

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] Fewer-Token Neural Speech Codec with Time-Invariant Codes
feVeRin 2024. 6. 13. 09:50반응형
Fewer-Token Neural Speech Codec with Time-Invariant Codes
- Neural codec은 speech를 discrete token으로 변환하는 데 사용되지만, excessive token sequence는 오히려 prediction accuracy에 부정적인 영향을 줄 수 있음
- TiCodec
- Time-invariant information을 별도의 code로 encoding/quantizing하여 encoding에 사용되는 frame-level information의 양을 줄임
- Utterance에서 time-invariant code의 consistency를 향상하기 위해, time-invariant encoding consistency loss를 도입
- Time-invariant information을 별도의 code로 encoding/quantizing하여 encoding에 사용되는 frame-level information의 양을 줄임
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Large language model은 zero-shot text-to-speech (TTS)에서 우수한 성능을 보이고 있음
- 특히 VALL-E는 discrete token을 speech representation으로 사용해 language model을 training 하고, 7개의 quantizer를 통해 개별적으로 token을 생성함
- 이를 통해 unknown speaker의 short recording을 acoustic prompt로 사용하여 고품질의 personalized speech를 생성할 수 있음
- BUT, multiple frame-level token sequence는 robustness와 추론 속도에 큰 영향을 미치므로, language model에서는 fewer-token으로 speech를 효과적으로 represent 하는 것이 중요함 - 이때 neural speech codec은 음성의 discrete token representation을 얻는데 핵심적으로 사용됨
- 대표적으로 SoundStream은 VQVAE vector quantizer를 residual vector quantizer로 확장하여 fully convolutional end-to-end audio codec을 구성함
- EnCodec은 spectrogram-only adversarial loss, gradient balancer, small transformer model을 활용
- HiFi-Codec은 group-residual vector quantization을 사용
- BUT, 해당 neural codec들 모두 한두개의 fewer-token sequence만으로 음성을 represent 하면 고품질의 reconstruction이 불가능함
- 특히 VALL-E는 discrete token을 speech representation으로 사용해 language model을 training 하고, 7개의 quantizer를 통해 개별적으로 token을 생성함
-> 따라서 fewer-token만으로도 고품질의 reconstruction이 가능한 TiCodec을 제안
- TiCodec
- 음성에서 time에 따라 변화하지 않는 time-invariant representation을 추출하여 fixed-length의 time-invariant code로 encoding함
- 이를 통해 frame-level code로 encoding 되는 information의 양을 줄여 time-related 측면에서 최대한 많은 information을 추출함 - 이후 frame-level, time-invariant feature는 frame-level, time-invariant token으로 개별적으로 quantize 됨
- 이를 통해 TiCodec을 downstream TTS에 적용하면, target speaker의 prompt에서 time-invariant token을 직접적으로 추출할 수 있음
- 결과적으로 target speaker의 timbre를 잘 유지할 수 있고, fewer frame-level token 만으로도 효과적인 예측이 가능함 - 추가적으로 추출된 time-invariant information에 더 많은 global information이 반영될 수 있도록 time-invariant encoding consistency loss를 도입함
- 음성에서 time에 따라 변화하지 않는 time-invariant representation을 추출하여 fixed-length의 time-invariant code로 encoding함
< Overall of TiCodec >
- 음성에서 time-varying information과 time-invariant information을 개별적으로 quantize 하는 neural codec
- Time-invariant code의 consistency를 향상하는 time-invariant encoding consistency loss를 추가
- 결과적으로 fewer-token에서도 고품질의 reconstruction이 가능하고 zero-shot TTS 모델의 성능 개선을 지원
2. Method
- TiCodec은 time-invariant representation extraction module과 consistency loss를 활용하여 구성됨
- Framework of TiCodec
- 전체 framework는 encoder-decoder architecture를 따름
- 이때 U-Net-like connection을 활용하여 encoder의 hidden layer에 대한 time-invariant feature를 decoder의 hidden layer로 반영함
- Duration $d$의 speech signal을 $x\in \mathbb{R}^{T}$, sampling rate를 $f_{sr}$이라고 하면, $T=f_{sr}\times d$
- Encoder $\text{Enc}$는 input speech signal $x$를 latent representation $z$로 변환하고, 해당 representation은 vector quantization을 위해 residual vector quantizer (RVQ) $Q_{1}$으로 전달됨
- Encoder의 intermediate layer representation $h$는 Time-Invariant Representatin Extraction module $\text{TIRE}$를 통해 time-invariant represnetation $m$을 추출하고, group vector quantizer (GVQ) $Q_{2}$에 의해 quantize 됨
- Quantizer $Q_{1}$은 compressed representation $z_{q}$와 discrete token sequence $c_{f}$를 생성하고, Quantizer $Q_{2}$는 compressed representation $m_{q}$와 discrete token sequence $c_{g}$를 생성함
- 최종적으로 decoder $\text{Dec}$는 compressed latent representation $z_{q}$와 compressed time-invariant representation $m_{q}$로부터 speech signal $\hat{x}$를 reconstruction 함
- 구조적으로 $\text{Enc}, \text{Dec}$는 HiFi-Codec을 따름
- $\text{Enc}$는 1D convolution layer와 4개의 convolution module, final 1D convolution layer로 구성됨
- 이때 각 convolution module은 3개의 residual unit, 1개의 downsampling layer를 가짐
- 해당 4개 module은 $320\times$의 downsampling을 의미 - $\text{Dec}$는 encoder의 반대로써 upsampling을 위한 transposed convolution을 가짐
- 한편으로 $Q_{1}$은 speech latent representation을 frame-level token으로 quantize 하는 RVQ module으로 구성됨
- $\text{Enc}$는 1D convolution layer와 4개의 convolution module, final 1D convolution layer로 구성됨
- 추가적으로 논문은 HiFi-Codec과 동일하게, multi-scale STFT discriminator, multi-period discriminator, multi-scale discriminator의 3가지 discriminator를 채택함

- Time-Invariant Representation Extraction and Quantization
- $\text{Enc}$의 두 번째 convolution module의 output을 $\text{TIRE}$의 input으로 사용하여 time-invariant representation $m$을 추출함
- 이는 quantizer $Q_{2}$를 통해 quantize 되어 compressed time-invariant representation $m_{q}$로 변환되고, 이후 decoding을 위해 $\text{Dec}$의 두 번째 transposed convolution module로 전달됨
- 구조적으로 $\text{TIRE}$는 3개의 1D convolution layer와 LeakyReLU layer를 통해 feature extraction을 수행함
- 먼저 추출된 feature에 대해 temporal averaging을 적용하여 frame-level feature를 time-invariant feature로 summarize 함
- 이때 해당 representation을 fully connected layer와 activation function으로 전달하여, final time-invariant representation $m$을 얻음 - 다음으로 time-invariant representation $m$을 quantize 하기 위해, TiCodec은 $m$을 8개의 group으로 나누는 GVQ를 도입하여 8개의 discrete time-invariant token을 얻음
- 여기서 GVQ는 representation space를 expand 하여 time-invariant encoding을 extensive 하게 나타냄 - 이후 compressed time-invariant representation $m_{q}$는 temporal dimension에 걸쳐 duplicate 되어 segment-level time-invariant feature를 frame-level feature로 다시 변환됨
- 최종적으로 original decoder의 마지막 두 번째 layer의 input에 추가되어 jointly decoding 함
- 먼저 추출된 feature에 대해 temporal averaging을 적용하여 frame-level feature를 time-invariant feature로 summarize 함
- Time-invariant representation extraction과 quantization module은 contracting path에서 symmetric expansive path로의 connection을 설정하여 shallow representation을 전달함
- 이때 time-invariant information은 time-invariant code로 represent 되고, 나머지 frame-level code는 information bottleneck으로 인해 더 큰 temporal dependency를 capture 하게 됨
- 결과적으로 이를 통해 frame-level code에 대한 redundancy를 줄일 수 있음
- Time-Invariant Encoding Consistency Loss
- Downstream TTS에서 TiCodec을 사용하는 경우, target speech segment에서 time-invariant token을 추출한 다음 textual information을 사용하여 frame-level token을 추출함
- 여기서 논문은 서로 다른 segment에서 추출된 invariant code의 consistency를 유지하기 위해, Time-Invariant Encoding Consistency Loss $\mathcal{L}_{c}$를 도입함
- 먼저 training 중에 speech segment $seg_{1}$을 encoding 하고 동일한 utterance에서 다른 segement $seg_{2}$를 random sampling 함
- 이후 $seg_{2}$는 $\text{Enc}, \text{TIRE}$ module을 통과한 다음, stop-gradient operation을 적용함
- 이때 두 segment의 extracted time-invariant representation에 대한 consistency loss $\mathcal{L}_{c}$로써, cosine similarity를 활용:
(Eq. 1) $\mathcal{L}_{c}=1-\cos(\text{TIRE}(\text{Enc}[:2](x_{1})), \text{TIRE}(\text{Enc}[:2](x_{2})))$
- $x_{1}, x_{2}$ : speech waveform의 $seg_{1}, seg_{2}$, $\cos$ : cosine similarity function - 그러면 generator는 다음의 loss로 최적화됨:
(Eq. 2) $\mathcal{L}=\lambda_{t}\mathcal{L}_{t}+\lambda_{f}\mathcal{L}_{f}+\lambda_{g}\mathcal{L}_{g}+\lambda_{feat}\mathcal{L}_{feat}+\lambda_{qz}\mathcal{L}_{qz}+\lambda_{qm}\mathcal{L}_{qm}+\lambda_{c}\mathcal{L}_{c}$
- $\mathcal{L}_{t},\mathcal{L}_{f}$ : time-/frequency-domain reconstruction loss, $\mathcal{L}_{g}$ : adversarial loss, $\mathcal{L}_{feat}$ : feature matching loss
- $\mathcal{L}_{qz}$ : frame-level code의 quantization loss, $\mathcal{L}_{qm} =||m-m_{q}||^{2}$ : time-invariant code의 commitment loss
- $\mathcal{L}_{c}$ : time-invariant encoding consistency loss
- $\lambda_{t},\lambda_{f},\lambda_{g},\lambda_{feat}, \lambda_{qz}, \lambda_{qm},\lambda_{c}$ : hyperparameter
- 여기서 논문은 서로 다른 segment에서 추출된 invariant code의 consistency를 유지하기 위해, Time-Invariant Encoding Consistency Loss $\mathcal{L}_{c}$를 도입함
3. Experiments
- Settings
- Dataset : LibriTTS, VCTK, AISHELL3
- Comparisons : EnCodec, HiFi-Codec
- Results
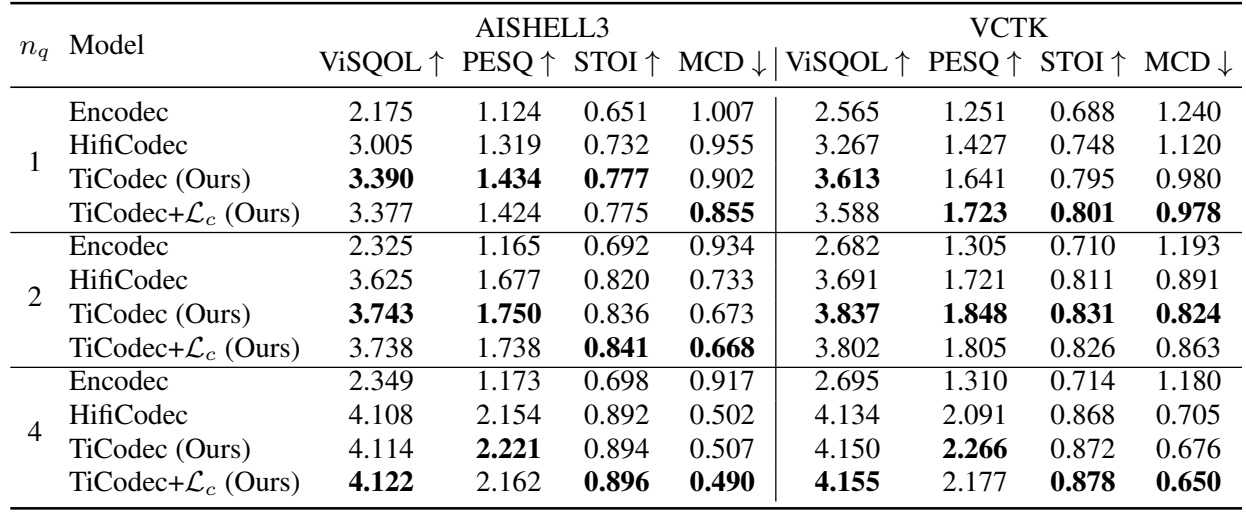
- Speech Reconstruction Performance of Codecs
- Reconstruction 성능 측면에서 TiCodec이 가장 우수한 결과를 보임
- 특히, TiCodec은 quantized token이 줄어들어도 뛰어난 성능을 유지함

- Generalization 측면에서도 TiCodec은 기존 모델들보다 뛰어난 성능을 달성함
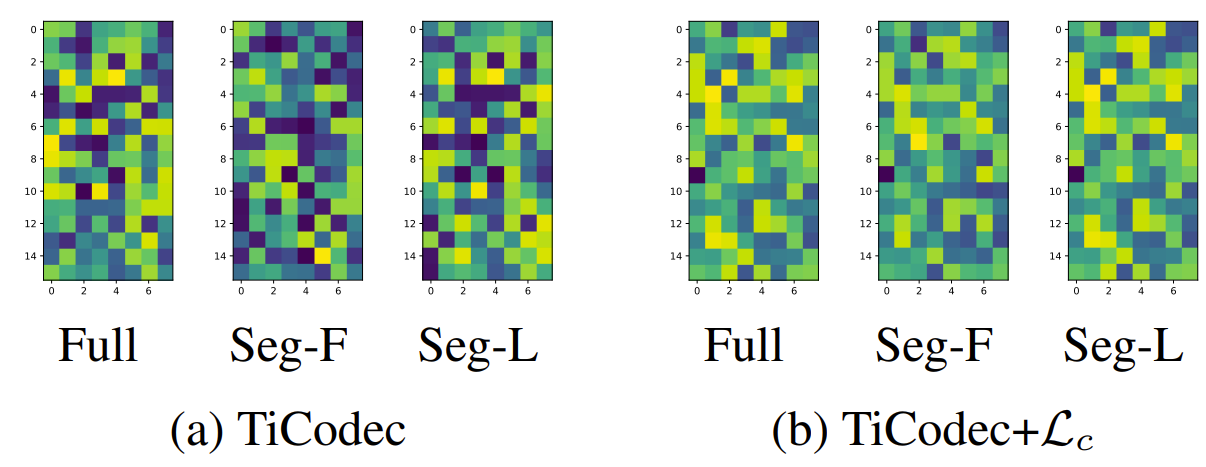
- Test set utterance에서 추출된 time-invariant representation을 확인해 보면, consistency loss $\mathcal{L}_{c}$를 추가하는 경우 동일한 utterance 내에서 서로 다른 representation 간의 consistency가 향상됨
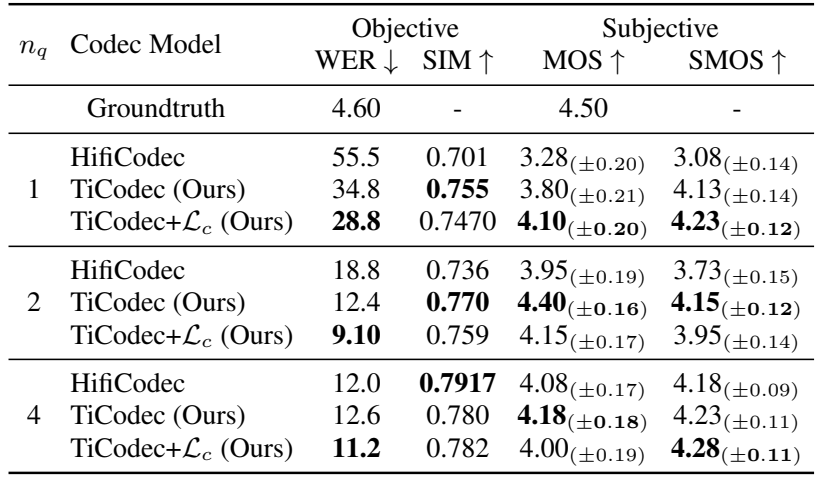
- Downstream Zero-Shot TTS Task
- Zero-Shot TTS를 위해 TiCodec은 prompt speech에서 time-invariant token을 직접 추출하여 VALL-E decoder에 반영할 수 있음
- 결과적으로 TTS 측면에서도 TiCodec을 사용했을 때 가장 좋은 성능을 달성함

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글