

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] SpecTokenizer: A Lightweight Streaming Codec in the Compressed Spectrum Domain
feVeRin 2025. 9. 9. 17:01반응형
SpecTokenizer: A Lightweight Streaming Codec in the Compressed Spectrum Domain
- Lightweight neural audio codec이 필요함
- SpecTokenizer
- Compressed spectral domain에서 동작하는 lightweight streaming codec
- CNN, RNN layer를 altering 하여 compressed spectrum domain에서 multi-scale modeling을 수행
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Neural Audio Codec (NAC)는 audio signal을 discrete code sequence로 compress 함
- BUT, EnCodec, SoundStream과 같은 high-performance NAC는 $G$-level computational complexity와 $M$-level parameter count를 가지므로 edge-hardware에서 사용하기 어려움
- 이를 위해 spectrogram-based model을 고려할 수 있지만, waveform-basec codec에 비해 성능이 떨어짐 - 특히 NAC를 audio reconstruction과 Speech Language Modeling (SLM)에 활용하려면 다음을 고려해야 함:
- Audio Quality
- NAC는 distortion 없이 audio detail을 faithfully reconstruct 해야 함 - Bitrate Efficiency
- Bitrate unit 당 information을 effectively transmit 해야 함 - Streaming
- Real-time interaction을 위해 low-latency speech encoding이 가능해야 함 - Single Codebook
- SLM architecture에서 design complexity를 줄이기 위해서는 single-codebook model을 사용해야 함 - Low Computational Complexity
- Faster encoding/decoding을 위해 low computational complexity를 가져야 함 - Low Parameter Count
- 적은 parameter는 storage requirement와 memory demand를 줄일 수 있음 - Low Token Rate
- Longer sequence는 SLM training을 slow down 하므로, NAC model은 low token rate를 가져야 함
- Audio Quality
- BUT, EnCodec, SoundStream과 같은 high-performance NAC는 $G$-level computational complexity와 $M$-level parameter count를 가지므로 edge-hardware에서 사용하기 어려움
-> 그래서 위를 만족하는 lightweight NAC인 SpecTokenizer를 제안
- SpecTokenizer
- CNN, RNN layer를 altering 하여 representation capability를 향상
- Compressed spectrum domain에서 multi-scale modeling을 수행
< Overall of SpecTokenizer >
- Spectral domain에서 $M$-level computation과 $K$-level parameter로 동작하는 lightweight streaming codec
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Overview
- Speech signal $x$는 STFT를 통해 complex spectrogram $s$로 transform 된 다음, Dynamic Range Compression (DRC)를 통해 $s_{c}$를 얻음
- Encoder $E$는 $s_{c}$에서 latent feature $z$를 추출하고 quantization layer $Q$는 compressed representation $z_{q}$를 생성하고, Decoder $G$는 compressed spectrum $\hat{s}_{c}$를 reconstruct 함
- 이후 Dynamic Range Expansion (DRE)를 적용하여 $\hat{s}$를 얻고, iSTFT를 사용해 reconstructed audio signal $\hat{x}$를 생성함

- Spectral Compression
- Audio signal은 extremely high dynamic range의 amplitude를 가지므로 raw spectral data를 directly processing 하기 어려움
- 따라서 논문은 spectrum에 대해 Spectral Compression을 수행함
- 즉, phase를 preserving 하면서 amplitude에 compression function을 적용함 - Dynamic range compression stage에서 complex spectrum $s$가 주어지면 다음과 같이 compress 할 수 있음:
(Eq. 1) $ s_{c}=f(|s|)\cdot \text{sign}(s),\,\,\,\text{where}\,f(|s|)=|s|^{1/p}$
- $|s|$ : $s$의 magnitude, $\text{sign}(s)=s/|s|$ : $s$의 phase, $p>0$ : compression coefficient - Dynamic range expansion stage에서는 reconstructed compressed spectrum $\hat{s}_{c}$를 얻은 다음, compressed-scale spectrum을 linear-scale spectrum으로 convert 하는 inverse function $f^{-1}$을 적용함:
(Eq. 2) $\hat{s}=f^{-1}(|\hat{s}_{c}|)\cdot \text{sign}(\hat{s}_{c}),\,\,\,\text{where}\,f^{-1}(|s_{c}|)=|s_{c}|^{p}$
- 따라서 논문은 spectrum에 대해 Spectral Compression을 수행함
- Encoder and Decoder
- SpecTokenizer의 encoder $E$는 2D complex convolution 다음에 frequency downsampling block $F_{down}$과 RNN2D block이 $N$번 alternating 함
- 각 $F_{down}$ block은 channel $C$, kernel size $K$, stride $S$, Snake2D activation을 가짐
- RNN2D block은 Frame-wise Layer Normalization (FLNorm), Tanh activation, GRU layer, kernel size/stride $1$의 2D convolution, Snake2D activation으로 구성됨
- 해당 RNN architecture는 short historical dependency를 가지는 audio encoder/decoding task에 적합하고 memory consumption이 적어 edge environment에 유리함
- FLNorm의 경우 streaming processing, stable training, accelerated convergence를 지원함
- Snake2D activation은 data의 periodic feature를 capture 하기 위해 사용됨
- 이후 논문은 각 timestep에서 channel, frequency dimension에 대한 normalization을 수행함:
(Eq. 3) $\mu_{t}=\frac{1}{C\times F}\sum_{c=1}^{C}\sum_{f=1}^{F}Y_{c,t,f}$
(Eq. 4) $\hat{Y}_{c,t,f}=\frac{Y_{c,t,f}-\mu_{t}}{\sqrt{\sigma_{t}^{2}+\epsilon}}$
- $Y_{c,t,f}$ : input tensor, $C$ : channel dimension, $F$ : frequency dimension
- $\mu_{t}, \sigma^{2}_{t}$ : time $t$의 $C,F$에 대한 mean/variance, $\epsilon$ : small constant - Decoder는 encoder structure를 mirror 하고 strided convolution 대신 transposed convolution을 사용함
- Discriminator
- 논문은 HiFi-GAN의 Multi-Period Discriminator (MPD)와 DAC의 frequency-domain Multi-Band Multi-Scale STFT Discriminator (MBMS-STFT)를 사용해 phase modeling을 개선함
- Loss Function
- SpecTokenizer의 loss function은:
(Eq. 5) $\mathcal{L}=\lambda_{rec}\mathcal{L}_{rec}+\lambda_{adv}\mathcal{L}_{adv}+\lambda_{feat}\mathcal{L}_{feat}+\lambda_{cmt}\mathcal{L}_{cmt}$
- $\lambda_{rec},\lambda_{adv},\lambda_{feat},\lambda_{cmt}$ : weight coefficient
- $\mathcal{L}_{rec}$ : reconstruction loss, $\mathcal{L}_{adv}$ : adversarial loss, $\mathcal{L}_{feat}$ : feature matching loss, $\mathcal{L}_{cmt}$ : commitment loss
3. Experiments
- Settings
- Dataset : LibriTTS
- Comparisons : EnCodec, HiFi-Codec, DAC, SpeechTokenizer, WavTokenizer, FreqCodec

- Results
- 전체적으로 SpecTokenizer의 성능이 가장 우수함
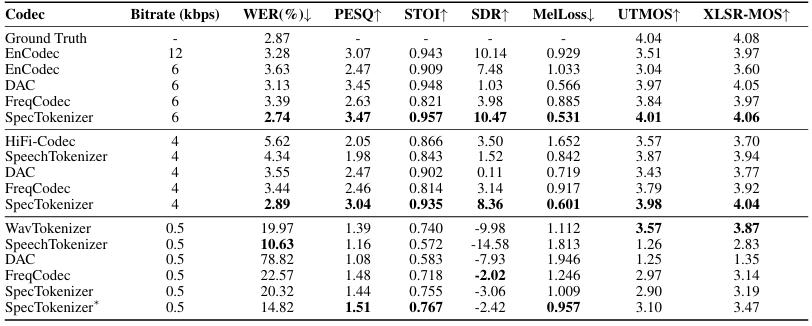
- Model Miniaturization
- SpecTokenizer는 4kpb에서도 뛰어난 성능을 보임

- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함

- Single codebook setup을 적용하는 경우 codebook utilization을 더 향상할 수 있음

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글