

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] WavTokenizer: An Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
feVeRin 2025. 5. 11. 09:11반응형
WavTokenizer: An Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
- Language model은 high-dimensional natural signal을 lower-dimensional discrete token으로 compress 하는 tokenizer를 활용함
- WavTokenizer
- Quantizer layer와 discrete codec의 temporal dimension을 compress
- Broader VQ space, contextual window extending, inverse Fourier transform structure를 통해 더 나은 reconstruction quality와 richer semantic information을 달성
- 논문 (ICLR 2025) : Paper Link
1. Introduction
- VALL-E, SPEAR-TTS, Mega-TTS2와 같이 Large Language Model (LLM)은 audio synthesis에서 우수한 성능을 보이고 있음
- 특히 해당 LLM은 EnCodec, SoundStream, DAC와 같은 neural codec model의 discrete acoustic codec representation을 기반으로 구축됨
- Discrete acoustic codec은 continuous speech signal과 discrete-token-based language model 간의 gap을 bridge 하고 high-rate audio signal을 finite token set으로 discretize 함 - 대부분의 end-to-end discrete codec은 Encoder, Residual Vector Quantization (RVQ), Decoder로 구성됨
- 먼저 encoder는 time-domain에서 audio를 downsampling 하여 compressed audio frame을 얻음
- 이후 compressed audio frame은 quantizer를 통해 quantize 됨
- 여기서 각 quantizer는 이전 quantizer의 residual을 기반으로 동작하고, quantizer 수는 overall bitrate에 영향을 미침 - Decoder는 quantizer output을 기반으로 audio signal을 reconstruct 하기 위해 time-domain에서 upsampling을 수행함
- 이러한 acoustic codec은 near-human level reconstruction이 가능하지만, 여전히 다음의 개선점이 존재함:
- Higher Bitrate Compression
- Quantizer 수와 codec의 temporal dimension 측면에서 추가적인 optimization이 가능함 - Richer Semantic Information
- 더 많은 semantic information을 포함하면 weakly supervised Text-to-Speech (TTS)가 가능함
- Higher Bitrate Compression
- 특히 해당 LLM은 EnCodec, SoundStream, DAC와 같은 neural codec model의 discrete acoustic codec representation을 기반으로 구축됨
-> 그래서 extreme compression과 high reconstruction quality를 달성할 수 있는 WavTokenzier를 제안
- WavTokenizer
- Decoder와 vocoder에서 multi-scale discriminator와 inverse Fourier transform upsampling structure를 사용하여 reconstruction quality를 향상
- $k$-means clustering initialization과 random awakening strategy를 채택하고 VQ space를 expanding 하여 audio representation을 compress
- 추가적으로 contextual window를 expand 하고 decoder의 attention network에 incoroporate 함으로써 rich semantic information을 확보
< Overall of WavTokenizer >
- VQ space expanding과 inverse Fourier structure를 활용한 neural codec
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
- WavTokenizer는 VQ-GAN framework를 기반으로 하는 SoundStream, EnCodec paradigm을 따름
- 구조적으로는 3가지 module로 구성됨:
- 먼저 raw audio $X$가 주어지면, full convolution encoder는 latent feature representation $Z$를 생성함
- 다음으로 single quantizer는 $Z$를 discrete repreentation $Z_{q}$로 quantize 함
- 최종적으로 decoder는 compressed latent representation $Z_{q}$로부터 audio signal $\tilde{X}$를 reconstruct 함
- WavTokenizer는 end-to-end training 되고 time, frequency domain에 대한 reconstruction loss, 서로 다른 resoultion의 discriminator로 얻어지는 perceptual loss로 optimize 됨
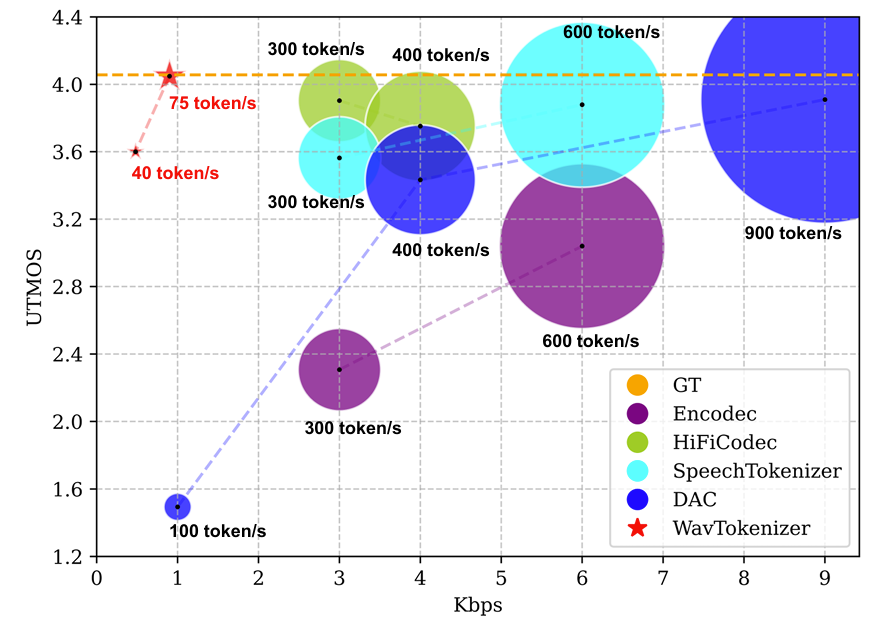
- 결과적으로 아래 그림과 같이, WavTokenizer는 75개의 token 만으로 최고의 reconstruction quality를 달성함
- 특히 extreme compression bitrate인 0.48 kbps에서 3.6 UTMOS를 보임
- 구조적으로는 3가지 module로 구성됨:
- Encoder
- EnCodec을 따라 encoder는 $C$ channel, 7 kernel size를 가지는 1D convolution과 이어지는 $B$ convolution block으로 구성됨
- 각 convolution block은 single residual unit과 stride $S$의 2배에 해당하는 kernel size의 stride convolution을 사용하는 downsampling layer로 구성됨
- Residual unit은 3 kernel size를 가지는 2개의 convolution과 skip-connection으로 구성됨 - Convolution block 다음에는 sequence modeling을 위한 two-layer LSTM과 7 kernel size, $D$ output channel을 가지는 final 1D convolution layer가 사용됨
- 논문은 $C=32, B=4, D=512$로 설정하고 non-linear activation으로 ELU를 사용함 - 한편으로 stride $S$에 대해 $(2,4,5,8), (4,5,5,6)$의 configuration을 채택하여 WavTokenizer가 time-dimension에서 24kHz speech를 각각 320배, 600배 downsampling 하도록 함
- 각 convolution block은 single residual unit과 stride $S$의 2배에 해당하는 kernel size의 stride convolution을 사용하는 downsampling layer로 구성됨
- Rethinking the Vector Quantization Space
- WavTokenizer는 speech representation을 single quantizer의 codebook space로 compress 하는 것을 목표로 함
- 이를 통해 speech를 seamless serialization 하고 downstream model에서 channel dimension에 대한 hierarchical design을 eliminate 할 수 있음
- 여기서 논문은 single quantizer reconstruction을 위해 natural language의 vast vocabulary space를 고려하여, speech를 unique language로 취급할 것을 가정함
- 해당 가정을 기반으로 codebook space를 $2^{10}$에서 $2^{14}$로 expand 하고, 아래 그림의 (a)와 같이 codebook의 probability distribution을 analyize 함
- 결과적으로 $2^{12}$의 left에 speech vocabulary의 concentration이 나타나므로, 기존의 $2^{10}$ size는 speech space를 fully represent 하지 못함
- 한편으로 quantized codebook space를 simply expand 하면 lower unitilization rate로 이어짐
- 따라서 논문은 $k$-means clustering을 활용하여 codebook vector를 initialize 함
- 이때 larger codebook space를 위해 cluster center 수를 200으로 설정하고, 0.99 decay를 가진 exponential moving average로 update 함 - Several batch에 대해 unassign 된 code는 current batch에서 randomly sample 된 input vector로 replace 됨
- 해당 forced activation strategy를 통해 large codebook space의 effective utilization을 보장할 수 있음
- 따라서 논문은 $k$-means clustering을 활용하여 codebook vector를 initialize 함
- 결과적으로 $k$-means clustering initialization, random awakening strategy를 적용하면,
- 아래 그림의 (b)와 같이 hierarchical RVQ structure를 single quantizer로 compressing 했을 때 발생하는 information loss를 reduce 할 수 있음
- 특히 speech는 serialized quantizer structure하에서 effectively reconstruct 될 수 있고, $2^{12}$ codebook space를 사용했을 때 codebook utilization과 reconstruction quality 측면에서 최적의 balance를 달성함

- Improved Decoder
- NaturalSpeech3에서 decoder는 encoder 보다 acoustic codec reconstruction에 더 중요하게 사용됨
- 특히 WavTokenizer는 aliasing artifact에 susceptible 한 transposed convolution과 mirrored decoder upsampling structure를 사용하지 않음
- 대신 모든 depth에서 consistent feature resolution을 maintain 하고 inverse Fourier transform을 통해 waveform upsampling을 수행함
- 즉, decoder에서 target audio signal $\tilde{X}$는 STFT를 통해 represent 됨:
(Eq. 1) $\text{STFT}(\tilde{X}_{[m,k]})=\sum_{n=0}^{N}\tilde{X}[n]w[n-m]e^{-j2\pi kn/K}$
- $K$ : Discrete Fourier Transform (DFT) 수행 이후의 frequency point 수, $k$ : frequency index
- $N$ : sampled sequence 내의 point 수, $n$ : particular sample point, $m$ : index length - 실제로 STFT는 data의 overlapped, windowed frame에 Fast Fourier Transform (FFT)를 적용하여 수행됨
- Window function은 frame을 생성하기 위해 time에 따라 hopping 됨
- 추가적으로 논문은 acoustic model의 semantic modeling capability를 directly enhance 하기 위해 attention network module을 incorporate 함
- 한편으로 acoustic codec은 randomly selected short 1-second audio clip에서 training 되므로 추론 시 long sequence modeling에 대한 potential extrapolation 문제가 발생할 수 있음
- BUT, 실험적으로 WavTokenizer는 long audio sequence에 대해서도 우수한 reconstruction 성능을 달성함 - 특히 contextual modeling window를 3-second로 설정하면 성능이 더욱 향상됨
- 1-second clip이 semantic information을 충분히 포함하지 못하기 때문
- 즉, contextual modeling window size를 늘리면 codec model의 context capture를 개선할 수 있음
- 한편으로 acoustic codec은 randomly selected short 1-second audio clip에서 training 되므로 추론 시 long sequence modeling에 대한 potential extrapolation 문제가 발생할 수 있음
- WavTokenizer는 $Z_{q}$를 Conv1D layer, attention block, ConvNeXt block에 input 한 다음, real-valued signal에 대해 Fourier transform을 수행함
- 여기서 ConvNeXt block은 input feature를 hidden dimensionality로 embed 한 다음, convolution block을 적용함
- 각 block은 large-kernel-sized depthwise convolution으로 구성되고, pointwise convolution을 통해 feature를 higher dimensionality로 project 하는 inverted bottlencek이 사용됨
- Bottleneck에서는 GELU activation이 사용되고, block 간에는 layer normalization이 사용됨 - Real-valued signal transformation의 경우, single side band spectrum을 활용하여 frame 당 $n_{fft}/2+1$의 coefficient를 생성함
- 이때 model은 phase, magnitude를 모두 output 하므로 hidden dimension의 activation은 $n_{fft}+2$ channel을 가진 tensor $h$로 project 됨 - 최종적으로 model은 inverse Fourier transform $\mathcal{F}^{-1}$을 사용하여 final audio를 reconstruct 함
- 여기서 ConvNeXt block은 input feature를 hidden dimensionality로 embed 한 다음, convolution block을 적용함
- 특히 WavTokenizer는 aliasing artifact에 susceptible 한 transposed convolution과 mirrored decoder upsampling structure를 사용하지 않음
- The Advanced Discriminator and The Loss Functions
- 논문은 perceptual quality를 향상하기 위해 adversarial loss를 도입함
- 특히 Vocos를 따라 HiFi-GAN의 Multi-Period Discriminator (MPD), UnivNet의 Multi-Resolution Discriminator (MRD)를 사용함
- 추가적으로 specific sub-band의 discriminative feature를 학습하고 stronger gradient signal을 제공하기 위해 DAC를 따라 complex STFT discriminator를 multiple time-scale에 적용함
- 결과적으로 hinge loss를 통해 얻어지는 discriminator training loss $\mathcal{L}_{dis}(X,\tilde{X})$는:
(Eq. 2) $\mathcal{L}_{dis}(X,\tilde{X})=\frac{1}{K}\sum_{k=1}^{K}\max\left( 0,1-D_{k}(X)\right)+ \max\left(0, 1+D_{k}(\tilde{X})\right)$
- $K$ : discriminator 수, $D_{k}$ : $k$-th discriminator
- WavTokenizer의 generator training loss는 quantizer loss, mel-spectrum reconstruction loss, adversarial loss, feature matching loss로 구성됨
- 먼저 quantizer loss는:
(Eq. 3) $\mathcal{L}_{q}(Z,Z_{q})=\sum_{i=1}^{N}\left|\left| Z_{i}-\hat{Z}_{i}\right|\right|_{2}^{2}$ - Mel-spectrum reconstruction loss는:
(Eq. 4) $\mathcal{L}_{mel}(X,\tilde{X})=\left|\left| \text{Mel}(X)-\text{Mel}(\tilde{X})\right|\right|_{1}$ - Discriminator의 logit에 대한 hinge loss로 얻어지는 adversarial loss는:
(Eq. 5) $\mathcal{L}_{adv} =\frac{1}{K}\sum_{k=1}^{K}\max\left(0,1-D_{k}(\tilde{X})\right)$ - $k$-th sub-discriminator의 $l$-th feature map 간의 distance로 정의되는 feature matching loss는:
(Eq. 6) $\mathcal{L}_{feat}=\frac{1}{K*L}\sum_{k}\sum_{l}\left|\left| D_{k}^{l}(X)-D_{k}^{l}(\tilde{X})\right|\right|_{1}$
- 먼저 quantizer loss는:
- 결과적으로 generator의 total training loss는:
(Eq. 7) $\mathcal{L}_{gen}=\lambda_{q}\mathcal{L}_{q}+\lambda_{mel}\mathcal{L}_{mel}+\lambda_{adv}\mathcal{L}_{adv}+\lambda_{feat}\mathcal{L}_{feat}$
- $\lambda_{q},\lambda_{mel}, \lambda_{adv},\lambda_{feat}$ : hyperparameter
- 특히 Vocos를 따라 HiFi-GAN의 Multi-Period Discriminator (MPD), UnivNet의 Multi-Resolution Discriminator (MRD)를 사용함
3. Experiments
- Settings
- Dataset : LibriTTS, VCTK
- Comparisons : EnCodec, HiFi-Codec, DAC, Vocos, SpeechTokenizer
- Results
- 전체적으로 WavTokenizer의 성능이 가장 우수함
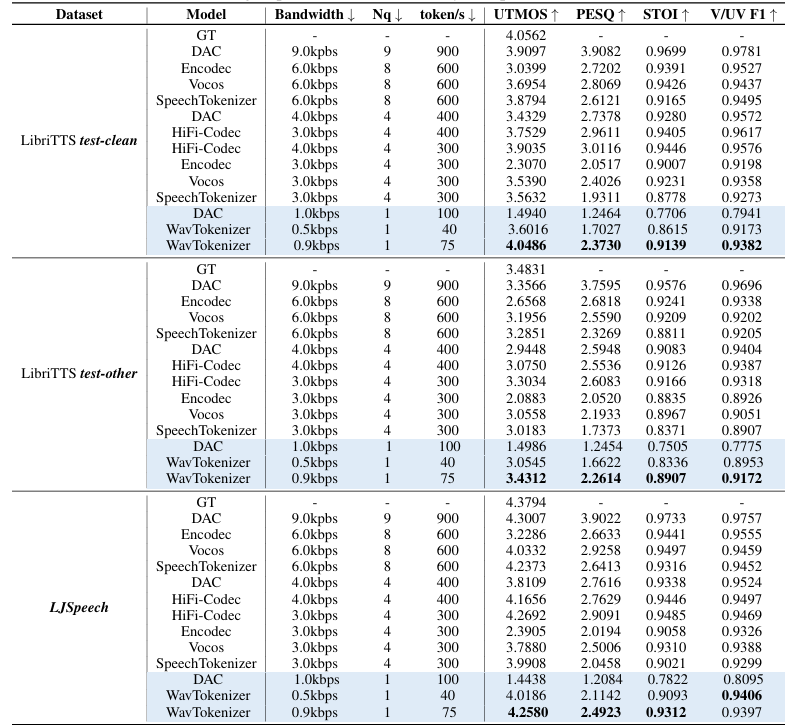
- Subjective evaluation 측면에서도 WavTokenizer가 우수한 성능을 보임

- Evaluation on Semantic Representation
- Semantic representation 측면에서도 WavTokenizer가 뛰어난 성능을 달성함

- Evaluation on Downstream Generative Task
- Downstream text-to-speech task에 대해 WavTokenizer를 사용하는 경우 더 나은 성능을 달성함

- Ablation Study
- Codebook size는 4096, contextual window size는 3일 때 최적의 성능을 달성함

- Multi-scale STFT discriminator에 대해 각 component를 제거하는 경우 성능 저하가 발생함

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글