

티스토리 뷰
Paper/Verification
[Paper 리뷰] ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN based Speaker Verification
feVeRin 2025. 6. 16. 17:03반응형
ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN based Speaker Verification
- Speaker verification은 speaker representation을 추출하는 neural network에 의존함
- ECAPA-TDNN
- Initial frame layer를 1-dimensional Res2Net module로 reconstruct 하고 channel interdependency를 explicitly modeling 하기 위해 Squeeze-and-Excitation block을 도입
- 서로 다른 hierarchical level의 feature를 aggregate, propagate 하고 channel-dependent frame attention을 통해 statistics pooling module을 개선
- 논문 (INTERSPEECH 2020) : Paper Link
1. Introduction
- Speaker verification은 enrollment, test recording에 해당하는 두 가지 embedding을 비교하여 두 recording이 same speaker를 포함하고 있는지를 판단함
- 이를 위해 Time Delay Neural Network (TDNN)이 주로 활용됨
- Neural network convergence 이후에는 output layer 이전의 bottleneck layer에서 low-dimensional speaker embedding을 추출하여 input recording의 speaker를 characterize 함
- 이후 simple cosine distance measurement나 Probabilistic Linear Discriminant Analysis (PLDA)를 사용하여 accept/reject에 대한 judgement를 수행함
- 이때 x-vector와 같이 ResNet architecutre를 기반으로 frame-level layer 간에 residual connection을 add 하면 embedding을 더욱 향상할 수 있음
- 추가적으로 x-vector는 statistics pooling layer는 time에 따른 hidden node activation의 statistics를 gathering 하여 fixed-length representation을 variable-length input으로 project 함
- 해당 pooling layer에 temporal self-attention을 적용하면 important frame에 더욱 focus 할 수 있음
- 이를 위해 Time Delay Neural Network (TDNN)이 주로 활용됨
-> 그래서 TDNN architecture와 pooling layer를 개선한 ECAPA-TDNN을 제안
- ECAPA-TDNN
- System 전반에 걸쳐 channel을 propagate, aggregate 하기 위해 additional skip connection을 도입
- Global context를 사용하는 channel attention을 frame layer와 statistics pooling layer에 incorporate
< Overall of ECAPA-TDNN >
- TDNN에 channel attention과 1-Dimensional Residual Block을 적용한 Speaker Verification model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- 논문은 frame-level, pooling-level enhancement를 목표로 함
- Channel- and Context-dependent Statistics Pooling
- 기존의 x-vector architecture에서는 temporal pooling layer에서 weighted statistics를 calculate 하기 위해 soft self-attention이 사용됨
- 이때 multi-head attention을 사용하면 certain speaker property를 서로 다른 frame set으로부터 추출할 수 있으므로, 논문은 해당 temporal attention mechanism을 channel dimension으로 extend 함
- 이를 통해 network는 identical, similar time instance에서 activate 되지 않는 speaker characteristic에 focus 함 - 먼저 channel-dependent attention mechanism은:
(Eq. 1) $e_{t,c}=\mathbf{v}_{c}^{\top}f(\mathbf{W}\mathbf{h}_{t}+\mathbf{b})+k_{c}$
- $\mathbf{h}_{t}$ : time step $t$에서 last frame layer의 activation
- $\mathbf{W}\in\mathbb{R}^{R\times C},\mathbf{b}\in\mathbb{R}^{R\times 1}$ : self-attention을 위해 information을 smaller $R$-dimensional representation으로 project 하고, 모든 $C$ channel에서 share 하여 overfitting을 방지하는 역할 - Non-linearity $f(\cdot)$ 이후, 해당 information은 weight $\mathbf{v}_{c}\in\mathbb{R}^{R\times 1}$과 bias $k_{c}$를 가지는 linear layer를 통해 channel-dependent self-attention score로 transform 됨
- 해당 scalar score $e_{t,c}$는 time에 따라 channel-wise softmax function을 적용하여 모든 frame에서 normalize 됨:
(Eq. 2) $\alpha_{t,c}=\frac{\exp(e_{t,c})}{\sum_{\tau}^{T}\exp(e_{\tau,c})}$
- Self-attention score $\alpha_{t,c}$는 channel에 대한 각 frame의 importance를 나타내고, channel $c$의 weighted statistics를 calculate 하는 데 사용됨 - 그러면 각 utterance에 대해 weighted mean vector $\tilde{\mu}$의 channel component $\tilde{\mu}_{c}$는 다음과 같이 estimate 됨:
(Eq. 3) $\tilde{\mu}_{c}=\sum_{t}^{T}\alpha_{t,c}h_{t,c}$ - Weighted standard deviation vector $\tilde{\sigma}$의 channel component $\tilde{\sigma}_{c}$는:
(Eq. 4) $\tilde{\sigma}_{c}=\sqrt{\sum_{t}^{T}\alpha_{t,c}h_{t,c}^{2}-\tilde{\mu}_{c}^{2}}$ - Pooling layer의 final output은 weighted mean vector $\tilde{\mu}$와 weighted standard deviation vector $\tilde{\sigma}$를 concatenate 하여 얻어짐
- 해당 scalar score $e_{t,c}$는 time에 따라 channel-wise softmax function을 적용하여 모든 frame에서 normalize 됨:
- 추가적으로 논문은 pooling layer의 temporal context를 expand 하여 self-attention이 utterance의 global property를 반영할 수 있도록 함
- 이를 위해 (Eq. 1)의 local input $\mathbf{h}_{i}$와 time domain에 대한 $\mathbf{h}_{t}$의 global non-weighted mean, standard deviation을 concatenate 함 - 해당 context vector는 attention mechanism이 noise, recording condition과 같은 utterance의 global property에 adapt 할 수 있도록 함
- 이때 multi-head attention을 사용하면 certain speaker property를 서로 다른 frame set으로부터 추출할 수 있으므로, 논문은 해당 temporal attention mechanism을 channel dimension으로 extend 함
- 1-Dimensional Squeeze-Excitation Res2Blocks
- 기존 x-vector는 frame layer의 temporal context를 15 frame으로 제한하지만, 논문은 wider temporal context를 활용하기 위해 frame-level feature를 rescale 함
- 따라서 논문은 1-Dimensional Squeeze-Excitation (SE)을 도입하여 global channel interdependency를 modeling 함
- 먼저 squeeze operation은 time domain에서 frame-level feature의 mean vector $\mathbf{z}$를 calculate 함:
(Eq. 5) $\mathbf{z}=\frac{1}{T}\sum_{t}^{T}\mathbf{h}_{t}$ - $\mathbf{z}$의 descriptor는 각 channel의 weight를 calculate 하는 excitation operation에 사용됨:
(Eq. 6) $\mathbf{s}=\sigma(\mathbf{W}_{2}f(\mathbf{W}_{1}\mathbf{z}+\mathbf{b}_{1})+\mathbf{b}_{2})$
- $\sigma(\cdot)$ : sigmoid function, $f(\cdot)$ : non-linearity
- $\mathbf{W}_{1}\in\mathbb{R}^{R\times C},\mathbf{W}_{2}\in\mathbb{R}^{C\times R}$
- 해당 operation은 input channel $C$, reduced dimensionality $R$의 bottleneck layer로 작용함 - Resulting vector $\mathbf{s}$는 $[0,1]$ range의 weigth $s_{c}$를 포함하고, channel-wise mulitplication을 통해 original input에 적용됨:
(Eq. 7) $\tilde{\mathbf{h}}_{c}=s_{c}\mathbf{h}_{c}$
- 먼저 squeeze operation은 time domain에서 frame-level feature의 mean vector $\mathbf{z}$를 calculate 함:
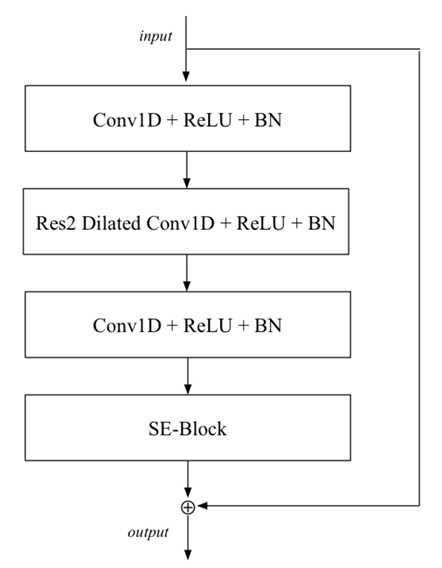
- 해당 1-Dimensional SE-block을 residual connection과 combine 하면 SE-Res2Block을 얻을 수 있음
- Res2block은 1 frame의 context를 가진 preceding, succeeding dense layer와 dilated convolution을 가짐
- First dense layer는 feature dimension을 reduce 하는 데 사용되고 second dense layer는 feature 수를 original dimension으로 restore 함 - 이후 각 channel을 scale 하는 SE-block과 skip conenction이 적용됨
- Res2block은 1 frame의 context를 가진 preceding, succeeding dense layer와 dilated convolution을 가짐
- 따라서 논문은 1-Dimensional Squeeze-Excitation (SE)을 도입하여 global channel interdependency를 modeling 함
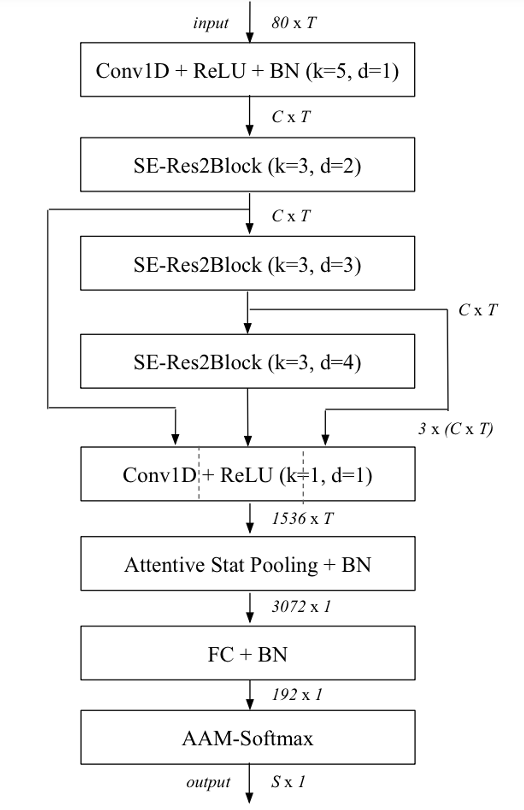
- Multi-layer Feature Aggregation and Summation
- 기존의 x-vector는 pooling statistics를 calculate 하기 위해 last frame-layer의 feature map을 사용함
- 이때 TDNN은 hierarchical nature를 가지므로 deeper level feature는 가장 complex 하고 speaker indentity와 strongly correlate 되어야 함
- BUT, shallow feature map 역시 robust speaker embedding에 contribute 할 수 있음 - 이를 위해 논문은 각 frame에 대해 다음 2가지 방식을 고려함:
- 모든 SE-Res2Block의 output feature map을 concatenate 함
- 해당 Multi-layer Feature Aggregation 이후, dense layer를 통해 concatenated information을 처리하여 attentive statistics pooling을 위한 feature를 생성함 - 한편으로 모든 preceding SE-Res2Block과 initial convolutional layer output을 각 frame layer block의 input으로 사용할 수도 있음
- 이는 각 SE-Res2Block에서 residual connection을 모든 previous block output의 sum으로 얻어짐
- 모든 SE-Res2Block의 output feature map을 concatenate 함
- 최종적으로 논문은 model parameter 수를 restrain 하기 위해 feature map summation 방식을 채택함
- 이때 TDNN은 hierarchical nature를 가지므로 deeper level feature는 가장 complex 하고 speaker indentity와 strongly correlate 되어야 함
3. Experiments
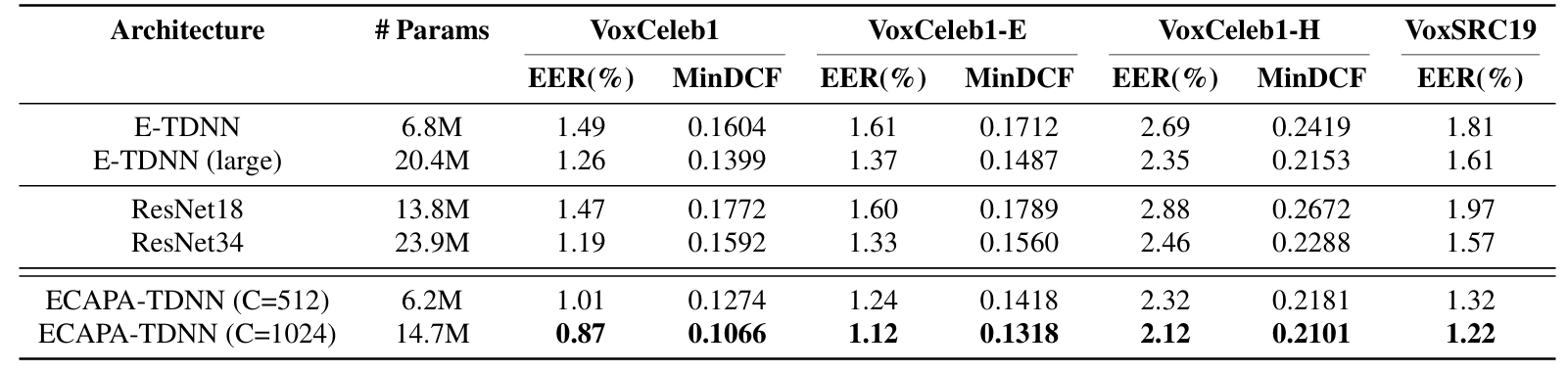
- Settings
- Dataset : VoxCeleb2
- Comparisons : ResNet
- Results
- 전체적으로 ECAPA-TDNN의 성능이 가장 우수함
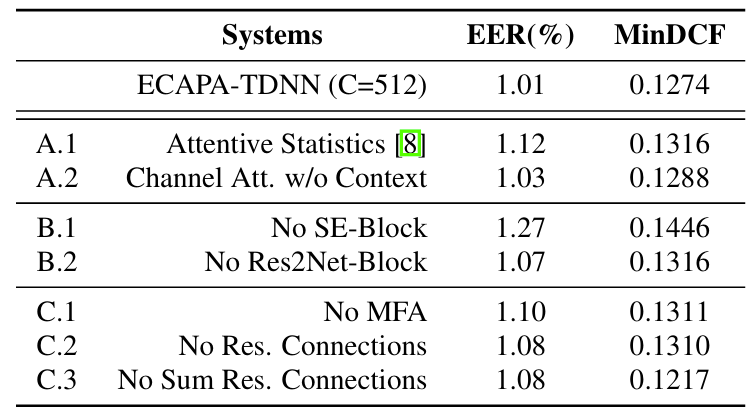
- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함
반응형
'Paper > Verification' 카테고리의 다른 글
댓글