

티스토리 뷰
Paper/TTS
[Paper 리뷰] PAVITS: Exploring Prosody-Aware VITS for End-to-End Emotional Voice Conversion
feVeRin 2024. 5. 2. 09:58반응형
PAVITS: Exploring Prosody-Aware VITS for End-to-End Emotional Voice Conversion
- Emotional voice conversion은 high content naturalness와 high emotional naturalness를 만족해야 함
- PAVITS
- Content naturalness를 향상하기 위해 VITS를 기반으로 하는 end-to-end architecture를 채택
- Acoustic converter와 vocoder를 seamlessly integrating 하여 emotional prosody training과 runtime conversion 간의 mismatch 문제를 해결 - Emotional naturalness를 위해 다양한 emotion의 subtle prosody variation을 모델링하는 emotion descriptor를 도입
- 추가적으로 주어진 emotion label을 기반으로 text로부터 prosody feature를 예측하는 prosody predictor를 사용하고 효과적인 training을 위한 prosody alignment loss를 도입
- Content naturalness를 향상하기 위해 VITS를 기반으로 하는 end-to-end architecture를 채택
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Emotional Voice Conversion (EVC)는 linguistic content, speaker identity를 preserving 하면서 spoken utterance의 emotion을 변환하는 것을 목표로 함
- 이때 EVC는 human voice에 비해 content naturalness가 낮고, emotion richness가 부족한 문제가 있음
- 이를 해결하기 위해, CycleGAN, StarGAN과 같은 frame-based 방식을 도입할 수 있지만 fixed-length nature로 인해 실질적으로 사용하기 어려움
- 한편으로 autoencoder-based 방식은 variable-length generation이 가능하고 text-to-speech (TTS)와의 joint training을 통해 naturalness를 향상할 수 있음 - BUT, speech emotion은 supra-segmental 하므로 여전히 spectrogram으로부터 emotional representation을 학습하는 것은 어려움
- 특히 기존의 EVC 모델들은 일반적으로 acoustic converter와 vocoder로 이루어진 cacade 방식으로 구성되므로 emotional prosody training과 runtime conversion 간의 mismatch가 발생함
- 결과적으로 audio 품질이 저하되므로 content naturalness, emotional experience 모두에 영향을 미침 - 따라서 EVC 모델은 prosody variant를 반영하고 acoustic feature generation과 waveform reconstruction 간의 gap을 해소할 수 있어야 함
- 이를 위해 FastSpeech2, VITS와 같은 end-to-end 동작 방식을 고려할 수 있음
- 이때 EVC는 human voice에 비해 content naturalness가 낮고, emotion richness가 부족한 문제가 있음
-> 그래서 emotional naturalness 향상을 위해 prosody variant를 반영하면서 end-to-end 방식으로 동작하는 PAVITS를 제안
- PAVITS
- VITS를 기반으로 한 end-to-end architecture를 통해 acoustic feature conversion과 waveform reconstruction 간의 mismatch 문제를 해결
- 이를 통해 content naturalness를 향상하고, multi-task learning을 적용하여 TTS의 mispronunciation을 줄임 - Emotional naturalness 향상을 위해, 다양한 emotional state를 capture 하는 emotion descriptor를 도입
- Valence-Arousal-Dominance value를 condition으로 활용하여 utterance-level의 emotional representation을 학습 - 추가적으로 frame-level emotional prosody feature를 예측하는 prosody predictor를 도입하고, audio/text에 대한 modality를 연결하는 prosody alignment loss를 적용
- VITS를 기반으로 한 end-to-end architecture를 통해 acoustic feature conversion과 waveform reconstruction 간의 mismatch 문제를 해결
< Overall of PAVITS >
- Content naturalness를 향상하기 위해 VITS를 기반으로 하는 end-to-end architecture를 채택
- Emotional naturalness를 위해 다양한 emotion의 subtle prosody variation을 모델링하는 emotion descriptor와 prosody predictor를 도입하고, 효과적인 training을 위한 prosody alignment loss를 제시
- 결과적으로 기존 모델들보다 뛰어난 성능을 달성
2. Method
- PAVITS는 아래 그림과 같이 VITS 기반의 conditional variational autoencoder (CVAE)로 구성됨
- 구조적으로 textual prosody prediction module, acoustic prosody modeling module, information alignment module, emotional speech synthesis module의 4가지 component로 구성됨
- 먼저 Textual Prosody Prediction (TPP) module은 prior distribution $p(z_{1}|c_{1})$을 예측함:
(Eq. 1) $z_{1}=TPP(c_{1})\sim p(z_{1}|c_{1})$
- $c_{1}$ : text $t$와 emotion label $e$를 포함 - Acoustic Prosody Modeling (APM) module은 emotion label이 주어진 source audio의 prosody variation, speaker identity, linguistic content를 disentangle 하여 posterior distribution $q(z_{2}|c_{2})$를 얻음:
(Eq. 2) $z_{2}=APM(c_{2})\sim q(z_{2}|c_{2})$
- $c_{2}$ : audio $y$와 emotion label $e$를 포함 - Information Alignment module은 text-speech alignment 뿐만 아니라 textual-acoustic prosody representation의 alignment에도 사용됨
- Emotional Speech Synthesis (ESS) module의 decoder는 latent representation $z$에 따라 waveform $\hat{y}$를 reconstruct 함:
(Eq. 3) $\hat{y}=Decoder(z)\sim p(y|z)$
- $z$는 $z_{1}$ 또는 $z_{2}$에서 얻어짐
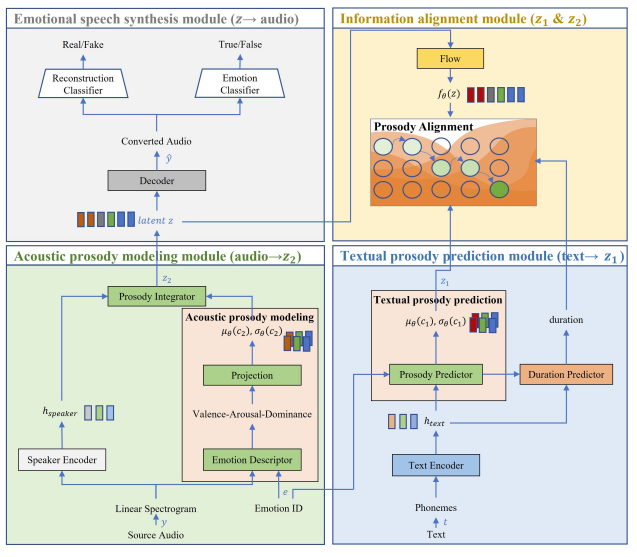
- Textual Prosody Prediction Module
- Text $t$와 emotion label $e$를 포함하는 condition $c_{1}$이 주어지면 Textual Prosody Prediction (TPP) module은 CVAE의 prior distribution $p(z_{1}|c_{1})$을 제공함
- 먼저 text encoder는 phoneme을 input으로 하여 linguistic information $h_{text}$를 추출함
- 이후 각 phoneme과 관련된 prosody variation을 고려하기 위해, prosody predictor를 사용하여 representation을 frame-level로 extend 하고, emotion label을 기반으로 prosody variation을 예측:
(Eq. 4) $p(z_{1}|c_{1}) =\mathcal{N}(f_{\theta}(z_{1});\mu_{\theta}(c_{1});\sigma_{\theta}(c_{1}))\left| \det \frac{\partial f_{\theta}(z_{1})}{\partial z}\right|$
- 즉, prosody variation은 normalizing flow $f_{\theta}$에 의해 생성된 평균 $\mu_{\theta}$, 분산 $\sigma_{\theta}$를 가지는 fine-grained prior normal distribution - Text Encoder
- Training process는 dataset 내의 text content에 의해 제한되기 때문에 preprocessing step에서 character나 text를 phoneme sequence로 변환하여 APM module과의 compatibility를 향상함
- 구조적으로는 VITS와 유사하게 linguistic information을 representing 하기 위한 linear projection layer를 가지는 Feed-Forward Transformer (FFT) block으로 구성됨
- Prosody Predictor
- Prosody predictor는 text encoder에서 추출한 phoneme-level linguistic information을 활용하여 discrete emotion label이 주어진 frame-level prosody variation을 예측함
- 이를 통해 TPP, APM module 모두에 대한 prosody modeling을 개선할 수 있음 - Prosody predictor는 여러 개의 1D convolution layer와 linear projection layer로 구성됨
- 특히 예측된 emotional prosody information을 linguistic information과 duration predictor의 input으로 integrate 하여 emotional speech duration modeling을 지원함
- Prosody predictor는 text encoder에서 추출한 phoneme-level linguistic information을 활용하여 discrete emotion label이 주어진 frame-level prosody variation을 예측함
- Acoustic Prosody Modeling Module
- Acoustic Prosody Modeling (APM) moduledms dimensional emotion representation인 Valence-Dominance value를 기반으로 한 fine-grained prosody variation을 통해 emotional feature를 제공함
- 여기서 speaker identity나 speech content information도 source audio로부터 disentangle 되어 posterior distribution $q(z_{2}|c_{2})$에 대한 prosody integrator를 통해 feature fusion 됨:
(Eq. 5) $q(z_{2}|c_{2})=\mathcal{N}(f_{\theta}(z_{2});\mu_{\theta}(c_{2});\sigma_{\theta}(c_{2}))$ - Speaker Encoder
- APM module은 emotional prosody를 보다 철저하게 understanding 하므로 변환 과정에서 speaker characteristic이 overlook 될 수 있음
- 따라서 speake encoder에 Fundamental frequency $F0$를 반영할 수 있는 $F0$ predictor를 추가함
- 구조적으로는 1D convolution layer와 linear projection layer로 구성
- Emotion Descriptor
- PAVITS의 emotional naturalness를 향상하기 위해, Russles's Cricumplex theory에 기반한 Speech Emotion Recognition system을 사용함
- 이를 통해 Valence-Arousal-Dominance value를 conditional input으로 하여 dimensional emotion representation을 예측
- 해당 input은 nuanced prosody variation을 capture 하여 utterance-level에서 emotion에 대한 human perception을 만족시키고, natural prosody variation이 segment-level에서 frame-level까지 retain 되도록 함
- 구조적으로는 SER module과 linear projection layer로 구성
- Prosody Integrator
- Prosody Integrator는 speaker identity attribute, emotional prosody characteristic, linear spectrogram에서 추출된 intrinsic content property를 통합함
- 구조적으로는 multiple convolution layer, WaveNet residual block, linear projection layer로 구성
- 여기서 speaker identity나 speech content information도 source audio로부터 disentangle 되어 posterior distribution $q(z_{2}|c_{2})$에 대한 prosody integrator를 통해 feature fusion 됨:
- Information Alignment Module
- VITS의 alignment mechanism인 Monotonic Alignment Search (MAS)는 textual, acoustic feature에만 의존함
- 즉, MAS는 emotional prosody nuance를 capture 하지 못하므로 TPP, APM module의 effective linkage를 방해함
- 따라서 PAVITS는 TPP, APM module 전반에 걸쳐 frame-level prosody modeling을 위한 joint training을 지원하는 Kullback-Leibler divergence 기반의 Prosody Alignment Loss를 사용:
(Eq. 6) $L_{psd}=D_{KL}(q(z_{2}|c_{2})||p(z_{1}|c_{1}))$
- Emotional Speech Synthesis Module
- Emotional speech synthesis module에서, decoder는 latent $z$를 기반으로 waveform을 생성하고, adversarial training을 통해 naturalness를 지속적으로 개선함
- Content naturalness를 향상하기 위해 $L_{\text{recon_cls}}$는 예측/target spectrogram 간의 $L1$ distance를 최소화함
- 한편으로 $L_{\text{recon\_fm}}$는 각 discriminator의 intermediate layer에서 추출된 feature map 간의 $L1$ distance를 최소화하여 training stability를 향상함
- Training 중에 $L_{\text{recon_cls}}$는 early-to-mid stage에 영향을 미치고, $L_{\text{recon_fm}}$는 mid-to-late stage에 영향을 주므로, contirbution을 balance 하기 위해 다음과 같이 coefficient를 적용함:
(Eq. 7) $L_{\text{recon}}=\gamma L_{\text{recon\_cls}}+\beta L_{\text{recon\_fm}}(G)$ - 추가적으로 emotion perception을 향상을 위한 loss로써 다음을 사용함:
(Eq. 8) $L_{\text{emo}} = L_{\text{emo\_cls}} +L_{\text{emo\_fm}}(G)$
- $L_{\text{emo\_cls}}$ : emotion classification loss, $L_{\text{emo_fm}}$ : emotion discrimination에 대한 feature matching loss
- Final Loss
- 결과적으로 CVAE와 adversarial training을 결합하면 다음의 final loss를 얻을 수 있음:
(Eq. 9) $L = L_{\text{recon}} + L_{\text{adv}}(G) + L_{\text{emo}} + L_{\text{psd}} + L_{F0} + L_{\text{dur}}$
(Eq. 10) $L(D) = L_{\text{adv}}(D)$
- $L_{\text{adv}}(G), L_{\text{adv}}(D)$ : 각각 generator, discriminator에 대한 adversarial loss
- $L_{F0}$ : 예측된 $F0$와 ground-truth 간의 $L2$ distance
- $L_{\text{dur}}$ : 추정된 alignment로부터 예측된 duration과 ground-truth 간의 $L2$ loss
- Runtime Conversion
- Runtime에서는 fixed-length approach인 PAVITS-FL과 variable-length approach인 PAVITS-VL 두가지를 고려할 수 있음
- PAVITS-FL은 latent $z$를 예측하기 위해 APM module을 사용하고, Dynamic Time Warping (DTW) limitation으로 인해 fixed spectrum length로 제한됨
- PAVITS-FL은 automatic speech recognition을 통해 얻은 text로부터 latent $z$를 예측하기 위해 TPP module을 사용함
- 이를 통해 duration modeling에 제약되지 않으면서 더 높은 naturalness를 제공할 수 있음 - 최종적으로 ESS module의 decoder는 latent $z$를 input으로 하여 별도의 vocoder를 사용하지 않고 waveform으로 변환함
3. Experiments
- Settings
- Dataset : ESD
- Comparisons : CycleGAN, StarGAN, Seq2Seq-WA2, VITS
- Results
- 주관적, 정량적 지표 모두에서 PAVITS는 우수한 성능을 달성함
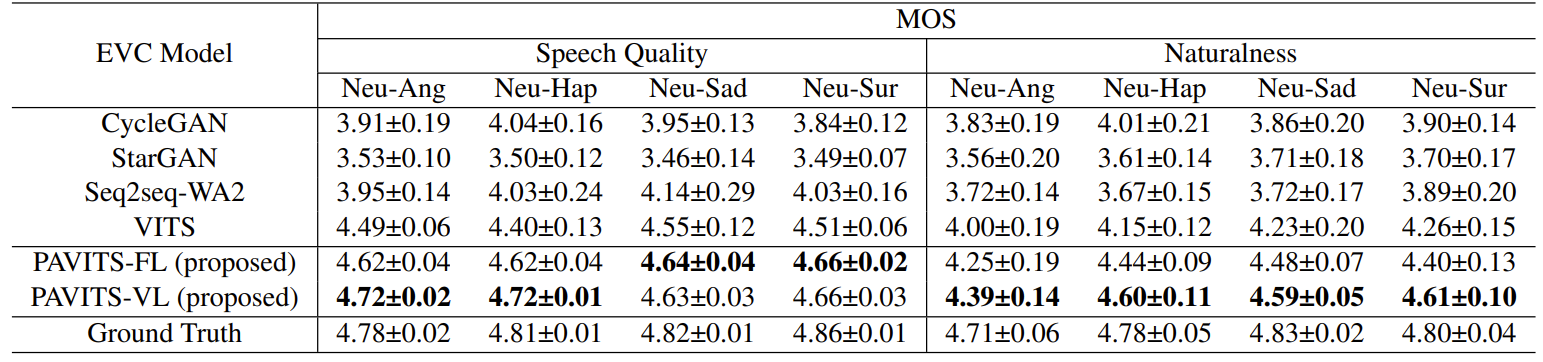

- Emotional Similarity Test 측면에서 PAVITS는 human perception과 가장 가까운 결과를 보임
- 즉, emotion modeling 과정에서 fine-grained granularity를 더 잘 반영할 수 있음

- Mel-Spectrogram 측면에서도 PAVITS는 각 frequency band 내에서 더 detail 한 prosody variant를 나타내면서 다른 frequency band에 대한 descriptive information을 preserving 할 수 있음
- 결과적으로 PAVITS는 ground-truth와 가장 비슷한 naturalness와 emotional accuracy를 보이게 됨

- Ablation study 측면에서, prosody predictor, prosody alignment, prosody integrator를 각각 제거할 때마다 성능 저하가 발생함
- 즉, PAVITS에서 제안된 각 module들을 사용하는 것이 성능 향상에 유효함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글