=1}^{K})=\sum_{i}\log P_{task_{i}}(\tilde{A}_{i}=A_{i}|\tilde{U})$ - 여기서 $Y$는 text, $\tilde{U}$는 predict token, $A$는 target attribute, $i$는 task ID
- 만약 MTR model이 accessible 하다면, synthesized audio attribute $\{A_{i}\}_{i=1}^{K}$를 control 하거나 MTR model에서 predict 된 post-probability를 maximize 하여 instruction을 따르도록 할 수 있음:

4. Experiments
- Settings
- Dataset : SFT
- Comparisons : CosyVoice2, F5-TTS, GPT-SoVITS
- Results
- CosyVoice2에 DiffRO를 적용하면 더 나은 성능을 얻을 수 있음

- Emotion Control
- DiffRO를 사용한 CosyVoice2는 뛰어난 emotion control이 가능함
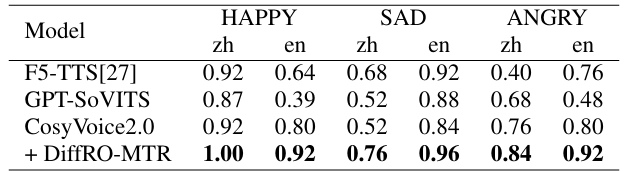
- Mel-spectrogram 측면에서도 DiffRO는 emotion을 효과적으로 반영함

- Other Attribute Control
- $\log P(A_{sqa}=\text{MOS}_{t}|\tilde{U})$를 reward로 사용하여 MOS를 control 해보면
- Predicted codec token이 target과 가까울수록 generation quality도 향상됨

반응형
'Paper > Language Model' 카테고리의 다른 글
댓글