

티스토리 뷰
Paper/Language Model
[Paper 리뷰] ELLA-V: Stable Neural Codec Language Modeling with Alignment-Guided Sequence Recording
feVeRin 2025. 5. 25. 09:06반응형
ELLA-V: Stable Neural Codec Language Modeling with Alignment-Guided Sequence Recording
- Acoustic, linguistic prompt에 기반한 language model은 zero-shot audio synthesis에서 우수한 성능을 보임
- ELLA-V
- Phoneme level에서 synthesized audio에 대한 fine-grained control을 지원
- Acoustic token ahead에 phoneme token이 appear 할 때 acoustic, phoneme token sequence를 interleaving
- 논문 (AAAI 2025) : Paper Link
1. Introduction
- Zero-shot Text-to-Speech (TTS)는 specified speaker의 training data 없이 high-quality target voice를 생성할 수 있음
- 특히 Transformer-based Language Modeling을 활용하면 powerful zero-shot synthesis가 가능함
- 대표적으로 VALL-E, SPEAR-TTS 등은 speech signal을 discrete acoustic token sequence로 quantize 한 다음, Autoregressive (AR) language model을 활용하여 coarse-grained acoustic token을 predict 함 - BUT, 해당 방식은 phoneme, acoustic token을 whole sequence로 directly concatenate 하여 language model을 training 하므로 audio와 phoneme sequence 간의 monotonic alignment를 explicitly capture 하기 어려움
- 추가적으로 decoder-only language model은 attention degradation 문제를 가지므로 generated sequence가 증가함에 따라 low-quality speech output이 나타남 - AR language modeling 측면에서, 주어진 sequence $\mathbf{x}$에 대해 standard AR model은 chanin rule $p(\mathbf{x})=\prod_{t=0}^{T}p(x_{t}|\mathbf{x}_{<t})$을 통해 likelihood $p(\mathbf{x})$를 factorize 함
- 즉, AR model은 추론 시 user control 없이 historical token에만 의존하여 current token을 predict 함
- 특히 VALL-E와 같은 TTS model은 output audio의 어떤 segment가 어떤 prompt phoneme에 해당하는지 directly determine 할 수 없으므로, generation process 문제를 promptly detect 할 수 없음
- 결과적으로 phoneme repetition, transposition, omission, infinite silence가 발생할 수 있음
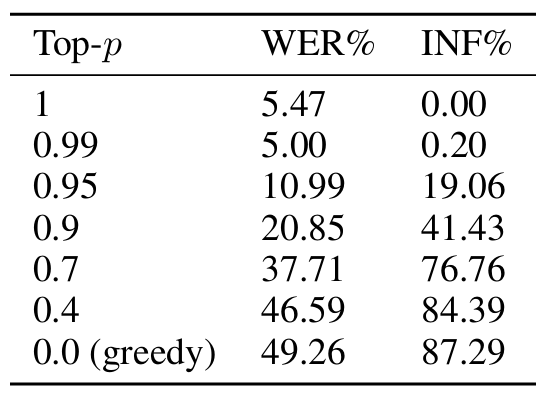
- 실제로 아래 표와 같이 VALL-E sample의 Word Error Rate (WER)와 Infinite Silence Probability (INF)를 비교해 보면, decoding strategy가 fully sampling에서 fully greedy로 shift 될수록 sample quality가 저하됨
- 특히 Transformer-based Language Modeling을 활용하면 powerful zero-shot synthesis가 가능함
-> 그래서 zero-shot TTS를 위해 기존 단점들을 개선한 effective languege model인 ELLA-V를 제안
- ELLA-V
- Neural codec의 Residual Vector Quantizer (RVQ) code의 first layer를 생성하기 위해 Generalized AR (GAR) model을 채택하고 다른 RVQ code를 얻기 위해 Non-AR (NAR) model을 활용
- 추가적으로 acousitc sequence에 해당하는 position에 phone token을 insert 하고, acoutic token과 special token에 대해서만 loss를 compute
- 이때 GAR model은 currently synthesizing phoneme을 always aware 하여 abnormal phoneme을 promptly detect, turncate 하여 infinite silence 문제를 방지함 - Local advance를 도입하여 $\text{EOP}$ token과 next-word phoneme token을 few frame ahead로 shift
< Overall of ELLA-V >
- GAR, NAR model를 기반으로 phoneme awareness, local advance를 반영한 zero-shot TTS language model
- 결과적으로 기존보다 우수한 zero-shot TTS 성능을 달성
2. Method
- Overview
- ELLA-V는 VALL-E의 two-stage framework를 따르고, zero-shot TTS를 conditional language modeling task로 취급함
- 먼저 ELLA-V는 input text prompt와 speech prompt를 각각 text encoder와 neural codec을 사용하여 unified vocabulary space로 mapping 함
- 이때 VALL-E와 달리 text-audio token sequence에 additional sequence order rearranging step을 수행하고,
- Decoder-only language model을 통해 phoneme, audio token sequence의 conditional generation을 학습함
- Discrete audio representation을 얻기 위해 논문은 pre-trained neural audio codec인 EnCodec을 채택함
- EnCodec은 24kHz raw waveform을 75Hz discrete token으로 변환하는 $L$ RVQ layer로 구성됨
- $L=8$, codebook size는 $1024$로 설정 - 결과적으로 waveform의 각 second는 RVQ에서 $75\times 8$ discrete token으로 represent 됨
- EnCodec은 24kHz raw waveform을 75Hz discrete token으로 변환하는 $L$ RVQ layer로 구성됨
- Phoneme sequence의 경우 Montreal Forced Aligner (MFA)를 적용하여 얻어짐
- 여기서 MFA는 text tokenizer와 phoneme과 해당 speech 간의 alignment를 추출하여, ELLA-V가 sequence order를 change 할 수 있도록 함
- 먼저 ELLA-V는 input text prompt와 speech prompt를 각각 text encoder와 neural codec을 사용하여 unified vocabulary space로 mapping 함

- Training: Codec Language Model
- ELLA-V는 EnCodec의 first quantization layer prediction을 위해 semantic information과 coarse-grained acoustic profile을 capture 하는 Generalized Autoregressive Codec Language Model을 활용함
- 이후에는 fine-grained acoustic detail을 reconstruct 하는 것으로 목표로 하는 non-autoregressive language model을 사용하여 subsequent quantization layer에 대한 code를 생성함
- Speech corpus $\mathcal{D}=\{\mathbf{x}_{i},\mathbf{y}_{i}\}$가 주어졌을 때, $\mathbf{x}_{i}$를 $i$-th audio sample, $\mathbf{y}_{i}$를 text transcription이라고 하자
- 여기서 EnCodec을 사용해 $\mathbf{x}_{i}$의 discrete representation을 $\mathbf{C}^{T\times 8}=\text{EnCodec}(\mathbf{x})$와 같이 추출할 수 있음
- $\mathbf{C}$ : 2-dimensional acoustic code matrix, $T$ : downsampled utterance legnth
- 논문은 transcription $\mathbf{y}$에 해당하는 phoneme sequence $\mathbf{P}_{1:n}$을 얻기 위해 MFA를 사용하고, audio $\mathbf{x}$와 transcription $\mathbf{y}$간의 forced alignment information $\mathbf{y}:(\mathbf{P}_{1:n},l_{1:n})=\text{MFA}(\mathbf{x},\mathbf{y})$을 얻음
- 여기서 $n$은 audio sample $\mathbf{x}$의 phoneme 수, $l_{i}$ : discrete audio sequence의 $i$-th phoneme length를 의미함
- MFA는 silence도 phoneme으로 취급하므로 original audio sequence는 $n$ phoneme에 해당하는 $n$ consecutive interval로 partition 됨
- 즉, $\langle \mathbf{C}_{i}\rangle^{l_{i}\times 8}$을 $i$-th phoneme의 audio sequence, $\mathbf{C}$를 $\langle \mathbf{C}_{i}\rangle$의 concatenation이라고 하면, $\langle\mathbf{C}_{k}\rangle_{1:l_{k}}=\mathbf{C}_{\sum_{i=1}^{k-1}l_{i}+1:\sum_{i=1}^{k}l_{i}}$을 얻을 수 있음 - Quantization 이후에는 discrete acoustic sequence $\mathbf{C}$로부터 audio waveform을 reconstruct 하기 위해 EnCodec decoder를 적용함
- 즉, $\hat{\mathbf{x}}\approx \text{DeCodec}(\mathbf{C})$
- Zero-shot TTS task의 optimization objective는 unseen speaker의 acoustic prompt $\hat{\mathbf{C}}$에 대해 $\max p(\mathbf{C}|\mathbf{P},\hat{\mathbf{C}})$와 같이 formulate 됨
- 이때 논문은 phoneme, codec code로 구성된 mixed sequence를 기반으로 acoustic token을 생성하는 language modeling을 수행함
- BUT, ELLA-V는 language model training을 위한 target sequence를 구성하기 위해 acoustic, phoneme token을 directly concatenate 하지 않음 - 대신 ELLA-V는 phoneme, acoustic token을 interleave 함
- 즉, silence phoneme을 제외한 각 phoneme token $P_{i}$를 audio sequence의 해당 position에 insert 하여 각 phoneme의 audio $\langle \mathbf{C}_{i}\rangle$이 $P_{i},\text{EOP}$ 사이에 sandwich 되도록 함 - 추가적으로 phoneme sequence를 mixed sequence의 beginning에 prepend 하는 global advance를 적용함
- 이때 논문은 phoneme, codec code로 구성된 mixed sequence를 기반으로 acoustic token을 생성하는 language modeling을 수행함
- 이후에는 fine-grained acoustic detail을 reconstruct 하는 것으로 목표로 하는 non-autoregressive language model을 사용하여 subsequent quantization layer에 대한 code를 생성함
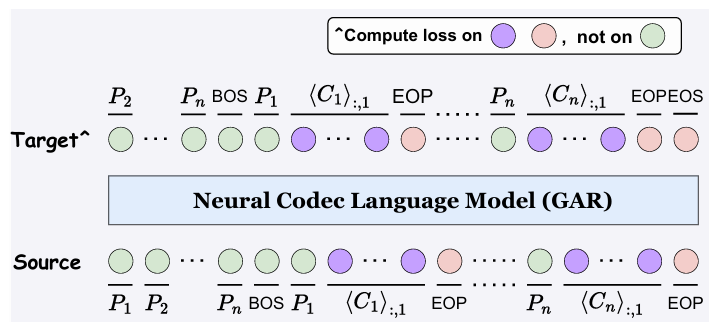
- Generalized Autoregressive (GAR) Codec Language Model
- ELLA-V는 먼저 acousitc, prompt token으로 구성된 hybrid sequence $ \mathbf{H}_{:,1}=\left[P_{1},P_{2},...,P_{n},\text{BOS},P_{1},\langle \mathbf{C}_{1}\rangle_{:,1}, \text{EOP},...,P_{n},\langle \mathbf{C}_{n}\rangle_{:,1},\text{EOP},\text{EOS} \right]$를 구성함
- 여기서 MFA는 silence를 distinct phoneme으로 취급하지만 phoneme sequence $\mathbf{P}$는 silence 이외의 phoneme 만으로 구성됨
- 즉, 논문은 silence와 관련된 acoustic component는 retain 하되, $\text{EOP}$와 specific silence phoneme으로 sandwich 하지 않고 gloal advance part에서도 silence phoneme을 사용하지 않음
- ELLA-V는 hybrid sequence에서 continuation task를 수행하기 위해, GAR language model을 활용하여 discrete acoustic code sequence $\mathbf{C}_{:,1}$을 생성함
- 구조적으로 GAR model은 multiple Transformer decoder layer로 구성되고, training 이후 specified text prompt, acoustic prompt에 대한 discrete audio code를 생성함
- 추가적으로 GAR은 phoneme과 entire sentence의 conclusion을 indicate 하기 위해 $\text{EOP},\text{EOS}$를 predict 함 - GAR optimization은 hybrid sequence $\mathbf{H}_{:,1}$의 acoustic part $\mathbf{C}_{:,1}$과 special $\text{EOP},\text{EOS}$ token의 likelihood를 maximize 하여 수행됨:
(Eq. 1) $ \max_{\theta_{GAR}}\log p\left(\tilde{\mathbf{C}}_{:,1}|\mathbf{P};\theta_{GAR}\right)=\sum_{i=1}^{n}\sum_{t=0}^{l_{i}}\log p\left(\langle \tilde{\mathbf{C}}_{i}\rangle_{t,1} |\langle \tilde{\mathbf{C}}\rangle_{<t,1},\langle \tilde{\mathbf{C}}_{<i}\rangle_{:,1},\mathbf{P};\theta_{GAR}\right)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, =\sum_{t=0,\mathbf{H}_{t,1}\neq\text{BOS},\mathbf{H}_{t,1}\notin\{\mathbf{P}\} }^{T_{\mathbf{H}}}\log p\left(\mathbf{H}_{t,1}|\mathbf{H}_{<t,1};\theta_{GAR}\right)$
- $\mathbf{H}$ : $T_{\mathbf{H}}\times 8$ size를 가짐
- $\{\mathbf{P}\}$ : phoneme set, $\tilde{\mathbf{C}}$ : $\langle \mathbf{C}_{i}\rangle$의 concatenation, $\theta_{GAR}$ : GAR model의 neural network parameter
- $\langle \tilde{\mathbf{C}}_{i}\rangle$ : trailing $\text{EOP},\text{EOS}$ token과 broadcast 되는 $\langle \mathbf{C}_{i}\rangle$의 concatenation
- 구조적으로 GAR model은 multiple Transformer decoder layer로 구성되고, training 이후 specified text prompt, acoustic prompt에 대한 discrete audio code를 생성함
- Training objective의 factorization 측면에서:
- GAR은 audio sequence를 phoneme-by-phoneme으로 생성함
- 여기서 GAR은 각 phoneme token에 대해 maximum likelihood prediction을 successively produce 하고 specified phoneme generation end를 indicate 하기 위해 $\text{EOP}$를 predict함 - 다음으로 global advancement를 통해 GAR은 network prediction에 의존하지 않고 next phoneme을 directly infer 할 수 있음
- 최종적으로 last phoneme에 대한 prediction이 완료된 다음, GAR은 $\text{EOS}$를 predict 함으로써 generation process를 stop 함
- GAR을 통해 생성된 sequence는 self-align 되어 있고 phoneme prompt에 해당하는 generated acoustic token의 해당 position을 instantly know 할 수 있음
- GAR은 audio sequence를 phoneme-by-phoneme으로 생성함
- Training 시 논문은 hybrid sequence에서 $\text{BOS}$ 이전의 phoneme sequence에 대해 bidirectional mask를 적용하고 $\text{BOS}$ 이후에는 unidirectional mask를 적용함
- 이를 기반으로 hybrid sequence에 대한 next-token-prediction language modeling task로 training 함
- 이때 model은 phoneme이나 $\text{BOS}$를 predict 하지 않고, predicted token이 phoneme이나 $\text{BOS}$가 아닐 때에 대한 loss를 compute 함 - 추론 시에는 phoneme에 대한 $\text{EOP}$를 predict 하고 next phoneme token를 sequence end에 directly append 함
- 이를 기반으로 hybrid sequence에 대한 next-token-prediction language modeling task로 training 함
- ELLA-V는 먼저 acousitc, prompt token으로 구성된 hybrid sequence $ \mathbf{H}_{:,1}=\left[P_{1},P_{2},...,P_{n},\text{BOS},P_{1},\langle \mathbf{C}_{1}\rangle_{:,1}, \text{EOP},...,P_{n},\langle \mathbf{C}_{n}\rangle_{:,1},\text{EOP},\text{EOS} \right]$를 구성함
- Non-Autoregressive (NAR) Codec Language Model
- Second stage에서 NAR language model은 last quantization layer까지의 code를 parallel predict 하기 위해 사용됨
- NAR model의 input-output sequence는 GAR model의 pattern과 동일함 - Hybrid sequence matrix $\mathbf{H}$의 $i$-th column $\mathbf{H}_{:,i}$는 $\left[P_{1},P_{2},...,P_{n},\text{BOS},P_{1},\langle \mathbf{C}_{1}\rangle_{:,i},\text{EOP},..., P_{n},\langle \mathbf{C}_{n}\rangle_{:,i},\text{EOP},\text{EOS}\right]$와 같이 구성됨
- $P_{i}$가 silence를 represent 하는 경우, $\mathbf{C}_{:,i}$는 $P_{i}, \text{EOP}$ 사이에 sandwich 되지 않음 - 결과적으로 NAR model은 previous $j-1$ layer의 previously generated hybrid sequence를 input으로 사용하고 $j$-th layer의 code를 parallel predict 함:
(Eq. 2) $\max_{\theta_{NAR}}\sum_{j=2}^{8}\log p\left( \mathbf{C}_{:,j}|\mathbf{H}_{:,<j},\mathbf{P};\theta_{NAR}\right)=\sum_{j=2}^{8}\sum_{t=0, \mathbf{H}_{t,j}\in\{\mathbf{C}_{:,j}\} }^{T_{\mathbf{H}}}\log p\left(\mathbf{H}_{t,j}|\mathbf{H}_{:,<j},\mathbf{P};\theta_{NAR}\right)$
- $\{\mathbf{C}_{:,j}\}$ : $j$-th quantizer의 acoustic token set
- 이후 previous $j-1$ quantizer의 token embedding을 sum up 하고 NAR에 전달하여 $j$-th layer를 predict 함
- Second stage에서 NAR language model은 last quantization layer까지의 code를 parallel predict 하기 위해 사용됨
- Inference
- ELLA-V는 unseen speaker의 short clip을 acoustic prompt로 사용하여 specified text에 대한 speech를 합성함
- VALL-E의 경우 추론 시 infinite loop에 stuck 할 수 있어 infinite silence나 repetitive pronunciation이 발생함
- 반면 ELLA-V의 경우 $\text{EOP}$를 생성하여 abnormally long phoneme을 promptly truncate 할 수 있음
- $\text{EOP}$ 이후 generated sequence end에 next phoneme token을 directly append 하여 abnormal pause나 repetition 없는 proper generation을 보장함
- GAR model의 경우 sampling-based decoding을 사용하고 NAR model의 경우 greedy decoding을 사용함

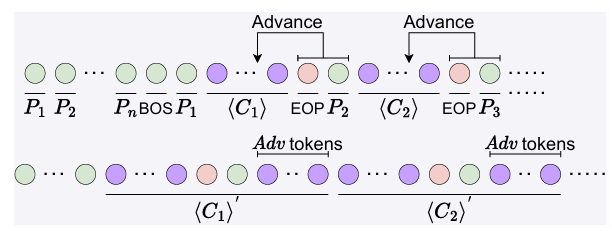
- Local Advance
- Phoneme의 pronunciation은 주변의 phoneme과 strongly relate 되어 있음
- BUT, GAR model의 autoregressive nature로 인해 acoustic token은 following phoneme token에 attend 할 수 없음
- 한편으로 global advance를 통해 long-term dependency를 modeling 하는 Transformer를 활용해 acoustic token generation에 대한 complete context를 제공할 수 있음
- 여기서 논문은 Transformer의 powerful local dependency modeling을 활용하기 위해 sequence order에 additional change를 도입함
- 즉, phoneme token과 $\text{EOP}$ token을 few frame ahead로 이동시키는 local advance를 적용함
3. Experiments
- Settings
- Dataset : LibriSpeech
- Comparisons : SoundStorm, YourTTS, VALL-E
- Results
- 전체적으로 ELLA-V의 성능이 가장 뛰어남

- Zero-Shot TTS Cross-Speaker Task on Hard Cases
- 100개의 Hard synthesis case에 대해 ELLA-V는 가장 낮은 WER을 달성함

- Analysis of Decoding Strategy and Local Advance
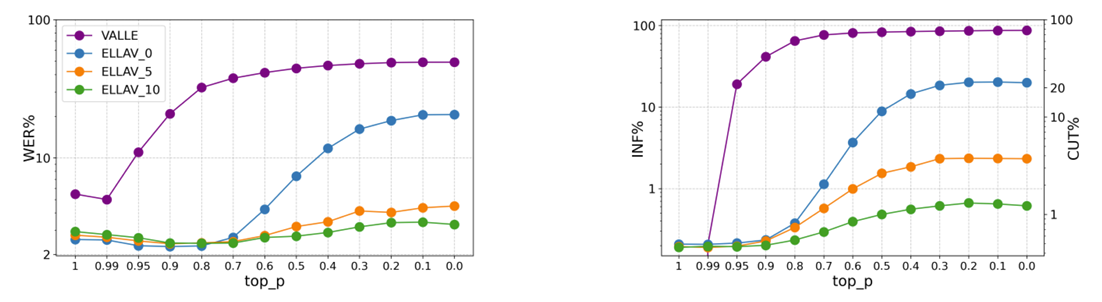
- 다양한 top-$p$ 값에 대한 decoding 성능을 비교해 보면, top-$p$가 감소함에 따라 VALL-E의 accuracy도 감소함
- 이 경우, VALL-E는 overfit silence token을 생성함 - ELLA-V의 경우 VALL-E에 비해 top-$p$ sampling strategy에 less sensitive 함
- 추가적으로 exceptional phoneme의 synthesis를 promptly truncate 할 수 있으므로 higher robustness를 가짐
- 다양한 top-$p$ 값에 대한 decoding 성능을 비교해 보면, top-$p$가 감소함에 따라 VALL-E의 accuracy도 감소함
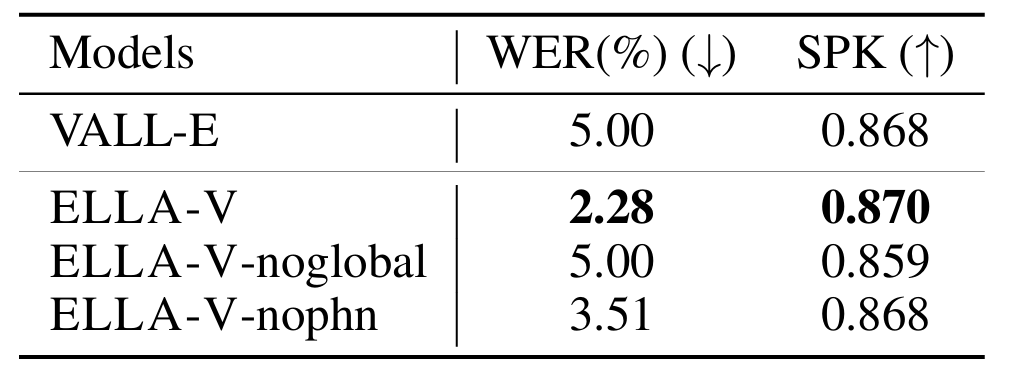
- Ablation Study
- Global, local phoneme information을 제거하는 경우 성능 저하가 발생함
반응형
'Paper > Language Model' 카테고리의 다른 글
댓글