

티스토리 뷰
Paper/TTS
[Paper 리뷰] Matcha-TTS: A Fast TTS Architecture with Conditional Flow Matching
feVeRin 2024. 4. 25. 10:30반응형
Matcha-TTS: A Fast TTS Architecture with Conditional Flow Matching
- Optimal-transport conditional flow matching을 사용하여 text-to-speech에서의 acoustic modeling 속도를 향상할 수 있음
- Matcha-TTS
- Optimal-transport conditional flow matching을 기반으로 기존의 score matching 방식보다 더 적은 step으로 고품질의 output을 제공하는 ODE-based decoder를 얻음
- Probabilistic, non-autregressive 하게 동작하고 external alignment 없이 scratch로 학습 가능
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Diffusion Probabilistic Model (DPM)은 Text-to-Speech (TTS)와 같은 continuous-valued data-generation task에서 우수한 성능을 보이고 있음
- 여기서 DPM은 target data distribution을 Gaussian과 같은 prior distribution으로 변환하는 diffusion process를 정의하고, 해당 과정을 reverse 하는 sampling process를 학습함
- 해당 process는 forward-/reverse-time Stochastic Differential Equation (SDE)로 formulate 되고, reverse-time SDE initial value problem을 solve 하여 learnt data distribution에서 sample을 생성
- 한편으로 probability flow Ordinary Differential Equation (ODE)를 사용하여 SDE와 동일한 분포를 sampling 할 수도 있음
- Probability flow ODE는 Continuous-time Normalizing Flow (CNF)와 유사하게 source sample을 data sample로 변환하는 deterministic process
- 이는 expensive ODE solver나 adjoint variable을 통해 reverse ODE를 근사할 필요가 없다는 장점이 있음
- 특히 DPM의 SDE formulation은 data distribution의 score function인 log probability density의 gradient를 근사하여 training 됨
- 일반적으로 training objective는 likelihood에 대한 Evidence Lower BOund (ELBO)에서 유도된 Mean Squared Error (MSE)로써 정의됨
- 해당 objective는 simple 하지만, normalizing flow와 달리 model architecture에 대한 어떠한 제한도 impose 하지 않음 - 결과적으로 numerical SDE 없이도 training이 가능하긴 하지만, 전체 neural network를 evaluate 해야 하므로 DPM에 대한 느린 합성 속도 문제로 이어짐
- 여기서 DPM은 target data distribution을 Gaussian과 같은 prior distribution으로 변환하는 diffusion process를 정의하고, 해당 과정을 reverse 하는 sampling process를 학습함
-> 그래서 빠른 TTS 합성을 위해 continuous normalizing flow를 기반으로 하는 probabilistic, non-autoregressive acoustic model인 Matcha-TTS를 제안
- Matcha-TTS
- 1D CNN과 transformer의 조합으로 구성되는 decoder를 활용한 encoder-decoder architecture를 구성
- 이를 통해 memory 사용량을 줄이고 합성 속도를 개선함 - Data distribution에서 sampling을 수행하는 ODE를 학습하기 위해 Optimal-Transport Conditioning Flow Matching (OT-CFM)을 사용
- 기존 CNF, score-mathcing flow와 비교하여 OT-CFM은 source에서 target까지의 simpler path를 정의 가능함
- 이를 통해 기존 DPM보다 더 적은 step으로 고품질의 합성이 가능
- 1D CNN과 transformer의 조합으로 구성되는 decoder를 활용한 encoder-decoder architecture를 구성
< Overall of Matcha-TTS >
- OT-CFM을 기반으로 기존의 score matching 방식보다 더 적은 step으로 고품질의 output을 제공하는 ODE-based decoder를 구성
- 결과적으로 기존 모델들보다 더 빠르고 효율적이면서 고품질의 합성이 가능
2. Method
- Optimal-Transport Conditional Flow Matching (OT-CFM)
- 먼저 $x$를 complicated, unknown data distribution $q(x)$에서 sampling된 data space $\mathbb{R}^{d}$의 observation이라고 하자
- Probability density path는 time-dependent probability density function $p_{t} : [0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}>0$이라고 할 수 있음
- 이때 data distribution $q$에서 sample을 생성하기 위해서는 probability density path $p_{t}$를 구성해야 함
- $t\in [0,1]$, $p_{0}(x)=\mathcal{N}(x;0,I)$는 $p_{1}(x)$가 data distribution $q(x)$에 근사되는 prior distribution - CNF는 vector field $v_{t}:[0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}^{d}$를 정의한 다음, ODE를 통해 flow $\phi_{t} : [0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}^{d}$를 생성함:
(Eq. 1) $\frac{d}{dt}\phi_{t}(x)=v_{t}(\phi_{t}(x)); \,\,\,\,\, \phi_{0}(x)=x$
- 이는 data point의 marginal probability distribution으로써 path $p_{t}$를 생성함
- (Eq. 1)의 initial value problem을 solve함으로써 근사 data distribution $p_{1}$에서 sampling을 수행할 수 있음
- 이때 data distribution $q$에서 sample을 생성하기 위해서는 probability density path $p_{t}$를 구성해야 함
- $p_{0}$에서 $p_{1}\approx q$까지의 probability path $p_{t}$를 생성하는 known vector field $u_{t}$가 있다고 하자
- 그러면 flow matching loss는:
(Eq. 2) $\mathcal{L}_{FM}(\theta)=\mathbb{E}_{t,p_{t}(x)}||u_{t}(x)-v_{t}(x;\theta)||^{2}$
- $t\sim\mathbb{U}[0,1]$이고 $v_{t}(x;\theta)$ : parameter $\theta$를 가지는 neural network
- 이때 vector field $u_{t}$와 target probability $p_{t}$에 access 하는 것은 non-trivial 하기 때문에 flow matching은 intractable 함 - 따라서 대신 conditional flow matching을 고려:
(Eq. 3) $\mathcal{L}_{CFM}(\theta)=\mathbb{E}_{t,q(x_{1}),p_{t}(x|x_{1})}||u_{t}(x|x_{1})-v_{t}(x;\theta)||^{2}$
- 이를 통해 intractable probability density와 vector field를 conditional probability density와 conditional vector field로 대체할 수 있음
- 결과적으로 이들은 tractable 하고 closed-form solution을 가지므로, $\mathcal{L}_{CFM}(\theta)$, $\mathcal{L}_{FM}(\theta)$ 모두 $\theta$에 대해 identical gradient를 가짐
- 그러면 flow matching loss는:
- 결과적으로 Matcha-TTS는 simple gradient를 사용하는 CFM variant인 OT-CFM을 사용하여 training 됨
- 이때 OT-CFM loss는:
(Eq. 4) $\mathcal{L}(\theta)=\mathbb{E}_{t,q(x_{1}),p_{0}(x_{0})}\left|\left| u_{t}^{OT}\left( \phi^{OT}_{t}(x)|x_{1}\right)-v_{t}\left(\phi_{t}^{OT}(x)|\mu;\theta\right)\right|\right|^{2}$
- $\phi_{t}^{OT}(x)=(1-(1-\sigma_{\min})t)x_{0}+tx_{1}$를 $x_{0}$에서 $x_{1}$까지의 flow로 정의하면, 각 datum $x_{1}$은 random sample $x_{0}\sim \mathcal{N}(0,I)$에 match 됨 - 기댓값을 학습 목표로 사용하는 gradient vector field는 $u_{t}^{OT}(\phi_{t}^{OT}(x_{0})|x_{1})=x_{1}-(1-\sigma_{\min})x_{0}$로 나타냄
- 이는 lienar, time-invariant 하고 $x_{0}, x_{1}$에만 의존하므로, 해당 property를 사용하여 DPM보다 더 빠른 training/generation이 가능하고 더 나은 성능을 얻을 수 있음
- 이때 OT-CFM loss는:
- Matcha-TTS에서 $x_{1}$은 acoustic frame, $\mu$는 decoder architecture를 사용하여 text로부터 예측된 frame들의 conditional mean value와 같음
- 논문에서는 hyperparameter $\sigma_{\min}$을 $\mathrm{1e-4}$로 설정
- Probability density path는 time-dependent probability density function $p_{t} : [0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}>0$이라고 할 수 있음
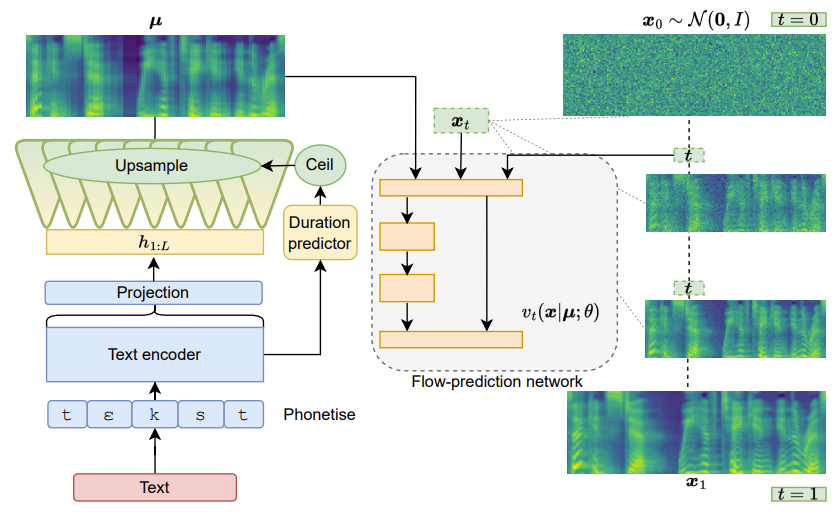
- Proposed Architecture
- Matcha-TTS는 non-autoregressive encoder-decoder architecture로 구성됨
- 먼저 text encoder, duration predictor는 Grad-TTS와 Glow-TTS를 따름
- 대신 realtive embedding이 아닌 rotational position embedding을 사용 - Alignment와 duration-model training을 위해 Monotonic Alignment Search (MAS)와 prior loss $\mathcal{L}_{enc}$를 사용
- 예측된 duration은 반올림된 다음, encoder output vector를 upsample 하여 text와 chosen duration에 대해 예측된 average acoustic feature $\mu$를 얻는 데 사용됨
- 해당 평균은 합성에 사용되는 vector field $v_{t}\left(\phi_{t}^{OT}|\mu;\theta \right)$를 예측하는 decoder를 condition 하는 데 사용되지만, initial noise sample $x_{0}$에 대해서는 사용되지 않음 - Matcha-TTS의 decoder architecture는 아래 그림과 같이 input을 downsampling/upsampling 하기 위한 1D convolution residual block을 가지는 U-Net으로 구성되고 $t\in[0,1]$에 대한 flow-matching step을 포함함
- 각 residual block 다음에는 transformer block이 추가되고, 이는 feedforward network과 snake beta activation으로 구성됨
- 이때 transformer에서는 positional embedding을 사용하지 않음
- Phone positional information은 이미 encoder에 의해 얻어져 있고, convolution과 downsampling operation은 동일한 phone의 frame 내에서 이를 interpolate 하고 relative position을 distinguish 하는 역할을 수행하기 때문
- 결과적으로 이렇게 구성된 Matcha-TTS의 decoder network는 Grad-TTS의 2D convolution-only U-Net보다 더 빠른 속도를 가지고 더 적은 memory를 소모함
- 먼저 text encoder, duration predictor는 Grad-TTS와 Glow-TTS를 따름

3. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : Grad-TTS, FastSpeech2, VITS
- Results
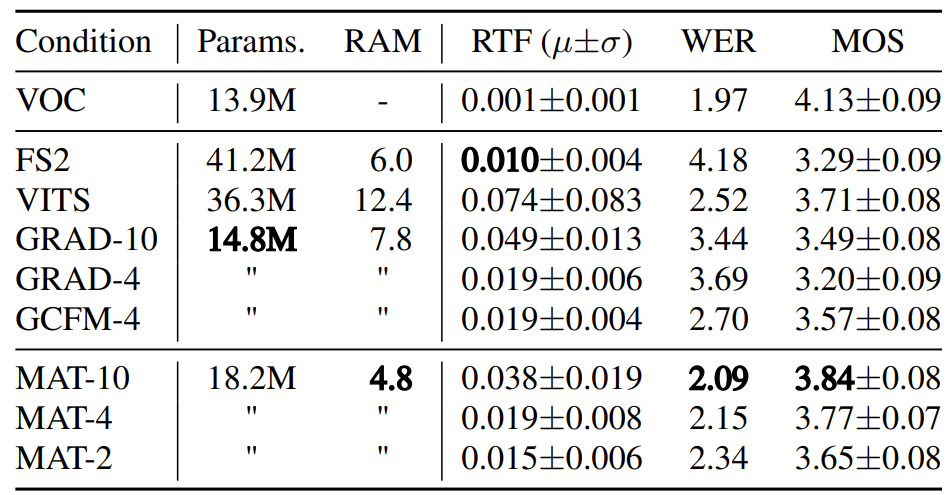
- 먼저 Matcha-TTS는 Grad-TTS와 비슷한 수준의 적은 parameter 수를 가지면서 가장 우수한 WER, MOS 성능을 보임
- 특히 13.9M의 HiFi-GAN vocoder를 추가하더라도 Matcha-TTS의 parameter 수는 VITS 보다 적음
- Memory 사용 측면에서도 Matcha-TTS는 가장 효율적이고 FastSpeech2 다음 수준의 RTF를 보임
- 추가적으로 utterance length에 따라 합성 시간의 변화를 확인해 보면
- Matcha-TTS는 500 character 이상의 longer utterance에서도 FastSpeech2 보다 빠른 합성이 가능함
- 특히 Grad-TTS와 비교하면 더 큰 합성 속도 격차를 보임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글