

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] FocalCodec-Stream: Streaming Low-Bitrate Speech Coding via Causal Distillation
feVeRin 2026. 3. 3. 12:38반응형
FocalCodec-Stream: Streaming Low-Bitrate Speech Coding via Causal Distillation
- Neural audio codec은 non-streamable 하므로 real-time application에서 사용하기 어려움
- FocalCodec-Stream
- Focal modulation에 기반한 hybrid codec을 활용하여 speech를 single binary codebook으로 compress
- 특히 multi-stage causal distillation과 lightweight refiner module을 도입
- 논문 (ICASSP 2026) : Paper Link
1. Introduction
- AudioLM, MuiscGen, AudioGen과 같은 Speech Language Model (SLM)은 Neural Audio Codec (NAC)의 discrete audio token을 활용하여 modeling 됨
- 특히 SpeechTokenizer, TAAE와 같은 hybrid codec은 acoustic token을 enrich 할 수 있음
- BUT, 대부분의 NAC는 long future context window에 의존하므로 streamability의 한계가 있음
- 즉, semantic, acoustic representation을 unify 하고 high reconstruction을 보장하는 low-bitrate, single-codebook codec이 필요함
-> 그래서 NAC에서 streamability를 달성한 FocalCodec-Stream을 제안
- FocalCodec-Stream
- Focal modulation에 기반한 hybrid codec을 활용해 low-bitrate single binary codebook으로 compress
- WavLM의 multi-stage causal distillation strategy과 lightweight refiner module을 채택
< Overall of FocalCodec-Stream >
- Focal modulation과 multi-stage causal distillation을 활용한 streamable hybrid codec
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Codec Architecture
- FocalCodec-Stream은 FocalCodec architecture를 기반으로 low-latency streaming inference를 지원함
- 먼저 Encoder는 WavLM-large의 first 6 layer에서 standard convolution을 causal convolution으로, full-context gated relative attention을 sliding window gated relative chunked attention으로 replace 하여 구성됨
- 해당 sliding window attention은 infinite streaming을 위해 old context를 discard 하고 chunking 시에는 3-frame look ahead를 활용함 - Focal modulation을 위한 Compressor와 Decompressor는 depth-wise convolution, position-wise feed-forward layer, non-linearity, global pooling으로 구성됨
- 이때 streaming을 위해 standard convolution을 causal convolution으로, global pooling을 large-kernel causal convolution으로 replace 함 - Binary Spherical Quantizer는 각 latent에 대해 independently operate 하고 Vocos Decoder는 ConvNeXt block을 causal convolution으로, iSTFT를 linear projection으로 replace 하여 구성됨
- Upsampling factor $K$에 대해 각 hidden state는 $K$ entry로 project 되고 이후 flatten 되어 waveform을 reconstruct 함 - 추가적으로 논문은 Decompressor 다음에 lightweight Refiner module을 도입함
- Refiner module은 residual chunk-wise feed-forward layer로 구성되고 available latency 내에서 WavLM feature와 better align 되도록 함
- 먼저 sequence length $N$, hidden size $D$에 대해 $x\in\mathbb{R}^{N\times D}$라고 하면, size $C$의 chunk $x_{c}\in\mathbb{R}^{N/C\times CD}$로 reshape 할 수 있음
- 그러면 각 chunk vector $x_{c}$에 대해:
(Eq. 1) $ \hat{x}_{c}=x_{c}+W_{out}\text{GELU}(W_{in}x_{c}+b_{in})+b_{out}$
- $W_{in}, W_{out}\in\mathbb{R}^{CD\times CD}$, $b_{in},b_{out}\in \mathbb{R}^{CD}$ - 최종적으로 $\hat{x}_{c}$를 original shape $\hat{x}\in \mathbb{R}^{N\times D}$로 unflatten 하여 사용함
- 먼저 Encoder는 WavLM-large의 first 6 layer에서 standard convolution을 causal convolution으로, full-context gated relative attention을 sliding window gated relative chunked attention으로 replace 하여 구성됨

- Causal Distillation
- FocalCodec의 streaming을 위해서는 full-context WavLM encoder를 streamable 하게 구성해야 함
- 이를 위해 original full-context WavLM encoder를 teacher로 사용하는 multi-stage distillation framework를 도입함
- Stage 1
- 먼저 streaming constraint 하에서 FocalCodec의 architectural module의 contribution을 assess 함
- Learned positional embedding, full-context gated relative attention을 critical component인 반면, convolutional feature extractor는 minor role에 해당함 - 특히 positional embedding은 128 feature frame의 receptive field를 가지는 convolution에 의존하므로 80ms latency budget을 exceed 하여 initial delay를 발생시킴
- 따라서 논문은 positional embedding의 causal variant가 full-context를 approximate 하도록 하여 training data에서 $L2$ loss를 minimize 하는 방식으로 positional embedding을 causally distill 함
- 먼저 streaming constraint 하에서 FocalCodec의 architectural module의 contribution을 assess 함
- Stage 2
- Positional embedding distillation 이후에는 attention과 convolutional feature extractor를 distill 함
- 해당 component는 causal form으로 convert 된 다음, full-context teacher model로부터 distill 됨 - 해당 process를 guide 하기 위해 6 layer 각각에서 causal, teacher embedding 간의 $L2$ loss를 minimize 하고 reversed linear schedule을 적용해 loss를 weight 함
- 이를 통해 earlier layer는 adaptation freedom을 가지면서 deeper layer에서는 representational strength를 preserve 할 수 있음
- Positional embedding distillation 이후에는 attention과 convolutional feature extractor를 distill 함
- Stage 3
- WavLM encoder가 distill 되면 causal compressor-quantizer-decompressor system을 training 함
- 이때 causally distilled, decompressed representation 간의 $L2$ loss를 사용함 - 추가적으로 original full-context WavLM representation을 사용하여 causal decoder를 training 함
- WavLM encoder가 distill 되면 causal compressor-quantizer-decompressor system을 training 함
- Stage 4
- Full-context feature로 training 된 decoder와 causally distilled feature를 reconstruct 하도록 training 된 decompressor 간에는 distribution shift가 존재함
- 이를 해결하기 위해 논문은 learnable refiner module을 도입함 - 해당 stage에서는 encoder, compressor, quantizer, decompressor, refiner를 jointly fine-tuning 하면서 teacher, refiner output 간에 $L2$ loss를 적용함
- Full-context feature로 training 된 decoder와 causally distilled feature를 reconstruct 하도록 training 된 decompressor 간에는 distribution shift가 존재함
3. Experiments
- Settings
- Dataset : LibriTTS
- Comparisons : EnCodec, AudioDec, FocalCodec, PAST, HILCodec, Mimi

- Results
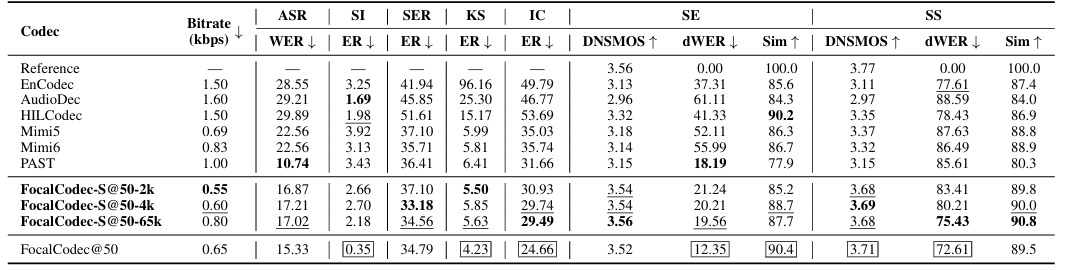
- FocalCodec-Stream은 speech resynthesis, voice conversion에서 우수한 성능을 달성함

- Discriminative downstream task에 대해서도 뛰어난 성능을 보임
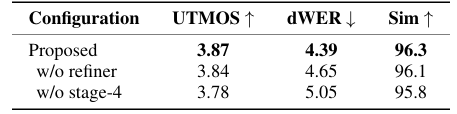
- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글