

티스토리 뷰
Paper/TTS
[Paper 리뷰] FastSpeech2: Fast and High-Quality End-to-End Text to Speech
feVeRin 2023. 7. 21. 12:23반응형
FastSpeech2: Fast and High-Quality End-to-End Text to Speech
- FastSpeech와 같은 non-autoregressive Text-to-Speech (TTS) 모델은 빠르게 음성합성이 가능함
- FastSpeech는 duration prediction과 knowledge distillation을 위해 autoregressive teacher 모델에 의존적임
- Teacher-student distillation 과정이 복잡하고 시간 소모적임
- Teacher 모델에서 추출한 duration이 정확하지 않고 target mel-spectrogram의 단순함으로 인해 정보 손실이 발생함
- FastSpeech 2
- Teacher의 단순화된 output 대신 ground-truth를 직접 학습하여 one-to-many 매핑 문제 해결
- Conditional input에 대한 음성의 variation information (pitch, energy, duration) 도입
- 논문 (ICLR 2021) : Paper Link
- 해당 논문의 Baseline : FastSpeech 리뷰
1. Introduction
- 기존의 TTS 모델은 text에서 autoregressive 하게 mel-spectrogram을 생성한 다음, 별도의 vocoder를 사용하여 생성된 mel-spectrogram에서 음성을 합성하는 방식을 사용함
- 느린 추론 속도, robustness (word skipping, repeating) 문제
- Non-autoregressive 모델은 이러한 문제를 해결
- FastSpeech는 가장 성공적인 non-autoregressive 모델 중 하나
- Autoregressive teacher 모델에서 생성된 mel-spectrogram을 사용하여 target의 data variance를 줄임 (Knowledge Distillation)
- Mel-spectrogram 시퀀스와 일치하도록 duration 정보를 활용 (teacher 모델의 attention map에서 추출)
- FastSpeech는 one-to-many 매핑을 쉽게하지만 단점도 존재
- Two-stage teacher-student training은 모델 학습 과정을 복잡하게 만듦
- Teacher 모델에서 생성된 target mel-spectrogram은 ground-truth에 비해 정보 손실이 존재함
- 생성된 mel-spectrogram으로부터 합성된 오디오 품질은 ground-truth보다 좋지 않기 때문 - Teacher 모델의 attention map에서 추출한 duration이 정확하지 않음
-> 그래서 FastSpeech의 단점을 해결하고 non-autoregressive TTS에서 one-to-many 매핑 문제를 처리할 수 있는 FastSpeech 2를 제안
- FastSpeech 2
- Teacher-student distillation에서 data 단순화로 인한 정보 손실을 방지하기 위해 teacher의 output 대신 ground-truth target으로 FastSpeech2를 직접 학습시킴
- Text 시퀀스와 mel-spectrogram 사이의 information gap을 줄이고 non-autoregressive TTS의 one-to-many 매핑 문제를 해결하기 위해 pitch, energy, duation을 포함한 variation information을 도입
- 학습 단계에서는 target speech waveform에서 직접 추출하고 추론 단계에서는 예측된 값을 사용
- Pitch가 가장 중요하고 예측하기 어려운 점을 고려해 continuous wavelet transform을 활용 - 음성 합성을 단순화하기 위해 mel-spectrogram을 intermediate output으로 사용하지 않고 text로부터 직접 음성을 생성하는 FastSpeech 2s 제시
< Overall of FastSpeech 2 >
- 학습 파이프라인을 단순화하여 FastSpeech 보다 3배 빠른 학습 속도 달성
- TTS의 one-to-many 매핑 문제를 해결하여 더 나은 음성 품질 달성
- FastSpeech 2s는 text로 부터 직접 음성을 생성하여 높은 음성 품질을 유지하면서 추론 파이프라인을 단순화
2. FastSpeech 2 and 2s
- Motivation
- TTS는 전형적인 one-to-many 문제로 볼 수 있음
- 음성 시퀀스의 pitch, duration, sound volume, prosody 같은 여러 variation들이 text 시퀀스에 대응할 수 있기 때문 - Non-autorgressive TTS에서 유일한 input 정보는 text임
- 음성의 variance를 예측하기에는 충분하지 않음
- Target speech의 variation에 overfit 되기 쉬워 generalization 능력이 떨어짐 - FastSpeech는 복잡한 학습 파이프라인, mel-spectrogram의 정보 손실, 정확하지 않은 duration 측정으로 인해 one-to-many 매핑 문제 해결에 부적합함
- Model Overview
- FastSpeech 2의 architecture
- Encoder는 phoneme embedding 시퀀스를 phoneme hidden 시퀀스로 변환
- Variance adaptor가 duration, pitch, energy와 같은 다양한 variance information을 hidden 시퀀스에 추가
- Mel-spectrogram decoder는 hidden 시퀀스를 mel-spectorgram 시퀀스로 변환
- FastSpeech 2의 Encoder, Mel-spectrogram decoder 구조
- Self-attention layer와 Feed-forward Transformer 블록 사용
- Feed-forward Transformer 블록은 FastSpeech의 1D-convolution layer stack과 동일
- FastSpeech와의 차이점
- Teacher-student distillation 파이프라인을 제거하고 ground-truth mel-spectrogram을 학습 target으로 사용
- Distill된 mel-spectrogram의 정보 손실을 방지하고 음성 품질을 향상 - Variance adaptor는 duration, energy, pitch predictor로 구성
- Duration predictor는 forced alignment로 얻어진 phoneme duration을 활용
- Pitch, Energy predictor는 더 많은 variance information을 제공하여 TTS의 one-to-many 매핑 문제를 완화 - 학습 파이프라인을 단순화하여 end-to-end 시스템인 FastSpeech 2s를 구성
- Text로 부터 직접 waveform을 생성하는 방식
- Cascaded mel-spectrogram 생성 (acoustic model), waveform 생성 (vocoder) 단계를 거치지 않음
- Teacher-student distillation 파이프라인을 제거하고 ground-truth mel-spectrogram을 학습 target으로 사용

- Variance Adaptor
- Variance adaptor는 TTS의 one-to-many 매핑에 대한 variant 음성을 예측하기 위해 phoneme hidden 시퀀스에 variance inofrmation을 추가해 주는 것을 목표로 함
- Phoneme duration : 음성이 얼마나 오래 들리는지를 나타냄
- Pitch : 감정을 전달하는 핵심 특징으로 speech prosody에 큰 영향을 미침
- Energy : mel-spectrogram의 frame-levle magnitude를 나타냄, 음성의 prosody, volume에 영향을 미침
- 감정, 스타일, 화자와 같은 variance information을 더 추가할 수도 있음
- Variance adaptor의 구성
- Duration predictor, Pitch predictor, Energy predictor로 구성
- Hidden sequence로부터 target speech를 예측하기 위해 녹음에서 추출된 duration, pitch, energy의 ground-truth value를 사용
- 각 predictor는 유사한 모델 구조를 사용
- ReLU activation이 포함된 2-layer 1D-convolutional network
- Layer noramlization, dropout layer, hidden state를 output 시퀀스로 projection 하기 위한 extra linear layer
- Duration Predictor
- Phoneme hidden 시퀀스를 입력으로 사용해 phoneme에 대응하는 mel frame 수를 나타내는 각 phoneme의 duration을 예측함
- 쉬운 예측을 위해 log로 변환 - Mean Square Error (MSE)로 최적화되고, training target의 duration을 추출
- FastSpeech에서 pre-train된 autoregressiv TTS 모델을 통해 phoneme duration을 추출하는 대신 alignment accuracy를 개선
- 모델의 input, ouput 간의 information gap을 줄임
- Montreal Forced Alignment (MFA) 사용
- Phoneme hidden 시퀀스를 입력으로 사용해 phoneme에 대응하는 mel frame 수를 나타내는 각 phoneme의 duration을 예측함
- Pitch Predictor
- Ground-truth pitch의 variation이 크기 때문에 예측된 pitch의 분포는 ground-truth 분포와 매우 다름
- Continuous Wavelet Transform (CWT)를 사용해 continuous pitch series를 pitch spectrogram으로 decompose 하고 pitch spectrogram을 MSE loss로 최적화하여 pitch predictor를 학습
- 추론 과정에서는 inverse CWT (iCWT)를 사용하여 pitch spectrogram을 예측
- 각 frame의 pitch $F_{0}$를 log-scale에서 256개의 가능한 값으로 quantization하고 pitch embedding vector $p$로 변환한 다음 hidden 시퀀스에 추가
- Energy Predictor
- 각 Short-Time Fourier Transform (STFT) frame 진폭의 L2 norm를 energy로 사용
- Pitch와 비슷하게 각 frame의 energy를 256개의 가능한 값으로 quantization하고 energy embeddign $e$를 hidden 시퀀스에 추가
- Energy predictor를 사용하여 quantization된 값 대신 energy의 원래 값을 예측하고 MSE loss로 최적화함
- FastSpeech 2s
- End-to-end waveform 생성을 위해 FastSpeech 2를 FastSpeech 2s로 확장
- FastSpeech 2s는 cascaded mel-spectrogram 생성과 waveform generation 없이 text로부터 직접 waveform을 생성
- FastSpeech 2s는 intermediate hidden에서 waveform conditioning을 생성하여 mel-spectrogram decoder를 사용하지 않고도 cascaded 방식과 비슷한 성능을 달성할 수 있음
- Challenges in Text-to-Waveform Generation
- Waveform에 mel-spectrogram보다 더 많은 variance information (e.g., phase)이 포함되어 있음
- Input과 ouput 사이의 information gap이 text-to-spectrogram 생성보다 큼 - 긴 waveform sample과 GPU 메모리 한계로 인해 전체 text 시퀀스에 해당하는 audio clip을 학습하기 어려움
- 짧은 audio clip은 partial text 시퀀스에서 phoneme 간의 관계를 캡처하기 어렵게 만들어 text 특징 추출을 방해함
- Waveform에 mel-spectrogram보다 더 많은 variance information (e.g., phase)이 포함되어 있음
- FastSpeech 2s
- Text-to-Waveform 생성 문제를 해결하기 위해 waveform decoder의 설계를 변경
1. Variance predictor를 사용하여 phase 정보를 예측하기 어려움
: Waveform decoder에서 adversarial training을 도입하여 자체적으로 phase information을 implicitly recover 하도록 함
2. FastSpeech 2 mel-spectrogram decoder의 활용
: Text 특징 추출을 돕기 위해 전체 text 시퀀스에 대해서 학습이 이루어짐 - Waveform decoder는 non-causal convolution과 gated activation을 포함하는 WaveNet 구조를 사용
- 짧은 audio clip에 해당하는 sliced hidden 시퀀스를 입력으로 사용
- Audio clip의 길이와 일치하도록 transposed 1D convolution으로 upsample - Adversarial training을 위한 discriminator는 Parallel WaveGAN과 동일한 구조를 사용
- Leaky ReLU activation이 있는 non-casual dilated 1D convolution layer 10개로 구성 - Waveform decoder는 multi-resolution STFT loss와 Parallel WaveGAN의 LSGAN discriminator loss에 의해 최적화됨
- 추론 단계에서는 mel-spectrogram decoder를 사용하지 않고 waveform decoder만 사용하여 음성을 합성함
- Text-to-Waveform 생성 문제를 해결하기 위해 waveform decoder의 설계를 변경
- Discussions
- FastSpeech 2, FastSpeech 2s와 기존 TTS 모델들 간의 차이
- Deep Voice, Deep Voice 2 등의 autogressive 모델
: FastSpeech 2, 2s는 self-attention 기반의 feed-forward network를 사용하여 waveform을 병렬로 생성 - 기존 non-autoregressive 모델
: 기존의 non-autorgressive 모델은 duration accuracy를 개선하는데 중점을 두지만, FastSpeech 2, 2s는 input, output 간의 information gap을 줄이기 위해 variation information을 사용 - ClariNet과 같은 text-to-waveform 모델
: autoregressive acoustic model과 non-autoregressive vocoder를 동시에 학습하지만, FastSpeech 2, 2s는 완전한 non-autoregressive 모델에 기반 - Non-autoregressive vocoder
: Time-aligned linguistic 특징을 waveform으로 변환하고 별도의 linguistic, acoutstic model을 필요로 하지만, FastSpeech 2, 2s는 linguistic, mel-spectrogram 특징 없이 phoneme sequence에서 바로 waveform을 합성
- Deep Voice, Deep Voice 2 등의 autogressive 모델
3. Experiments and Results
- Settings
- Dataset : LJSpeech
- Comparisons : FastSpeech, Tacotron 2, Transformer TTS
- Model Performance
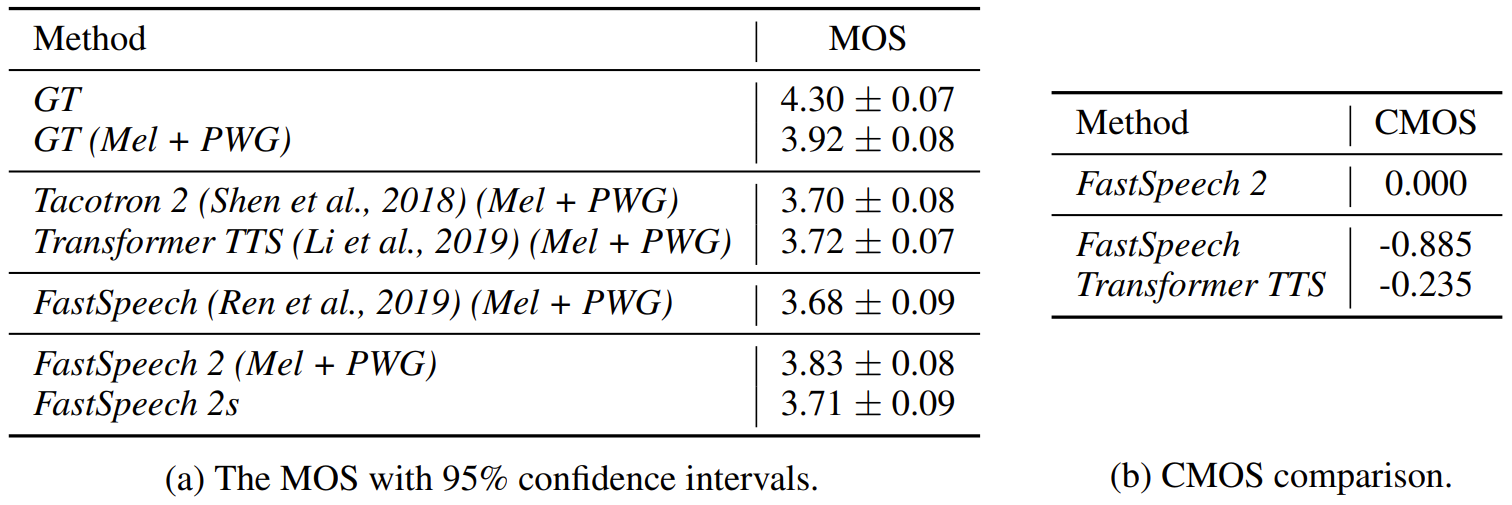
- Audio Quality
- FastSpeech 2가 autoregressive model인 Transformer TTS, Tacotron 2와 비슷한 음성 품질을 달성
- FastSpeech 2는 FastSpeech의 품질을 능가함
- Variance information을 활용하고 teacher-student distillation 없이 ground-truth 음성을 target으로 학습한 효과
- Training and Inference Speedup
- FastSpeech 2는 FastSpeech와 비교하여 3.12배의 학습 속도 향상을 보임
- Transformer TTS와 비교하여 FastSpeech 2, 2s는 각각 47.8, 51.8배의 오디오 생성 속도 향상을 보임
- FastSpeech 2s는 end-to-end 방식을 사용하기 때문에 FastSpeech 2보다 빠름

- Analysis on Variance Information
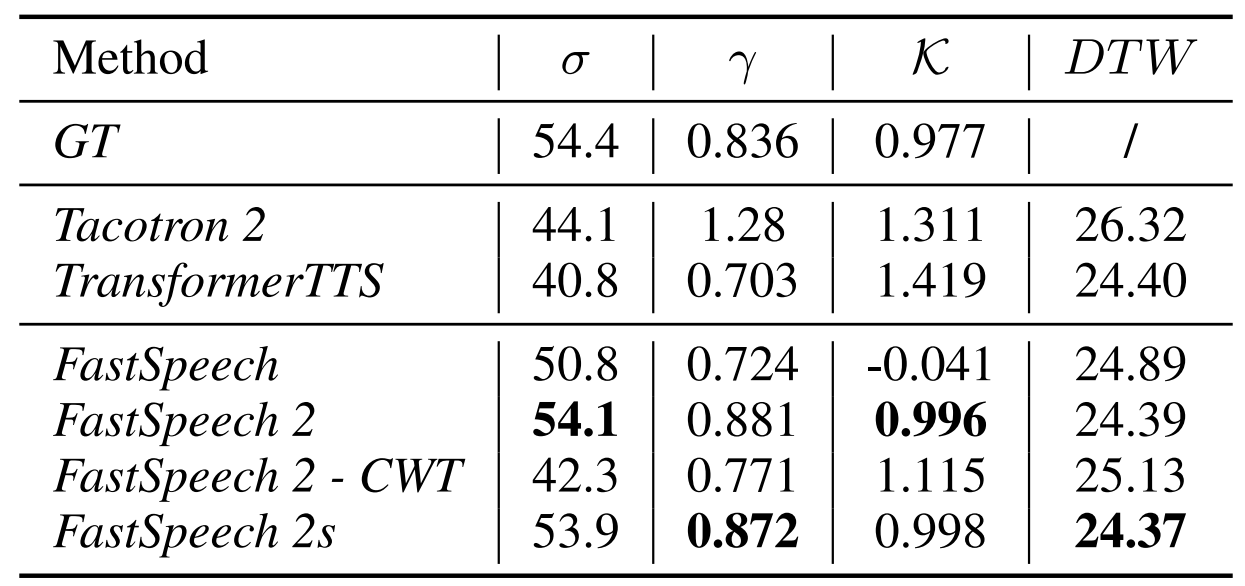
- More Accurate Variance Information in Synthesized Speech
- 표준편차 ($\sigma$), 왜도($\gamma$), 첨도($K$), average Dynamic Time Warping (DTW) distance에 대해 비교
- FastSpeech와 비교했을 때,
- FastSpeech 2, 2s에서 생성된 오디오의 $\sigma, \gamma, K$가 ground-truth에 더 가까움
- FastSpeech 2, 2s에서 생성된 오디오 pitch와 ground-truth pitch 사이의 avearge DTW distance도 더 작음 - FastSpeech 2, 2s가 더 자연스러운 pitch contour를 생성할 수 있음
- 더 나은 prosody를 가지는 음성을 생성 가능
- Energy의 경우 생성된 waveform에서 추출된 frame별 energy와 ground-truth 간의 Mean Absolute Error (MAE)를 계산
- FastSpeech 2, 2s의 energy는 FastSpeech 보다 작음
- FastSpeech 2, 2s가 Ground-truth와 유사한 energy로 음성을 합성하는 것을 의미
- FastSpeech 2, 2s의 energy는 FastSpeech 보다 작음

- More Accurate Duration for Model Training
- FastSpeech 2에서 적용된 MFA가 FastSpeech의 teacher 모델보다 더 정확한 duration을 생성할 수 있음
- CMOS 측면에서 비교했을 때 MFA를 통한 더 정확한 duration 정보가 FastSpeech의 음성 품질을 향상 시킴

- Ablation Study
- Pitch and Energy Input
- FastSpeech 2, 2s에서 energy를 제거하면 음성 품질의 저하가 발생함
- Pitch를 제거하는 경우 -0.245, -1.130의 CMOS 저하가 발생함
- Pitch와 energy를 모두 제거하는 경우 현저한 품질 저하가 발생함
- Predicting Pitch in Frequency Domain
- CWT의 효과를 확인하기 위해 예측된 pitch와 ground-truth 사이의 average DTW distance를 계산
- CWT가 사용되지 않은 경우 0.185, 0.201의 CMOS 저하가 발생
- CWT가 pitch를 더 잘 모델링할 수 있음
- Mel-spectrogram Decoder in FastSpeech 2s
- Mel-spectrogram decoder를 제거했을 때 0.285 CMOS 저하가 발생
- Mel-spectrogram decoder가 고품질 waveform 생성에 필수적임
- Mel-spectrogram decoder를 제거했을 때 0.285 CMOS 저하가 발생

반응형
'Paper > TTS' 카테고리의 다른 글
댓글