

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] FreeCodec: A Disentangled Neural Speech Codec with Fewer Tokens
feVeRin 2025. 9. 3. 17:15반응형
FreeCodec: A Disentangled Neural Speech Codec with Fewer Tokens
- Neural speech codec은 fewer token에 대해서는 성능 저하를 보임
- FreeCodec
- Distinct frame-level encoder를 사용하여 intrinsic speech property를 decompose
- 서로 다른 frame-level information을 dedicated quantizer로 quantizing 하여 encoding efficiency를 향상
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Neural Speech Codec은 distortion을 최소화하면서 제한된 bit 수로 speech signal을 compress 하기 위해 사용됨
- 이때 fewer token일수록 bitrate가 낮아지므로, lower bitrate에서도 high-quality를 유지할 수 있어야 함
- 이를 위해 SoundStream, DAC 등의 기존 neural codec은 VQ-VAE architecture를 활용하여 encoder-vector quantization layer-decoder를 End-to-End (E2E)로 학습함
- 여기서 vector quantization layer는 encoder의 continuous latent feature를 discretize 함 - 한편으로 reconstructed speech quality를 향상하기 위해 disentanglement method를 고려할 수 있음
- 대표적으로 FACodec은 phone, $F0$, speaker label 등을 고려하여 supervised manner로 disentangling을 수행함
- TiCodec, SpeechTokenizer와 같은 unsupervised method는 implicit disentanglement를 위해 additional global encoder를 사용하거나 self-supervised learning model을 사용함
- BUT, 앞선 방식들은 reconstruction과 disentanglement 간의 balance를 이루지 못함
-> 그래서 더 나은 reconstruction과 disentanglement를 달성할 수 있는 FreeCodec을 제안
- FreeCodec
- Complex speech를 intrinsic attribute (speaker, prosody, content)로 modeling 하고 speaker information을 explicitly disentangle
- 각 attribute에 대해 서로 다른 frame-level representation을 적용하여 higher compression을 지원
- 추가적으로 information reconstruction을 향상하기 위해 improved decoder를 도입
< Overall of FreeCodec >
- $57$의 fewer token 만으로도 reconstruction이 가능한 self-supervised disentangled neural codec
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Overall
- FreeCodec은 encoder, quantizer, decoder의 3가지 component로 구성됨
- 먼저 encoder는 human speech의 다양한 intrinsic property에 대해 detailed modeling을 지원함
- 특히 content, speaker, prosody information을 각각 encode 하기 위해 3개의 encoder를 사용함 - 이후 quantization layer는 compressed representation을 생성함
- Improved decoder는 content decoder, backbone module, upsampling decoder로 구성되어 compressed latent representation으로부터 speech signal을 reconstruct 함
- 먼저 encoder는 human speech의 다양한 intrinsic property에 대해 detailed modeling을 지원함
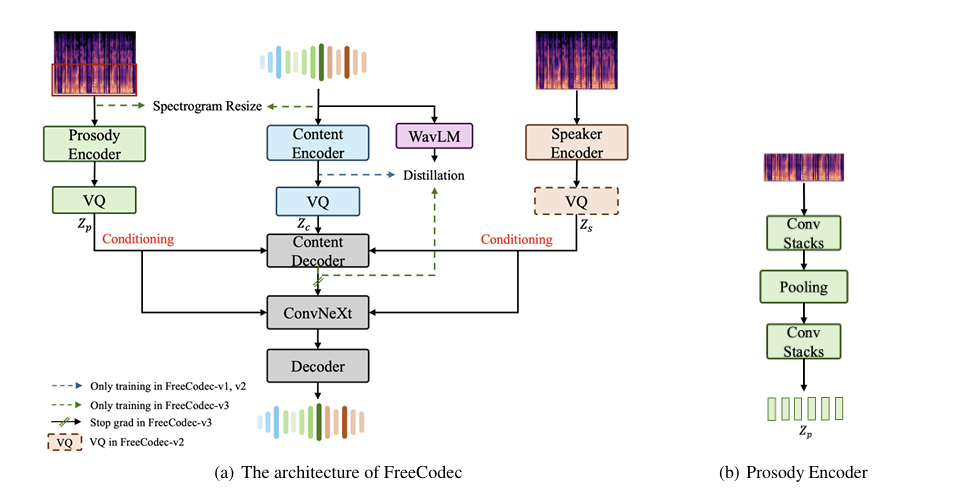
- Encoders
- Speaker Encoder
- 기존 neural codec은 global embedding이 speaker characteristic, speaking style과 같은 time-invariant information을 represent 할 수 있다고 가정함
- 여기서 논문은 unsupervised manner를 활용하여 speaker information을 further extract 함
- 이를 위해 attentive statistics pooling layer를 활용한 CNN-based speaker recognition network인 ECAPA-TDNN을 사용함
- 결과적으로 raw speech signal에서 sampling 된 mel-spectrogram을 speaker encoder에 전달하여 global timbre vector를 얻음
- Content Encoder
- Content Encoder는 $(2,4,5,8)$ stride를 사용하는 SuperCodec encoder를 따름
- Convolution block 수는 $B_{enc}=4$ - 해당 encoder는 $320\times$ downsampling에 해당하고, 16kHz speech에서 50Hz frame rate로 256-dimensional content feature를 output 함
- 추가적으로 content encoder redundancy를 reduce 하기 위해 content information을 explicitly modeling 하는 self-supervised model을 도입함
- Content Encoder는 $(2,4,5,8)$ stride를 사용하는 SuperCodec encoder를 따름
- Prosody Encoder
- Prosody Encoder는 Mega-TTS2를 따라 stride $8$의 max pooling layer와 2개의 convolution stack으로 구성된 prosody encoder를 채택함
- FFT, hop size는 각각 $1024, 320$으로 설정됨 - 결과적으로 Prosody Encoder는 $256$ dimension과 7Hz frame rate를 가진 feature embedding을 생성함
- Prosody Encoder는 Mega-TTS2를 따라 stride $8$의 max pooling layer와 2개의 convolution stack으로 구성된 prosody encoder를 채택함
- Quantization
- Content, prosody information의 경우 quantization을 위해 $256$ codebook size의 plain vector quantizer를 사용함
- Speaker embedding을 위해서는 다음의 2가지 type을 고려함:
- FreeCodec-v1, FreeCodec-v3의 경우 continuous representation
- FreeCodec-v2의 경우 discrete representation
- 특히 FreeCodec-v2에서는 speech coding을 위해 Group Vector Quantization (GVQ)를 사용하여 speaker embedding을 compress 함
- 이때 speaker embedding을 $8$ group으로 divide 하고 $1024$ codebook size로 codebook을 quantize 함 - FreeCodec-v1, FreeCodec-v3의 경우 FACodec과 유사하게, better reconstruction을 위해 continuous representation을 decoder에 제공함
- Speaker embedding을 위해서는 다음의 2가지 type을 고려함:
- Improved Decoders
- FreeCodec은 upsampling 전에 semantic modeling을 향상하기 위해 4-layer Transformer encoder로 구성된 content encoder를 도입함
- 이후 prosody와 speaker representation을 condition 하기 위해 ConvNeXt를 fundamental backbone으로 도입하고, speech signal을 reconstruct 하기 위해 mirrored decoder upsampling structure를 적용함
- Mirroed decoder는 $(8,5,4,2)$ stride를 통해 $320\times$의 upsampling을 수행함
- Training Strategy
- 논문은 perceptual quality를 향상하기 위해 multi-scale STFT-based discriminator (MS-STFT) 기반의 adversarial training을 incorporate 함
- FreeCodec의 training loss는 reconstruction loss $\mathcal{L}_{rec}$, VQ commitment loss $\mathcal{L}_{vq}$, content loss $\mathcal{L}_{c}$, feature matching loss $\mathcal{L}_{feat}$, adversarial loss $\mathcal{L}_{adv}$로 구성됨
- 이때 reconstruction loss, feature loss, adversarial loss는 EnCodec을 따름
- Content loss의 경우 pre-trained WavLM-large의 last layer representation을 semantic learning target으로 사용해 cosine similarity loss를 적용함
- FreeCodec-v1, FreeCodec-v2에서는 content encoder의 redundancy를 줄이기 위해 content encoder output과 semantic learning target 간의 cosine similarity를 maximize 함
- FreeCodec-v3에서는 additional speaker information이 content encoder, quantizer로 leak 되는 것을 방지하기 위해 decoder에만 semantic learning target을 적용함
- 추가적으로 prosody/content encoder에 대한 spectrogram-resize based data augmentation을 적용함 - 결과적으로 얻어지는 generator loss는:
(Eq. 1) $\mathcal{L}_{G}=\lambda_{adv}\mathcal{L}_{adv}+\lambda_{feat}\mathcal{L}_{feat}+\lambda_{rec}\mathcal{L}_{rec}+\lambda_{vq}\mathcal{L}_{vq}+\lambda_{c}\mathcal{L}_{c}$
- $\lambda_{adv}=3,\lambda_{feat}=3, \lambda_{rec}=1, \lambda_{vq}=1,\lambda_{c}=10$
- FreeCodec의 training loss는 reconstruction loss $\mathcal{L}_{rec}$, VQ commitment loss $\mathcal{L}_{vq}$, content loss $\mathcal{L}_{c}$, feature matching loss $\mathcal{L}_{feat}$, adversarial loss $\mathcal{L}_{adv}$로 구성됨
3. Experiments
- Settings
- Dataset : LibriSpeech
- Comparisons : SpeechTokenizer, WavTokenizer, FACodec, TiCodec, DAC, SemantiCodec
- Results
- 전체적으로 FreeCodec은 우수한 성능을 보임

- Subjective evaluation 측면에서도 뛰어난 reconstruction 성능을 보임
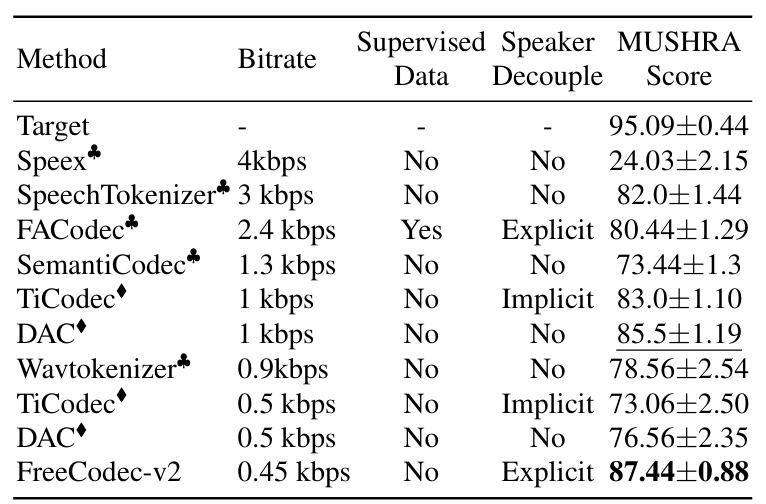
- Disentanglement Ability
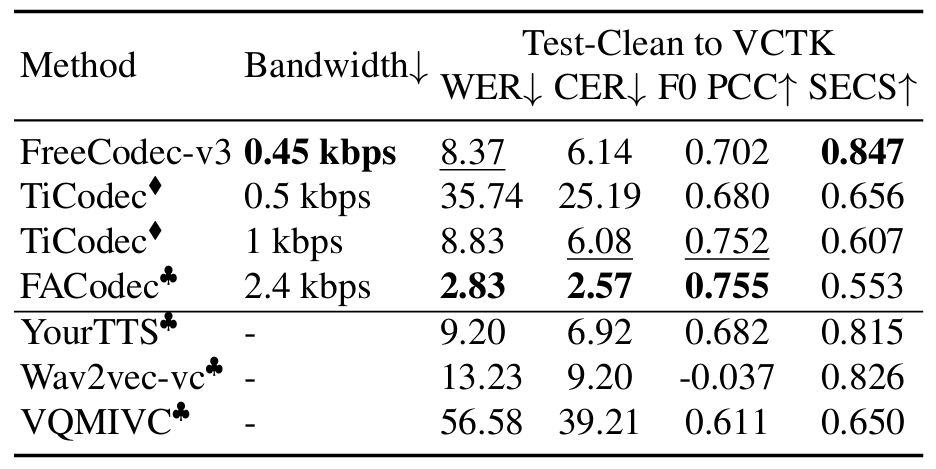
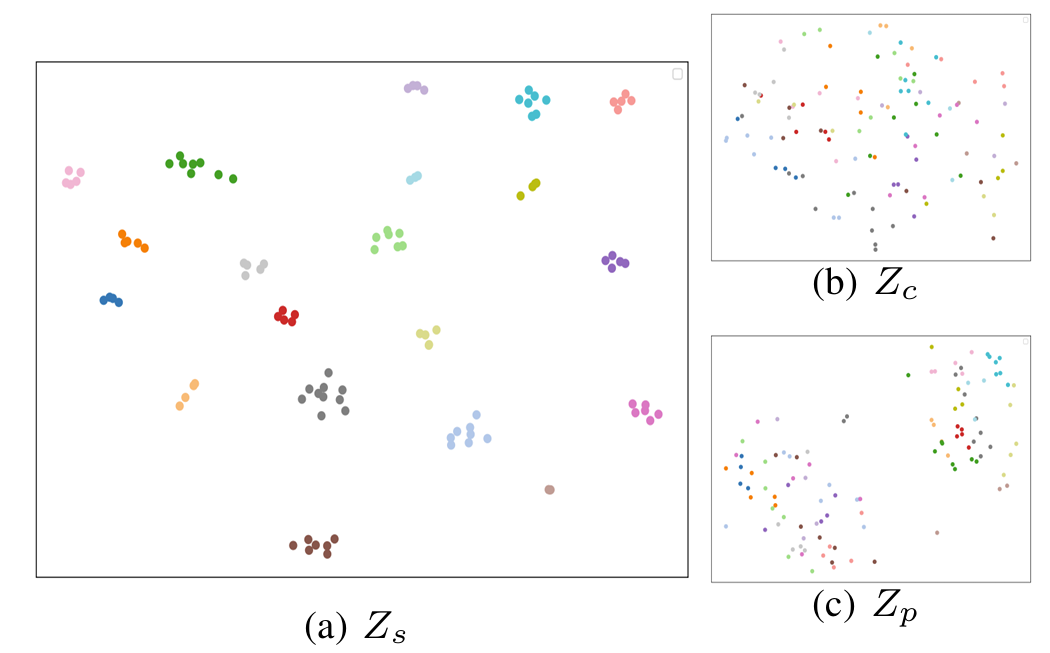
- FreeCodec은 unseen speaker scenario에 대해 높은 speaker similarity를 달성함
- $t$-SNE 측면에서 speaker embedding은 clear clustering pattern을 가짐
- $Z_{s}$ : speaker representation, $Z_{c}$ : content representation, $Z_{p}$ : prosody representation
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글