

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] Say More with Less: Variable-Frame-Rate Speech Tokenization via Adaptive Clustering and Implicit Duration Coding
feVeRin 2026. 2. 11. 13:29반응형
Say More with Less: Variable-Frame-Rate Speech Tokenization via Adaptive Clustering and Implicit Duration Coding
- 기존의 speech tokenizer는 information density나 temporal fluctuation에 관계없이 고정된 token per second를 assign 하므로 speech의 intrinsic structure와 mismatch가 존재함
- VARSTok
- Speech를 variable-length unit으로 adaptively segment 하는 Temporal-Aware Density Peak Clustering을 도입
- Content, temporal span을 single token index에 embed하여 implicit duration coding을 지원
- 논문 (AAAI 2026) : Paper Link
1. Introduction
- SoundStream, AudioDec, RepCodec과 같은 neural audio codec은 continuous speech signal을 discrete token sequence로 convert 하여 speech tokenization을 수행함
- 특히 해당 tokenized speech는 CosyVoice와 같은 Large Language Model (LLM)를 bridge할 수 있음
- BUT, 기존의 acoustic tokenizer는 fixed frame rate를 따라 token을 uniformly allocate 하므로 speech의 underlying content나 information density를 ignore 함
- 이로 인해 inefficient token usage와 poor alignment가 발생할 수 있음
-> 그래서 dynamic frame rate를 modeling 할 수 있는 VARSTok를 제안
- VARSTok
- Local similarity에 따라 token을 adaptively allocate 하는 Temporal-Aware Clustering algorithm을 채택
- Downstream LLM에서 auxiliary duration predictor에 대한 의존성을 제거하기 위해 content, duration을 single token index에 embed 하는 Implicit Duration Coding scheme을 도입
< Overall of VARSTok >
- Temporal-Aware Clustering, Implicit Duration Coding을 활용한 variable-frame-rate speech tokenizer
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Overview
- VARSTok는 local speech feature similarity에 따라 token을 adaptively allocate 함
- 특히 기존 fixed-rate tokenizer와 달리 redundant region에서는 token usage를 reduce 하고 rich variation에서는 더 많은 token을 assign 하여 better alignment와 intrinsic fluctuation modeling을 지원함
- 구조적으로 VARSTok는 speech encoder, temporal-aware density peak clustering module, VQ module, speech decoder의 4가지 component로 구성됨
- 먼저 speech encoder는 raw waveform을 frame-level embedding $\mathbf{X}=[\mathbf{x}_{1},...,\mathbf{x}_{T}]\in\mathbb{R}^{T\times H}$로 transform 함
- $T$ : frame 수, $H$ : embedding dimension - Adjacent frame은 temporal-aware density peak clustering module을 통해 local feature similarity에 기반하여 $N$ variable-length cluster $\mathcal{C}=\{\mathcal{C}_{1},...,\mathcal{C}_{N}\}$으로 adaptively group 됨
- 각 cluster $\mathcal{C}_{n}$은 mean-pooled embedding $\mathbf{z}_{n}\in\mathbb{R}^{H}$로 summarize 되고 size $K$의 single codebook $\mathcal{E}=\{\mathbf{e}_{0},...,\mathbf{e}_{K-1}\}$를 가지는 VQ module로 quantize 됨
- $\mathbf{e}_{k}$ : $k$-th codebook entry - 각 cluster의 quantized embedding $\hat{\mathbf{z}}_{n}$은 duration $d_{n}$과 pair 됨
- 해당 duration은 implicit duration coding scheme을 통해 token index에 integrate 되어 각 token이 auxiliary duration predictor 없이도 content, temporal span을 jointly encode 할 수 있도록 함 - 결과적으로 quantized embedding $\hat{\mathbf{Z}}=[\hat{\mathbf{z}}_{1},...,\hat{\mathbf{z}}_{N}]$은 duration $\mathbf{d}=[d_{1},...,d_{N}]$에 따라 expand 되어 frame-level sequence $\hat{\mathbf{Z}}^{R}=[\hat{\mathbf{z}}_{1}^{R},...,\hat{\mathbf{z}}_{T}^{R}]\in\mathbb{R}^{T\times H}$를 생성함
- 이후 speech decoder로 전달되어 high-fidelity waveform reconstruction을 수행함
- 먼저 speech encoder는 raw waveform을 frame-level embedding $\mathbf{X}=[\mathbf{x}_{1},...,\mathbf{x}_{T}]\in\mathbb{R}^{T\times H}$로 transform 함

- Model Architecture
- VARSTok는 WavTokenizer를 따라 encoder-VQ-decoder architecture를 채택함
- Speech encoder는 1D convolutional layer, temporal downsampling을 위한 4개의 convolutional block으로 구성됨
- 각 convolutional block은 channel이 두배로 증가하는 strided convolution과 residual unit을 가짐
- Downsampled feature는 2-layer bidirectional-LSTM과 projection layer로 further process 되어 frame-level embedding $\mathbf{X}$를 생성함
- Activation function을 ELU를 사용함
- Speech decoder는 attention layer, ConvNeXtV2 block, inverse Fourier transform-based upsampling module을 combining 하여 구성됨
- Decoder는 각 quantized cluster embedding $\hat{\mathbf{z}}_{n}$을 해당 duration $d_{n}$에 따라 repeating 하여 얻어진 quantized cluster embedding $\hat{\mathbf{Z}}^{R}$의 expanded sequence를 receive 하여 original waveform을 reconstruct 함 - VQ module은 $K=4096$ entry를 가지는 single codebook을 사용하여 구성됨
- 이때 각 cluster embedding $\mathbf{z}_{n}\in\mathbb{R}^{H}$는 factorization 이후 $L2$ distance를 기반으로 nearest codebook entry $\mathbf{e}_{k_{n}}\in\mathcal{E}$에 mapping 됨
- Codebook은 exponential moving average를 사용하여 update 되고 training 시에는 random awakening이 적용됨
- Speech encoder는 1D convolutional layer, temporal downsampling을 위한 4개의 convolutional block으로 구성됨
- Temporal-Aware Density Peak Clustering
- Encoder output $\mathbf{X}$를 variable-length unit으로 adaptively segment하기 위해 논문은 temporal-aware density peak clustering algorithm을 도입함
- 각 frame의 local density $\rho_{i}$, peak distance $\delta_{i}$를 calculate하여 모든 frame의 potential cluster center를 identify 함
- Local density $\rho_{i}$는 embedding space에서 frame이 얼마나 similar neighbor로 surrond 되어 있는지를 나타내고, higher $\rho_{i}$는 $\mathbf{x}_{i}$가 embedding space의 dense region에 위치한다는 것을 의미함:
(Eq. 1) $ \rho_{i}=\exp\left(\frac{1}{m} \sum_{j\in \text{KNN}(i)}\phi(\mathbf{x}_{i},\mathbf{x}_{j})\right)$
- $\text{KNN}(i)$ : $x_{i}$의 $m$-most-similar frame에 대한 index - $\phi (\cdot, \cdot)$은 두 frame 간의 normalized cosine-similarity로써:
(Eq. 2) $\phi(\mathbf{x}_{i},\mathbf{x}_{j})=\frac{1+<\mathbf{x}_{i},\mathbf{x}_{j}>}{2}$ - Peak distance $\delta_{i}$는 frame이 higher density region과 얼마나 separate 되어 있는지를 나타냄:
(Eq. 3) $\delta_{i}=\left\{\begin{matrix} \min_{j:\rho_{j}>\rho_{i}} 1-\phi(\mathbf{x}_{i},\mathbf{x}_{j}), & \text{if such}\,\,j \,\,\text{exists} \\ \max_{j} 1-\phi(\mathbf{x}_{i},\mathbf{x}_{j}), & \text{otherwise} \\ \end{matrix}\right.$
- Larger $\delta_{i}$는 $\mathbf{x}_{i}$가 density landscape에서 isolated peak를 가지는 것을 의미함 - 결과적으로 final peak score는:
(Eq. 4) $s_{i}=\rho_{i}\cdot \delta_{i}$
- High $s_{i}$를 가지는 frame은 locally dense, relatively isolate 되어 있음
- Local density $\rho_{i}$는 embedding space에서 frame이 얼마나 similar neighbor로 surrond 되어 있는지를 나타내고, higher $\rho_{i}$는 $\mathbf{x}_{i}$가 embedding space의 dense region에 위치한다는 것을 의미함:
- Peak score $\{s_{i}\}_{i=1}^{T}$를 compute 한 다음, 논문은 cluster를 greedy 하게 구성함
- 각 step에서 new cluster $\mathcal{C}_{n}=\{i*\}$을 initialize 하기 위해 highest peak score $s_{i*}$을 가진 unassigned frame $i*$을 select 함
- 이후 cluster는 seed $i*$을 기준으로 bidirectionally expand 됨
- Candidate frame $t$는 다음 두 condition을 만족하는 경우에만 current cluster $\mathcal{C}_{n}$에 add 되고, condition을 만족하지 않거나 cluster span이 pre-defined maximum $S_{\max}$에 도달하면 expansion이 중단됨
- Similarity Criterion:
(Eq. 5) $\phi(\mathbf{x}_{i*},\mathbf{x}_{t})-\beta\cdot s_{t}>\tau$
- $\beta$ : penalty factor, $\tau$ : manually defined similarity threshold
- $-\beta\cdot s_{t}$는 strong cluster seed를 adding 하여 (Eq. 5)를 penalize 함 - Temporal-aware:
- 즉, $t$-th frame은 immediate temporal neighbor가 current cluster $\mathcal{C}_{n}$에 assign된 경우만 inclusion 함
- 해당 constraint는 모든 cluster가 temporally continguous segment임을 보장함
- Similarity Criterion:
- Cluster $\mathcal{C}_{n}$에 대한 expansion이 완료되면 mean-pooled embedding $\mathbf{z}_{n}=\frac{1}{|\mathcal{C}_{n}|}\sum_{t\in \mathcal{C}_{n}}\mathbf{x}_{t}$를 compute 하고 span $d_{n}=|\mathcal{C}_{n}|$을 record 함
- 해당 process는 모든 frame이 assign 될 때까지 repeate 되어 cluster embedding의 variable-length sequence $[\mathbf{z}_{1},...,\mathbf{z}_{N}]$을 생성함
- 각 frame의 local density $\rho_{i}$, peak distance $\delta_{i}$를 calculate하여 모든 frame의 potential cluster center를 identify 함

- Implicit Duration Coding via Extended Index
- Speech의 temporal structure를 faithfully reconstruct 하고 downstream model과의 alignment를 향상하기 위해서는 accurate duration modeling이 필요함
- 이를 위해 FastSpeech-style duration predictor를 incorporate 할 수 있지만, architecture complexity가 증가하고 optimization instability가 발생할 수 있음
- 따라서 논문은 content identity와 temporal span을 single token index에 embed 하는 implicit duration coding을 도입하여 auxiliary predictor에 대한 의존성을 제거함
- 특히 maximum allowable cluster duration $S_{\max}$ 만큼 VQ codebook index space를 expand 하여 $K\cdot S_{\max}$의 unique token ID를 가지는 conceptual vocabulary를 구성함
- 실제로는 size $K$의 original single codebook $\mathcal{E}$만 instantiate 되고 training 됨 - 먼저 VQ codebook index $k_{n}\in\{0,...,K-1\}$, duration $d_{n}\in\{1,...,S_{\max}\}$를 가지는 quantized cluster embedding $\hat{\mathbf{z}}_{n}$를 single unified token ID로 mapping 하면:
(Eq. 6) $ \text{ID}_{n}=(d_{n}-1)\cdot K+k_{n}$ - Decoding 시에는 (Eq. 6)을 reverse 하여 token ID로부터 content, duration을 recover 할 수 있고, 이때 duration은 integer division을 통해 recover 됨:
(Eq. 7) $d_{n}=\left\lfloor \frac{\text{ID}_{n}}{K}\right\rfloor+1$ - Original VQ index는 다음과 같이 recover 됨:
(Eq. 8) $k_{n}=\text{ID}_{n} \mod K$ - 해당 quantized cluster embedding $\hat{\mathbf{z}}_{n}=\mathbf{e}_{k_{n}}$은 speech decoder input을 구성하기 위해 $d_{n}$번 repeat 되어 correct temporal resolution을 restore 함
- 특히 maximum allowable cluster duration $S_{\max}$ 만큼 VQ codebook index space를 expand 하여 $K\cdot S_{\max}$의 unique token ID를 가지는 conceptual vocabulary를 구성함
- Implicit duration coding scheme은 content, duration을 모두 embedding 하여 downstream speech LM의 modeling process를 streamline 할 수 있음
- 즉, frame-level repetition/upsampling 없이 extended token ID의 compact sequence에서 directly operate 됨
- Training Objective
- VARSTok의 training objective는 mel-spectrogram reconstruction loss, vector quantization loss, adversarial loss, feature matching loss를 jointly optimize 함:
(Eq. 9) $\mathcal{L}=\lambda_{mel}\mathcal{L}_{mel}+\lambda_{q}\mathcal{L}_{q}+\lambda_{adv}\mathcal{L}_{adv}+\lambda_{feat}\mathcal{L}_{feat}$
3. Experiments
- Settings
- Dataset : LibriTTS
- Comparisons : DAC, WavTokenizer, X-Codec, SQCodec, BigCodec
- Results
- 전체적으로 VARSTok의 성능이 가장 뛰어남
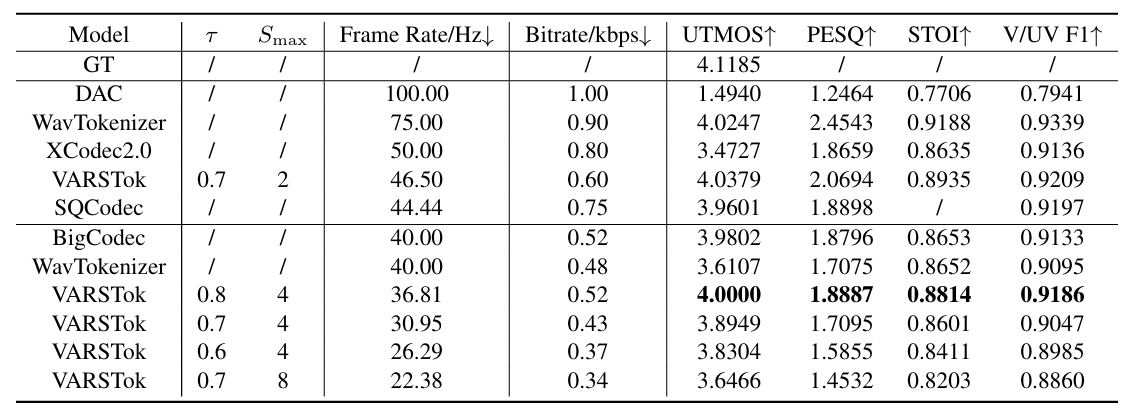
- VARSTok는 token duration을 dynamically adjust 할 수 있음

- Semantic evaluation 측면에서도 우수한 성능을 보임

- TTS Language Modeling
- TTS modeling에서도 최고의 성능을 달성함

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글