

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] AudioDec: An Open-Source Streaming High-Fidelity Neural Audio Codec
feVeRin 2024. 4. 15. 10:58반응형
AudioDec: An Open-Source Streaming High-Fidelity Neural Audio Codec
- Telecommunication과 같은 live application에 적합한 audio codec은 다음의 속성을 만족해야 함
- Compression : signal을 transmit 하는데 필요한 bitrate는 가능한 낮아야 함
- Latency : encoding, decoding은 최소한의 delay만으로 수행되어야 함
- Reconstruction quality of signal - AudioDec
- 위 3가지 property를 모두 만족하는 streamable, real-time neural audio codec
- 6ms 미만의 GPU에서 12kbps 만으로 동작하면서 고품질의 48kHz 음성을 reconstruction 가능
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Audio codec은 audio signal을 code로 compress 하고 이를 기반으로 audio signal을 reconstruction 하는 것
- 일반적으로 audio codec은 encoder, quantizer, decode module로 설계됨
- 이때 quantized code의 bitrate는 일반적으로 input audio signal의 bitrate보다 훨씬 낮으므로 code는 transmission이나 storage에 적합하게 사용될 수 있음 - 기존의 parametetric codec은 psycho-acoustics나 digital signal processing을 통해 설계되어 낮은 bitrate에서 bandwidth 제한으로 인해 낮은 품질을 보임
- 이러한 제한적인 modeling capacity는 natural과 reconstructed audio signal 간의 품질 차이를 발생시키는 원인 - 한편으로 최신의 neural network (NN)를 활용하는 neural codec은 모델링 성능을 크게 향상하고 있음
- 그중에서도 vocoder-based codec은 parametric coder나 quantized acoustic feature의 code에 따라 condition 된 neural vocoder를 사용하여 audio signal을 reconstruction 하는 방식
- 특히 vocoder-based codec의 성능과 bitrate는 upstream encoding과 밀접하게 연관되어 있음 - 따라서 global optimation과 flexible bitrate를 달성하기 위해, raw waveform I/O를 사용하는 End-to-End AutoEncoder (E2E AE)를 고려할 수 있음
- 이때 해당 E2E codec은 고품질 음성을 생성할 수 있지만, 효율적인 training paradigm이 불분명하므로 다양한 application에 대해 flexible 하게 적용할 수 없음
- 그중에서도 vocoder-based codec은 parametric coder나 quantized acoustic feature의 code에 따라 condition 된 neural vocoder를 사용하여 audio signal을 reconstruction 하는 방식
- 일반적으로 audio codec은 encoder, quantizer, decode module로 설계됨
-> 그래서 효율적인 training paradigm을 갖춘 E2E neural codec인 AudioDec를 제안
- AudioDec
- Modularized architecture를 통해 다양한 application에 대한 flexibility를 확보
- State-of-the-art neural vocoder인 HiFi-GAN을 AudioDec에 통합하여 well-trained encoder와 powerful vocoder의 조합을 통해 최고의 음성 품질을 달성함
- Group convolution mechanism을 채택하여 streamable network가 GPU, CPU 모두에서 낮은 latency를 가지고 real-time으로 동작 가능하도록 함
< Overall of AudioDec >
- HiFi-GAN vocoder를 통합하고 efficient training paradigm을 적용한 real-time neural audio codec
- 결과적으로 streamable 한 낮은 latency를 확보하면서 48kHz 이상의 high-fidelity 음성을 합성 가능
2. Baseline Neural Audio Codec
- AudioDec은 SoundStream backbone을 가지는 E2E AE-based architecture를 채택함
- End-to-End AutoEncoder-based Audio Codec
- 일반적인 E2E AE-based codec은 encoder, projector, quantizer, decoder module로 구성됨
- Encoding stage에서 raw waveform signal은 lower temporal resolution으로 encode 된 다음, designed multi-dimensional space에 project 됨
- Projected representation은 transmission/storage를 위한 code로 quantize 됨
- Decoding stage에서 code는 lookup process를 통해 representation으로 transfer 된 다음, decoder가 해당 representation을 기반으로 raw waveform으로 reconstruct 함 - 여기서 NN-based AE codec의 모든 module을 jointly optimize 하기 위해, 주로 vector quantization (VQ)를 채택함
- 대표적으로 softmax quantization, Gumbel softmax, exponential moving average (EMA), straight-through gradient 등을 gradient propagation을 위해 사용함 - 이때 bitrate는 VQ codebook size와 직접적으로 연관되어 있지만, huge plain codebook으로 모델을 training 하는 것은 impractical 함
- 따라서 tractable hierarchical codebook을 위해 residual VQ, multi-scale VQ 등을 사용하여 encoded latent code의 fine-coarse structure를 decomposing 하거나,
- Cross-module residual learning을 사용하여 output waveform을 decompose 하는 scalable codec을 도입함
- Encoding stage에서 raw waveform signal은 lower temporal resolution으로 encode 된 다음, designed multi-dimensional space에 project 됨
- SoundStream Audio Codec
- SoundStream은 residual VQ를 채택한 E2E AE-based neural codec
- SoundStream은 streamable, real-time requirement를 만족하기 위해 fully causal convolution architecture를 채택함
- Cauality로 인해 network는 previous sample을 기반으로 audio signal을 encode/decode 하므로, 전체 process는 continuous segmental manner로 동작 가능함
- 이때 효율적인 encoding/decoding을 위해 convolution network는 parallel computation을 활용하고, SoundStream을 training 하기 위해 metric/adversarial loss를 활용함 - 먼저 input signal $x$와 output signal $\hat{x}$가 주어졌을 때, metric mel-spectrogram loss $L_{mel}$은:
(Eq. 1) $L_{mel}(x,\hat{x})=\mathbb{E}[|| \mathrm{mel}(x)-\mathrm{mel}(\hat{x})||_{1}]$
- $\mathrm{mel}()$ : mel-spectrogram extraction - 이때 SoundStream은 short-time Fourier transform discriminator (STFTD)는 complex spectrogram을 input으로 하고, multi-scale discriminator (MSD)는 waveform을 input으로 사용함
- 여기서 모든 discriminator는 discriminator output logit에 대한 hinge loss를 채택
- 그러면 discriminator $D$와 generator $G$가 주어졌을 때, adversarial discriminator loss $L_{D}$는:
(Eq. 2) $L_{D}=\mathbb{E}[\max(0,1-D(x))+\max(0,1+D(G(x)))]$ - Adversarial generator loss $L_{adv}$는:
(Eq. 3) $L_{adv}=\mathbb{E}_{x}[\max(0,1-D(G(x)))]$ - 모든 discriminator의 feature map에 대해 feature matching loss $L_{fm}$을 적용하고, VQ codebook에는 EMA loss $L_{vq}$를 적용하여 얻어지는 전체 generator loss는:
(Eq. 4) $L_{G}=L_{adv}+\lambda_{fm}L_{fm}+\lambda_{mel}L_{mel}+\lambda_{vq}L_{vq}$
- $\lambda_{fm}, \lambda_{mel}, \lambda_{vq}$ : weight
- SoundStream은 위를 통해 low bitrate로 고품질의 audio reconstruction이 가능하지만, 추가적인 training efficiency 개선과 model flexibility 향상이 필요함
- 특히 Generative Adversarial Network (GAN) 기반의 모델은 high-fidelity의 음성을 얻기 위해 여러 개의 discriminator가 필요하므로, 해당 discriminator들을 training 하는데 많은 시간이 소모됨
- 이때 GAN training은 waveform detail, high-frequency component, phase synchronization을 모델링하는 것과 관련이 있고 low-frequency component를 모델링하는 것은 metric loss로만 학습할 수 있음
- 따라서 단순히 scratch로 metric loss와 adversarial loss를 모두 사용하여 모델을 training 하는 것은 비효율적임
- 추가적으로 다양한 application에 맞게 SoundStream을 flexibly adjust 할 수 있어야 함
- SoundStream은 streamable, real-time requirement를 만족하기 위해 fully causal convolution architecture를 채택함
3. Proposed Neural Audio Codec
- SoundStream의 training efficiency, model flexibility, audio quality를 개선하기 위해 efficient training paradigm과 modularized architecture를 도입
- 이를 기반으로 제안하는 AudioDec에 HiFi-GAN-based multi-period discriminator를 적용
- 추가적으로 HiFi-GAN vocoder에 group convolution mechanism을 적용하여 4개의 thread를 가지는 CPU에서 real-time으로 동작할 수 있도록 함
- Efficient Training Paradigm
- Mel-spectrogram과 같은 standard spectral feature에는 speaker identity, content와 같은 high-level information이 포함되어 있지만, high-fidelity 음성을 얻기 위해서는 phase information이 가장 중요함
- 특히 codec의 경우, code가 low-bitrate transmission에 필요한 information만을 포함하므로 decoder는 high-fidelity의 waveform을 reconstruction 할 수 있도록 충분히 powerful 해야 함
- 따라서 AudioDec은 metric loss 만으로 encoder/decoder 모두를 training 하는 efficient training paradigm을 제안함
- 이를 통해 training은 더 빠르고 stable 하게 수렴될 수 있음
- 이후 discriminator는 decoder에 대해서만 jointly train 되어 reconstruction waveform의 detail과 phase synchronization을 처리함 - 먼저, 아래 그림과 같이 projector와 quantizer를 포함한 encoder parameter $\theta$와 decoder parameter $\phi$가 주어지면,
- Stage 1 : AudioDec generator는 처음 200k iteration 동안 (Eq. 1)을 사용하여 training 됨
- Stage 2 : 다음의 500k iteration 동안에는 전체 모델이 updated mel-spectral loss로 training 됨:
(Eq. 5) $L_{mel'}(x,\hat{x})=\mathbb{E}[|| \mathrm{mel}(x)-\mathrm{mel}(f_{\phi}(\mathrm{sg}[f_{\theta}(x)]))||_{1}]$
- $\mathrm{sg}[]$ : stop gradient operator
- 그러면,
- Updated adversarial discriminator loss는:
(Eq. 6) $L_{D'}=\mathbb{E}_{x}[(1-D(x))^{2}+D(f_{\phi}(\mathrm{sg}[f_{\theta}(x)]))^{2}]$ - Updated adversarial generator loss는:
(Eq. 7) $L_{adv'}=\mathbb{E}_{x}[(1-D(f_{\phi}(\mathrm{sg}[f_{\theta}(x)])))^{2}]$
- 여기서 training stability를 위해 least squares-GAN이 채택됨
- Updated adversarial discriminator loss는:

- Modularized Architecture
- Encoder와 decoder는 denoising이나 binaural rendering과 같은 다양한 scenario에서 쉽게 교체될 수 있어야 하므로, AudioDec의 각 component를 modularizing 함
- 따라서 AudioDec은 pre-train mechanism을 활용하여 high-quality clean corpus로 train 된 standard quantizer와 complete codebook을 얻음
- 이후 해당 quantizer와 codebook을 fixing 하여 arbitrarily encoder/decoder를 쉽게 개발하도록 함 - 여기서 symmetric encoder-decoder architecture가 AE의 training stability에 필수적인 것으로 나타남
- 일반적으로 waveform decoder는 high-resolution audio signal의 모든 detail을 처리하는데 powerful 하고,
- Encoder는 input audio signal의 limited essential information을 preserve 하는데 중요함 - 즉, asymmetric architecture는 unstable 할 수 있고 symmetric architecture는 inefficient 함
- 이때 AudioDec은 modularized architecture를 제공함으로써 well-trained AE codec의 decoder가 powerful vocoder로 쉽게 대체될 수 있도록 함으로써 flexible 한 설계를 가능하게 함
- 결과적으로 AudioDec은 HiFi-GAN vocoder를 codec에 통합함으로써 더 나은 성능을 달성할 수 있음
- 따라서 AudioDec은 pre-train mechanism을 활용하여 high-quality clean corpus로 train 된 standard quantizer와 complete codebook을 얻음
- HiFi-GAN-based Multi-Period Discriminator
- HiFi-GAN은 고품질의 음성 합성 성능을 보여주는 state-of-the-art neural vocoder
- 여기서 HiFi-GAN은 성능 개선을 위해 Multi-Period Discriminator (MPD)를 활용함
- Original과 downsampling signal에 대해서 동작하는 MSD와 달리, MPD는 서로 다른 segment length (period)를 가지는 segmental signal에서 동작함
- Long-term dependency를 capture 하는 MSD와 비교하여 MPD는 periodic detail을 capture 하는데 효과적임 - 한편으로 SoundStream의 STFTD는 long-term dependency와 관련되어 있으므로, 중복적인 STFTD를 MPD로 대체함으로써 audio 품질을 향상할 수 있음
- 여기서 HiFi-GAN은 성능 개선을 위해 Multi-Period Discriminator (MPD)를 활용함
- Low-Latency Implementation
- Streaming과 real-time은 low-latency encoding/decoding의 2가지 main factor
- AudioDec의 causal convolution과 deconvolution은 streaming을 위해 one-side padding으로 구현됨
- 이때 paralle computation을 통한 real-time coding을 위해 non-autoregressive arhcitecture를 채택 - BUT, 앞서 적용한 HiFi-GAN의 Multi-Receptive Field Fusion (MRF) module은 parallel-computation-friendly 하지 않으므로, vanilla HiFi-GAN으로는 AuidioDec을 real-time으로 동작시키기 어려움
- 여기서 각 MRF의 서로 다른 kernel size는 fully parallel computation을 방해하는 주요 원인이지만, 모든 MRF에 대해 가장 큰 kernel size를 채택하면 이론적으로 동일하거나 더 나은 모델링 성능을 얻을 수 있음 - 따라서 AudioDec은 이러한 ad-hoc kernel size의 불필요성을 활용하여 동일한 kernel size로 MRF를 simulation 하는 group convolution mechansim을 적용함
- 결과적으로 해당 group HiFi-GAN generator를 통해 GPU, CPU 모두에서 parallel computation이 가능
- AudioDec의 causal convolution과 deconvolution은 streaming을 위해 one-side padding으로 구현됨
3. Experiments
- Settings
- Dataset : Valentini Dataset
- Comparisons : SoundStream
- Results
- Objective Evaluation
- SymAD (Symmetric AudioDec)와 SoundStream 간의 성능 차이는 AudioDec의 MPD가 효과적이라는 것을 나타냄
- 한편으로 제안된 training paradigm을 적용하지 않은 SymAD*의 성능 저하는 GAN training이 decoder 성능 개선에 큰 영향을 준다는 것을 의미함
- 결과적으로 제안된 AudioDec은 모든 metric 측면에서 최고의 성능을 달성함
- 즉, well-trained audio encoder로 추출된 globally normalized code로 vocoder를 training 하는 것은 neural codec의 성능을 향상하는데 주요한 방법임

- Subjective Evaluation
- MOS 측면에서 합성 품질을 비교해 보면, 제안된 AudioDec은 SoundStream 보다 뛰어난 성능을 보임
- AD v1과 같이 vocoder의 modeling capacity가 향상되는 경우, vocoder-based approach가 가장 좋은 성능을 달성함

- Discussion
- 제안된 training paradigm에 대한 학습 속도를 확인해 보면, metric loss만 사용하는 것이 discriminator를 사용하는 training 보다 더 빠른 것으로 나타남
- 특히 decoder, discriminator training 중에 encoder를 fix 하면 학습 속도도 약간 향상됨

- Streaming capability에 대해 확인해 보면
- GPU의 parallel computation capacity로 인해 다양한 window length에 대한 processing time은 거의 동일한 것으로 나타남
- 즉, 제안된 AudioDec은 12.5ms buffer에서도 potentially streamable 하다고 볼 수 있음
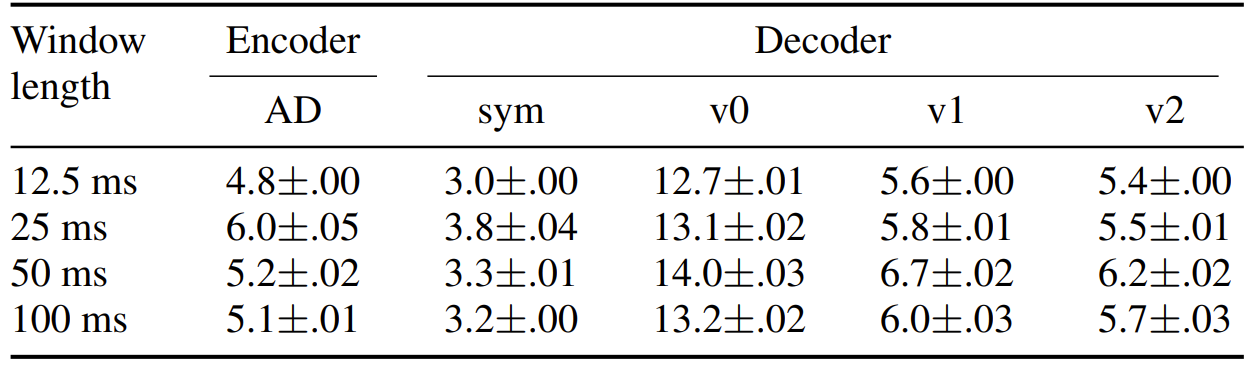
- 한편으로 4개의 thread가 있는 CPU에서 streaming 성능을 확인해 보면
- Stand-alone audio recording, encoding, decoding, playing pipeline은 35ms buffer size의 CPU에서 원활하게 동작할 수 있음
- 일반적인 internet call의 acceptable maximum latency가 150ms이므로 충분한 여유를 보임

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글