

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform
feVeRin 2024. 2. 7. 12:09반응형
iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform
- Mel-spectrogram vocoder는 3가지 inverse 작업을 해결할 수 있어야 함
- Original-scale magnitude spectrogram의 복구, Phase reconstruction, Frequency-to-time conversion - 이를 위해 temporal upsampling layer를 활용하지만, mel-spectrogram 내의 time-frequency structure를 효과적으로 사용할 수 없음
- iSTFTNet
- Upsampling layer를 통해 frequency dimension을 줄인 다음, vocoder의 output layer를 inverse Short-Time Fourier Transform으로 대체
- 결과적으로 black-box modeling의 계산 비용을 줄이고 high-dimensional spectrogram의 중복 추정을 방지
- 논문 (ICASSP 2022) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 일반적으로 2-stage로 구성됨
- Text, source에서 intermediate representation을 예측
- 예측된 intermeidate representation으로부터 raw waveform을 합성
- 이때 mel-spectrogram은 compactness와 expressiveness로 인해 intermediate representation으로 주로 사용됨
- Mel-spectrogram vocoder는 3가지 inverse 문제를 해결해야 함
- Original-scale magnitude spectrogram의 복구, Phase reconstruction, Frequency-to-time conversion
- 일반적인 convolutional mel-spectrogram vocoder는 neural network와 temporal upsampling layer를 활용
- 이를 통해 high-dimensional spectrogram reconsturction과 같은 합성 과정의 중복 process를 줄일 수 있음
- BUT, black-box로 동작하고 mel-spectrogram에 존재하는 time-frequency struture를 반영하지 못함
-> 그래서 일반적인 mel-spectrogram vocoder의 output layer를 inverse Short-Time Fourier Transfor (iSTFT)로 대체하는 iSTFTNet을 제안
- iSTFTNet
- Convolutional mel-spectrogram vocoder에 정립된 signal processing 방법인 iSTFT를 도입
- 특히 input mel-spectrogram의 dimension 수에 비해 frequency dimension 수가 충분히 적은 경우에 적합
< Overall of iSTFTNet >
- Upsampling layer를 통해 frequency dimension을 줄인 다음, vocoder의 output layer를 iSTFT로 대체
- Black-box modeling의 계산 비용을 줄이고 high-dimensional spectrogram의 중복 추정을 방지
- 결과적으로 HiFi-GAN의 layer를 iSTFTNet으로 대체했을 때, 음성 품질을 유지하면서 더 빠른 추론이 가능

2. Method
- Convolutional Mel-Spectrogram Vocoder
- Raw waveform에서 mel-spectrogram의 추출은,
- Short-Time Fourier Transform (STFT)를 통해 raw waveform에서 magnitude/phase spectrogram을 추출
- 이후 phase spectrogram을 drop 하고,
- Magnitude spectrogram을 mel-scale로 변환
- 따라서 mel-spectrogram vocoder는 raw waveform을 얻기 위해 위 3가지 과정에 대한 inverse process를 수행해야 함
- 일반적인 convolutional mel-spectrogram vocoder는
- Temporal upsampling layer를 포함한 CNN을 통해 inverse process를 수행
- 이를 통해 original-scale magnitude와 phase spectrogram에 대한 중복 추정을 피할 수 있음
- Low-capacitiy 모델에서도 convolution mel-spectrogram vocoder를 활용할 수 있다는 것을 의미
- i.g.) HiFi-GAN v2는 기존의 513보다 작은 128 channel의 1D convolution만을 사용하여 우수한 성능을 달성

- iSTFTNet: Fast and Lightweight Vocoder with iSTFT
- Black-box modeling은 유용하지만 inverse 문제를 해결하는데 도움을 줄 수 있는 mel-spectrogram의 time-frequency structure를 활용하지 못함
- 따라서 iSTFTNet은 아래 그림과 같이,
- Upsampling layer를 사용해서 frequency dimension을 줄인 다음, iSTFT를 통해 time-frequency resolution을 explicitly 하게 반영
- 이때 STFT의 time, frequency resolution trade-off를 활용 - $s\times$ upsampling 이후에 필요한 iSTFT를 $iSTFT(f_{s}, h_{s}, w_{s})$라고 하면,
- $iSTFT(f_{s}, h_{s}, w_{s})$는 original-scale spectrogram $iSTFT(f_{1}, h_{1}, w_{1})$에 필요한 iSTFT parameter를 통해 계산할 수 있음:
(Eq. 1) $iSTFT(f_{s},h_{s},w_{s}) = iSTFT \left( \frac{f_{1}}{s}, \frac{h_{1}}{s}, \frac{w_{1}}{s}\right)$
- $f_{s}$ : FFT size, $h_{s}$ : hop length, $w_{s}$ : window length - 여기서 STFT의 특성인 $f_{1} \cdot 1 = f_{s} \cdot s = constant$를 활용하면,
- (Eq. 1)은 $s$를 증가시켜 frequency dimension을 줄일 수 있다는 것을 의미함
- 따라서 아래 그림과 같이 iSTFTNet은 upsample 수를 늘려 frequency direction의 structure를 단순화할 수 있음
- 이때 합리적인 품질을 위해서는 아래의 (c), (d)와 같이 2개 이상의 upsampling을 필요로 함
- 따라서 iSTFTNet은 아래 그림과 같이,
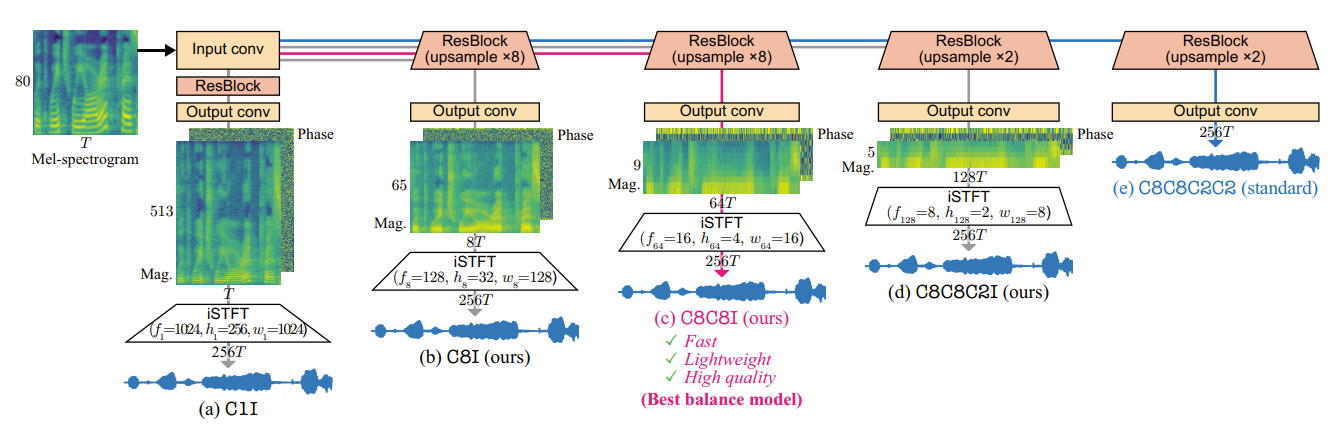
- Implementation
- iSTFTNet은 아래의 수정을 통해 다른 convolutional mel-spectrogram vocoder에 통합할 수 있음
- Raw waveform 대신 magnitude/phase spectrogram을 생성하기 위해서 최종 convolution layer의 output channel을 1에서 $(f_{s}/2+1)\times 2$로 변경
- Magnitude/phase spectrogram을 계산할 때 exponential, sine activation을 적용해야 함
- Magnitude spectrogram이 linear scale을 사용하고 input mel-spectrogram은 log-scale을 사용하므로 exponential function을 적용
- Phase spectrogram은 periodic characteristic을 얻기 위해 sine function을 적용 - Raw waveform은 (Eq. 1)을 따라 iSTFT를 적용해 magnitude/phase spectrogram에서 생성되어야 함
- Raw waveform 대신 magnitude/phase spectrogram을 생성하기 위해서 최종 convolution layer의 output channel을 1에서 $(f_{s}/2+1)\times 2$로 변경
3. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : HiFi-GAN, Multi-Band MelGAN, Parallel WaveGAN
- Results
- HiFi-GAN의 output layer를 iSTFTNet으로 대체하면, 추론 속도가 빨라지고 모델 size가 감소함
- MOS 측면에서 HiFi-GAN v1, v2에 iSTFTNet C8C8I, C8C8C2I를 각각 적용한 모델은 기존과 유사한 품질을 보임
- HiFi-GAN v3에 C8C8I를 적용하면 합성 품질이 다소 저하되지만, Multi-Band MelGAN, Parallel WaveGAN 보다는 여전히 우수한 성능을 보임
- iSTFTNet는 upsampling layer와 residual block을 결합하여 성능을 향상함,
- 하나의 upsampling과 2개의 residual block을 사용하는 C8C1I의 경우, 더 많은 upsampling을 활용하는 C8C8I 보다 더 낮은 성능을 보임
- Network architecture를 변경하지 않으면서 iSTFT를 적용하기 위해서는 upsampling을 통해 frequency dimension을 줄이는 것이 중요하다는 것을 의미
- V2-C8C8I는 Multi-Band MelGAN 보다 더 작은 size를 가지면서 더 우수한 합성 품질을 보임
- 이때 multi-band formulation과 iSTFT는 orthogonal 하고 compatible 하므로, 아래와 같이 통합될 수 있음:
$iSTFT \left( \frac{f_{1}}{sb} \frac{h_{1}}{sb}, \frac{w_{1}}{sb} \right)$
- $b$ : sub-band 개수
- 이때 multi-band formulation과 iSTFT는 orthogonal 하고 compatible 하므로, 아래와 같이 통합될 수 있음:

- TTS 작업으로 iSTFTNet을 확장했을 때, V1-C8C8I가 가장 우수한 성능을 보임
- iSTFTNet이 TTS에 대해서도 음성 품질을 손상시키지 않는다는 것을 의미

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글