

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] GLA-Grad: A Griffin-Lim Extended Waveform Generation Diffusion Model
feVeRin 2024. 5. 9. 11:05반응형
GLA-Grad: A Griffin-Lim Extended Waveform Generation Diffusion Model
- Diffusion model은 diffusion process로 인한 비효율성이 존재하고 unseen speaker에 대한 고품질 합성이 어려움
- GLA-Grad
- Conditioning error를 최소화하면서 diffusion process의 효율성을 향상하기 위해 diffusion process의 각 step에 Griffin-Lim algorithm을 도입
- 이를 통해 추가적인 training이나 fine-tuning 없이 already-trained waveform generation model에 직접 적용 가능
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- 고품질 음성 합성을 위한 vocoder로써 normalizing flow, generative adversarial network (GAN) 등의 다양한 방법들이 제시되고 있음
- Diffusion model은 differental equation을 solve 하기 위해 stochastic flow가 fixed noise schedule에 의해 관리되는 generative model임
- 대표적으로 WaveGrad, DiffWave, PriorGrad 등은 diffusion model을 음성 합성에 적용하여 우수한 성능을 달성 - BUT, diffusion model은 stability를 보장하기 위해 large dataset에서 상당한 iteration을 필요로 하므로 효율성이 떨어짐
- 이를 위해 FastDiff는 noise schedule을 dynamically predict하여 iteration 수를 줄이는 방법을 제시했음 - 이외에도 diffusion model은 speech signal의 다양성으로 인해 unseen scenario에서 generalization 성능이 떨어짐
- Diffusion model은 differental equation을 solve 하기 위해 stochastic flow가 fixed noise schedule에 의해 관리되는 generative model임
-> 그래서 diffusion model의 효율성을 향상하면서 unseen scenario에 대한 generalization을 보장할 수 있는 GLA-Grad를 제안
- GLA-Grad
- Reverse process iteration 중에 mel-spectrogram의 conditioning error를 rectify 하는 것을 목표로 WaveGrad를 확장
- Griffin-Lim Algorithm (GLA)를 활용하여 diffusion process에서 current sample의 STFT phase를 conditioning mel-spectrogram의 pseudo-inverse로 얻은 magnitude spectrogram과 partially reconcile 함
- 이를 통해 주어진 signal이 training dataset과 다른 경우에 대해서도 reverse process의 consistency를 보장
< Overall of GLA-Grad >
- Griffin-Lim Algorithm을 각 diffusion step에 적용하여 conditioning error를 최소화함
- 결과적으로 unseen scenario에 대한 우수한 generalization과 합리적인 추론 속도를 달성
2. Background
- DDPM
- $\mathbf{y}\sim q(\mathbf{y}_{0})$을 data sample이라고 하자
- Denoising Diffusion Probabilistic Model (DDPM)은 forward process에서 $\mathbf{y}_{0}$에 noise를 점진적으로 추가한 다음, reverse process를 통해 이를 recover 하는 방법을 학습함
- Forward process에서 각 time step $n\in [1,N]$의 $\mathbf{y}_{n}$은 $q(\mathbf{y}_{n}| \mathbf{y}_{n-1})=\mathcal{N}(\mathbf{y}_{n};\sqrt{1-\beta_{n}}\mathbf{y}_{n-1})$을 통해 얻어짐
- 여기서 $(\beta_{n})_{n}$ : variance schedule, $N$ : maximum time step 수라고 하면, 다음의 formulation을 얻을 수 있음:
(Eq. 1) $\mathbf{y}_{0}\sim q(\mathbf{y}_{0}),\,\,\, q(\mathbf{y}_{1:N}|\mathbf{y}_{0})\triangleq\prod_{n=1}^{N}q(\mathbf{y}_{n}|\mathbf{y}_{n-1})$ - $\alpha_{n}\triangleq 1-\beta_{n},\, \bar{\alpha}_{n}\triangleq \prod_{s=1}^{n}\alpha_{s}, \, \epsilon\sim\mathcal{N}(\epsilon;0,I)$라고 하면, $\mathbf{y}_{n}$은 주어진 time $n$에 대해 closed form으로 얻어짐:
(Eq. 2) $\mathbf{y}_{n}=\sqrt{\bar{\alpha}_{n}}\mathbf{y}_{0}+\sqrt{1-\bar{\alpha}_{n}}\epsilon$
- 여기서 $(\beta_{n})_{n}$ : variance schedule, $N$ : maximum time step 수라고 하면, 다음의 formulation을 얻을 수 있음:
- Reverse process에서는 $\mathbf{y}_{0}$를 reconstruct 하는 것을 목표로 함
- 여기서 $q(\mathbf{y}_{n-1}|\mathbf{y}_{n})$은 intractable 하기 때문에 neural network는 true denoising distribution과 match 되도록 training 됨
- 따라서 reverse process에 대한 equation은:
(Eq. 3) $p_{\theta}(\mathbf{y}_{0:N})\triangleq p(\mathbf{y}_{N})\prod_{n=1}^{N}p_{\theta}(\mathbf{y}_{n-1}|\mathbf{y}_{n})$
- $N$이 충분히 크다고 가정하면, $p_{\theta}(\mathbf{y}_{n-1}|\mathbf{y}_{n})$은 neural network에 의해 결정된 평균과 분산을 가지는 Gaussian distribution으로 모델링 됨
- 이때 $\theta$는 model parameter를 나타내고, $p(\mathbf{y}_{N})=\mathcal{N}(\mathbf{y}_{N};0,I)$
- 실질적으로 $\epsilon_{\theta}(\mathbf{y}_{n}, n)$으로 표현되는 neural network는 (Eq. 2)에서 $\mathbf{y}_{0}$에 추가된 noise를 추정하기 위해 parameterize 되어 다음의 training objective를 최소화함:
(Eq. 4) $\mathbb{E}_{n,\epsilon}\left[|| \epsilon_{\theta}\left( \sqrt{\bar{\alpha}_{n}}\mathbf{y}_{0}+\sqrt{1-\bar{\alpha}_{n}}\epsilon, n\right)-\epsilon||_{2}^{2}\right]$
- 결과적으로 이는 denoising score-matching과 유사
- WaveGrad
- WaveGrad는 DDPM을 기반으로 $\tilde{\mathbf{X}}$가 mel-spectrogram인 conditional diffusion process $p_{\theta}(\mathbf{y}_{0:n}|\tilde{\mathbf{X}})$를 사용하여 waveform을 합성
- 이때 $\tilde{\mathbf{X}}$를 conditioning factor로 고려하는 graident-based sampler를 사용한 iterative refinement process를 통해 Gaussian white noise signal를 점진적으로 개선함
- WaveGrad는 DDPM과 달리 discrete iteration index $n$ 대신 continuous noise level $\bar{\alpha}$를 condition으로 하여 model을 reparameterize 함
- 결과적으로 WaveGrad의 loss function은:
(Eq. 5) $\mathbb{E}_{\bar{\alpha},\epsilon}\left[\left|\left| \epsilon\left( \sqrt{\bar{\alpha}}\mathbf{y}_{0}+\sqrt{1-\bar{\alpha}}\epsilon,\tilde{\mathbf{X}},\sqrt{\bar{\alpha}}\right)-\epsilon \right|\right|_{1}\right]$
- $n>1$에서 $\mathbf{z}\sim\mathcal{N}(\mathbf{z},0,I)$이고, $n=1$일때 $\mathbf{z}=0, \sigma_{n}=\frac{1-\bar{\alpha}_{n-1}}{1-\bar{\alpha}_{n}}\beta_{n}$ - WaveGrad는 $\mathbf{y}_{n-1}$을 생성하기 위해 다음의 iterative procedure를 적용함:
(Eq. 6) $\mathbf{y}_{n-1}=\frac{\left(\mathbf{y}_{n}-\frac{1-\alpha_{n}}{\sqrt{1-\bar{\alpha}_{n}}}\epsilon_{\theta}\left(\mathbf{y}_{n},\tilde{\mathbf{X}},\sqrt{\bar{\alpha}_{n}}\right)\right)}{\sqrt{\alpha_{n}}}+\sigma_{n}\mathbf{z}$
- SpecGrad
- SpecGrad는 WaveGrad를 기반으로 dynamic spectral characteristic을 conditioning mel-spectrogram과 align 하는 방식으로 diffusion noise를 adjust 함
- Time-varying filtering을 통해 SpecGrad의 adaptation은 high-frequency region에 대한 fidelity를 크게 개선함
- 여기서 SpecGrad는 time-frequency domain 내에서 time-varying filter를 적용함 - 먼저 time-domain에서 time-frequency domain의 flattened version인 STFT의 matrix representation을 $\mathbf{T}$, inverse STFT (iSTFT) matrix를 $\mathbf{T}^{\dagger}$라고 하자
- 그러면 time-varying filter는:
(Eq. 7) $\mathbf{L}=\mathbf{T}^{\dagger}\mathbf{D}\mathbf{T}$
- $\mathbf{D}$ : time-frequency domain에서 filter를 결정하는 diagonal matrix로 spectral envelope를 통해 얻어짐 - 이후 $\mathbf{L}$로부터 diffusion process에서 Gaussian noise $\mathcal{N}(0,\Sigma)$의 covariance matrix $\Sigma=\mathbf{L}\mathbf{L}^{\top}$를 얻을 수 있음
- 결과적으로 loss function은:
(Eq. 8) $\mathbb{E}_{\bar{\alpha},\epsilon}\left[\left|\left| \mathbf{L}^{-1}\left(\epsilon\left( \sqrt{\bar{\alpha}}\mathbf{y}_{0}+\sqrt{1-\bar{\alpha}}\epsilon,\tilde{\mathbf{X}},\sqrt{\bar{\alpha}}\right)-\epsilon\right)\right|\right|_{2}^{2}\right]$
- 그러면 time-varying filter는:
- Time-varying filtering을 통해 SpecGrad의 adaptation은 high-frequency region에 대한 fidelity를 크게 개선함
3. Griffin-Lim Diffusion Extension
- Griffin-Lim Algorithm
- Griffin-Lim Algorithm (GLA)는 해당하는 magnitude와 가장 일치하는 phase를 추정하여 주어진 magnitude mel-spectrogram $\hat{\mathbf{S}}\in \mathbb{R}^{T\times F}$로부터 length $L$의 time-domain signal $s\in\mathbb{R}^{L}$을 iteratively reconstruct 하는 방법
- 먼저 $T, F$를 각각 time-frequency (TF) representation의 time/frequency dimension으로, STFT/iSTFT operation을 각각 $\mathbf{T}, \mathbf{T}^{\dagger}$라고 하자
- 이때 GLA는 complex time-frequency domain $\mathbf{C}^{T\times F}$에서 2가지의 projection operation에 의존함
- 첫 번째는 consistent spectrogram의 subset $\mathcal{C}\subset \mathbb{C}^{T\times F}$에 대한 projection으로:
(Eq. 9) $P_{\mathcal{C}}(\mathbf{C})=\mathbf{T}\mathbf{T}^{\dagger}\mathbf{C}$
- $\mathbb{C}^{T\times F}$의 element는 $\mathbb{R}^{L}$의 signal에 대한 STFT로 얻어짐 - 두 번째는 magnitude가 $\hat{\mathbf{S}}$과 같은 spectrogram의 subset $\{\mathbf{C}\in\mathbb{C}^{T\times F}| |\mathbf{C}|=\hat{\mathbf{S}}\}$으로의 projection:
(Eq. 10) $P_{|\cdot|=\hat{\mathbf{S}}}(\mathbf{C})=\hat{\mathbf{S}}\odot \frac{\mathbf{C}}{|\mathbf{C}|}$
- $\odot, \frac{\cdot}{\cdot}$ : 각각 element-wise product, division
- 첫 번째는 consistent spectrogram의 subset $\mathcal{C}\subset \mathbb{C}^{T\times F}$에 대한 projection으로:
- 이때 GLA는 $\mathbf{C}_{0}=\hat{\mathbf{S}}\odot e^{i\Phi_{0}}$로 initialize 되고, $\Phi_{0}$은 일반적으로 random임
- 그러면 $k$-th iteration은:
(Eq. 11) $\mathbf{C}_{k}=P_{\mathcal{C}}\circ P_{|\cdot|=\hat{\mathbf{S}}}(\mathbf{C}_{k-1})$
- 실질적으로 논문에서는 optimization을 가속하고 diffusion model modification에 쉽게 적용할 수 있도록 GLA의 modified version인 Fast Griffin-Lim Algorithm (FGLA)를 사용
- GLA-Grad: Griffin-Lim Corrected Diffusion Model
- GLA-Grad는 WaveGrad를 기반으로 함
- 이때 (Eq. 6)과 같은 diffusion model의 iteration process는 training data distribution을 벗어나는 signal $\mathbf{y}_{n-1}$로 이어질 수 있음
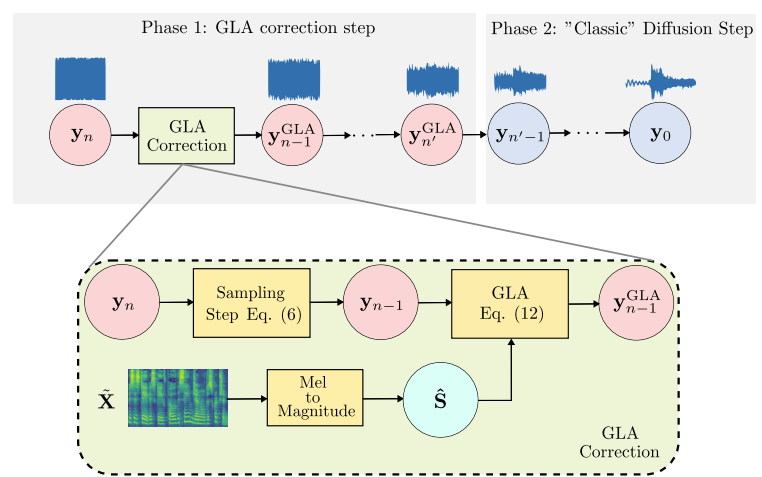
- 즉, $\tilde{\mathbf{X}}$에 대한 conditioning 외에도 더 강한 constraint가 필요함 - 따라서 GLA-Grad는 아래 그림과 같이 GLA를 도입하여 생성된 signal과 예측된 signal 간의 bias를 correction 하는 것을 목표로 함
- 이를 위해 diffusion process의 각 step에 GLA를 도입하고, desired magnitude spectrogram의 추정치와 해당하는 magnitude $|\mathbf{T}\mathbf{y}_{n-1}|$를 최소화함으로써 step $n-1$에서 signal estimation $\mathbf{y}_{n-1}$의 생성을 guide 함
- Desired magnitude은 직접적으로 access 할 수 없지만, desired mel-spectrogram $\tilde{\mathbf{X}}$에서 얻은 magnitude spectrogram estimation $\hat{\mathbf{S}}$에 pseudo-inverse $\mathbf{M}^{\dagger}$를 적용하여 $\hat{\mathbf{S}}=\mathbf{M}^{\dagger}\tilde{\mathbf{X}}$의 mel transform을 고려함
- 그러면 diffusion time step $n-1$에서 magnitude spectrogram $\hat{\mathbf{S}}$를 desired magnitude로 사용하여 GLA를 수행 가능
- 결과적으로 (Eq. 6)에 대해 WaveGrad를 통해 얻은 current diffusion estimate $\mathbf{y}_{n-1}$에서 시작하여 다음의 new estimate $\mathbf{y}_{n-1}^{GLA}$로 이어지는 Griffin-Lim correlction을 도입함:
(Eq. 12) $\mathbf{y}_{n-1}^{GLA}=\mathbf{T}^{\dagger}(P_{\mathcal{C}}\circ P_{|\cdot|=\hat{\mathbf{S}}})^{K}(\mathbf{T}\mathbf{y}_{n-1})$
- $(P_{\mathcal{C}}\circ P_{|\cdot|=\hat{\mathbf{S}}})^{K}$ : $\mathbf{y}_{n-1}$의 spectrogram $\mathbf{T}\mathbf{y}_{n-1}$을 initial value로 하여 $K$ iteration GLA를 적용한 결과 - 실질적으로 GLA-Grad는 아래 그림과 같이 두 단계로 구성됨
- Initial phase에서는 diffusion process의 각 sampling step에서 GLA-corrected approach를 적용
- 즉, (Eq. 6)의 WaveGrad update를 사용하여 $\mathbf{y}_{n-1}$을 얻은 다음, (Eq. 12)의 GLA correction을 통해 $\mathbf{y}_{n-1}^{GLA}$를 얻는 과정
- 이러한 GLA projection을 통해 diffusion process에서 signal consistency를 유지할 수 있음 - 이후 second phase에서는 기존의 diffusion process를 수행함
- Initial phase에서는 diffusion process의 각 sampling step에서 GLA-corrected approach를 적용
- 이때 (Eq. 6)과 같은 diffusion model의 iteration process는 training data distribution을 벗어나는 signal $\mathbf{y}_{n-1}$로 이어질 수 있음
4. Experiments
- Settings
- Results
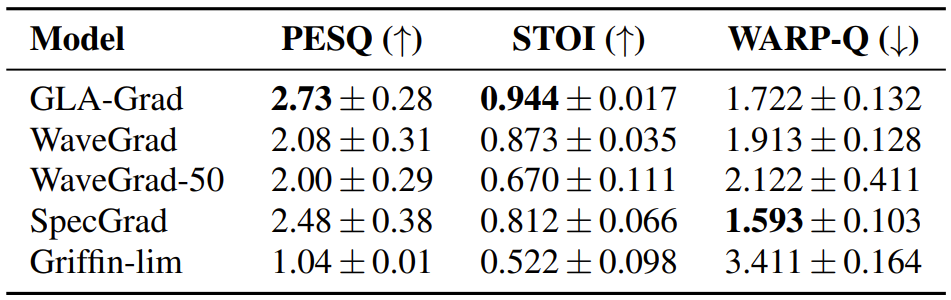
- LJSpeech에서는 WaveGrad의 성능이 좀 더 높았지만, GLA-Grad는 PESQ 측면에서 낮은 표준편차를 보이므로 보다 안정적인 output quality를 가짐

- VCTK 측면에서는 GLA-Grad의 합성 품질이 가장 뛰어남

- 한편으로 LJSpeech에서 VCTK로의 generalization 측면에서는 GLA-Grad가 가장 우수한 성능을 보임
- Complexity 측면에서 GLA-Grad는 WaveGrad보다 빠른 속도를 보임

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글