

티스토리 뷰
Paper/TTS
[Paper 리뷰] VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
feVeRin 2024. 4. 30. 09:35반응형
VQTTS: High-Fidelity Text-to-Speech Synthesis with Self-Supervised VQ Acoustic Feature
- 대부분의 text-to-speech 모델은 acoustic model과 vocoder로 구성된 cascade system을 기반으로 함
- 이때 acoustic feature로써 일반적으로 mel-spectrogram을 활용하는데, 이는 time-frequency axis를 따라 high-correlated 되어 있기 때문에 acoustic model로 예측하기 어려움
- VQTTS
- 일반적인 mel-spectrogram이 아닌 self-supervised Vector-Quantized acoustic feature에 대해 acoustic model로써 txt2vec을 사용하고 vocoder로써 vec2wav를 적용
- 특히 txt2vec은 regression이 아닌 classification model로 구성되고, vec2wav는 discontinuous quantized feature를 smoothing 하기 위해 additional feature encoder를 활용함
- 논문 (INTERSPEECH 2022) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 script에 해당하는 음성을 합성하는 것을 목표로 함
- 일반적인 TTS pipeline은 input transcript에서 acoustic feature를 예측하는 acoustic model (AM)과 주어진 acoustic feature로부터 waveform을 합성하는 vocoder로 구성된 cascade system을 활용
- 대표적인 AM으로써 encoder-decoder architecture를 기반으로 하는 FastSpeech2가 있고, vocoder로는 Multi-Band MelGAN, HiFi-GAN 등을 활용할 수 있음 - BUT, 대부분의 모델에서 acoustic feature로 사용하는 mel-spectrogram은 time-frequency axis를 따라 highly correlate 되어 있기 때문에 AM으로 예측하기 어려움
- 결과적으로 vocoder를 통해 reconstruct할 때, ground-truth와 AM에서 예측된 mel-spectrogram 간의 차이로 인해 전체 TTS 모델의 성능이 저하됨 - 위 문제를 완화하기 위해서 다음의 2가지 방법을 고려할 수 있음
- Input transcript 외에 AM에 prosody, linguistic feature와 같은 strong condition을 함께 제공하는 방법
- Phoneme-level prosody, word-level prosody, hierarchical prosody 등을 활용하는 방법들이 꾸준히 제시됨
- 한편으로 VQ-VAE나 word embedding 등을 활용할 수도 있음 - 더 나은 training criterion을 설정하는 방법
- 일반적으로 AM은 $L1, L2$ loss를 training criterion으로 사용하므로 acoustic feature distribution이 unimodal임을 가정하게 됨
- 따라서 Flow-TTS, Glow-TTS 등은 normalizing flow를 사용해 더 복잡한 data distribution을 모델링 하지만, invertibility의 한계가 있음
- Input transcript 외에 AM에 prosody, linguistic feature와 같은 strong condition을 함께 제공하는 방법
- 일반적인 TTS pipeline은 input transcript에서 acoustic feature를 예측하는 acoustic model (AM)과 주어진 acoustic feature로부터 waveform을 합성하는 vocoder로 구성된 cascade system을 활용
-> 그래서 기존의 mel-spectrogram에서 벗어나 self-supervised Vector-Quantized acoustic feature를 acoustic feature로 사용하는 VQTTS를 제안
- VQTTS
- AM으로써 txt2vec을 활용하고 vocoder로써 vec2wav를 사용
- txt2vec은 time-frequency axis에 대해 highly-correlate 된 mel-spectrogram을 예측하는 대신, self-supervised Vector-Quantized (VQ) acoustic feature를 통해 time-axis에 대한 correlation만 고려
- 이를 통해 ground-truth와 예측된 acoustic feature 간의 차이를 줄임 - vec2wav는 discontinuous quantized feature를 smoothing 하기 위해 HiFi-GAN generator 이전에 additional feature encoder를 도입
< Overall of VQTTS >
- Self-supervised Vector-Quantized acoustic feature을 기반으로, acoustic model로써 txt2vec, vocoder로써 vec2wav를 활용
- 결과적으로 mel-spectrogram을 기반으로 하는 기존 cascade TTS 모델들보다 더 우수한 성능을 달성
2. Self-Supervised VQ Acoustic Feature
- Automatic Speech Recognition (ASR)에서 neural network를 통해 추출된 acoustic feature는 기존 acoustic feature 보다 우수한 것으로 밝혀짐
- 여기서 해당 neural network는 일반적으로 self-supervised 방식으로 speech data 만을 사용하여 training 됨
- 즉, raw speech waveform $\mathcal{X}$를 input으로 하여 speech segment의 characteristic을 represent 하는 feature $\mathcal{Z}$를 생성함
- 대표적으로 wav2vec은 contrastive loss를 사용해 최적화된 multi-layer convolutional network를 training 함 - Vector quantization은 self-supervised feature extraction에 적용됨
- 대표적으로 VQ-Wav2Vec은 gumbel-softmax나 $k$-means를 사용하여 acoustic feature $\mathcal{Z}$를 VQ acoustic feature $\hat{\mathcal{Z}}$로 quantize 함
- 이후 $\hat{\mathcal{Z}}$는 ASR initialization을 위한 BERT를 training 하는 데 사용됨
- 이때 codebook에서 적은 양의 vector만 사용되는 mode collapse를 피하기 위해 VQ-wave2vec은 $\hat{\mathcal{Z}}$의 dimension을 2개의 group으로 나누어 개별적으로 quantize 함 - 한편으로 wav2vec 2.0은 codebook에서 더 많은 vector를 활용하도록 contrastive loss와 diversity loss를 통해 feature extractor와 BERT를 jointly training 함
- HuBERT의 경우, feature extractor와 codebook을 jointly training 하면서 $k$-means를 사용하여 feature를 사전에 clustering 하는 방식을 사용함
- 대표적으로 VQ-Wav2Vec은 gumbel-softmax나 $k$-means를 사용하여 acoustic feature $\mathcal{Z}$를 VQ acoustic feature $\hat{\mathcal{Z}}$로 quantize 함
- 이때 self-supervised VQ acoustic feature를 기존의 ASR task 외에, TTS 작업에 사용하는 것을 고려할 수 있음
- 여기서 해당 neural network는 일반적으로 self-supervised 방식으로 speech data 만을 사용하여 training 됨
3. VQTTS
- VQTTS는 음성 합성을 위해 self-supervised VQ acoustic feature를 사용함
- 이때 VQ acoustic feature로부터 waveform을 reconstruct 하기 위해서는 additional prosody feature가 필요함
- 따라서 논문에서는 log pitch, energy, probability of voice (POV)를 포함하는 3-dimensional prosody feature를 사용
- 여기서 prosody feature는 zero mean, unit variance가 되도록 normalize 됨 - 이렇게 얻어지는 VQ acoustic feature와 3-dimensional prosody feature의 조합을 $\text{VQ&pros}$라고 하자
- 그러면 VQTTS는 input phoneme sequence에서 $\text{VQ&pros}$를 예측하는 acoustic model인 txt2vec과 $\text{VQ&pros}$에서 waveform을 생성하는 vocoder인 vec2wav로 구성됨
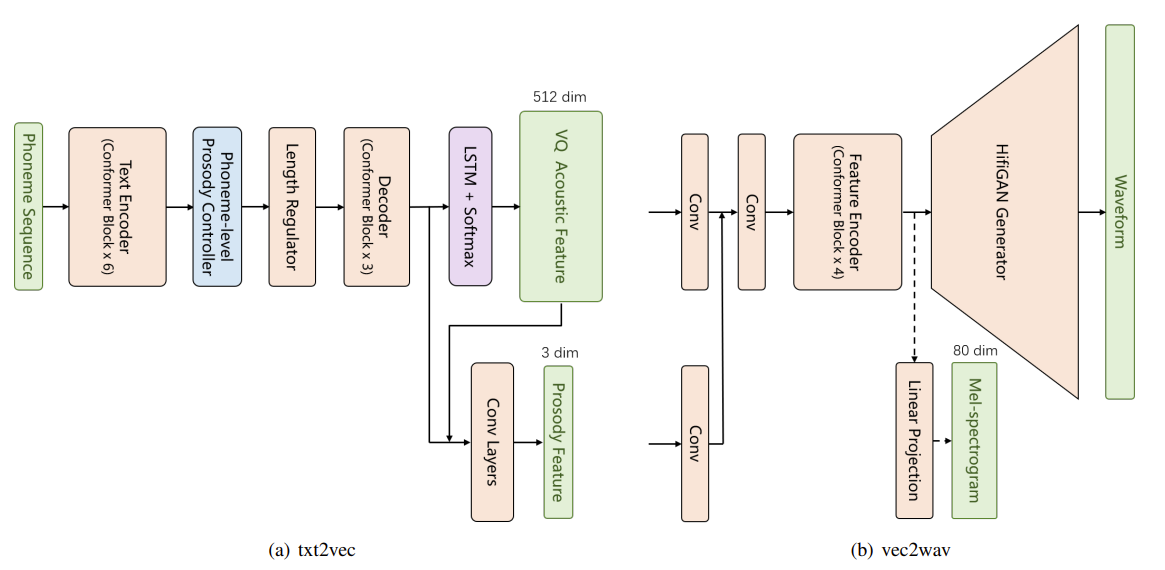
- txt2vec
- Model Architecture
- txt2vec을 training 하기 전에, 모든 phoneme에 대한 phoneme-level (PL) prosody를 label 함
- 이때 txt2vec의 architecture는
- Text encoder는 input phoneme을 hidden state $\mathbf{h}$로 encoding 하는 6개의 Conformer block으로 구성됨
- 이후 hidden state는 PL prosody label을 예측하는 PL prosody controller와 각 phoneme의 duration을 예측하는 duration predictor로 전달됨
- 그리고 FastSpeech2와 같이 해당하는 phoneme duration에 따라 hidden state를 repeat 함 - Decoder는 3개의 Conformer block으로 구성되고, output은 LSTM layer 이후에 VQ acoustic feature classification을 위해 softmax activation으로 전달됨
- 다음으로 decoder output과 VQ acoustic feature는 concatenate 되어 4개의 convolution layer로 전달됨
- 각 layer는 prosody feature prediction을 위해 layer normalization, dropout layer를 포함함
- Text encoder는 input phoneme을 hidden state $\mathbf{h}$로 encoding 하는 6개의 Conformer block으로 구성됨
- Phoneme duration과 prosody feature는 각각 $L2, L1$ loss로 training 되고 PL prosody label과 VQ acoustic feature는 cross-entropy loss로 training 됨
- 결과적으로 overall training criterion은:
(Eq. 1) $\mathcal{L}_{\text{txt2vec}}=\mathcal{L}_{\text{PL_lab}}+\mathcal{L}_{\text{dur}}+\mathcal{L}_{\text{VQ}}+\mathcal{L}_{\text{pros}}$
- Phoneme-Level Prosody Labelling
- VQTTS는 3-dimensional normalized prosody feature $\mathbf{p}$를 사용하고, 해당하는 dynmaic feature $\Delta\mathbf{p}, \Delta^{2}\mathbf{p}$를 계산함
- 총 9-dimensional prosody feature $[\mathbf{p}, \Delta\mathbf{p}, \Delta^{2}\mathbf{p}]$는 각 prosody 내의 frame에 대해 average 되므로, 각 phoneme의 prosody를 하나의 vector로 represent 할 수 있음
- 이후 모든 PL prosody representation을 $k$-means를 사용하여 $n$ class로 clustering 한 다음, 해당 cluster index를 PL prosody label로 사용 - PL prosody controller의 architecture는 아래 그림과 같음
- LSTM을 사용하여 text encoder output $\mathbf{h}$에서 PL prosody label을 예측하도록 training 됨
- 이후 quantized PL prosody ($k$-means cluster의 center)가 project 되고, following acoustic feature generation을 control 하기 위해 $\mathbf{h}$에 추가됨
- Training에서는 ground-truth quantized PL prosody를 사용하고, 추론 시에는 예측된 PL prosody를 사용
- VQTTS는 3-dimensional normalized prosody feature $\mathbf{p}$를 사용하고, 해당하는 dynmaic feature $\Delta\mathbf{p}, \Delta^{2}\mathbf{p}$를 계산함

- Beam Search Decoding
- txt2vec에는 2개의 LSTM이 존재하는데, 이는 각각 PL prosody label과 VQ acoustic feature에 대한 autoregressive prediction에 사용됨
- Training 중에 두 LSTM은 input과 ground-truth previous output에 따라 condition 되고, 추론 시에는 Beam Search Decoding을 사용함
- 이때 decoding은 all-zero vector $\text{<sos>}$에서 시작함
- Beam size를 $k$라고 했을 때, 각 decoding step에서 모든 current hypothesis에 대해 top $k$ class를 고려하고, 새로운 $k$ hypothesis로써 top $k$ probability를 사용해 result를 취하도록 함
- History를 기반으로 각 step에서 best result를 선택하는 greedy search decoding에 비해 beam search decoding은 history와 future를 모두 고려할 수 있음
- vec2wav
- Model Architecture
- 먼저 vec2wav에서 VQ acoustic feature와 prosody feature는 모두 channel이 각각 92, 32이고 kernel size가 5인 convolution layer로 변환됨
- 이후 두 output이 concatenate 되고 convolution layer, feature encoder, HiFi-GAN generator 순으로 전달됨 - Feature encoder는 discontinuous quantized acoustic feature를 smoothing 하기 위해 사용됨
- 구조적으로는 4개의 Conformer block으로 구성되고, 각 block은 2개의 attention head, 384-dimensional self-attention을 가짐 - 최종적으로 HiFi-GAN generator를 통해 waveform을 생성하고, 이때 HiFi-GAN의 training criterion은 vec2wav의 최적화에 사용됨
- 먼저 vec2wav에서 VQ acoustic feature와 prosody feature는 모두 channel이 각각 92, 32이고 kernel size가 5인 convolution layer로 변환됨
- Multi-task Warmup
- HiFi-GAN loss 만으로 vec2wav를 scratch로 training 하면 제대로 수렴하지 않는 것으로 나타남
- 따라서 linear projection layer를 추가로 사용하여 feature encoder output에서 mel-spectrogram을 예측하는 multi-task warmup을 적용하고, 이때 warmup training criterion은:
(Eq. 2) $\mathcal{L}_{\text{vec2wav}}=\mathcal{L}_{\text{HiFiGAN}}+\alpha\mathcal{L}_{\text{mel}}$
- Warmup 이후에는 $\alpha=0$으로 설정하여 mel-spectrogram 예측 과정을 제거함
4. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : Tacotron2, Glow-TTS, FastSpeech2, VITS
- Results
- Speech Reconstruction with Vocoders
- Mel-spectrogram과 달리 VQ feature에 대해서는 vec2wav가 HiFi-GAN 보다 더 나은 reconstruction 성능을 보임
- 특히 PESQ 측면에서 HiFi-GAN은 낮은 성능을 보이는데, 이는 quantization으로 인해 information loss가 발생하기 때문
- 결과적으로 discontinuous quantized input feature로 인해 undesired artifact가 발생할 가능성이 높음

- Naturalness of Text-to-Speech Synthesis
- VQTTS는 high-fidelity, natural speech를 생성할 수 있음
- 특히 기존의 cascade TTS 모델들과 비교하여 VQTTS는 가장 뛰어난 성능을 보임

- Prosody Diversity in PL Prosody Hypothesis
- TTS는 transcript 외에도 다양한 prosody를 포함하기 때문에 기본적으로 one-to-many mapping 문제를 가짐
- 특히 VQTTS는 PL prosody controller를 사용해 diversity를 모델링하므로, beam search에서 서로 다른 PL prosody hypothesis를 사용하여 control 할 수 있음
- 실제로 3가지의 prosody hypothesis에 대한 pitch track을 확인해 보면 VQTTS는 다양한 prosody를 모델링할 수 있음

- Decoding Algorithm
- PL prosody label과 VQ acoustic feature에 대한 beam search decoding의 효과를 확인해보면
- Beam search decoding의 accuracy는 greedy search 보다 뛰어남
- 특히 5의 beam size는 PL prosody labrel prediction에 유용하고 10의 beam size는 VQ acoustic feature prediction에 유용함


반응형
'Paper > TTS' 카테고리의 다른 글
댓글