

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] SoundStorm: Efficient Parallel Audio Generation
feVeRin 2024. 4. 26. 09:49반응형
SoundStorm: Efficient Parallel Audio Generation
- Efficient, non-autoregressive audio generation을 위한 neural codec이 필요함
- SoundStorm
- AudioLM의 semantic token을 input으로 receive 하고 bidrectional attention과 confidence-based parallel decoding을 사용하여 neural audio codec token을 생성
- Autoregressive 방식과 비교하여 2배의 속도 향상 효과와 고품질의 audio 합성이 가능
- 논문 (Google Research 2023) : Paper Link
1. Introduction
- Neural codec을 통해 생성된 audio의 discrete representation을 모델링하여 고품질의 audio를 생성할 수 있음
- BUT, 고품질 audio를 생성하기 위해서는 discrete representation의 rate를 늘려야 하므로, codebook size가 exponential 하게 증가하고 token sequence가 길어짐
- 결과적으로 exponential 하게 증가한 codebook size는 memory 문제를 발생시키고, 긴 token sequence는 autoregressive 모델에 대한 계산 문제가 발생함
- 특히 attention-based model의 경우, sequence length와 관련하여 quadratic runtime complexity가 필요함
- 따라서 perceptual quality와 runtime 간의 trade-off를 해결하는 것은 중요한 과제임 - 이때 long-sequence audio modeling을 위해 audio token sequence의 특수한 구조를 활용할 수 있음
- 대표적으로 SoundStream과 EnCodec은 Residual Vector Quantization (RVQ)를 활용함
- 이를 통해 hierarchical token structure를 유도함으로써 token sequence의 joint distribution에 대한 근사와 효율적인 factorization이 가능
-> 그래서 long audio token sequence에 대한 특수한 input structure를 활용해 효율적이고 고품질의 합성이 가능한 SoundStorm을 제안
- SoundStorm
- Audio token의 hierarchical structure에 적합한 architecture를 적용하고, MaskGIT을 기반으로한 parallel, non-autoregressive, confidence-based decoding scheme을 도입하여 RVQ token sequence를 처리
- 구조적으로,
- AudioLM의 semantic token과 같은 conditioning signal이 주어지면, masked audio token을 예측하도록 training 된 bidirectional attention-based Conformer를 활용
- Input 측면에서는 SoundStream frame에 해당하는 token의 embedding을 summation 하여 사용
- 여기서 self-attention의 internal sequence length는 SoundStream의 frame 수와 동일하고 RVQ의 quantizer 수에 따라 달라짐 - 이후 output embedding은 RVQ level 별로 개별적인 head에 의해 process되어 masked target token을 예측
- 추론 시에는 conditioning signal이 주어지면, SoundStorm은 masked token RVQ를 여러 iteration에 걸쳐 token을 parallel 하게 예측
- 이를 위해 추론 procedure를 mimic하는 masking scheme을 training에 적용
< Overall of SoundStorm >
- AudioLM의 semantic token을 input으로 receive 하고 bidrectional attention과 confidence-based parallel decoding을 사용하여 neural audio codec token을 생성
- 결과적으로 autoregressive로 동작하는 AudioLM과 비교하여 2배의 속도 향상 효과와 고품질의 audio 합성이 가능
2. Method
- SoundStorm은 conditioning signal을 represent 하는 discrete token sequence를 input으로 receive 한 다음, audio waveform으로 decoding이 가능한 token sequence를 output으로 생성함
- 여기서 conditioning signal이 SoundStream frame과 time-align되어 있거나 동일한 rate로 upsampling 된다고 가정
- 해당 conditioning signal은 AudioLM, MusicLM 등에서 사용되는 semantic token sequence와 같음 - SoundStorm은 AudioLM의 coarse/fine acoustic modeling stage에 대한 acoustic generator를 대체하는 것을 목표로 함
- 여기서 conditioning signal이 SoundStream frame과 time-align되어 있거나 동일한 rate로 upsampling 된다고 가정
- Architecture
- SoundStorm의 architecture는
- 먼저 input side에서는 time-aligned conditioning token을 frame level SoundStream token과 함께 interleave 하고,
- Resulting sequence를 embed 한 다음, 동일한 frame에 해당하는 embedding을 summation 함
- 이후 conditioning token embedding을 추가하고, 얻어지는 continuous embedding을 Conformer에 전달
- 결과적으로 Conformer의 bidirectional self-attention의 sequence length는 SoundStream의 frame 수에 의해 결정됨
- 따라서 RVQ level 수 $Q$와는 무관하게 분(minute) 단위의 length로 audio를 처리할 수 있음 - Output side에서는 $Q$ dense layer를 head로 사용하여 target SoundStream token을 생성함
- 먼저 input side에서는 time-aligned conditioning token을 frame level SoundStream token과 함께 interleave 하고,

- Masking
- MaskGIT의 masking과 confidence-based parallel decoding scheme을 RVQ에서 생성된 token sequence로 확장함
- 이는 RVQ level 별로 coarse-to-fine order로 정렬되는 것으로 볼 수 있음
- 이러한 coarse-to-fine order는 RVQ hierarchy level 간의 conditional dependency를 respect 하면서, coarser level의 모든 token이 주어진 경우에 대해 finer level token의 conditional independence를 활용할 수 있음
- 이때 finer level의 token은 local, fine acoustic detail을 담당하므로 audio 품질의 loss 없이 parallel 하게 sampling을 수행 가능함 - Masking scheme 설계를 위해, 먼저 voice prompting에 대하여 time step $t\in\{1,...,T\}$에서 random sampling을 수행하자
- 해당 time step 이전에 대해서는 어떠한 token도 masking 하지 않고 conditioning token에 대해서도 mask 하지 않음
- $T$ : maximum sequence length - 그리고 $Y\in \{1,...,C\}^{T\times Q}$를 SoundStream token, $C$를 $Q$ level의 각 RVQ에서 사용되는 codebook size라고 했을 때, SoundStorm의 masking scheme은 다음과 같이 수행됨:
- Time step $t\sim \mathcal{U}\{0,T-1\}$에서 prompt delimiter를 sampling
- Current RVQ level $q\sim\mathcal{U}\{1,Q\}$를 sampling
- Level $q$에 대해 cosine schedule에 따라 mask $M\in \{0,1\}^{T}$를 sampling
- 즉, $u\sim\mathcal{U}[0,\pi/2]$에서 masking ratio $p=\cos(u)$를 sampling 하고, $i.i.d.$ $M_{i}\sim \mathrm{Bernoulli}(p)$를 sampling 함 - Current RVQ level $q$에서 select 된 non-prompt token을 mask 함 ($M'_{t}=1, t'>t$인 경우, $Y_{t',q}$를 mask)
- 그리고 finer RVQ level ($Y_{>t, >q}$)의 모든 non-prompt token도 mask 함
- Masked token sequence가 주어지면, ground-truth token을 target으로 사용하여 cross-entropy loss로 모델을 training 할 수 있음
- 이때 loss는 $q$-th RVQ level 내의 masked token에 대해서만 계산됨
- 논문에서는 $T=4, Q=3, t=0, q=2$로 설정
- 이는 RVQ level 별로 coarse-to-fine order로 정렬되는 것으로 볼 수 있음
- Iterative Parallel Decoding
- SoundStorm의 decoding scheme은 conditioning signal이 주어졌을 때, prompt token을 제외한 모든 SoundStream token이 mask 된 상태로 시작함
- 이후 coarse-to-fine order로 RVQ level-wise token sampling을 수행
- 이때 level $1,...,q$에 대한 모든 token이 sampling 된 경우에만 level $q+1$로 넘어감 - RVQ level 내에서는 confidence-based sampling scheme을 사용함
- Multiple forward pass를 수행하고, 각 iteration $i$에서 masked position에 대한 candidate를 sampling 하여 confidence score를 기반으로 $p_{i}$를 retaining 함
- 여기서 $p_{i}$는 cosine schedule을 따름 - 추가적으로 각 RVQ level 내의 마지막 iteration에 대해 confidence-based sampling 대신 greedy encoding을 사용하면 audio 품질을 향상할 수 있음
- 한편으로, level-wise RVQ decoding을 통해 finer level에서 conditional independence assumption을 활용할 수 있음
- 즉, multiple finer token은 local, fine acoustic detail을 represent 하므로 parallel 하게 sampling 가능함
- 이를 통해 decoding 중에 finer RVQ level로 진행함으로써 forward pass 수를 크게 줄일 수 있음
- 이후 coarse-to-fine order로 RVQ level-wise token sampling을 수행
3. Experiments
- Settings
- Dataset : LibriSpeech
- Comparisons : AudioLM
- Results
- Speech Intelligibility, Audio Quality, Voice Preservation, Acoustic Consistency
- Speech intelligibility 측면에서 SoundStorm은 prompted/unprompted scenario 모두에서 AudioLM 보다 우수한 성능을 보임
- Voice preservation 측면에서도 SoundStorm은 AudioLM 보다 더 나은 cosine similarity를 보임
- Consistency drift 측면에서 SoundStorm은 AudioLM에 비해 긴 audio sample에 대해서도 우수한 성능을 유지함
- MOS 측면에서도 SoundStorm이 가장 좋은 품질을 보임

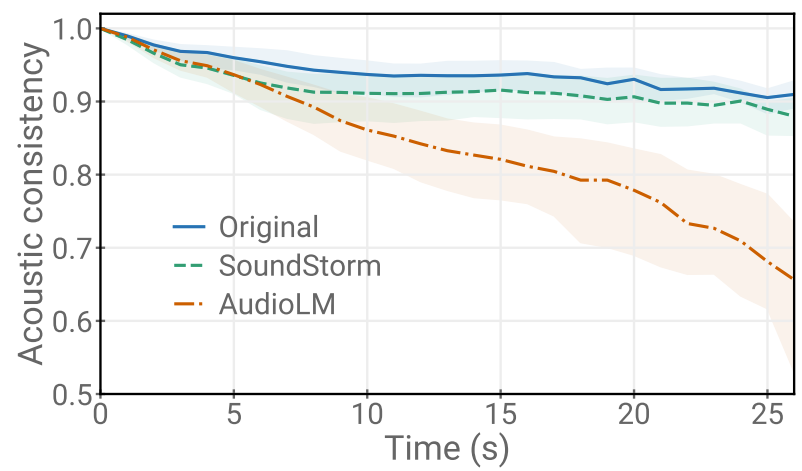
- 추가적으로 acoustic consistency drift에 대한 embedding의 cosine similarity를 확인해 보면
- SoundStorm으로 생성된 audio의 경우 original sample과 가까운 consistency score를 보이지만,
- AudioLM의 결과는 time이 지남에 따라 상당한 drift가 발생하는 것으로 나타남
- Runtime
- Single TPU-v4에서 30초 audio 생성에 걸리는 runtime을 측정해 보면
- SoundStorm은 0.017의 RTF로 AudioLM 보다 2배 빠르게 합성이 가능함

- Ablation Study
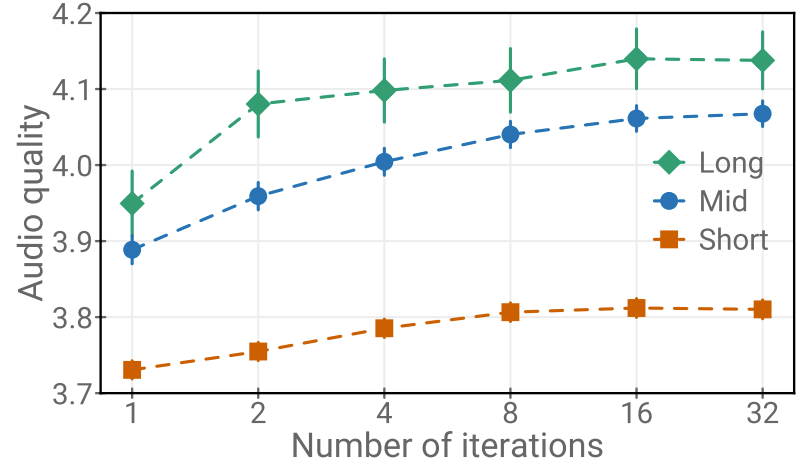
- 다양한 RVQ level에 대한 decoding iteration 횟수의 영향을 확인해 보면
- Level-wise greedy decoding을 기반으로 16번의 iteration을 수행하면 최적의 품질을 얻을 수 있음
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글