
티스토리 뷰
Paper/Vocoder
[Paper 리뷰] JenGAN: Stacked Shifted Filters in GAN-based Speech Synthesis
feVeRin 2024. 7. 3. 09:48반응형
JenGAN: Stacked Shifted Filters in GAN-based Speech Synthesis
- Non-autoregressive GAN-based vocoder는 빠른 추론 속도와 우수한 품질을 지원하지만, audible artifact가 발생하는 경향이 있음
- JenGAN
- Shift-equivariant property를 보장하기 위해 shifted low-pass filter를 stack 하는 training strategy
- 추론 시에 사용되는 model structure를 유지하면서 aliasing을 방지하고 artifact를 줄임
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Neural vocoder는 mel-spectrogram과 같은 audio feature를 사용하여 audio waveform을 output 함
- 그중 non-autoregressive vocoder는 Generative Adversarial Network (GAN), Normalizing flow, Diffusion model 등을 기반으로 함
- 특히 GAN-based vocoder는 빠른 합성 속도를 유지하면서 우수한 품질의 audio를 생성할 수 있음 - BUT, GAN-based vocoder는 up/downsampling layer로 인해 audible artifact가 발생함
- 대표적으로 HiFi-GAN의 transposed upsampling convolution은 tonal artifact를 발생시키고, downsampling 이전의 signal이 band-limit 되지 않은 경우 signal aliasing이 나타남
- 한편으로 point-wise non-linearity activation은 discrete singal의 aliasing으로 이어짐
- 이를 해결하기 위해 non-linearity function 이전에 signal을 up/downsampling 하는 방식으로 aliasing을 완화할 수 있지만, 추가적인 up/downsampling layer로 인해 속도가 느려진다는 단점이 있음
- 따라서 GAN-based vocoder의 architecture를 수정하지 않고 artifact 문제를 완화할 수 있는 방법이 필요함
- 그중 non-autoregressive vocoder는 Generative Adversarial Network (GAN), Normalizing flow, Diffusion model 등을 기반으로 함
-> 그래서 GAN-based vocoder에서 audible artifact를 줄이는 anti-aliasing algorithm인 JenGAN을 제안
- JenGAN
- Original neural network block 전후에 sinc kernel과 2개의 convolution operation을 추가하여 aliasing과 관련된 shift-equivariant property를 달성
- 이때 Avocodo와 같이 architecture를 수정하지 않고 training strategy 만을 변경
- 이를 통해 필요한 model architecture를 preserve 함으로써 더 빠른 추론과 fine-tuning을 지원 가능
< Overall of JenGAN >
- Shift-equivariant property를 보장하는 training strategy를 통해 vocoder architecture 변경 없이 artifact를 완화
- 결과적으로 기존 GAN-based vocoder와 결합하여 사용했을 때, 전체적인 성능을 크게 개선
2. Method
- Stacked Shifted Filters
- Vocoder에서 block의 discrete input/output signal은 continuous signal에서 얻은 sample로 볼 수 있음
- 이때 continuous signal의 frequency가 sampling rate의 절반을 초과하는 경우, continuous domain에서 discrete domain으로 변환할 때 aliasing이 발생함
- 즉, aliasing을 방지하려면 continuous representation의 frequency를 sampling rate의 절반 미만으로 제한해야 함 - 이를 위해 특정 block의 input/output signal 모두에 low-pass filter를 추가함으로써 해당 block 내의 signal frequency range를 제한할 수 있음
- BUT, frequency 제한을 위해 discrete representation에 대해 naive 하게 low-pass filter를 적용하면 continuous domain의 frequency control로 정확하게 변환되지 않음
- 따라서 JenGAN은 continuous domain에 대한 ideal block과 discretized model 모두에서 성립하는 shift-equivariant property를 활용함
- Shift-equivariant property는 input signal이 specific real-valued number $\delta$ 만큼 shift 하고, output signal이 이후 $-\delta$ 만큼 shift 될 때, resulting block이 continuous domain에서 동일하게 유지되는 것을 보장함
- 해당 shifting method를 사용하여 discrete representation에 대해 block을 training 하고 $\delta$ value를 변경함으로써, behavior를 continuous domain의 ideal block에 근사해 high-frequency band를 제한할 수 있음 - 결과적으로 해당 training strategy를 통해 discrete domain의 block이 shift-equivariant property를 달성할 수 있으므로 alisaing을 완화할 수 있음
- 이때 continuous signal의 frequency가 sampling rate의 절반을 초과하는 경우, continuous domain에서 discrete domain으로 변환할 때 aliasing이 발생함

- JenGAN
- JenGAN은 anti-aliasing을 위해 training 과정에서 block의 structure만을 변경하고, 추론 시에는 변경하지 않음
- 먼저 vocoder의 block $M(\mathbf{x}[n])$을 다음과 같이 수정함:
(Eq. 1) $M(\mathbf{x}[n]*F_{\text{sinc}}(-\delta))*F_{\text{sinc}}(+\delta)$
- $*$ : discrete domain의 channel-wise convolution operation - 여기서 $F_{\text{sinc}}(\delta)$는 $n\in\mathbb{Z}$에 대해 $-12\leq n\leq 12$ range에서 정의된 shifted sinc filter:
(Eq. 2) $F_{\text{sinc}}(\delta)[n]=\left\{\begin{matrix} 1, & \text{if}\,\,n+\delta=0 \\ \sin (\pi(n+\delta))/(\pi(n+\delta)),& \text{otherwise} \end{matrix}\right.$
- 해당 operation은 calculated sinc filter를 사용하고 `groups` parameter를 input channel size와 동일하게 설정한 PyTorch의 `F.Conv1d`를 통해 구현됨 - 추론 시에는 $\delta=0$으로 설정하여 block이 수정된 version이 아닌 original form을 유지할 수 있도록 함
- 한편으로 modified block은 input/output representation을 shifting 하는 것과 동일하므로, 해당 block을 stack 하고 reconstruction loss를 적용하는 것은 model이 shift-equivariance를 학습하도록 forcing 하는 것과 같음 - Block에 up/downsampling layer가 포함된 경우, output signal의 sampling frequency는 input sampling frequency에 따라 달라짐
- BUT, shifting value는 continuous domain의 input/output signal 모두에 대해 consistent 하게 유지되어야 함
- 따라서 JenGAN에서는 output sinc filter를 $r_{d}\cdot \delta$만큼 shift 하고, vocoder의 up/downsampling layer를 포함하는 block $M(\mathbf{x}[n])$을 다음과 같이 수정함:
(Eq. 3) $M(\mathbf{x}[n]*F_{\text{sinc}}(-\delta))*F_{\text{sinc}}(+r_{d}\cdot \delta)$
- $r_{d}$ : frequency difference ratio
- 이때 convolution function은 differentiable 하므로 JenGAN은 gradient flow가 가능함
- 한편으로 $\delta$를 select 하기 위해서는 specific distribution에서 sampling을 수행하고, 사용된 sinc filter의 finite length로 인한 sampling value의 최댓값을 고려해야 함
- 이를 위해 upsampling block이 포함될 때 output shifting에 sampling value을 적용하고 downsampling block이 포함될 때 input shifting에 sampling value를 적용해 sinc filter의 shifting value가 bound 되도록 함
- 해당 process는 아래 [Algorithm 1]을 따라 model의 모든 block에 적용됨
- 먼저 vocoder의 block $M(\mathbf{x}[n])$을 다음과 같이 수정함:

- Shifting Value Sampling Method
- [Algorithm 1], [Algorithm 2]의 shifting value $\delta$에 대해서 다음 3가지의 sampling method를 고려할 수 있음
- $[-2, 2)$ range의 uniform distribution sampling
- Standard deviation $2$의 normal distribution sampling
- $\{ -2, -1, 0, 1,2\}$ value set의 equal probability discrete sampling
- 여기서 논문은 generator/dsicriminator 모두에 대해 discrete distribution samping을 채택

3. Experiments
- Settings
- Results
- HiFi-GAN에 JenGAN을 결합하여 사용하는 경우 가장 우수한 성능을 달성함

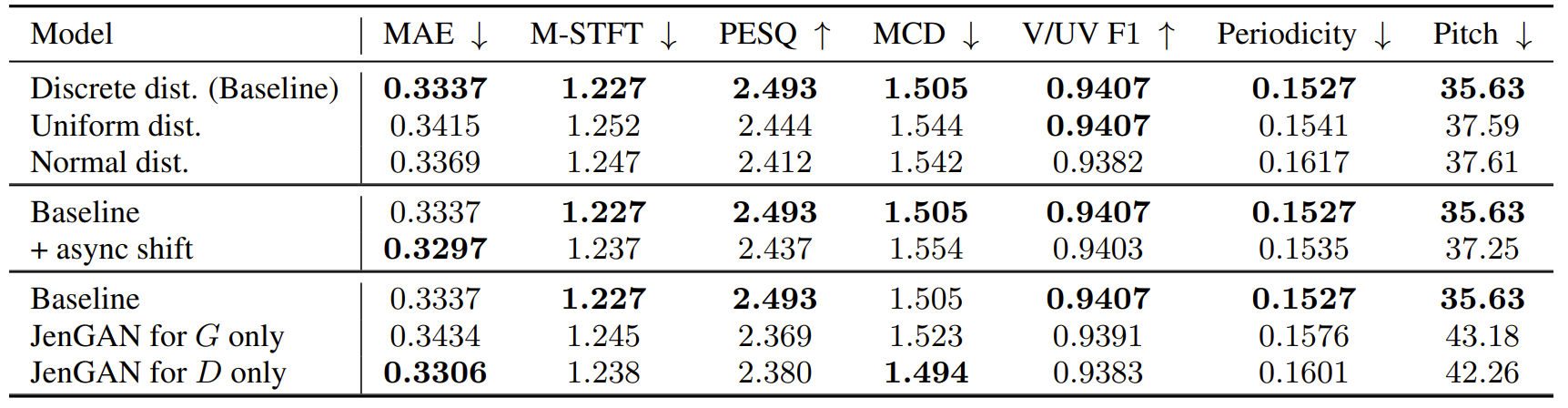
- Ablation study 측면에서 discrete distritubtion sampling을 사용한 경우 최고의 성능을 달성함
- 한편으로 async shift method를 적용한 경우, 성능 저하가 발생했음
- Generator에서 [Algorithm 1]만 사용하거나 discriminator에서 [Algorithm 2]만 사용하는 경우에도 성능 저하가 발생함
- Avocodo, BigVGAN vocoder에 적용했을 때도 JenGAN은 마찬가지로 성능 개선의 효과를 보임

- Mel-spectrogram 측면에서 비교해 보면, JenGAN은 pattern clarity를 크게 향상하는 것으로 나타남
- 즉, JenGAN은 natural-sounding human harmonics를 생성할 수 있음

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글