
티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] ALMTokenizer: A Low-Bitrate and Semantic-Rich Audio Codec Tokenizer for Audio Language Modeling
feVeRin 2025. 6. 22. 08:54반응형
ALMTokenizer: A Low-Bitrate and Semantic-Rich Audio Codec Tokenizer for Audio Language Modeling
- Audio token을 audio language model에서 중요하게 사용됨
- ALMTokenizer
- Frame 간의 context information을 explicitly modeling 하여 learnable query token set을 통해 holistic information을 capture 하는 Query-based Compression Strategy를 도입
- Semantic information을 향상하기 위해 Masked AutoEncoder, Semantic prior-based Vector Quantization, Autoregressive loss를 도입
- 논문 (ICML 2025) : Paper Link
1. Introduction
- 최근의 AudioLM, MusicLM, UniAudio 등은 audio generation을 위해 Large Language Model (LLM)의 Autoregressive (AR) Transformer를 주로 활용함
- 이때 SoundStream, EnCodec과 같은 audio tokenizer는 audio singal을 AR audio language modeling을 위한 discrete token sequence로 convert 하는 데 사용됨
- 해당 codec은 audio data를 quantized discrete latent space에 represent하고 codec decoder는 generated discrete token sequence로부터 audio signal을 reconstruct 함 - 한편으로 어떤 type의 audio codec이 audio language modeling에 적합한지 확인하기 위해, 50Hz, 25Hz, 12.5Hz의 frame rate에서 각 audio tokenizer를 비교해 보면:
- 아래 그림과 같이 low-bitrate audio codec은 training/inference efficiency를 향상할 수 있음
- Semantic information의 경우 LM-based generative method에서 효과적으로 modeling 됨
- 즉, audio language modeling을 위해서는 low-bitrate, semantic-rich audio codec이 필요함
- 이때 SoundStream, EnCodec과 같은 audio tokenizer는 audio singal을 AR audio language modeling을 위한 discrete token sequence로 convert 하는 데 사용됨

-> 그래서 audio LLM을 위한 low-bitrate, semantic-rich audio codec인 ALMTokenizer를 제안
- ALMTokenizer
- Query-based compressison을 도입하여 learnable query token set을 사용해 audio frame 간의 text information을 explicitly modeling 하고, holistic information을 capture
- 이때 better compression, semantic modeling을 위해 Transformer를 활용하고, query token 수를 adjust 하여 compression rate를 dynamic control 할 수 있음 - Codec의 semantic richness를 향상하기 위해 Masked AutoEncoder (MAE) loss를 활용
- VQ layer에 semantic prior를 integrate 하고, latent space를 optimize 하는 AR prediction loss를 도입
- 이를 위해 pre-trained Wav2Vec 2.0, BEATs encoder output에 대해 $k$-means clustering을 수행하고, cluster center를 사용하여 VQ layer를 initialize 함
- Query-based compressison을 도입하여 learnable query token set을 사용해 audio frame 간의 text information을 explicitly modeling 하고, holistic information을 capture
< Overall of ALMTokenizer >
- Query-based compression, MAE/AR loss를 활용한 low-bitrate, semantic-rich audio codec tokenizer
- 결과적으로 기존보다 뛰어난 성능을 달성
2. Method
- Preliminary
- EnCodec, SoundStream과 같은 기존의 audio codec은 encoder-quantizer-decoder framework를 주로 활용함
- 이때 audio는 encoder를 통해 several audio frame으로 encode 되고 Residual Vector Quantization (RVQ)를 통해 해당 audio frame을 quantize 함
- 이후 decoder는 quantized audio frame에서 waveform을 recover 함 - BUT, 기존의 codec은 각 audio frame을 equally treat 하고 quantized frame에 의존하여 audio를 recover 함
- 결과적으로 서로 다른 audio frame이 서로 다른 information을 encode 한다는 것을 ignore 하므로 low-bitrate setting에서 audio recover가 어려움
- 서로 다른 frame 간의 context information을 반영할 수 없음
- 이때 audio는 encoder를 통해 several audio frame으로 encode 되고 Residual Vector Quantization (RVQ)를 통해 해당 audio frame을 quantize 함
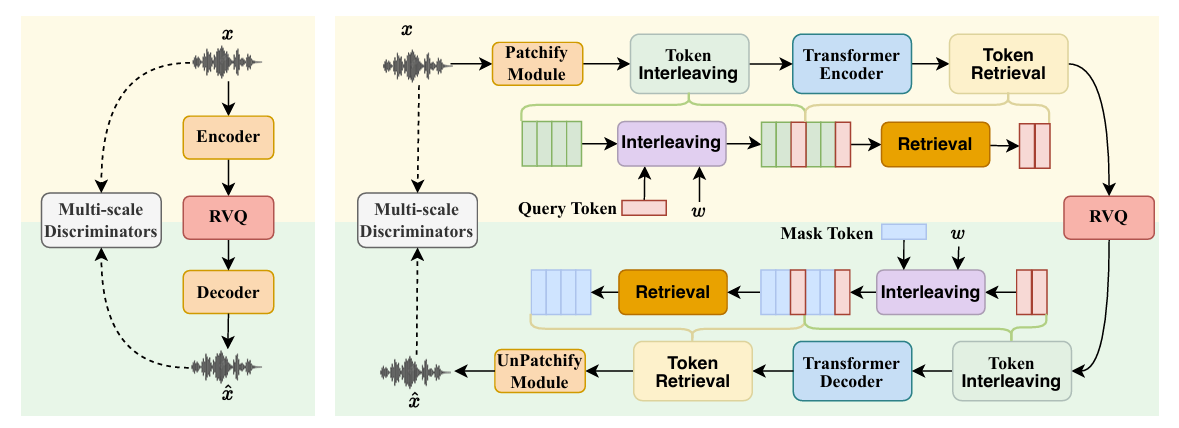
- Query-based Audio Compression
- 논문은 low-bitrate, semantically rich audio codec을 구성하기 위해 Query-based Compression을 도입함
- 특히 MAE는 high mask rate ($75\%$)로 original image에 masking operation을 적용한 다음, Transformer encoder/decoder에서 patch 간 context information을 통해 image recovering이 가능함
- 따라서 논문은 Transformer encoder를 통해 audio frame의 holistic audio context information을 caputre 할 수 있도록, rich context information을 포함하는 query token group을 도입함
- 이후 Transformer decoder와 mask token을 quantized query token에서 audio를 reconstruct 하는 데 사용함
- Patchify and UnPatchify
- 먼저 논문은 다음 2가지의 Patchify module을 고려함:
- Audio data $\mathbf{x}$를 $\mathbf{e}\in\mathbb{R}^{T\times d}$로 encode 하는 EnCodec과 같은 convolution-based module
- $T, d$ : 각각 frame 수, vector dimension - Audio data를 $\mathbf{e}\in\mathbb{R}^{T\times d}$로 encode 하기 위해 StableCodec과 같이 linear layer를 사용하고 Transformer layer를 add 하는 module
- Audio data $\mathbf{x}$를 $\mathbf{e}\in\mathbb{R}^{T\times d}$로 encode 하는 EnCodec과 같은 convolution-based module
- EnCodec-style Patchify module을 사용하는 경우, UnPatchify module은 stride convolution을 transposed convolution으로 substitute 하고 stride order를 reverse로 적용함
- 논문은 EnCodec-style Patchify/Unpatchify module을 default setting으로 사용함 - StableCodec-style Patchify module을 사용하는 경우, UnPatchify module은 Transformer block과 reshape operation을 가짐
- 먼저 논문은 다음 2가지의 Patchify module을 고려함:
- Token Interleaving
- Token Interleaving module은 두 개의 token sequence를 single sequence로 combine 함
- Encoder part에서는 audio frame $\mathbf{e}\in\mathbb{R}^{T\times d}$와 query token $\text{[CLS]}$를 combine 함
- 이때 window size $w$에 대해, query token은 매 $w$-interval 마다 audio frame에 insert 됨 - Decoder part에서는 quantized query token과 learnable mask token을 combine 함
- 각 query token 앞에 $w$ mask token을 insert 됨 - Training 시에는 각 training iteration에 대해 window size를 dynamically choice 함
- Token Retrieval
- Token Retrieval module은 sequence에서 relevant token을 retrieve 하는 것을 목표로 함
- Encoder part에서는 learnable query token, decoder part에서는 learnable mask token을 retrieve 함
- Query-based Transformer Encoder
- 논문은 audio frame $\mathbf{e}$에서 holistic information을 capture 하기 위해 learnable query token $\text{[CLS]}\in \mathbb{R}^{1\times d}$를 도입함
- 먼저 window size $w$에 대해 audio frame, query token을 token interleaving module을 통해 combine 함
- Transformer module은 whole sequence $\mathbf{e}_{a}$를 modeling 하는 데 사용됨 - 이후 query token을 추출하기 위해 token retrieval module을 사용하여 $\mathbf{h}\in\mathbb{R}^{\lfloor T/w\rfloor \times d}$를 얻음:
(Eq. 1) $ \mathbf{e}=P(\mathbf{x}),\,\,\mathbf{e}_{a}=\text{Interleaving}(\mathbf{e},\text{CLS},w), \,\, \mathbf{e}_{a}=\text{En}(\mathbf{e}_{a}),\,\, \mathbf{h}=\text{Retrieval}(\mathbf{e}_{a},w)$
- $P(\cdot)$ : Patchify Module, $\text{En}(\cdot)$ : Transformer encoder
- Residual Vector Qunatization
- Low-bitrate audio codec $\hat{\mathbf{h}}=Q(\mathbf{h})$를 위해 RVQ layer 수는 3으로 설정됨
- 추가적으로 Wav2Vec 2.0의 $k$-means cluster를 speech semantic prior, BEATs의 $k$-means cluster를 sound semantic prior로 사용함
- Codebook size를 $C$라고 했을 때, $C/2$는 speech를 represent 하는 데 사용하고 나머지는 general sound를 represent하는데 사용함
- 이후 해당 semantic prior를 사용하여 VQ layer의 codebook을 initialize 하고 fix 함
- 다음으로 input feature를 VQ layer로 mapping 하기 위해 linear layer를 적용함
- Query-based Transformer Decoder
- Audio information을 recover 하기 위해 Encoder part를 사용하여 reverse process를 구성함
- 먼저 token interleaving module을 사용하여 mask token $\mathbf{m}\in\mathbb{R}^{1\times d}$를 $\hat{\mathbf{h}}$와 combine 함
- 이후 Transformer module을 통해 sequence를 modeling 함 - 결과적으로 mask token은 UnPatchify module을 통해 audio information으로 recover 됨:
(Eq. 2) $\mathbf{q}_{a}=\text{Interleaving}(\hat{\mathbf{h}},\mathbf{m},w),\,\, \mathbf{q}_{a}=\text{De}(\mathbf{q}_{a}),\,\, \mathbf{e}_{o}=\text{Retrieval}(\mathbf{q}_{a},w),\,\, \hat{\mathbf{x}}=\text{UnP}(\mathbf{e}_{o})$
- $\text{UnP}(\cdot)$ : UnPatchify module, $\text{De}(\cdot)$ : Transformer decoder
- Training Loss
- ALMTokenizer는 GAN objective를 기반으로 generator (Patchify module, Transformer encoder, quantizer, Transformer decoder, UnPatchify module)과 discriminator를 optimize 함
- Generator의 경우 reconstruction loss, adversarial loss, MAE loss, AR prediction loss로 구성됨
- Reconstruction loss, adversarial loss는 SoundStream, EnCodec을 따름
- MAE Loss
- Semantic-rich audio codec tokenizer를 위해 논문은 MAE loss를 incorporate 함
- Frame sequence $\mathbf{e}$에 대해 audio frame feature를 randomly choice 하고 해당 frame을 $\mathbf{e}_{m}=\text{Mask}(\mathbf{e})$와 같이 0으로 설정함
- 이후 masked feature $\mathbf{e}_{m}$을 encoder Transformer에 전달함
- Encoded feature는 MAE-decoder Transformer block으로 전달되어 $\mathbf{e}$를 predict 함
- 여기서 논문은 $[0.2,0.3]$의 dynamic mask rate를 사용하고, MSE loss를 masked audio frame에 적용함
- AR Loss
- RVQ-based audio codec model의 first layer는 다른 layer 보다 audio language model에 더 fit 함
- 이는 first layer가 semantically related information을 더 많이 encode 하기 때문 - 즉, speech data에서 대부분의 content information은 first VQ layer에 의해 recover 되지만, residual layer는 acoustic-level information을 encode 하므로 speech quality에 영향을 줌
- 따라서 residual layer의 token이 fit 될 수 있도록 RVQ latent space에 AR prediction prior를 도입함
- 이를 위해 RVQ layer에서 next-token prediction을 수행하는 lightweight continuous AR Transformer를 활용하여 first, second VQ layer feature를 기반으로 third VQ layer의 quantized feature를 predict 함
- Optimization은 MSE loss를 통해 수행됨
- RVQ-based audio codec model의 first layer는 다른 layer 보다 audio language model에 더 fit 함
- Two-Stage Training Strategy
- ALMTokenizer의 reconstruction, semantic information을 향상하기 위해 two-stage training을 도입함
- Audio codec quantization은 local relationship modling에 focus 하고 semantic informatin은 global representation modeling에 focus 하기 때문
- First stage에서는 quantization 없이 AutoEncoder를 Patchify, UnPatchify module로 directly training 함
- 이때 Patchify module에서 semantic information을 encoding 하기 위해 Transformer-based MAE encoder/decoder를 도입함
- Encoder는 masked frame sequence를 처리하고, decoder는 masked part를 predict 함
- Training 이후 Transformer encoder/decoder는 discard 됨
- Second stage에서는 Patchify, UnPatchify module을 first stage의 checkpoint로 initialize 하고, Patchify module의 parameter를 freeze 함
- 이후 앞선 training loss를 적용하여 model을 training 함
3. Experiments
- Settings
- Dataset : LibriTTS, AudioSet
- Comparisons : HuBERT, WavLM, EnCodec, DAC, WavTokenizer, StableCodec
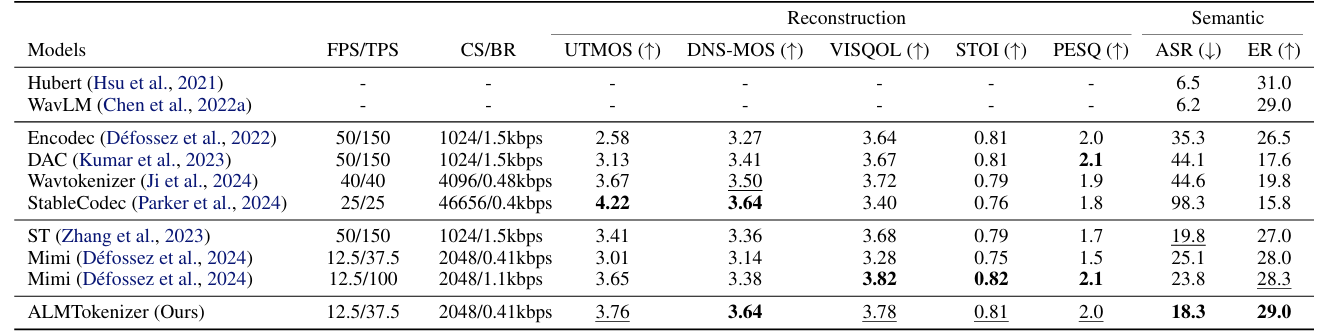
- Results
- 전체적으로 ALMTokenizer는 우수한 성능을 달성함
- MUSHRA test에서도 우수한 성능을 보임

- ALMTokenizer는 sound reconstruction에서도 뛰어난 성능을 달성함

- Music reconstruction도 마찬가지로 우수한 성능을 보임

- Speech Understanding and Generation
- ALMTokenizer를 사용하는 경우 LM-based TTS/ASR 성능을 향상할 수 있음

- Sound/Music Understanding and Generation
- LM-based Sound/Music task 역시 ALMTokenizer를 사용할 때 가장 우수한 성능을 달성함

- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함

- Influence of AR Loss
- LM loss를 사용하는 경우 second, thrid VQ layer에서 token prediction accuracy를 크게 향상할 수 있음

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글