
티스토리 뷰
Paper/Vocoder
[Paper 리뷰] FreeV: Free Lunch for Vocoders through Pseudo Inversed Mel Filter
feVeRin 2024. 6. 28. 09:31반응형
FreeV: Free Lunch for Vocoders through Pseudo Inversed Mel Filter
- Frequent-domain GAN vocoder는 우수한 합성 품질을 달성했지만, 상당한 parameter size로 인해 memory burden이 존재함
- FreeV
- Pseudo-Inverse를 통해 amplitude spectrum을 roughly initialization 하여 vocoder의 parameter demand를 크게 줄임
- Stream-lined amplitude prediction branch를 통해 추가적인 추론 속도 향상을 달성
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Vocoder는 speech acoustic feature를 waveform을 변환하는 역할을 수행함
- 대부분의 vocoder는 frequency-domain에서 amplitude/phase spectra를 예측한 다음, inverse STFT (iSTFT)를 통해 waveform을 reconstruction 하는 방식을 사용함
- 이때 해당 방식들은 extensive time-domain waveform prediction을 회피해 computation burden을 줄임
- 한편으로 diffusion-based vocoder는 signal processing insight를 결합해 뛰어난 reconstruction 성능을 보이고 있음
- PriorGrad는 covariance matrix의 diagonal을 mel-spectrogram의 frame 별 energy와 align 하는 방식을 사용함
- SpecGrad는 이를 확장하여 dynamic spectral characteristic을 conditioning mel-spectrogram과 align 함
- GLA-Grad의 경우, estimated amplitude spectrum을 diffusion step의 post-processing stage에 embedding 하여 reconstruction 성능을 향상함
- BUT, diffsuion-based vocoder의 경우 우수한 합성 품질에 비해 추론 속도가 상당히 느리다는 한계점이 있음
-> 따라서 빠른 속도와 적은 parameter를 사용하면서 고품질의 음성 합성을 지원하는 FreeV를 제안
- FreeV
- Mel-spectrogram의 product와 Mel-filter의 pseudo-inverse를 input으로 사용하여 complexity를 크게 완화
- Pseudo-amplitdue spectrum을 활용한 spectral prediction branch를 통해 합성 품질을 저해하지 않으면서 parameter 수와 추론 속도를 크게 줄임
< Overall of FreeV >
- Pseudo-inverse technique과 stream-lined GAN을 활용한 lightweight vocoder
- 결과적으로 기존 vocoder 수준의 합성 품질을 유지하면서 추론 속도를 상당히 개선

2. Related Work
- PriorGrad & SpecGrad
- PriorGrad는 DDPM process를 통해 waveform을 reconstruction 하는 diffusion-based vocoder인 WaveGrad를 기반으로 함
- 이때 PriorGrad는 input mel-spectrogram $X$에서 계산되는 $\Sigma$를 활용해 adaptive prior $\mathcal {N}(0,\Sigma)$를 구성함
- $\Sigma$ : covariance matrix로써, $\Sigma=\text{diag}[(\sigma_{1}^{2}, \sigma_{2}^{2}, .., \sigma_{D}^{2})]$
- $\sigma_{d}^{2}$ : $d$-th sample에서의 signal power로써, frame energy를 interpolate 하여 얻어짐 - 기존의 DDPM-based vocoder와 비교하여, PriorGrad는 source distribution을 target distribution에 더 가깝게 만들기 위해 prior signal을 통해 reconstruction task를 simplify 함
- $\Sigma$ : covariance matrix로써, $\Sigma=\text{diag}[(\sigma_{1}^{2}, \sigma_{2}^{2}, .., \sigma_{D}^{2})]$
- SpecGrad는 PriorGrad를 기반으로 dynamic spectral characteristic을 conditioning mel-spectrogram과 align 하는 방식으로 diffusion noise를 adjust 함
- 이때 SpecGrad는 mel-spectrogram 기반의 T-F domain filtering을 활용하여 decomposed covariance matrix와 해당 근사 inverse를 유도함
- 즉, STFT를 matrix $G$라고 하고 iSTFT를 matrix $G^{+}$라고 했을 때, time-varying filter $L$은:
(Eq. 1) $L=G^{+}DG$
- $D$ : diagonal matrix로써 spectral envelope로 얻어짐 - 그러면 diffusion process에서 standard Gaussian noise $\mathcal{N}(0,\Sigma)$의 covariance matrix $\Sigma=LL^{\top}$으로 얻어짐
- 결과적으로 SpecGrad는 더 정확한 prior를 도입함으로써 고품질의 reconstruction이 가능
- 이때 SpecGrad는 mel-spectrogram 기반의 T-F domain filtering을 활용하여 decomposed covariance matrix와 해당 근사 inverse를 유도함
- 이때 PriorGrad는 input mel-spectrogram $X$에서 계산되는 $\Sigma$를 활용해 adaptive prior $\mathcal {N}(0,\Sigma)$를 구성함
- APNet & APNet2
- APNet과 APNet2는 Amplitude Spectra Predictor (ASP)와 Phase Spectra Predictor (PSP)를 활용하여 구성됨
- 각 component는 amplitude와 phase를 개별적으로 예측한 다음, iSTFT를 통해 waveform을 reconstruction 함
- 특히 APNet2는 ConvNeXtV2 block을 사용하여 구성되고, PSP branch에 대해서 parallel phase estimation architecture를 활용함 - Parallel phase estimation은 pseudo-imarginary part $I$와 real part $R$로 두 convolution layer의 output을 취한 다음, (Eq. 2)를 통해 phase spectra를 계산함:
(Eq. 2) $\arctan\left(\frac{I}{R}\right)-\frac{\pi}{2}\cdot \text{sgn}(I)\cdot [\text{sgn}(R)-1]$
- $\text{sgn}$ : sign function - 여기서 loss는 HiFi-GAN에서 사용한 mel-loss $\mathcal{L}_{mel}$, generator loss $\mathcal{L}_{g}$, discriminator loss $\mathcal{L}_{d}$, feature matching loss $\mathcal{L}_{fm}$을 포함하여 다음의 term들을 추가하여 얻어짐
- Amplitude spectrum loss $\mathcal{L}_{A}$ : predicted/real amplitude 간의 $L2$ distance
- Phase spectrogram loss $\mathcal{L}_{P}$ : instantaneous phase loss, group delay loss, phase time difference loss의 합
- 이때 모든 phase spectrogram은 anti-wrap 됨 - STFT spectrogram loss $\mathcal{L}_{S}$ : STFT consistency loss와 predicted/real STFT spectrogram 간의 $L1$ loss
- 각 component는 amplitude와 phase를 개별적으로 예측한 다음, iSTFT를 통해 waveform을 reconstruction 함
3. Method
- Amplitude Prior
- FreeV는 real prediction target인 amplitude spectrum에 가까운 prior signal을 얻는 것을 목표로 함
- 즉, 주어진 mel-spectrogram $X$와 known Mel-filter $M$이 있을 때, 다음과 같이 actual amplitude spectrum $A$에 대한 distance를 최소화하는 estimated amplitdue spectrum $\hat{A}$는 다음과 같이 얻어짐:
(Eq. 3) $\min || \hat{A}M-A||_{2}$ - 이때 앞선 SpecGrad의 $G^{+}DG\epsilon$은 input으로 prior noise $\epsilon$을 요구하므로 적합하지 않음
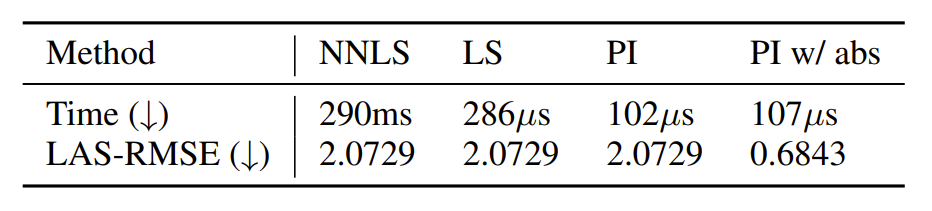
- 특히 Librosa를 통한 $\hat{A}$ 추정은 non-negativity를 위해 Non-Negative Least Square (NNLS)를 사용하고, multiple iteration이 요구되므로 속도가 상당히 느림
- 추가적으로 TorchAudio 역시 singular least squares를 통해 amplitude spectrum을 추정하고 iterative calculation을 적용하므로 FreeV의 속도 향상에 비효율적임
- 한편으로 Mel-filter $M$이 calculation 전반에 걸쳐 unchange된 상태로 유지된다는 점을 고려하면, pseudo-inverse $M^{+}$를 pre-compute할 수 있음
- 이후 amplitdue spectrum의 non-negativity를 보장하고 training stability를 보장하기 위해 근사 amplitude spectrum 값에 $10^{-5}$의 lower bound를 적용함 - 여기서 FreeV는 아래 그림의 (b)와 같이 pseudo-inversed Mel-filter에서 나타나는 negative block을 줄이기 위해, $M^{+}$와 $X$의 product에 대해 $\text{Abs}$ function을 적용하여 근사 amplitude spectrum $\hat{A}$를 얻음:
(Eq. 4) $\hat{A}=\max (\text{Abs}(M^{+}X), 10^{-5})$
- 즉, 주어진 mel-spectrogram $X$와 known Mel-filter $M$이 있을 때, 다음과 같이 actual amplitude spectrum $A$에 대한 distance를 최소화하는 estimated amplitdue spectrum $\hat{A}$는 다음과 같이 얻어짐:

- Model Structure
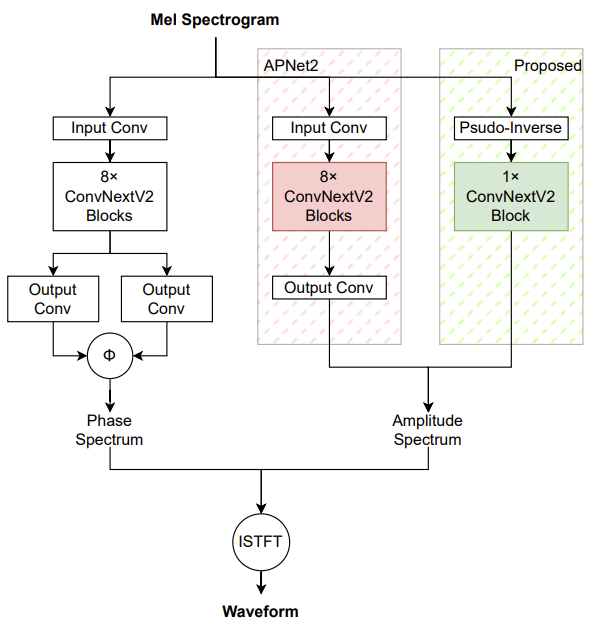
- FreeV는 PSP와 ASP로 구성되고, ConvNeXtV2를 basic block으로 사용함
- 먼저 PSP는 input convolution layer, 8개의 ConvNeXtV2 block, parallel phase estimation을 위한 2개의 convolution layer로 구성됨
- ASP는 APNet2와 달리 input convolution layer를 frozen parameter를 가지는 Mel-filter $M$의 pre-computed pseudo-inverse Mel-filter $M^{+}$로 대체됨
- 이를 통해 ConvNeXtV2 block의 사용을 8개에서 1개로 줄일 수 있으므로, FreeV는 parameter size와 computation time을 크게 개선 가능함 - 이때 ConvNeXtV2 block의 input-output dimension은 amplitude spectrum의 dimension과 align되도록 tailor됨
- 이를 통해 ASP module은 estimated amplitude spectrum과 ground-truth 간의 residual을 exclusively modeling할 수 있음 - 결과적으로 ConvNeXtV2 module의 input-output dimension이 amplitdue spectrum과 일치하므로 ASP에서 output convolution layer를 제거할 수 있고, paramter 수를 더욱 줄일 수 있음
- Training Criteria
- MPD와 MRD를 discriminator로 사용하고 adversarial training을 위한 loss로써 hinge GAN loss를 사용함
- 이때 generator와 discriminator의 loss function은:
(Eq. 5) $\mathcal{L}_{Gen}=\lambda_{A}\mathcal{L}_{A}\mathcal{L}_{Gen}=\lambda_{A}\mathcal{L}_{A}+ \lambda_{P}\mathcal{L}_{P}+ \lambda_{S}\mathcal{L}_{S}+ \lambda_{W}(\mathcal{L}_{mel}+\mathcal{L}_{fm}+\mathcal{L}_{g}) $
(Eq. 6) $\mathcal{L}_{Dis}=\mathcal{L}_{d}$
- $\lambda_{A}, \lambda_{P},\lambda_{S},\lambda_{W}$ : weight
- 이때 generator와 discriminator의 loss function은:
4. Experiments
- Settings
- Results
- Computational Efficiency of Prior
- FreeV는 estimated amplitude spectra $\hat{A}$의 computation cost를 줄이는 것을 목표로 함
- LS : Least Square, PI : Pseudo-Inverse - 결과적으로 pseudo-inverse method는 $\hat{A}$를 가장 빠르게 계산할 수 있음
- 추가적으로 $\text{Abs}$ function을 통한 amplitude spectrogram estimation error를 크게 줄일 수 있음
- FreeV는 estimated amplitude spectra $\hat{A}$의 computation cost를 줄이는 것을 목표로 함
- Model Convergence
- (a), (b)와 같이 amplitude spectrum branch의 parameter가 줄어들어도 관련 loss는 APNet 보다 낮게 유지됨
- 추가적으로 amplitude spectrum loss는 (c)와 같이 phase-time difference loss에도 영향을 줌

- Mel-spectrogram input을 estimated amplitude spectrum $\hat{A}$로 대체하는 경우, early-stage convergence를 향상할 수 있음

- Model Performance
- 전체적인 모델 성능 비교에서도 FreeV가 가장 우수한 결과를 달성함
- 특히 $\hat{A}$를 각 vocoder에 적용하는 경우, 성능 개선 효과를 얻을 수 있는 것으로 나타남

- 추론 속도 측면에서도 FreeV는 Vocos 수준의 빠른 합성 속도를 보임

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글