

티스토리 뷰
Paper/TTS
[Paper 리뷰] Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search
feVeRin 2023. 12. 20. 12:21반응형
Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search
- Parallel text-to-speech 모델은 externel aligner의 guidance 없이 학습하기 어려움
- Glow-TTS
- Externel aligner가 필요 없는 flow-based parallel text-to-speech 모델
- Flow property와 dynamic programming을 결합한 monotonic alignment search의 도입
- Hard monotonic alignment를 사용하면 robust한 생성이 가능하고 flow를 활용하면 빠르고 다양한 생성이 가능
- 논문 (NeurIPS 2020) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 text에 해당하는 speech를 생성하는 것을 목표로 함
- Tacotron2와 같은 autoregressive 모델은 합성 품질은 우수하지만 실시간 서비스에 배포하기에 적합하지 않음
- Length에 따라 추론 시간이 선형적으로 증가하기 때문
- Robustness가 부족해 input text에 반복되는 단어가 포함되어 있는 경우, attention error가 발생함
- Tacotron2와 같은 autoregressive 모델은 합성 품질은 우수하지만 실시간 서비스에 배포하기에 적합하지 않음
- Autoregressive 모델의 한계를 극복하기 위해 FastSpeech와 같은 parallel TTS 모델이 등장
- Autoregressive 모델보다 빠르게 mel-spectrogram을 합성할 수 있음
- FastSpeech의 경우 monotonic alignment를 사용해 mispronouncing, skipping, reapting 문제를 회피 - BUT, parallel TTS 모델은 text와 speech 간의 well-aligned attention map이 필요함
- 주로 pre-trained autoregressive 모델을 externel aligner로 활용하여 attention map을 추출
-> 결과적으로 모델의 성능이 externel aligner에 의해 크게 좌우될 수 있음
- Autoregressive 모델보다 빠르게 mel-spectrogram을 합성할 수 있음
-> 그래서 externel aligner에 대한 의존성을 제거하고 자체적인 alignment를 학습할 수 있는 parallel flow-based TTS 모델인 Glow-TTS를 제안
- Glow-TTS
- Flow property와 dynamic programming을 결합해 text와 speech latent representation 사이의 monotonic alignment를 효율적으로 search
- Alignment를 통해 음성의 log-likelihood를 최대화하는 것을 목표로 함 - Hard monotonic alignment 적용 시 long utterance를 일반화하는 robust TTS가 가능
- Flow를 활용하면 빠르고, 다양하고, 제어가능한 TTS가 가능
- Flow property와 dynamic programming을 결합해 text와 speech latent representation 사이의 monotonic alignment를 효율적으로 search
< Overall of Glow-TTS >
- 사람이 단어를 건너뛰지 않고 순서대로 text를 읽는다는 점을 condition으로 활용
- Externel aligner의 필요성을 제거하는 monotonic alignment search의 도입
- Flow-based 모델을 기반으로 하는 다양하고 제어가능한 음성 합성 모델
2. Glow-TTS
- Training and Inference Procedures
- Glow-TTS는 flow-based decoder $f_{dec} : z \rightarrow x$를 통해 조건부 prior 분포 $P_{Z}(z|c)$를 변환하여 mel-spectrogram의 조건부 분포 $P_{X}(x|c)$로 모델링
- $x$ : input mel-spectrogram, $c$ : input text
- Variable의 변화를 기반으로 data에 대한 exact log-likelihood를 계산할 수 있음:
$log P_{X}(x|c) = log P_{Z}(z|c) + log \left | det \frac{ \partial f^{-1}_{dec} (x) }{\partial x} \right |$ - Network parameter $\theta$와 alignment function $A$를 사용해 data와 prior 분포를 parameterize 하면,
- Prior 분포 $P_{Z}$는 isotropic multivariate Gaussian 분포임
- 이때 prior 분포의 $\mu$, $\sigma$는 text encoder $f_{enc}$에 의해 얻어짐
- Text encoder는 text condition $c= c_{1:T_{text}}$를 $\mu = \mu_{1:T_{text}}$와 $\sigma = \sigma_{1:T_{text}}$로 mapping - Alignment function $A$는 음성의 latent representation index에서 $f_{enc} : A(j) = i$의 statistics로의 mapping을 의미
- $z_{j} \sim N(z_{j}, \mu_{i}, \sigma_{i})$
- 이때 Glow-TTS가 text input을 skip/repeat하지 않도록 alignment function $A$가 monotonic하고 surjective하다고 가정 - 이때 얻어지는 prior 분포는:
$log P_{Z} (z|c; \theta, A) = \sum^{T_{mel}}_{j=1} log \mathcal{N} (z_{j} ; \mu_{A(j)}, \sigma_{A(j)})$
- $T_{mel}$ : input mel-spectrogram의 length
- Prior 분포 $P_{Z}$는 isotropic multivariate Gaussian 분포임
- Glow-TTS는 data의 log-likelihood를 최대화하는 parameter $\theta$와 alignment $A$를 찾는 것을 목표로 함
- Training Objective:
$max_{\theta, A} L(\theta, A) = max_{\theta, A} log P_{X}(x|c;A, \theta)$
-> BUT, 전역해를 계산하는 것은 computationally intractable함 - 문제 해결을 위해 objective를 2개의 하위 문제로 decompose 하여 parameter와 alignment에 대한 search space를 줄임
- 현재 parameter $\theta$에 대해 가장 가능성 있는 monotonic alignment $A^{*}$를 탐색:
$A^{*} = argmax_{A} log P_{X}(x|c;A,\theta) = argmax_{A} \sum_{j=1}^{T_{mel}} log \mathcal{N} (z_{j}; \mu_{A(j)}, \sigma_{A(j)})$
-> 이때, 효과적인 탐색을 위해 Monotonic Alignment Search (MAS)가 사용됨 - log-likelihood $logp_{X}(x|c; \theta, A^{*})$를 최대화하기 위해 parameter $\theta$를 업데이트
- 현재 parameter $\theta$에 대해 가장 가능성 있는 monotonic alignment $A^{*}$를 탐색:
- Iterative approach를 활용하여 2가지 하위 문제를 처리함
- 각 training step에서 $A^{*}$를 찾은 다음, gradient descent를 활용하여 $\theta$를 업데이트
- 이때, iterative 과정은 가장 가능성이 높은 hidden alignment의 log-likelihood를 최대화하는 Viterbi training임
-> 결과적으로 modified objective는 전역해를 보장하지는 않지만, 전역해에 대한 합리적인 lower bound를 제공함
- Training Objective:
- 추론 과정에서 Glow-TTS는 가장 가능성이 높은 monotonic alignment $A^{*}$를 추정해야 함
- 이를 위해 alignment $A^{*}$에서 계산된 duration label과 일치하도록 duration predictor $f_{dur}$를 학습시킴:
$d_{i} = \sum_{j=1}^{T_{mel}} 1_{A^{*}(j)=i}, i=1, ..., T_{text}$ - FastSpeech와 같이 text encoder 다음에 duration predictor를 추가하고, logarithmic domain에서 Mean Squared Error (MSE) loss로 학습:
$L_{dur} = MSE(f_{dur} (sg[f_{enc} (c)]), d)$ - Maximum likelihood objective에 영향을 주지 않기 위해, stop gradient operator $sg[\cdot]$을 duration predictor의 input에 적용
- Stop gradient operator는 backward pass에서 input의 gradient를 제거하는 역할 - 추론 과정에서 prior 분포와 alignment의 statistic은 text encoder와 duration predictor에 의해 예측됨
- 이후 prior 분포로부터 latent variable을 sampling 하고,
- Flow-based decoder를 통해 latent variable을 변환하여 mel-spectrogram을 합성
- 이를 위해 alignment $A^{*}$에서 계산된 duration label과 일치하도록 duration predictor $f_{dur}$를 학습시킴:

- Monotonic Alignment Search
- MAS는 input speech와 text에서 가져온 latent variable과 prior 분포 간의 가장 가능성 높은 monotonic alignment를 탐색함
- MAS algorithm은 partial alignment에 대한 reculsive solution을 얻은 다음, 전체 alignment를 찾는 방식임
- $Q_{i,j}$를 prior 분포와 latent variable이 각각 $i$-th, $j$-th element까지 부분적으로 주어지는 maximum log-likelihood라고 하면, $Q_{i,j}$는 $Q_{i-1, j}, Q_{i,j-1}$로 reculsive하게 공식화됨:
$Q_{i,j} = max_{A} \sum_{k=1}^{j} log \mathcal{N} (z_{k}; \mu_{A(k)}, \sigma_{A(k)}) = max(Q_{i-1, j-1} ,Q_{i, j-1}) + log \mathcal{N} (z_{j}; \mu_{i}, \sigma_{i})$
- Partial sequence의 마지막 element인 $z_{j}$와 $\{ \mu_{i}, \sigma_{i} \}$가 align 되면, previous latent variable $z_{j-1}$은 monotonicity와 surjection을 만족시키기 위해 $\{ \mu_{i-1}, \sigma_{i-1} \}$ 또는 $\{ \mu_{i}, \sigma_{i} \}$로 align 되어야 하기 때문
- MAS는 $Q_{T_{text}, T_{mel}}$까지 $Q$의 모든 값을 iterative 하게 계산 - 가장 가능성 높은 alignment $A^{*}$는 recurrence relation에서 어떤 $Q$ 값이 더 큰지를 결정하는 것으로 찾을 수 있음
- $A^{*}$는 모든 $Q$ 값을 caching 하여 dynamic programming으로 계산될 수 있음
- $A^{*}$의 모든 값은 alignment의 마지막 $A^{*} (T_{mel}) = T_{text}$에서 backtracking 됨 - MAS algorithm의 time complexity는 $O(T_{text} \times T_{mel})$
- 학습과정에서 MAS는 20ms의 시간만을 소비함 (전체 학습 시간의 2%)
- 추론과정에서는 duration predictor가 alignment를 추정하는데 사용되므로 MAS가 사용되지 않음


- Model Architecture
- Decoder
- Glow-TTS는 flow-based decoder를 활용해 forward, inverse process를 parallel로 수행
- Training 과정에서는 maximum likelihood 추정 및 internal alignment search를 위해 mel-spectrogram을 latent representation으로 변환
- Inference 과정에서는 parallel decoding을 위해 prior 분포를 mel-spectrogram 분포로 변환 - Activation normalization layer, Invertible $1 \times 1$ convolution layer, Affine coupling layer로 구성된 block을 stack 해 구성
- Local conditiong을 제외한 WaveGlow의 affine coupling layer architecture를 활용 - 계산 효율성을 위해 80-channel mel-spectrogram frame을 time 차원을 따라 두 부분으로 분할
- Flow operation 전에 160-channel feature map으로 grouping
- Jacobian determinant 계산 시간을 줄이기 위해 $1 \times 1$ convolution을 수정
- Glow-TTS는 flow-based decoder를 활용해 forward, inverse process를 parallel로 수행
- Encoder and Duration Predictor
- Encoder는 Transformer-TTS의 encoder architecture를 수정하여 활용
- Positional embedding을 제거하고 relative position representation을 self-attention에 추가
- Encoder pre-net에 residual connection을 추가
- Prior 분포의 statistic을 추정하기 위해 encoder의 마지막에 linear projection layer를 추가 - Duration predictor는 ReLU activation, Layer normalization, Dropout이 포함된 2개의 convolution layer와 projection layer로 구성
- FastSpeech의 duration predictor와 동일
- Encoder는 Transformer-TTS의 encoder architecture를 수정하여 활용
3. Experiments
- Settings
- Dataset : LJSpeech, LibriTTS
- Comparison : Tacotron2
- Results
- Audio Quality
- Temperature가 0.333일 때, Glow-TTS가 가장 좋은 합성 품질을 보임
- 다른 temperature에서도 Glow-TTS의 합성 품질은 Tacotron2 보다 우수함

- Sampling Speed and Robustness
- Sampling Speed
- Glow-TTS의 추론 시간은 length에 관계없이 40ms로 일정하게 나타나지만 Tacotron2의 경우 sequential sampling으로 인해 length에 따라 선형적으로 증가함
-> Glow-TTS는 Tacotron2에 비해 평균 15.7배 빠른 합성 속도를 보임
- End-to-End 설정에서, Glow-TTS의 총 추론 시간은 1.5초
-> 특히 Mel-spectrogram을 합성할 때까지의 추론 시간은 55ms에 불과함 - Robustness
- Character Error Rate (CER) 측면에서, Glow-TTS는 long text에 대해서도 안정적인 성능을 보임
- Sampling Speed

- Diversity and Controllability
- Glow-TTS는 flow-based 모델이기 때문에 다양한 sample을 합성할 수 있음
- Temperature와 Gaussian noise를 변화시켰을 때, 합성된 sample의 pitch track을 비교해 보면,
- Temperature를 변경하면 유사한 intonation을 유지하면서 pitch를 조절할 수 있음 - Positive scalar를 곱하면 speaking rate를 조절할 수 있음

- Multi-Speaker TTS
- Audio Quality
- Multi-speaker의 경우도 마찬가지로 Glow-TTS의 합성 품질이 Tacotron2보다 우수함 - Speaker-Dependent Duration
- 동일한 문장에 대해, 서로 다른 speaker를 사용하여 생성된 음성의 pitch track을 비교해 보면,
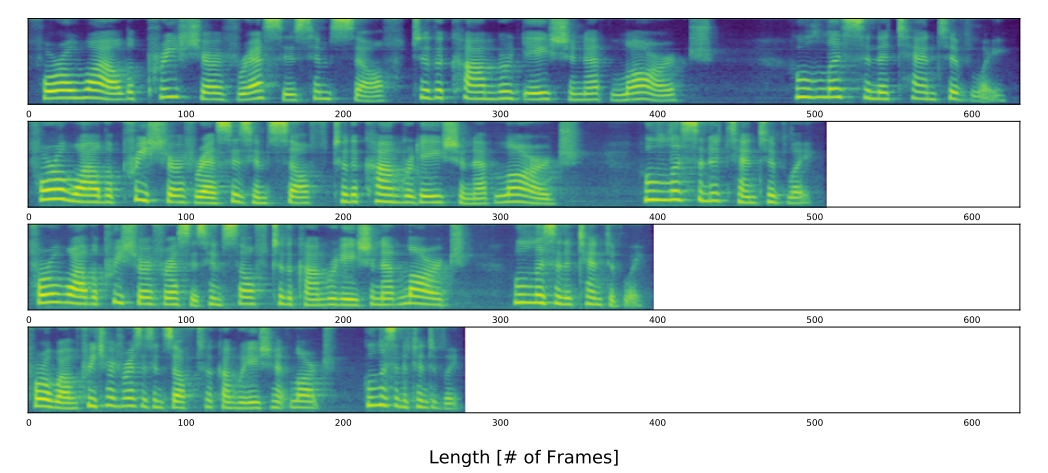
-> Glow-TTS는 speaker 별로 각 input token의 duration을 서로 다르게 예측할 수 있음 - Voice Conversion
- Glow-TTS는 latent representation과 speaker identity를 disentangle 하는 방법을 학습함
- Ground-truth mel-spectrogram을 올바른 speaker identity에 대한 latent representation으로 변환한 다음, dlfmf 다른 speaker identity로 invert 해보면,
-> Converted sample은 유사한 trend를 유지하면서 서로 다른 pitch level을 가짐
- Audio Quality


반응형
'Paper > TTS' 카테고리의 다른 글
댓글