

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] SuperCodec: A Neural Speech Codec with Selective Back-Projection Network
feVeRin 2024. 4. 12. 12:43반응형
SuperCodec: A Neural Speech Codec with Selective Back-Projection Network
- Neural speech coding은 우수한 compression 성능을 보여주지만, low bitrate에서 fine detail reconstruction의 한계가 있음
- SuperCodec
- Low bitrate에서도 뛰어난 성능을 달성하기 위해 selective feature fusion을 가지는 back-projection method를 활용한 neural speech codec
- 특히 encoder, decoder의 standard up-/down-sampling layer를 대체하기 위해 Selective Up-sampling Back Projection, Selective Down-sampling Back Projection module을 도입
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Speech coding은 distortion을 최소화하면서 speech signal을 minimal bit로 compress 하는 것을 목표로 함
- 기존에는 psycho-acoustics를 기반으로 parameter를 추출하고 compression을 위한 codebook을 활용함
- BUT, 해당 방식은 quantization error의 inevitable increase로 인해 low bitrate에서 한계를 보임 - 한편으로 neural codec은 기존 speech coding의 성능을 크게 향상하고 있음
- 먼저 decoded speech의 품질을 향상하기 위해 기존 codec의 synthesizer를 generative model로 대체하는 방식이 있음
- 대표적으로 Lyra는 quantized mel-spectrum에서 3kpbs의 고품질 음성을 생성하는 autoregressive WaveGRU를 사용 - EnCodec과 같이 convolutional-based encoder-decoder와 VQ-VAE framework를 사용하는 end-to-end coding을 사용할 수도 있음
- Encoder에서는 input speech를 downsampling하여 data를 compress 하는 convolution layer를 사용하고,
- Decoder에서는 speech signal을 reconstruct하기 위한 transposed convolution layer가 사용됨
- 먼저 decoded speech의 품질을 향상하기 위해 기존 codec의 synthesizer를 generative model로 대체하는 방식이 있음
- End-to-End neural codec은 generative model 기반의 neural codec 보다 low bitrate에서 더 높은 품질을 달성하여 coding efficiency를 크게 향상할 수 있음
- BUT, end-to-end 방식을 사용하더라도 여전히 1.5kbps 미만의 bitrate에서는 좋은 성능을 보이지 못함 - 이는 end-to-end neural codec이 아래의 2가지 한계점을 가지고 있기 때문
- Missing Information
- 대부분의 simple convolution layer를 사용하여 input signal에서 latent representation을 추출함
- 이러한 convolution layer는 downsampling process에서 redundancy를 제거하면서 reconstruct를 위한 모든 information을 preserve해내기 어려움 - Stumbling in Reconstruction
- 일반적으로 low-resolution input representation은 decoder의 transposed convolution layer를 통해 original speech로 upsample 됨
- 해당 방식은 neural codec이 optimal reconstruction을 위해 fine-grained information을 추론하는 것을 어렵게 함
- Missing Information
- 기존에는 psycho-acoustics를 기반으로 parameter를 추출하고 compression을 위한 codebook을 활용함
-> 그래서 low bitrate에서도 고품질의 음성을 유지할 수 있는 neural codec인 SuperCodec을 제안
- SuperCodec
- 기존의 standard feed-forward up-/down-sampling layer를 각각 Selective Up-sampling Back Projection (SUBP), Selective Down-sampling Back Projection (SDBP) module로 대체
- 이를 통해 information을 efficiently preserve 하면서 network의 lower layer에서 higher layer로의 rich feature를 얻음
- 추가적으로 input feature map을 consolidate 하기 위해 SUBP와 SDBP에 selective feature fusion block을 도입
< Overall of SuperCodec >
- Back projection approach를 활용하여 low bitrate에서도 고품질의 speech signal을 reconstruct 할 수 있는 neural codec
- Input feature map을 consolidate 하여 richer representation을 추출하기 위해, feature fusion block을 SUDP, SDBP module에 도입
- 결과적으로 기존 neural codec 보다 우수한 성능을 달성
2. Method
- Overall Framework
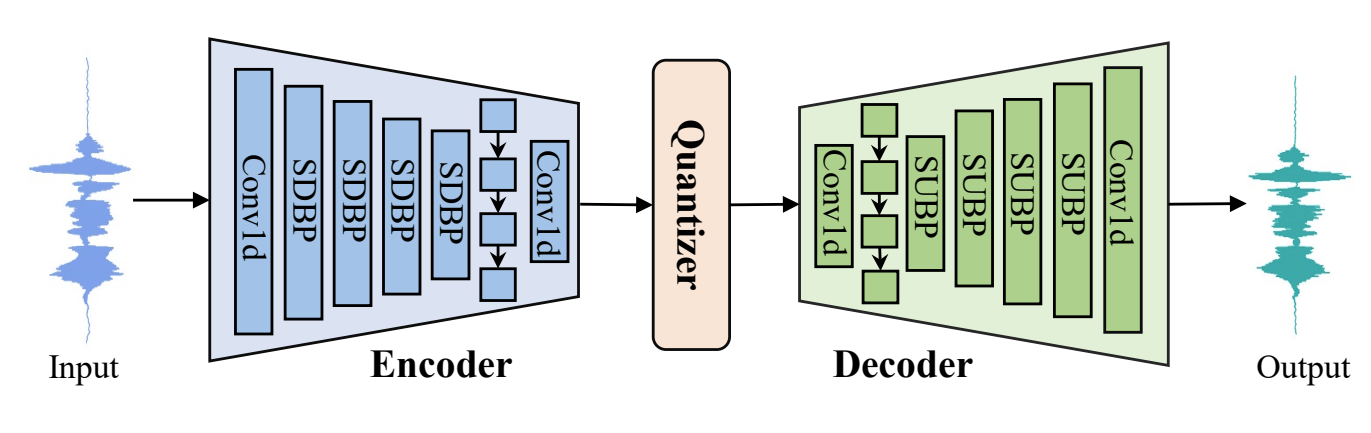
- SuperCodec은
- 다음의 3가지 component로 구성됨
- Feautre encoder network는 length $T$의 raw speech signal $\mathbf{x}\in[-1,1]^{T}$를 latent speech representation sequence $\mathbf{e}\in \mathbb{R}^{T_{e}\times N_{e}}$로 mapping 함
- $T_{e}$ : length, $N_{e}$ : dimension - Residual quantizer는 error minimization과 codebook의 해당 index code를 사용하여 $\mathbf{e}$의 해당 discrete representation을 search 함
- Decoder는 de-quantized representation으로부터 speech signal을 합성함
- Feautre encoder network는 length $T$의 raw speech signal $\mathbf{x}\in[-1,1]^{T}$를 latent speech representation sequence $\mathbf{e}\in \mathbb{R}^{T_{e}\times N_{e}}$로 mapping 함
- 아래 그림과 같이 SuperCodec의 encoder는 down-sampling을 담당하는 4개의 sequential SDBP module로 구성되고, decoder는 up-sampling을 담당하는 4개의 sequential SUBP module로 구성됨
- 여기서 encoder는 16kHz의 음성에서 50kHz의 frame rate로 256-dimensional speech feature를 output - Quantizer의 경우, low bitrate에서 continuous speech feature를 transmit 하기 위해 Residual Vector Quantization (RVQ)를 사용
- 전체 architecture는 causal 1D convolution과 end-to-end training을 기반으로 함
- 다음의 3가지 component로 구성됨
- Selective Back Projection Blocks
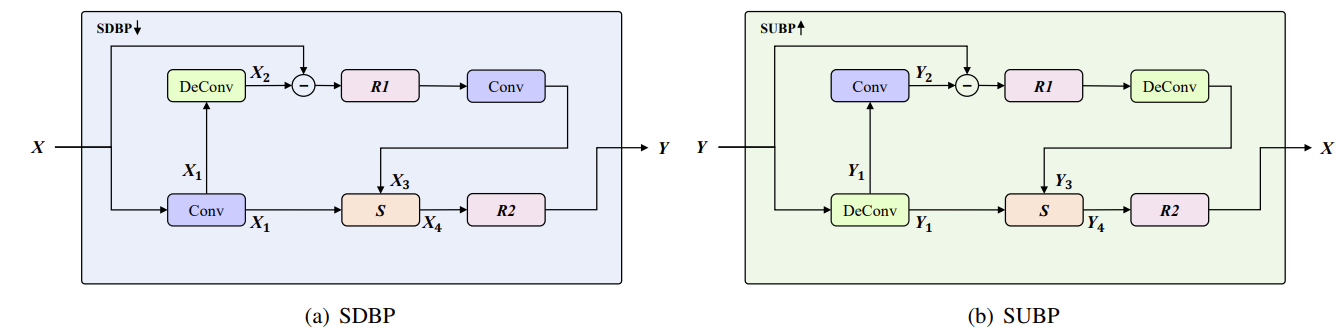
- 기존의 neural codec은 일반적으로 standard casual convolution과 deconvolution layer를 각각 down-/up-sampling operator로 사용하여 lower-/higher-resolution feature map을 생성함
- BUT, 해당 mechanism은 reconstruction 과정에서 detail을 preserve 하는데 어려움이 있음
- 한편 back projection은 feedback residual을 iterative 하게 활용하여 high-resolution feature map을 refine 하는 방식
- 이때 project 된 high-resolution feature map의 down-sampled version이 original low-resolution feature map과 최대한 가까워야 한다는 가정에 기반함 - 따라서 SuperCodec은 back projection technique을 neural codec에 적용하고 확장함
- 즉, 기존 encoder와 decoder에서 standard convolution과 deconvolution layer를 각각 SDBP $\downarrow$, SUBP $\uparrow$로 대체
- 결과적으로 아래 그림과 같이 back projection의 complementary information을 활용하여 next stage에서 더 높은 품질의 feature를 생성하는 refined feature map을 얻을 수 있음
- 이는 computation 전반에 걸쳐 propagate 되어 feature를 점진적으로 imporve 함
- For example, SUBP $\uparrow$ module은 original resolution을 recover 하기 위해,
- Reverse mapping을 적용하여 $X_{1}$에서 upsampling 된 output feature map $X_{4}$를 refine 함
- 이를 통해 동일한 resolution이더라도 re-sampled feature map $X_{3}$에는 앞선 $X_{1}$에서는 사용할 수 없었던 detail이 enclose 됨
- 이후 해당 feature map은 fusion block $S$를 사용하여 $X_{4}$에 integrate 됨
- Selective Feature Fusion
- Selective feature fusion module은 아래 그림과 같이 각 input에 대한 dynamic adjustment를 수행함
- 이를 위해 self-attention을 사용하여 다양한 receptive field feature의 information을 adaptively aggregate 함
- 아래 그림에서 $\bigoplus$는 element-wise summation, $\bigotimes$는 element-wise production operation - 해당 module은
- 2개의 parallel feature로부터 input을 receive 하고 element-wise sum을 사용하여 $Z_{1}, Z_{2}$를 combine 함
- 이후 $Z_{t} \in\mathbb{R}^{N_{e}\times T_{e}}$의 time dimension을 따라 global average pooling (GAP)를 적용하여 statistics $\mathbf{s}\in \mathbb{R}^{N_{e}\times 1}$을 계산함
- 여기서 두 feature descriptor $v_{1}, v_{2} \in \mathbb{R}^{N_{e}\times 1}$은 2개의 parallel convolution layer에 의해 제공됨 - 다음으로 서로 다른 feature map $Z_{1}, Z_{2}$를 adaptively recalibrating 하기 위한 attention activation $s_{1}, s_{2}$를 얻기 위해, 해당 descriptor에 softmax function을 적용함
- 결과적으로 feature recalibration과 aggregation에 대한 전체 process는:
(Eq. 1) $\mathbf{U}=s_{1}\cdot Z_{1}+s_{2}\cdot Z_{2}$
- Selective feature fusion module은 아래 그림과 같이 각 input에 대한 dynamic adjustment를 수행함

- Training Paradigm
- SuperCodec은 adversarial loss를 활용하는 framework를 training에 사용함
- Adversarial training framework에는 SoundStream을 따르는 waveform domain, STFT domain discriminator가 포함됨
- 이를 기반으로 standard adversarial loss, feature matching loss를 사용하여 SuperCodec을 training 함 - 추가적으로 codebook size는 $2^{10}$을 사용하고 1kbps, 2kbps, 3kbps, 6kbps에 대해 RVQ layer 수를 $\{2,4,6,12\}$로 설정
- 최종적으로 adversarial training은 800k step으로 수행됨
- Adversarial training framework에는 SoundStream을 따르는 waveform domain, STFT domain discriminator가 포함됨
3. Experiments
- Settings
- Dataset : VCTK
- Comparisons : EnCodec, Lyra v2
- Results
- Subjective Results
- 아래 그림과 같이 1kbps의 SuperCodec이 3.2kbps의 Lyra v2, 6kpbs의 EnCodec 보다 우수한 성능을 보임
- 특히 SuperCodec은 동일한 bitrate에서 re-train 된 EnCodec 보다 일관적으로 더 뛰어난 성능을 달성함

- Objective Results
- 1kbps에서 SuperCodec은 ViSQOL 및 WARP-Q 측면에서 pre-trained EnCodec (6kbps), re-trained EnCodec (2kbps) 보다 더 뛰어난 성능을 보임
- 동일한 bitrate에서 동작할 때 SuperCodec은 re-trained EnCodec보다 더 나은 성능을 달성함

- Ablation Study
- SDBP, SUBP module에 대한 ablation study를 수행해 보면, decoder에서 SUBP를 제거하는 경우 가장 큰 성능 저하가 관찰됨
- SDBP, SUBP를 standard convolution으로 대체하는 경우에도, 성능 저하가 발생함

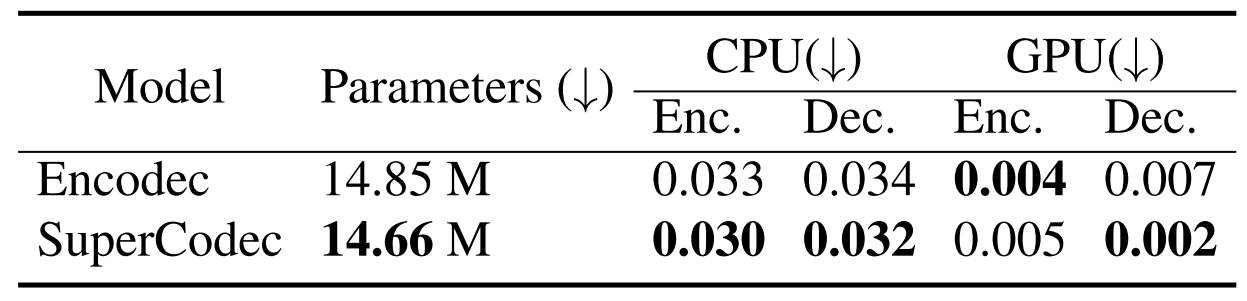
- Complexity and Computation Time
- 아래 표와 같이 SuperCodec은 가장 적은 parameter 수를 가짐
- RTF 측면에서 처리 속도를 비교해 보면, SuperCodec은 EnCodec보다 더 우수한 처리 속도를 보임
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글