

티스토리 뷰
Paper/TTS
[Paper 리뷰] Mega-TTS2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
feVeRin 2024. 7. 21. 11:25반응형
Mega-TTS2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
- Zero-shot text-to-speech에서 prompting mechanism은 다음의 문제를 가지고 있음
- 대부분 single-sentence prompt로 training 되므로 추론 시 주어지는 data가 다양한 경우 성능이 제한됨
- Prompt의 prosodic information은 timbre와 highly couple 되어 있고, 서로 untransferable 함 - Mega-TTS2
- 고품질 reconstruction을 제공하면서 prosody, timbre information을 compressed latent space로 separately encode 하는 acoustic autoencoder를 설계
- Multi-sentence prompt에서 useful information을 추출하기 위해 prosody-latent language model을 도입
- 논문 (ICLR 2024) : Paper Link
1. Introduction
- Adaptive text-to-speech (TTS)는 few speech data가 주어졌을 때 personalized voice를 cloning 하는 것을 목표로 함
- 특히 YourTTS, GenerSpeech, Grad-StyleSpeech와 같은 generative model 기반의 zero-shot TTS는 sinlge speech prompt 만으로도 효과적인 음성 합성이 가능함
- 이를 통해 추가적인 data preparation이나 fine-tuning에 대한 의존성을 줄임 - BUT, zero-shot TTS에서 prompt mechanism은 다음의 문제점을 가지고 있음:
- Lack of Multi-sentence Prompting Strategy
- 기존의 zero-shot TTS는 training 중에 single-sentence speech prompt를 사용하므로, 추론 시 natural speech의 voice variability를 반영하기에 충분하지 못함
- 즉, multi-sentence speech prompt에서 useful information을 추출하는 strategy가 부족함 - Lack of Specialized Prompting Mechanism for Prosodic Information
- 기존의 zero-shot TTS는 주어진 prompt의 unique timbre를 preserving 하면서 unseen prosodic style을 효과적으로 control 하지 못함
- 즉, prosodic style control을 위해 speech prompt와 prosody information을 disentangle 해야 함
- Lack of Multi-sentence Prompting Strategy
- 특히 YourTTS, GenerSpeech, Grad-StyleSpeech와 같은 generative model 기반의 zero-shot TTS는 sinlge speech prompt 만으로도 효과적인 음성 합성이 가능함
-> 그래서 앞선 zero-shot TTS의 prompt mechanism을 개선한 Mega-TTS2를 제안
- Mega-TTS2
- Speech를 prosody, timbre representation으로 decompose 하고 compact latent space에 represent 하는 acoustic autoencoder를 설계
- 이후 multi-sentence prompt에서 useful information을 추출하는 Multi-Reference Timbre Encoder (MRTE)와 Prosody-Latent Language Model (P-LLM)을 도입
- 추가적으로 target speaker의 timbre를 유지하면서 multiple speaker의 prosody prompt를 활용하여 prosody code generation을 control 하는 prosody interpolation technique을 적용
< Overall of Mega-TTS2 >
- Prosody, timbre information을 latent space로 separately compress 하는 acoustic autoencoder를 도입
- Speaker similarity gap을 해소하기 위해 multiple reference speech에서 fine-grained information을 추출하는 MRTE, P-LLM을 채택
- 결과적으로 기존보다 뛰어난 합성 품질을 달성하고 prosody controllability를 향상
2. Method
- Decomposition for Prosody and Timbre
- Problem Formulation
- $H(X)$를 $X$의 Shannon entropy, $I(Y;X)$를 mutual information이라고 하자
- 논문은 mel-spectrogram $y$가 $y=D(z_{c},z_{pd},z_{t},g)$의 generative process를 통해 reconstruct 될 수 있다고 가정함
- $z_{c}, z_{t}$ : 각각 fine-grained content, timbre hidden state
- $g$ : timbre, prosody를 포함하는 global style information - $z_{pd} = (z_{p}, z_{d})$가 pitch/energy $z_{p}$와 duration $z_{d}$에 대한 fine-grained prosodic style information을 포함한다고 하자
- 그러면 $z_{d}=\text{Aligner}(y)$는 external alignment tool로 얻을 수 있고, $z_{pd}$로부터 disentangle 됨 - 결과적으로 $D$를 mel-spectrogram decoder라고 했을 때, 논문은 speech component를 disentangle 하기 위해 autoencoder-based model을 구축하는 것을 목표로 함
- Decomposition via Corpus Partition
- $Y=\{y_{1},...,y_{n}\}$을 certain speaker $S$에 대한 speech corpus라고 하자
- Training 중에 $Y$는 target mel-spectrogram $y_{t}$와 나머지 mel-sepctrogram $\tilde{y}$로 partition 됨
- 이때 논문은 $y_{t}, \tilde{y}$ 간의 mutual information에는 $y_{t}$의 timbre information $H(z_{t})$와 global style information $H(g)$만 포함된다고 가정함:
(Eq. 1) $I(y_{t};\tilde{y})=H(z_{t})+H(g)$
- 위 가정에 의하면,
- $z_{t}$와 $g$는 $E_{t}(\tilde{y})$를 통해 추출될 수 있지만, $E_{t}(\tilde{y})$에서는 $z_{p}, z_{c}$를 얻을 수 있는 방법이 없음
- $E_{c}$에 phoneme sequence만 제공하면 $E_{c}$는 content information $z_{c}$만 전달할 수 있음
- $z_{c}, z_{t}$ information은 available 하므로 prosody encoder $E_{p}$는 information bottleneck $B(\cdot)$으로 인해 information이 손실되는 경우, fine-grained content와 timbre를 removing 하는 것을 prioritze 함
- 여기서 bottleneck으로 인해 $E_{p}(y_{t})$는 다른 encoder가 제공할 수 없는 fine-grained prosodic style $z_{p}$만을 전달하여 decomposition을 수행할 수 있음
- $Y=\{y_{1},...,y_{n}\}$을 certain speaker $S$에 대한 speech corpus라고 하자
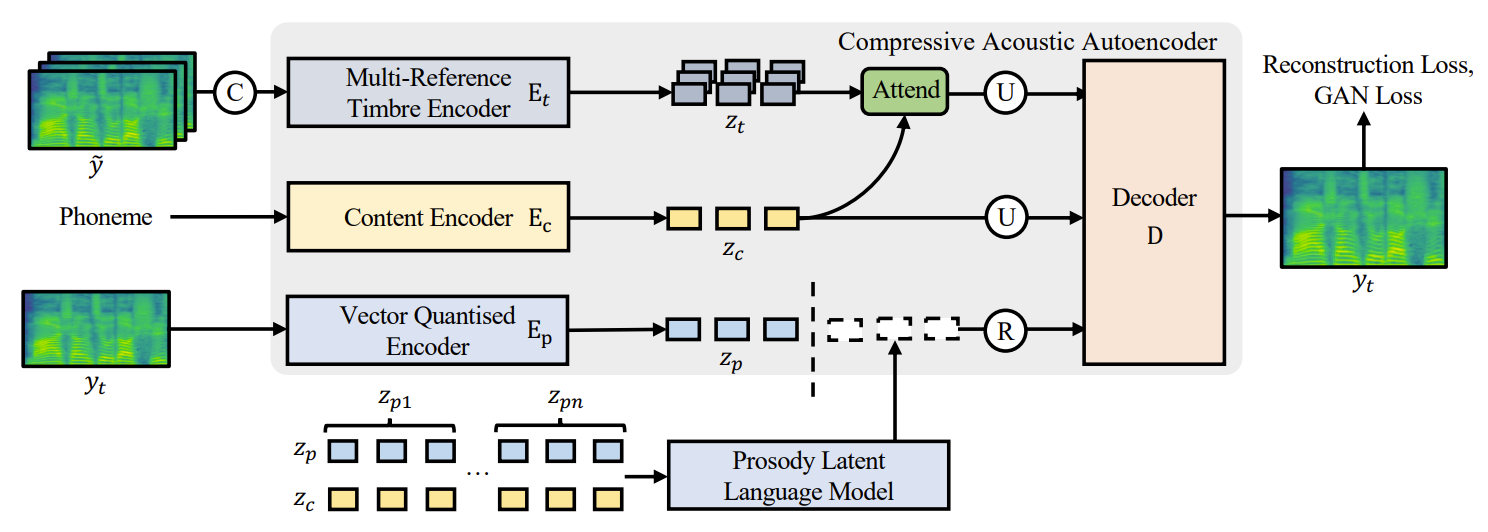
- Compressive Acoustic Autoencoder
- 다양한 speaker에 대한 timbre information을 store 하기 위해서는 많은 codebook entry가 필요함
- 앞서 prosody, timbre는 decompose 되었으므로 prosody $z_{p}$는 compact codebook으로 comrpess 될 수 있고, timbre information $z_{t}$는 powerful speaker encoder로 추출될 수 있음
- 해당 decomposition strategy를 통해 Mega-TTS2는 long prosody prompt를 accomdate 할 수 있고, 생성된 음성의 prosodic style을 control 할 수 있음 - 이를 위해 논문은 vector-quantized (VQ) encoder $E_{p}$, multi-reference timbre encoder (MRTE) $E_{t}$, content encoder $E_{c}$를 도입
- 특히 $E_{p}$는 prosodic variance information을 capture 하고, GAN-based mel-spectrogram decoder $D$를 채택해 spectrogram의 high-frequency detail을 모델링함
- 전체적으로 first-stage training loss는 $\mathcal{L}=\mathcal{L}_{rec}+\mathcal{L}_{VQ}+\mathcal{L}_{adv}$로 formulate 됨
- $\mathcal{L}_{rec}=||y_{t}-\hat{y}_{t}||^{2}$ : reconstruction loss, $\mathcal{L}_{VQ}$ : VQ codebook loss, $\mathcal{L}_{adv}$ : LSGAN-styled adversarial loss - 추가적으로 content encoder는 FastSpeech2를 따라 feed-forward transformer layer로 구성됨
- 앞서 prosody, timbre는 decompose 되었으므로 prosody $z_{p}$는 compact codebook으로 comrpess 될 수 있고, timbre information $z_{t}$는 powerful speaker encoder로 추출될 수 있음
- Vector Quantized Encoder
- VQ encoder $E_{p}$는 2개의 convolution stack과 vector quantization bottleneck으로 구성됨
- First convolution stack은 mel-spectrogram을 length $r$의 factor로 hidden state로 compress 하고, second stack은 feature correlation을 capture 함
- 이후 vector quantization layer는 해당 hidden state를 사용하여 prosody code $\mathbf{u}=\{u_{1},u_{2},...,u_{n}\}$과 hidden state $z_{p}$를 얻음
- VQ encoder의 information bottleneck $B(\cdot)$은 temporal compression, vector quantization layer로 구성됨
- VQ encoder $E_{p}$는 2개의 convolution stack과 vector quantization bottleneck으로 구성됨
- Multi-Reference Timbre Encoder (MRTE)
- Mega-TTS2는 multi-sentence speech prompt에서 fine-grained timbre information을 추출하는 것을 목표로 함
- Speaker는 speaking habit이나 semantic meaning에 따라 timbre를 변경할 수 있으므로, timbre encoder는 speaker habit을 나타낼 수 있는 multiple prompt에서 fine-grained information을 추출해야 함 - 이를 위해 논문은 MRTE를 도입
- 먼저 target speaker에 속하지만 target mel-spectrogram과는 다른 reference mel-spectrogram $\tilde{y}$를 concatenate 함
- 이후 mel-encoder는 concatenated mel-spectrogram을 length $d$의 factor만큼 acoustic hidden state $z_{t}$로 compress 함
- 다음으로 speech prompt에서 semantically relevant timbre information을 추출하는 timbre-to-content attention module을 도입함
- 해당 module은 $z_{c}$를 query로 $z_{t}$를 key/value로 사용 - 최종적으로 length regulator를 사용하여 target mel-spectrogram의 length와 일치하도록 timbre-to-content attention module의 output을 upsampling 함
- Mega-TTS2는 multi-sentence speech prompt에서 fine-grained timbre information을 추출하는 것을 목표로 함

- Prosody Latent Language Model
- Prosody Latent Language Model (P-LLM)은 multi-sentence prompt에서 speaker prosodic pattern을 효과적으로 capture 하는 것을 목표로 함
- Second-stage training process에서
- 먼저 compressed prosody hidden state $\{z_{p1},z_{p2},...,z_{pn}\}$을 추출
- 이후 compressive acoustic autoencoder를 사용하여 target speaker의 multiple speech clip $\{s_{1}, s_{2},...,s_{n}\}$에서 content hidden state $\{z_{c1},z_{c2}, ...,z_{cn}\}$을 추출
- 다음으로 time axis를 따라 concatenate 하여 $z'_{p}=\text{Concat}(z_{p1},z_{p2},...,z_{pn})$과 $z'_{c}=\text{Concat}(z_{c1},z_{c2},...,z_{cn})$을 구성
- 이때 temporal dimension에서 $z'_{p}, z'_{c}$의 length를 match 하기 위해 duration information $z_{d}$를 사용하여 $z'_{c}$를 frame-level로 expand 하고 max pooling layer를 사용하여 $r$배로 compress 함 - 최종적으로 $z'_{p}$를 prosody code $\mathbf{u}'$으로 변환한 다음, $z'_{c}$를 P-LLM에 전달하여 autoregressive manner로 prosody code를 예측함:
(Eq. 2) $p(\mathbf{u}' | z'_{c};\theta)=\prod_{l=0}^{L}p(\mathbf{u}'_{l} | \mathbf{u}'_{<l},z'_{c};\theta)$
- $\theta$ : P-LLM의 parameter, $L$ : concatenated prosody code $\mathbf{u}'$의 length
- Training 시에는 batch size를 1로 설정하여 각 batch의 prosody code 수 $m$을 최대한 증가시킴
- Single speaker의 총 speech frame 수가 $m\times r$보다 작으면 해당 batch에 다른 speaker sample을 포함하고, speaker-level attention mask를 추가하여 P-LLM에 전달함 - Mega-TTS2는 cross-entropy loss가 있는 teacher-forcing technique을 통해 concatenate 된 speech sample을 사용하여 language model을 training 함
- 이때 transition area 문제를 회피하기 위해, 각 sentence에 start/end token을 할당하여 P-LLM이 current sentence를 continue 하고 previous sentence에서 useful information을 추출하도록 guide 함
- 이를 통해 multi-sentence prompt에서도 prosody-level information을 capture 할 수 있음 - 추론 시에는 reference speech clip을 concatenate 하여 prompt length를 extending 함으로써 생성 품질을 향상 가능함
- 이때 transition area 문제를 회피하기 위해, 각 sentence에 start/end token을 할당하여 P-LLM이 current sentence를 continue 하고 previous sentence에서 useful information을 추출하도록 guide 함
- 추가적으로 duration modeling을 위해 phoneme-level autoregressive duration model을 채택함
- 해당 model은 autoregressive model의 powerful in-context learning capability를 활용해 duration modeling을 향상할 수 있음
- Autoregressive duration model의 전체 architecture는 P-LLM과 동일하지만, Mean Squared Error (MSE) loss를 통해 최적화됨
- Second-stage training process에서
- Prosody Interpolation
- 논문은 추가적으로 timbre reconstruction 품질을 보장하면서 discrete space에서 target speaker의 prosodic style을 control 하거나 replace 하는 prosody interpolation을 도입
- 이를 위해 multiple speaker로부터 얻어지는 multiple P-LLM output의 probability를 interpolate 함
- e.g.) Target speaker가 sad speaking tone을 가지고 있을 때, 해당 timbre를 유지하면서 happier speech를 생성하는 것을 목표로 한다고 하자
- 그러면 먼저 다른 speaker의 happy tone speech에서 prosody latent $\mathbf{u}_{a}$를 추출하고 target speech prompt에서 sad prosody latent $\mathbf{u}_{b}$를 추출하고,
- 이후 prosodic prompt $\mathbf{u}_{a}, \mathbf{u}_{b}$를 사용하여 target prosody code $\hat{\mathbf{u}}$을 separately decode 하는 2개의 language model을 적용
- 해당 language model은 동일한 parameter를 share 함
- 결과적으로 decoding process의 모든 timestep $t$에서 두 language model의 probability distribution은 weight $\gamma$로 interpolate 됨:
(Eq. 3) $p(\hat{\mathbf{u}})=\prod_{t=0}^{T}\left( (1-\gamma)\cdot p(\hat{\mathbf{u}} | \hat{\mathbf{u}}_{<t},\mathbf{u}_{b},\text{Concat}(z_{cb},\hat{z}_{c});\theta)+ \gamma\cdot p(\hat{\mathbf{u}}_{t}|\hat{\mathbf{u}}_{<t},\mathbf{u}_{a},\text{Concat}(z_{ca},\hat{z}_{c});\theta) \right)$
- $z_{cb},z_{ca}$ : 각각 speech clip $s_{b}, s_{a}$의 content information
- $\hat{z}_{c}$ : target sentence의 content information - 해당 prosody interpolation을 사용하면, 추론 시 생성되는 prosodic style을 freely control 할 수 있음
- 추가적으로 해당 prosody interpolation algorithm은 prosody transfer를 위해 language model의 autoregressive probability distribution을 활용함
- 결과적으로 time-averaged prosody representation $\mathbf{u}_{b}$를 $\mathbf{u}_{a}$로 대체하는 기존 방식과 비교하여, P-LLM은 autoregressive process를 통해 $\mathbf{u}_{a},\mathbf{u}_{b}$를 soft, fine-grained manner로 mix 할 수 있음

3. Experiments
- Settings
- Dataset : LibriLight
- Comparisons : VALL-E
- Results
- Results of Zero-Shot Speech Synthesis
- 전체적인 성능 측면에서 Mega-TTS2가 가장 우수한 합성 성능을 달성함
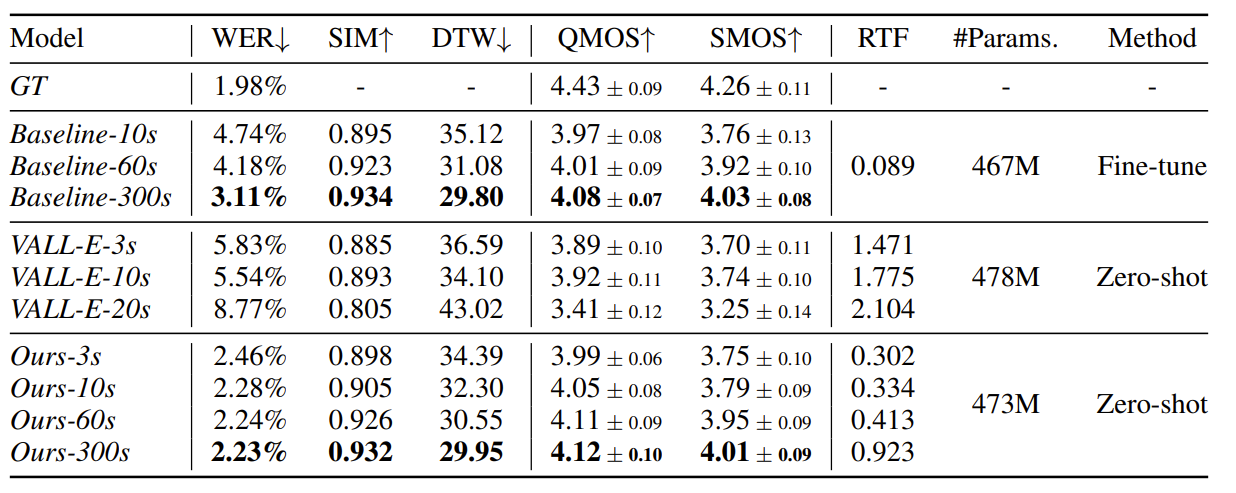
- 추가적으로 Mega-TTS2는 낮은 WER을 유지하면서 speaker similarity를 향상할 수 있음

- Results of Prosody Transfer
- Prosody transfer 측면에서도 Mega-TTS2는 기존보다 뛰어난 성능을 달성함

- Prosody transfer 적용 전/후를 살펴보면, Mega-TTS2는 transfer 된 각 dataset의 분포를 효과적으로 반영할 수 있음

- Ablation Study - Prosody and Timbre Prompt
- MRTE, P-LLM에 대한 prompt length를 비교해 보면, timbre prompt가 길어질수록 SIM score와 음성 품질이 증가함
- Prosody prompt의 legnth를 늘리면 speaker similarity를 유지하면서 DTW distance가 감소함

- Ablation Study - VQ Encoder and MRTE
- MRTE, VQ Encoder를 제거하는 경우 성능 저하가 발생함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글