

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] SpeechTokenizer: Unified Speech Tokenizer for Speech Language Models
feVeRin 2025. 5. 10. 08:57반응형
SpeechTokenizer: Unified Speech Tokenizer for Speech Language Models
- Speech language model은 semantic, acoustic token과 같은 discrete speech representation을 기반으로 구축됨
- SpeechTokenizer
- Speech token이 speech language model에 적합한지를 evaluate 하기 위해 SLMTokBench를 도입
- Residual Vector Quantization에 기반한 encoder-decoder architecture를 채택하여 unified speech tokenizer를 구성
- 논문 (ICLR 2024) : Paper Link
1. Introduction
- Speech Language Model (LM)은 discrete speech representation을 기반으로 구축됨
- 일반적으로 discrete speech representation은 acoustic token과 semantic token으로 분류됨
- Semantic token은 HuBERT, Wav2Vec 2.0과 같이 masked language model을 training objective로 하는 self-supervised pre-trained model에서 얻어짐
- 특히 specific intermediate layer에서 $k$-means clustering을 통해 derive 되고, 주로 1-dimensional sequence로 represent 됨 - Acoustic token은 SoundStream, EnCodec과 같은 neural audio codec을 통해 얻어짐
- 특히 Residual Vector Quantization (RVQ)에 기반한 hierarchical quantizer를 활용하여 timestep, quantizer의 2가지 dimension으로 구성된 matrix로 represent 됨
- Semantic token은 HuBERT, Wav2Vec 2.0과 같이 masked language model을 training objective로 하는 self-supervised pre-trained model에서 얻어짐
- 한편으로 speech LM은 아래 표와 같은 speech token modeling을 채택할 수 있음
- Semantic LM은 TWIST와 같이 semantic token을 기반으로 external unit vocoder를 사용해 speech synthesis를 수행함
- BUT, 해당 방식은 acoustic detail을 충분히 반영하지 못함 - Acoustic LM은 VALL-E와 같이 acoustic token을 기반으로 구축됨
- BUT, inaccurate content로 인한 한계가 있음 - Hierarchical speech LM은 AudioLM과 같이 semantic, acoutic LM을 모두 활용함
- Content, speech quality 측면에서 우수한 성능을 보이지만, multi-stage modeling으로 인해 processing speed와 error accumulation 문제가 발생함
- Semantic LM은 TWIST와 같이 semantic token을 기반으로 external unit vocoder를 사용해 speech synthesis를 수행함
- 결과적으로 speech LM은 content를 accurately modeling 하면서 simplicity의 저하 없이 high-quality speech를 생성할 수 있어야 함
- 즉, ideal speech token은 strong text alignment와 speech information의 effective preservation이 가능해야 함
- 일반적으로 discrete speech representation은 acoustic token과 semantic token으로 분류됨

-> 그래서 speech LM을 위해 semantic token과 acoustic token을 unifying 한 SpeechTokenizer를 제안
- SpeechTokenizer
- Speech LM에서 주어진 speech token의 suitability를 평가하는 SLMTokBench를 구축
- RVQ 기반의 encoder-decoder architecture를 채택하여 semantic, acoustic token을 unifying
< Overall of SpeechTokenizer >
- Speech information의 서로 다른 aspect를 hierarchically disentangle 하여 semantic, acoustic token을 unify 한 speech LM 전용 tokenizer
- 결과적으로 기존보다 뛰어난 성능을 달성
2. SLMTokBench: Speech Language Model Token Benchmark
- Discrete speech representation은 poweful speech LM을 위해 strong text alignment와 speech information의 effective preserving이 가능해야 함
- 이때 논문은 SLMTokBench를 활용하여 speech token의 suitability를 assess 함
- Text Alignment Evaluation
- 먼저 speech token과 text 간의 mutual information을 estimating 하여 text alignment를 evalutate 함
- 이때 $\mathbf{X}$가 discrete speech representation, $\mathbf{Y}$가 text, $\mathcal{I}(\mathbf{X};\mathbf{Y})$가 mutual information, $\mathcal{D}=\{ (x_{i},y_{i})\}_{i=1}^{N}$가 test dataset, $\theta$가 downstream model을 나타낸다고 하자
- 그러면 $\mathcal{I}(\mathbf{X};\mathbf{Y})$는 다음과 같이 esitmate 됨:
(Eq. 1) $ \hat{\mathcal{I}}(\mathbf{X};\mathbf{Y})=\frac{1}{N^{2}}\sum_{i=1}^{N}\sum_{j=1}^{N}\left[ \log q_{\theta}(y_{i}|x_{i})-\log q_{\theta}(y_{j}|x_{i})\right]$
- $q_{\theta}(\mathbf{Y}|\mathbf{X})$ : downstream model $\theta$로 parameterize 된 variational distribution - Downstream model은 CTC loss로 optimize 된 vanilla 2-layer 1024-unit BLSTM으로 구성되고, speech token을 input으로 사용함
- 이때 각 discrete representation에 대해 random initialize, $k$-mean centroid, vector quantization codebook 등을 활용하여 embedding matrix를 derive 함
- 해당 embedding matrix를 사용하여 discrete representation을 embedding 하고 continuous representation을 얻은 다음 downstream model에 전달함
- 그런 다음 downstream model을 활용하여 mutual information과 WER을 estimate 함
- Information Preservation Evaluation
- Discrete speech representation에서 speech information preservation을 evaluate 하기 위해, 논문은 speech token을 speech로 convert 하여 resynthesized speech를 evaluate 함

3. Method
- Model Structure
- SpeechTokenizer는 SoundStream, EnCodec과 같이 RVQ-GAN framework를 기반으로 구성됨
- Convolutional encoder-decoder network를 채택하여 striding factor를 통해 temporal downscaling을 수행함
- 특히 기존 EnCodec의 LSTM layer를 BiLSTM로 replace 하여 semantic modeling ability를 향상함 - 추가적으로 initial quantization step 이후에 distinct codebook을 사용하여 residual을 quantize 하는 Reisdual Vector Quantization (RVQ)를 통해 encoder output을 quanitze 함
- Training 시 semantic teacher는 RVQ process를 guide 하기 위해 semantic representation을 제공함
- Convolutional encoder-decoder network를 채택하여 striding factor를 통해 temporal downscaling을 수행함

- Semantic Distillation
- 서로 다른 RVQ layer에서 다양한 information을 hierarchical modeling 하기 위해 first quantizer에 대한 semantic guidance를 통해 content information을 capture 함
- 이를 위해 논문은 HuBERT를 semantic teacher로 채택하고, Continuous representation distillation과 Pseudo-label prediction의 2가지 distillation method를 고려함
- 먼저 Continuous representation distillation을 위해, 9-th layer HuBERT representation이나 모든 HuBERT layer의 average representation을 semantic teacher로 사용함
- 이때 continuous distillation loss는 모든 timestep의 dimension level에서 RVQ first layer output과 semantic teacher representation 간의 cosine similarity를 maximize 하는 것과 같음:
(Eq. 2) $\mathcal{L}_{distill}=-\frac{1}{D}\sum_{d=1}^{D}\log \sigma\left( \cos\left( \mathbf{AQ}^{(:,d)}_{1},\mathbf{S}^{(:,d)}\right)\right)$
- $\mathbf{Q}_{1},\mathbf{S}$ : 각각 RVQ first layer의 quantized output, semantic teacher representation
- $\mathbf{A}$ : projection matrix, $D$ : semantic teacher representation의 dimension
- $(:,d)$ : dimension $d$의 모든 timestep에 대한 vector comprising value, $\cos(\cdot)$ : cosine similarity, $\sigma(\cdot)$ : sigmoid activation - Pseudo-label prediction의 경우, HuBERT unit을 target label로 활용하고, 이때 training objective는:
(Eq. 3) $\mathcal{L}_{distill}=-\frac{1}{T}\sum_{t=1}^{T}\mathbf{u}^{t}\log \left(\text{Softmax}(\mathbf{Aq}_{1}^{t})\right)$
- $\mathbf{q}_{1}^{t}, \mathbf{u}^{t}$ : 각각 first VQ layer의 quantized output, timestep $t$의 HuBERT unit
- $T$ : timestep 수, $\mathbf{A}$ : projection matrix
- Training Objective
- SpeechTokenizer의 training은 reconstruction task와 semantic distillation task를 모두 포함함
- Reconstruction task에서는 GAN objective를 채택하여 reconstruction term, discriminative loss term, RVQ commitment loss를 optimize 함
- Semantic distillation task에서는 semantic distillation loss term을 optimize 함
- Reconstruction task에서는 GAN objective를 채택하여 reconstruction term, discriminative loss term, RVQ commitment loss를 optimize 함
- Reconstruction Loss
- 먼저 $\mathbf{x}, \hat{\mathbf{x}}$를 각각 speech signal, reconstructed signal이라고 하자
- Reconstruction loss는 time, frequency domain loss로 구성됨
- Time-domain에서는 $\mathbf{x},\hat{\mathbf{x}}$ 간의 $L1$ distance를 $\mathcal{L}_{t}=|| \mathbf{x}-\hat{\mathbf{x}}||_{1}$과 같이 minimize 함
- Frequency-domain에서는 여러 time scale의 mel-spectrogram에 대해 $L1, L2$ loss를 linearly combine 함:
(Eq. 4) $\mathcal{L}_{f}=\sum_{i\in e}\left|\left| \mathcal{S}_{i}(\mathbf{x})-\mathcal{S}_{i}(\hat{\mathbf{x}})\right|\right|_{1}+\left|\left| \mathcal{S}_{i}(\mathbf{x})-\mathcal{S}_{i}(\hat{\mathbf{x}})\right|\right|_{2}$
- $\mathcal{S}_{i}$ : 64-bin mel-spectrogram (window size : $2^{i}$, hop length : $2^{i}/4$)
- $e=5,...,11$ : scale set
- Discriminative Loss
- 논문은 HiFi-Codec을 따라 multi-scale STFT-based (MS-STFT) Discriminator, Multi-Period Discriminator (MPD), Multi-Scale Discriminator (MSD)를 채택함
- Adversarial loss는 perceptual quality를 향상하기 위해 사용되고, 여러 time에 걸쳐 multiple discriminator로 average 된 discriminator logit에 대한 hinge loss로 정의됨
- $K$를 discriminator 수라고 하면, generator의 adversarial loss는 $\mathcal{L}_{g}=\frac{1}{K}\sum_{k=1}^{K}\max(1-D_{k}(\hat{\mathbf{x}}),0)$과 같음
- 그러면 discriminator의 adversarial loss는:
(Eq. 5) $\mathcal{L}_{D}=\frac{1}{K}\sum_{k=1}^{K}\max(1-D_{k}(\mathbf{x}),0)+\max(1+D_{k}(\hat{\mathbf{x}}),0)$
- 추가적으로 feature matching loss는:
(Eq. 6) $\mathcal{L}_{feat}=\frac{1}{KL}\sum_{k=1}^{K}\sum_{l=1}^{L}\frac{|| D_{k}^{l}(\mathbf{x})-D_{k}^{l}(\hat{\mathbf{x}})||_{1}}{\text{mean}(|| D_{k}^{l}(\mathbf{x})||_{1})}$
- $L$ : discriminator의 layer 수
- RVQ Commitment Loss
- 논문은 pre-quantized value와 quantized value 간의 commitment loss $\mathcal{L}_{w}$를 도입함
- 이때 RVQ commitment loss는:
(Eq. 7) $\mathcal{L}_{w}=\sum_{i=1}^{N_{q}}||\mathbf{z}_{i}-\mathbf{z}_{q}||^{2}_{2}$
- $\mathbf{z}_{i}, \mathbf{z}_{q_{i}}$ : 각각 current residual, 해당 codebook 내의 nearest entry - 결과적으로 generator는 다음의 loss로 training 됨:
(Eq. 8) $\mathcal{L}_{G}=\lambda_{t}\mathcal{L}_{t}+\lambda_{f}\mathcal{L}_{f}+\lambda_{g}\mathcal{L}_{g}+ \lambda_{feat}\mathcal{L}_{feat}+\lambda_{w}\mathcal{L}_{w}+\lambda_{distill}\mathcal{L}_{distill}$
-$\lambda_{t},\lambda_{f},lambda_{g},\lambda_{feat},\lambda_{distill}$ : hyperparameter
- Unified Speech Language Model
- SpeechTokenizer를 기반으로 unified speech language model을 구축할 수 있음
- 구조적으로는 AutoRegressive (AR), Non-AutoRegressive (NAR) model로 구성되어 speech information을 hierarchically modeling 함
- 먼저 AR model은 first RVQ quantizer에서 token을 modeling 하여 content information을 capture 함
- NAR model은 first-layer token으로 condition 되어 subsequent quantizer에서 token을 생성함
- 이를 통해 AR model에 대한 paralinguistic information을 complement 할 수 있음
- AR model은 first-layer token $\mathbf{c}_{1}$을 기반으로 구축됨
- Transformer decoder-only architecture $\theta_{AR}$을 기반으로 causal language modeling task로 동작하고 phoneme sequence $\mathbf{u}$는 AR model의 prompt로 사용됨
- 그러면 training objective는:
(Eq. 9) $\mathcal{L}_{AR}=-\log \prod_{t=0}^{T}p(\mathbf{c}_{1}^{t}|\mathbf{c}_{1}^{<t},\mathbf{u}; \theta_{AR})$
- NAR model은 subsequent quantizer에서 token $\mathbf{c}_{2:8}$을 생성함
- 구조적으로는 AR model과 유사하고, 8개의 distinct acoustic embedding layer와 output prediction layer를 가짐
- 이때 speaker voice의 characteristic을 control 하기 위해 acoustic prompt $\hat{\mathbf{C}}$가 timbre guidance로 사용됨 - 결과적으로 model은 phoneme sequence $\mathbf{u}$, acoustic prompt $\hat{\mathbf{C}}$, previous quantizer의 token을 기반으로 다음의 objective로 training 됨:
(Eq. 10) $\mathcal{L}_{NAR}=-\log \prod_{i=2}^{8}p(\mathbf{c}_{i}|\mathbf{c}_{<i},\hat{\mathbf{C}}, \mathbf{u};\theta_{NAR})$
- 구조적으로는 AR model과 유사하고, 8개의 distinct acoustic embedding layer와 output prediction layer를 가짐
- Inference 시에는 text input을 phoneme sequence로, speech prompt를 speech token으로 convert 한 다음, AR/NAR model의 prompt를 구성하기 위해 concatenate 함
- 이를 기반으로 AR model은 first-level token을 생성하고 NAR model은 subsequent level의 token을 iteratively produce 함
- AR, NAR model을 통해 생성된 token은 concatenate 되어 speech token matrix를 구성함 - 최종적으로 complete token matrix를 기반으로 SpeechTokenizer decoder를 통해 waveform을 생성함
- 이를 기반으로 AR model은 first-level token을 생성하고 NAR model은 subsequent level의 token을 iteratively produce 함
- 구조적으로는 AutoRegressive (AR), Non-AutoRegressive (NAR) model로 구성되어 speech information을 hierarchically modeling 함
4. Experiments
- Settings
- Dataset : LibriSpeech
- Comparisons : EnCodec
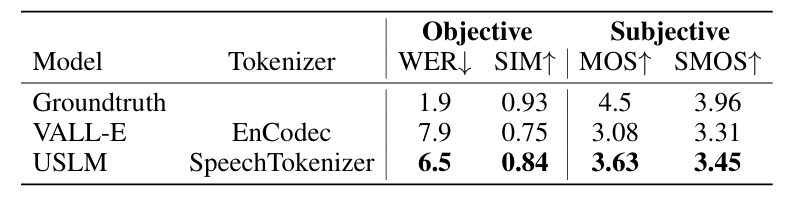
- Results
- 전체적으로 SpeechTokenizer의 reconstruction 성능이 더 뛰어남

- SLMTokBench에 대해서도 SpeechTokenizer가 우수한 성능을 보임

- Zero-shot TTS 측면에서도 SpeechTokenizer를 사용하는 경우 더 나은 성능을 달성함
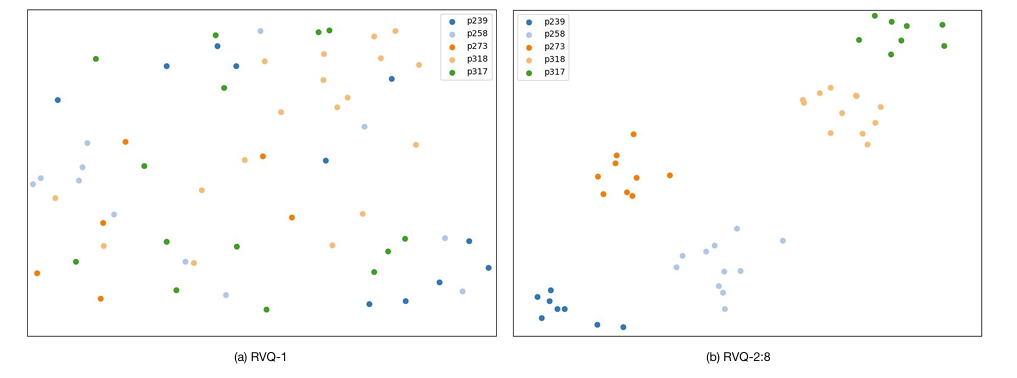
- Effectiveness of Information Disentanglement
- One-shot Voice Conversion 측면에서 reference token layer 수가 증가할수록 speaker similarity도 증가함
- 즉, reference와 source 간의 information disentanglement가 효과적으로 수행됨

- $t$-SNE 측면에서 RVQ-1 representation은 randomly scatter 되는 반면, RVQ-2:8 representation은 cluster로 나타남
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글