

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis
feVeRin 2024. 6. 18. 11:14반응형
Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis
- Neural vocoder를 통해 고품질의 audio를 합성할 수 있지만, 여전히 low-end device에서는 real-time으로 사용하기 어려움
- 한편으로 Digital Signal Processing 기반의 vocoder는 lightweight FFT를 통해 구현될 수 있으므로 neural vocoder보다 빠르게 동작가능함
- BUT, vocal tract의 approximate representation에 대해 over-smoothed acoustic model prediction을 사용하므로 합성 품질이 저하되는 경향이 있음 - DDSP Vocoder
- Digital Signal Processing vocoder와 jointly optimize 되는 acoustic model을 도입
- Vocal tract에 대한 spectral feature를 추출하지 않고도 학습되는 lightweight Differential Digital Signal Processing vocoder를 구성
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 voice assistant, in-car navigation 등의 accessibility device에서 필수적으로 사용되고 있음
- 기존의 autoregressive vocoder는 human voice 수준의 합성 성능을 달성했지만, model size와 높은 GFLOPS로 인한 computational requirement로 인해 on-device TTS에서는 활용하기 어려움
- 한편으로 MelGAN, HiFi-GAN, WaveGlow와 같은 non-autoregressive vocoder는 parallel frame-wise generation을 통해 autoregressive model보다 빠른 합성 속도를 달성함
- BUT, 해당 방식들 역시 model size나 근본적인 computational complexity를 해결한 것은 아니므로 GPU나 multi-core CPU device에서만 실행가능함
- 소형 vocoder 측면에서는 Multi-Band MelGAN, LPCNet을 고려할 수 있지만, 이들 역시 스마트폰과 같은 high-end device가 아닌 smartglass 등의 low-end/low-memory wearable device에는 적합하지 않음
- 특히 neural vocoder는 stochastic nature로 인해 audio waveform의 phase를 모델링하는 것이 어렵기 때문에 compuationally intensive 함
- 이때 Differentiable Digital Signal Processing (DDSP)에서는 서로 다른 phase waveform은 동일한 sound를 내고, 서로 다른 magnitude spectrogram을 가지는 waveform은 서로 다른 sound를 낸다는 것을 밝힘
- 즉, phase information을 생성하면서 true audio와 비교하여 magnitude spectrogram만 정확히 학습하는 방식으로 vocoder의 효율성을 개선할 수 있음
-> 그래서 Digital Signal Processing (DSP) vocoder와 acoustic model을 결합한 DDSP vocoder를 제안
- DDSP Vocoder
- Acoustic model은 neural network로 구성되지만 DSP vocoder는 learnable parameter를 가지지 않음
- 대신 joint module을 통해 end-to-end differentiable 하게 구성하여 true audio의 magnitude spectrogram을 학습하도록 함
- DDSP 측면에서 Neural Homomorphic Vocoder (NHV)는 log mel-spectrogram을 예측한 다음, neural network를 사용해 spectral envelope의 linear time-varying filter coefficient로 변환하는 방식을 사용함
- 이때 NHV와 달리, 제안하는 DDSP Vocoder는 zero-phase filter만을 사용하여 24배의 FLOPS 절감 효과와 4.36 MOS의 높은 합성 품질을 달성
- Acoustic model은 neural network로 구성되지만 DSP vocoder는 learnable parameter를 가지지 않음
< Overall of DDSP Vocoder >
- Learnable parameter가 없는 simple DSP vocoder와 acoustic model을 end-to-end로 jointly train 하는 differentiable DSP optimization technique을 도입
- 결과적으로 기존 neural vocoder 보다 훨씬 적은 FLOPS와 빠른 합성 속도를 달성하면서도 고품질의 합성이 가능
2. Method
- DDSP Vocoder를 활용한 on-device text-to-speech pipeline은 아래 그림과 같이 구성됨
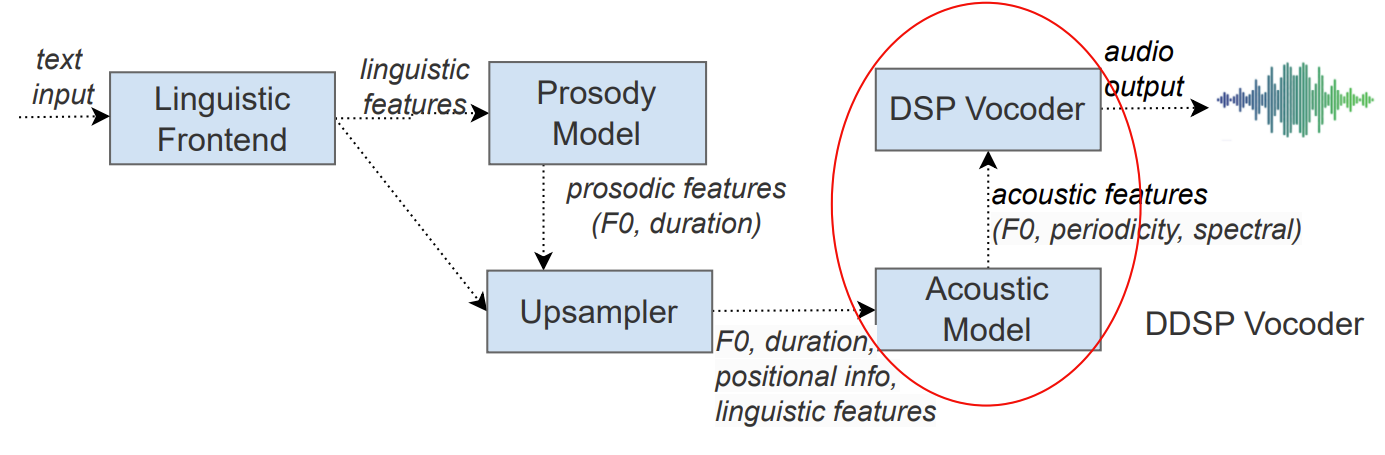
- Frontend Components
- Linguistic Frontend
- Input text를 linguistic feature로 변환하는 역할
- 이를 위해 text를 normalize 하고, International Phonetic Alphabet (IPA)를 사용해 phonetic transcription을 예측한 다음,
- Phone, syllable stress, phrase type과 같은 supra-segmental infromation을 one-hot feature로 변환
- 추가적으로 prosody의 naturalness를 향상하기 위해 pre-trained word embedding을 추가
- 결과적으로 phrase, word, syllable rate에 대한 feature는 각 phone에 대해 repeat 되어 phone 당 하나의 feature vector로 얻어짐
- Input text를 linguistic feature로 변환하는 역할
- Prosody Model
- Frontend에서 제공하는 linguistic feature를 통해 각 phone의 duration과 average fundamental frequency를 예측하는 역할
- 구조적으로는 input linear layer와 output 이전에 2개의 linear layer를 가지는 Emformer를 기반으로 하고, ground-truth audio에서 추정된 reference feature에 대한 $L2$ loss로 training 됨
- Upsampler
- Phone-wise duration information을 통해 linguistic feature를 repeat하여 time synchronous frame으로 roll out함
- 이때 current phone, syllable, word, phrase 내에서 current frame의 positional information과 함께 pitch, duration value를 반영함

- DDSP Vocoder
- 제안하는 DDSP Vocoder는 acoustic model과 differential DSP vocoder로 구성되고, final audio waveform에 대한 loss를 통해 end-to-end training됨
- DSP Vocoder
- DSP vocoder는 위 그림과 같은 source-filter model을 기반으로 하고, output speech signal $s$를 생성하기 위해 3가지의 input feature를 사용함:
- Fundamental Frequency $F0$ (1-dimensional Hz value)
- Periodicity $P$ (impulse train에 해당하는 periodic과 noise에 해당하는 aperiodic excitation 간의 12-dimensional mel band-wise ratio)
- Vocal Tract Filter $V$ (257-dimensional linear frequency log magnitude)
- Excitation signal $E$는 동일한 energy의 impulse train $E_{imp}(F0)$ 또는 white noise $E_{noise}$에 해당함
- 여기서 mixed excitation signal을 얻기 위해, 각각을 combination 하는 대신 periodicity feature를 multiply 하여 vocal tract filter를 periodic/aperiodic part로 split 함
- 이후 두 excitation signal을 filter 하여 final audio $s$에 추가함
- 해당 방식을 통해 excitation type에 사용되는 algorithm을 최적화하여 artifact를 방지하고 computational efficiency를 향상할 수 있음
- 결과적으로, frequency domain의 variable을 대문자로 time domain의 variable을 소문자로 나타내었을 때 해당 과정은 다음과 같이 formulate 됨:
(Eq. 1) $s=\mathrm{iFFT}(E\times V)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,s=\mathrm{iFFT}([P\times E_{imp}(F0)+(1-P)\times E_{noise}]\times V)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,s=\underset{\text{Periodic Signal}}{\underbrace{\mathrm{iFFT}(P\times V)*e_{imp}(F0)}}+\underset{\text{Aperiodic Signal}}{\underbrace{\mathrm{iFFT}((1-P)\times V\times E_{noise})}}$
- 해당 vocoder는 24000Hz의 sampling rate에서 overlap-add를 통해 merge 되어 final audio waveform을 생성함
- 논문에서는 128 sample의 frame shift와 512 point의 FFT size를 사용하고, 12-dimensional $P$는 257 linear coefficient로 extrapolate 됨 - 각 frame $i$에 대한 periodic/aperiodic signal은 개별적으로 생성되고, 먼저 Periodic Signal은:
- Periodic part $P_{i}\times V_{i}$를 얻기 위해, periodicity $P_{i}$에 vocal tract filter $V_{i}$를 곱함
- 이후 inverse FFT와 $180^{\circ}$ phase를 사용하여 $P_{i}\times V_{i}$를 time domain으로 변환함
- 이는 $P_{i}\times V_{i}$ filter의 periodic part에 의해 filtering 된 single impulse를 의미 - 다음으로 running phase value를 $1/F0_{i}$씩 증가시켜 frame 내 impulse의 timestamp를 계산하여 filtered impulse train을 rendering 함
- 최종적으로 energy normalization을 위해 $1/sqrt(F0_{i})$를 곱함
- Low $F0_{i}$ value에서 frame 내 impulse가 떨어지지 않거나 완전히 0일 수 있으므로, 해당 경우에는 frame을 skip 함
- Aperiodic Signal은:
- 128 frame shift로 noise buffer를 shift 하고 $-1,...,1$ 사이에서 uniformly distribute 된 pseudo-random number로 새로운 128 value를 fill 함
- 그리고 $1/sqrt(24000)$을 곱하여 noise를 impulse와 동일한 level로 scale 함
- 이후 complex spectrum $E_{noise_{i}}$를 얻기 위해, windowing function 없이 forward FFT를 적용하여 noise buffer를 frequency domain으로 변환
- 여기서 각 sample은 uncorrelate 되어 있으므로 $E_{noise_{i}}$는 discontinuity 없이 완벽하게 periodic 하므로 windowing function을 사용하지 않음 - 다음으로 $E_{noise_{i}}$에 filter $V_{i} \times (1-P_{i})$의 aperiodic part를 곱하고, result에 inverse FFT를 적용하여 time domain으로 다시 변환함
- 최종적으로 intermediate noise buffer에 256 point의 centered Hann window를 적용하여 overlap-add audio의 합이 최대 $1.0$이 되도록 함
- 결과적으로 각 frame에 대해 두 intermediate audio buffer를 overlap-add 하고 128 sample의 frame shift를 통해 final audio waveform을 생성함
- DSP vocoder는 위 그림과 같은 source-filter model을 기반으로 하고, output speech signal $s$를 생성하기 위해 3가지의 input feature를 사용함:
- Acoustic Model
- Acoustic model은 linguistic feature, repeated phone-level $F0$와 duration, 각 frame에 대한 positional information으로 구성된 512-dimensional input vector를 사용함
- 이때 구조적으로는 아래 표의 Emformer architecture를 따름 - 결과적으로 acoustic model은 1-dimensional $F0$, 12-dimensional periodicity $P$, vocal tract $V$에 대한 257-dimensional representation에 해당하는 270-dimensional output을 제공
- Acoustic model은 linguistic feature, repeated phone-level $F0$와 duration, 각 frame에 대한 positional information으로 구성된 512-dimensional input vector를 사용함

- Joint Modeling via DDSP
- Excitation signal $E$에는 phase information이 포함되어 있고, $V$는 $E$ 위의 linear filter로 사용됨
- 이때 speech signal $s$만 observe 하므로 $E$를 모르면 $V$를 정확하게 결정할 수 없음
- 특히 cepstral smoothing, linear predictive coding (LPC), pitch synchronouosly extracted log mel-spectrogram $\text{lmel}_{psync}$에서는 $V$를 결정하기 위해
- $V$가 magnitude spectrogoram (formant) 전반에 걸쳐 slow change를 담당한다고 가정하고, $s$의 smoothed magnitude spectrogram을 생성함
- 즉, $\text{lmel}_{psync}$ feature에 대해 acoustic model을 training 할 때, prediction error는 approximate feature extraction 위에 추가됨
- 결과적으로 audio sound가 muffle 되고 unnatural 해질 수 있음
- 한편으로 DSP vocoder는 differentialbe 하므로 acoustic model과 결합하여 사용할 수 있음
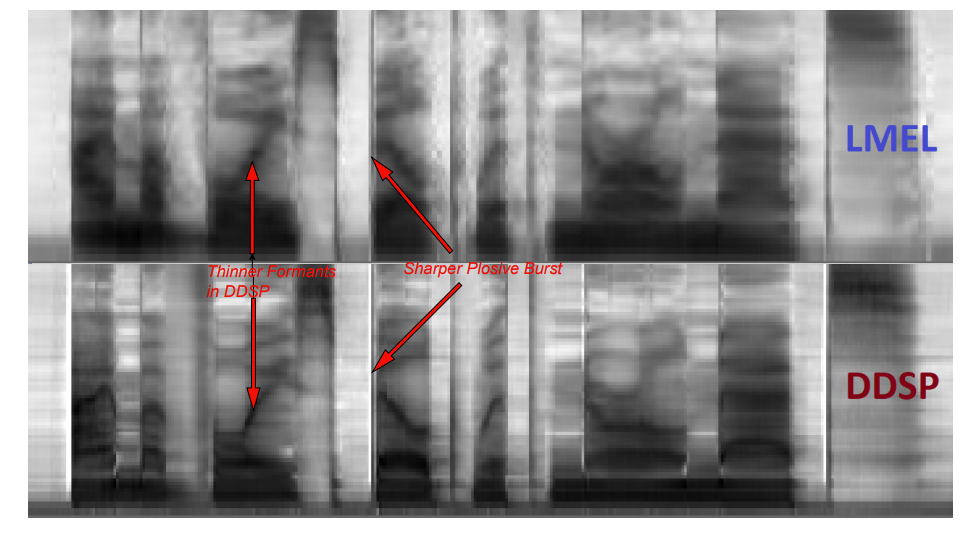
- 즉, 예측된 audio를 true audio와 비교하여 jointly optimize 하여 vocoder를 driving 하는 spectral feature를 학습할 수 있음 - 실제로 아래 그림과 같이 DSP Vocoder Adv의 $\text{lmel}_{psync}$ prediction과 DDSP Vocoder에서 학습된 intermediate spectral representation을 비교해 보면,
- DDSP Vocoder는 thinner formant와 sharper plosive를 가지는 detailed spectral representation을 학습할 수 있음
- 이때 speech signal $s$만 observe 하므로 $E$를 모르면 $V$를 정확하게 결정할 수 없음
- Training
- DDSP Vocoder의 training을 위해 다음의 3가지의 loss를 사용함
- Reference MSE Loss (on Acoustic Model Prediction)
- Training 수렴을 위해 reference $F0$를 사용하여 예측된 fundamental frequency $\tilde{F}0$에 대한 $L2$ loss를 적용함
- Periodicity feature prediction $\tilde{P}$의 경우, 모델은 reference $P$의 explicit supervision 없이 학습될 수 있음
- BUT, reference $P$에 $L2$ loss를 추가하면 breathy voice를 줄이고 품질을 향상할 수 있음:
(Eq. 2) $L_{refmse}=L_{refmse\text{_}F0}+L_{refmse\text{_}P}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, L_{refmse\text{_}F0}=\mathbb{E}_{(F0,\tilde{F}0)}[\lambda_{F0}(F0-\tilde{F}0)^{2}]$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, L_{refmse\text{_}P}=\mathbb{E}_{(P,\tilde{P})}\left[\frac{\lambda_{P}}{d_{P}}(P-\tilde{P})^{2}\right]$
- $d_{P}=12$ : Periodicity dimension, $\lambda_{F0} = 50,\lambda_{P}=30$
- Multi-Window STFT Loss (on Vocoder Output)
- Reference audio $x$의 amplified log magnitude STFT spectrogram과 predicted audio $\tilde{x}$ 사이의 $L1$ loss는:
(Eq. 3) $L_{mw\text{_}stft}(G)=\mathbb{E}_{(x,\tilde{x})}\sum_{i=1}^{C}\frac{\lambda_{stft,i}||X_{i}-\tilde{X}_{i}||_{1}}{N_{i}}$
- $X_{i} = \text{amp_log}(|\text{STFT}_{i}(x)|), \tilde{X}_{i}=\text{amp_log}(|\text{STFT}_{i}(\tilde{x})|)$, $N_{i}$ : $i$-th FFT size에 대한 magnitude의 element 수
- $\lambda_{stft}$ : 512, 1024, 2048의 $C=3$ FFT size 각각에 대한 loss weight로써, 25.7, 51.3, 102.5로 설정됨 - STFT extraction은 128개 sample의 frame shift로 수행되고, $\text{amp_log}$ operation은 signal을 72dB로 amplify 하고 $e$보다 큰 signal에 대해 log를 취하여 $e$ 아래에서 linear 하게 만듦
- 해당 방식을 통해 digital zero input이 zero output으로 mapping 되고, log를 취함으로써 excessively large negative number로 발산하지 못하도록 함:
(Eq. 4) $ \text{amp_log}(y)=\left\{\begin{matrix}
\log(y*gain), &\text{if}\,\, y*gain\geq e \\
\frac{y*gain}{e}, &\text{if}\,\, y*gain<e \\
\end{matrix}\right.$
- Reference audio $x$의 amplified log magnitude STFT spectrogram과 predicted audio $\tilde{x}$ 사이의 $L1$ loss는:
- Adversarial Loss (on Vocoder Output)
- MSE-based loss는 adversarial loss가 없는 경우, over-smoothed spectral prediction으로 인해 muffled sound가 발생함
- 이때 adversarial loss는 vocal tract filter prediction을 sharp 하게 만들어 realistic audio를 생성하는데 도움을 줌 - 따라서 논문은 128 sample의 frame shift에서 추출된 257-dimensional magnitude spectrogram (512-point FFT)에서 동작하는 discriminator를 도입함
- DDSP Vocoder는 data에서 phase를 모델링하지 않으므로 adversarial loss는 MelGAN, HiFi-GAN과 달리 magnitude spectrogram에서 동작함 - 이를 위해 $K=8$의 discriminator를 사용하고, 각 discriminator는 257-dimensional spectrogram에서 8 overlapping point가 있는 48-point band를 확인함
- 2개의 terminal discriminator는 one side에서만 overlap 되므로 40 point의 frequency band만 확인함
- 특히 multiple discriminator를 사용하면 spectrogram이 서로 다른 frequency band에서 서로 다른 characteristic을 가진다는 점을 반영할 수 있음
- 결과적으로 다음의 least squares adversarial loss를 사용:
(Eq. 5) $L_{adv}(D_{k})=\mathbb{E}_{(X,\tilde{X})}\left[\frac{(D_{k}(X)-1)^{2}}{N_{k}}+\frac{D_{k}(\tilde{X})^{2}}{N_{k}}\right]$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, L_{adv}(G)=\mathbb{E}_{\tilde{X}}\left[\lambda_{adv}\sum_{k=1}^{K}\frac{(D_{k}(\tilde{X})-1)^{2}}{N_{k}}\right]$
- $D_{k}$ : $k$-th discriminator, $N_{k}$ : $k$-th STFT magnitude band의 element 수
- $X, \tilde{X}$ : reference, predicted audio의 amplified log magnitude spectrogram
- $\lambda_{adv} = 50$ : adversarial loss weight - 구조적으로 모든 discriminator는 아래 표와 같이 convolutional architecture를 따름
- 여기서 각 $D_{k}$는 할당된 frequency band에 대한 input을 image로 처리하고 receptive field와 동일한 $5\times 31$ size의 patch를 classify 함
- 제안하는 DDSP Vocoder 역시 PatchGAN과 마찬가지로 smaller patch에서 동작하는 discriminator가 전체 input에 대한 하나의 discriminator보다 더 높은 품질의 audio를 생성할 수 있음
- 따라서 generator training을 위한 final loss는:
(Eq. 6) $L(G)=L_{refmse}+L_{mw\text{_}stft}+L_{adv}(G)$
- MSE-based loss는 adversarial loss가 없는 경우, over-smoothed spectral prediction으로 인해 muffled sound가 발생함

3. Experiments
- Settings
- Dataset : American English Speech (internal)
- Comparisons : WaveRNN, HiFi-GAN, Multi-Band MelGAN
- Results
- MOS 측면에서 DDSP Vocoder가 가장 우수한 성능을 달성함
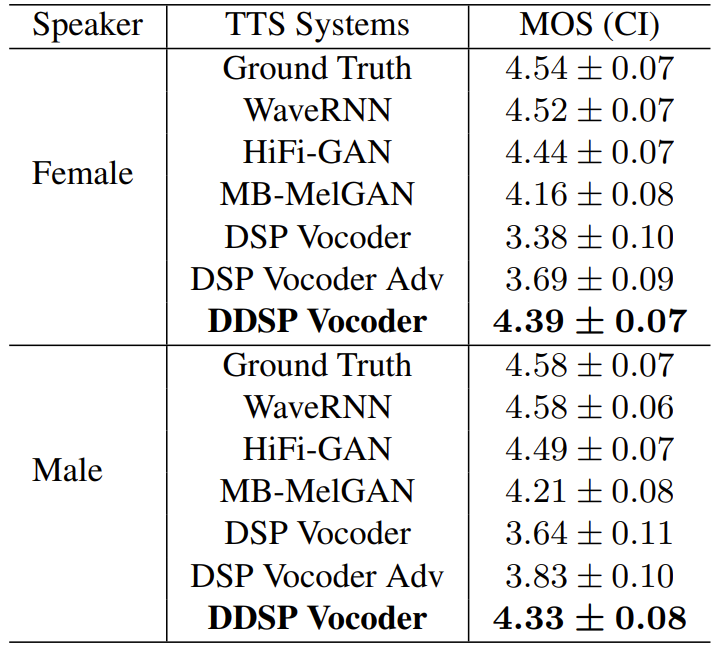
- Complexity 측면에서 DDSP Vocoder는 Multi-Band MelGAN과 비교하여 340배 더 적은 FLOPS를 가짐
- RTF 측면에서는 34배 빠르게 동작함

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글